
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі дослідженн, заплановані результати
- 3. Огляд досліджень та розробок
- 4. Автоматизоване наповнення звукової бази синтезатора мови з використанням методів кратномасштабного аналізу
- 4.1. Алгоритм сегментації з використанням методу кратномасштабного аналізу
- 4.2. Модифікація алгоритму
- 5. Інтонаційні конструкції російської мови
- 6. Огляд методів синтезу мовлення з інтонаційним забарвленням
- 6.1. Синтез інтонаційної складової мовного сигналу з застосуванням сплайнової інтерполяції
- 6.2. Синтез монотонної і виразної мови методом Unit Selection
- Висновки
- Перелік посилань
Вступ
Розроблюванні на сьогоднішній день система здатні не тільки виконувати різні операції по обчисленню та обробці інформації, але і виконувати її розпізнавання і відновлення по вхідним даним. В останній час такі системи користуються великим інтересом не тільки в наукових, але і в практичних областях діяльності людей. Однією з актуальних задач даних систем є синтез мови.
Синтезом мови називається процес відновлення форми мовного сигналу по його параметрам.
При проектуванні і створенні сучасних синтезаторів мови часто використовують звукову базу [1], що містить або віддільні фонеми, або їх сполучення, або повноцінні записи слів, або словосполучення в залежності від підходу до синтезу. На перших етапах створення синтезаторів наповнення бази може відбуватися вручну. Та такий підхід чреватий часовими затратами на пошук необхідних сегментів, суб’єктивним людським сприйняттям звукового сигналу, складністю відтворення результатів такого наповнення. В зв’язку з цим постає питання автоматизації даного процесу з використанням методів сегментації мови.
Існує велика кількість методів сегментації мови, основаних на різних математичних апаратах: дискретному вейвлет-перетворенні [2], динамічному програмуванні [3], перетворенні логарифмічного спектру [4]. Вони дозволяють отримувати відтворюванні результати сегментації з різною якістю та точністю. Особливою вимогою до методів сегментації є дикторонезалежність, оскільки ця властивість дозволяє, не змінюючи параметрів метода під окремого диктора, отримати базу звуків для різних голосів.
До сучасних систем синтезу мови пред’являються вимоги розбірливості та природності (натуральності) звучання. Розбірливість передбачає правильне розпізнавання людиною всіх слів синтезованої мови. Більшість сучасних систем синтезу мови демонструють добру розбірливість, що наближається до розбірливості природної мови. У той же час практика показує, що розбірлива мова, але неприродна не задовольняє вимогам користувачів. Природність синтезованої мови оцінюється по тому, наскільки вона схожа на мову живої людини.
Під мовою з інтонаційним забарвленням розуміється вираз відношення читаючого текст до змісту цього тексту і до аудиторії. Як правило, стиль і зміст тексту диктує вибір стилю мови. В мові з інтонацією підкреслені окремі слова, виділені паузами певні ділянки тексту і т.д.
1. Актуальність теми
Синтез мови по тексту може бути використаний в техніці зв’язку, в інформаційно довідкових системах, для допомоги людям з порушеннями опорно-рухового або зорового апаратів, видачі інформації про технологічні процеси, у військовій і космічній техніці, у робототехніці. У перспективі розробка високоякісних систем синтезу мови по тексту є необхідним кроком в напрямку більш тісного спілкування людини з комп’ютером. В цілому мовний синтез може знадобитися у всіх випадках, коли одержувачем інформації є людина.
На основі вище сказаного можна зробити висновок, що магістерська робота присвячена актуальній науковій задачі синтезу мови.
2. Мета і завдання дослідження, заплановані результати
Метою магістерської роботи є розробка програмного забезпечення для синтезу слів і словосполучень російський мови з моделюванням інтонаційного забарвлення.
Для досягнення поставленої мети необхідно вирішити наступні задачі:
- Cегментування мовного сигналу диктора для автоматизованого наповнення бази звукосполучень синтезатора.
- Аналіз тексту, що вводиться.
- Транскрибування проаналізованого тексту.
- Склеювання звукосполучень з бази синтезатора без клацань по транскрипції.
- Визначення інтонаційної конструкції тексту.
- Приведення мовного сигналу до заданого мелодійного контуру.
Об’єкт дослідження: мова, як послідовність звуків, які є реалізаціями конкретних фонем.
Предмет дослідження: алгоритми моделювання мелодійного контуру при синтезі мови та їх програмна реалізація.
У рамках магістерської роботи планується отримання актуальних наукових результатів за наступними напрямками:
- Розробка алгоритму сегментації мовного сигналу з використанням методу кратномасштабного аналізу, що дозволить надалі автоматизувати процес наповнення бази звуків синтезатора.
- Розробка алгоритму визначення інтонаційної конструкції тексту.
- Розробка алгоритму накладення мелодійного контуру на синтезований мовний сигнал.
Для експериментальної оцінки отриманих теоретичних результатів в якості практичних результатів планується розробка програмної реалізації синтезатора мови.
3. Огляд досліджень та розробок
Синтезом мови займалися такі вчені як Дж. Фланаган [5], Фант Г. [6–7], Сорокін В.К. [1], Лобанов Б.М. [8]. В їхніх працях розглянуто теоретичні та експериментальні основи синтезу та аналізу мови, а також описані конкретні практичні результати у вирішенні завдань комп’ютерного синтезу.
Для синтезу російської мови необхідно мати уявлення про фонетичну складову російської мови. Дане питання викладено в працях Буланіна Л.Л. [9], Бондарко Л.Б. [10] і Бондарко Л.В. [11]. Інтонаційні конструкції сформульовані Бризгуновою Е.А. [12], Пешковским А.М. [13] і Цеплітісом Л.К. [14].
Підходи до інтонаційного забарвлення синтезованого мовного сигналу запропоновані в статтях Людовик Т.В. [15–16] і Кіломолдаева М.Н. [17].
У статтях Вишнякової О.А. [2], Давидова О.Г. [3], Колокова А.С. [4], Єрмоленко Т.В. [18–19], Сорокіна В.М. [20] викладені алгоритми сегментації мовного сигналу, які можна використовувати в цілях автоматизованого наповнення звукової бази синтезатора мови.
Математичні апарати, що використовуються при обробці звукового сигналу, зібрані в книгах Сергієнко А.Б. [21], Р. Лайонса [22], Е. Айфічера [23], Умняшкіна С.В. [24].
4. Автоматизоване наповнення звукової бази синтезатора мови з використанням методів кратномасштабного аналізу
4.1. Алгоритм сегментації з використанням методу кратномасштабного аналізу
Як відомо, мовний сигнал складається з квазістаціонарних ділянок, відповідних голосовим і шиплячим фонемам, перемежованих ділянками з порівняно швидкими змінами спектральних характеристик сигналу (межфонемні переходи, вибухові і смичні фонеми, переходи мова-пауза в середині слова) [20]. В межах стаціонарних ділянок значну роль для аналізу мови відіграють спектральні особливості сигналу, що визначаються передаточною характеристикою мовного тракту, що змінюється в процесі артикуляції. Можна сказати, що мовний сигнал характеризується нелінійними флуктуаціями різних масштабів. Тому досить ефективним для аналізу мовного сигналу представляється кратномасштабний аналіз та вейвлет-перетворення.
Розкладання по вейвлетам мовного сигналу довжиною N відліків є сумою наступного вигляду [25]:
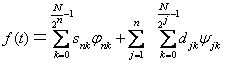
де Snk — коефіцієнти апроксимації; djk — коефіцієнти, що деталізують; φnk — масштабована скейлінг-функція φ; ψjk — зміщена версія скейлінг-функції материнського вейвлета ψ; n — рівень деталізації.
Масштабування і зміщення функцій φ і ψ знаходяться наступним чином:
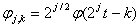
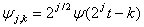
Алгоритм сегментації, заснований на кратномасштабному аналізі сигналу містить наступні кроки [18]:
- Мовний сигнал, оцифрований з частотою дискретизації 22050 Гц, розбивається на вікна розміром 512 відліків з половинним перекриванням вікна.
- Сигнал розкладається по U рівнями (U = 6, використовувалося кратномасштабне вейвлет-перетворення в базисі Добеши 8).
- Для кожного j-го рівня будується числова послідовність
- Використовуючи співвідношення:
- Знаходиться загальна кількість передбачуваних меж для всіх рівнів sum(ti), i=(1;N).
- Вибираючи пороговий коефіцієнт gпор що змінюється в межах [0; 1], отримуємо нерівність для пошуку межфонемного переходу:
- Рахуємо координату межі межфонемного переходу, усереднюючи сформований за нерівності вище масив знайдених меж.
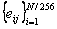
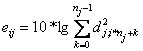
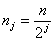
де i — номер ковзаючого вікна; nj — розмір ковзаючого вікна на j-му рівні; n — розмір вікна у вихідному сигналі.
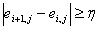
де ɳ= 3,5.
Визначаються передбачувані межі між вікнами з номерами i та i+1.
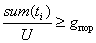
4.2. Модифікація алгоритму
При використанні методу кратномасштабного аналізу на записах цілих слів було визначено, що можливе виникнення в результатах міток меж, не відповідних жодної з позицій транскрипції. Приклад такого випадку показаний на рисунку 1 на записі слова машина
. На рисунку видно, що крім цих меж між фонем на звуковому сигналі поставлено дві зайві мітки: на голосній а
та шиплячій ш
. Така ситуація відбувається через невірно підібраних параметрів ɳ і gпор. Тому вихідний метод є дикторозалежним — для кожного диктора і окремих випадків необхідні свої параметри ɳ і gпор.
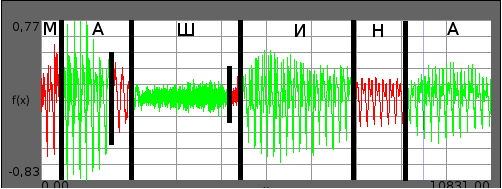
Рисунок 1 — Сегментація слова
машинаметодом кратномасштабного аналізу
Оскільки сегментація застосовується на записах цілих слів з апріорним знанням транскрипції, то це дозволяє орієнтуватися на необхідну кількість міток сегментів.
З метою вдосконалення алгоритму пропонується наступна модифікація:
- Підрахунок кількості необхідних міток сегментування N:
- Зміна параметрів ɳ і gпор в діапазонах [2.5; 4] та [0.4; 1] відповідно для формування вектора T, що задає усілякі унікальні мітки кордонів;
- Перевіряється виконання умови (1) в векторі Т:
- Якщо довжина вектора Т більше N, то формується вектор P, що описує швидкість зміни потужності спектра на межах:
- До тих пір, поки розмір вектора T більше N, з вектора T видаляються межі, відповідно яким елемент вектора P є мінімальним.
N = S - 1,
де S — кількість фонем в транскрипції слова.
T[i] - T[i+1] < 512, (1)
де T[i] — значення межі в i позиції вектора; T[i+1] — значення межі в такій позиції вектора.
Якщо умова (1) виконується, то межа T[i] покладається наступному значенню:
T[i] = (T[i]+T[i+1])/2
а значення мітки кордону T[i +1] видаляється з вектора T.
P[i] = |Fmax(j) - Fmax(j-1)| + |Fmax(j) - Fmax(j+1)|;
j=T[i]/256,
де j — це номер вікна в 256 відліків звукового сигналу для межі T[i]; Fmax (j) — максимальне значення спектра звукового сигналу в j вікні.
Таким чином величина P[i] характеризує швидкість зміни потужності спектра на межі T[i]. На дійсних межах величина P[i] має набагато більше значення ніж на несправжніх. Це пояснюється тим що на межфонемних переходах спектр буде відрізнятися, а під час промовляння окремої фонеми буде практично ідентичний на сусідніх вікнах.
Описаний алгоритм дозволяє незалежно від заданого диктора сформувати необхідну базу звуків для синтезатора мови.
5. Інтонаційні конструкції російської мови
Інтонаційна конструкція [13] — сукупність інтонаційних ознак, достатніх для диференціації значень висловлювань і передачі таких параметрів висловлювання, як комунікативний тип, смислова важливість складових його синтагм, актуальне членування.
У російській мові усього виділяється 7 інтонаційних конструкцій [12].
1. Перша інтонаційна конструкція (ІК–1, див. Рис. 2).
В доцентровій частини ІК–1 коливання тонів має восходяще-спадний напрям або зосереджений в середній смузі її діапазону. Голосна центру вимовляється з спадним рухом тону нижче рівня доцентрової частини. Позацентрова частина вимовляється нижче рівня доцентрової частини. ІК–1 вживається при оповіданні, в простих реченнях і в складнопідрядних реченнях з препозиції головної частини, синтаксично завершеною, що стоїть перед придаточною. Ця інтонаційна конструкція висловлює власне завершеність, в якій відсутній смислове протиставлення чи зіставлення.
Рисунок 2 — Перша інтонаційна конструкція
2. Друга інтонаційна конструкція (ІК–2, див. Рис 3).
В доцентровій частини коливання тонів зосереджені в середньо-верхній смузі її діапазону. Голосна центру вимовляється із спадним або рівним рухом тону в діапазоні доцентровій частини або нижче її, якщо центр знаходиться в кінці конструкції; рівень тону вище, ніж в ІК–1. Голосна центру характеризується, на відміну від ІК–1, посиленням словесного наголосу в порівнянні з іншими ударними складами. Позацентрова частина вимовляється на рівні тони нижче доцентровій. ІК–2 вживається при питанні, розповіді і волевиявленні. При вираженні питання ІК–2 вживається в пропозиціях з союзом або з питальними займенниками. У пропозиціях з займенниками широко використовується пересування центру ІК–2 як засобу смислового протиставлення. При оповіданні, як і при питанні, ІК–2 є засобом смислового виділення або протиставлення. ІК–2 вживається при зверненнях, вітаннях, в вигуках.
Рисунок 3 — Друга інтонаційна конструкція
3. Третя інтонаційна конструкція (ІК–3, див. рис 4).
В доцентровій частини ІК–3 коливання тони зосереджені в середній смузі її діапазону. Голосна центру вимовляється з висхідним рухом тону вище рівня доцентровій частини; в кінці гласного тон рівний або спадний. Позацентрова частина вимовляється на рівні тони нижче доцентровій. ІК–3 вживається при питанні, оповіданні, волевиявленні. Також ІК–3 вживається при власне питанні, при повторенні питання (у відповіді). В оповіданні ІК–3 в не кінцевої синтагмі сигналізує незавершеність висловлювання.
Рисунок 4 — Третя інтонаційна конструкція
4. Четверта інтонаційна конструкція (ІК–4, див. Рис 5).
В доцентровій частини ІК–4 коливання тони зосереджені в середньо-верхній смузі її діапазону або утворюють восходяще-спадний напрям. Голосна центру вимовляється на рівні тони нижче доцентровій частини; при цьому варіюється рівний, спадний, спадне-висхідне, висхідний напрями тону. Позацентрова частина вимовляється вище рівня центру та доцентровій частини. ІК–4 вживається при питанні, розповіді і волевиявленні. Також ІК–4 вживається при вираженні питання, який пов’язаний співставляючими відносинами з попереднім реченням. В оповіданні ІК–4, поряд з ІК-3, сигналізує про незавершеність висловлювання. ІК–4, на відміну від ІК–3, додає мові офіційність.
Рисунок 5 — Четверта інтонаційна конструкція.
5. П’ята інтонаційна конструкція (ІК–5, див. рис 6).
ІК–5, на відміну від інших інтонаційних конструкцій, має два центри, які слідують один за одним або роз’єднані кількома складами, тому ІК–5 можлива в реченні, що має мінімум два склади. В доцентровій частини коливання тони зосереджені в середньо-нижній смузі її діапазону. Голосна першого центру вимовляється з висхідним рухом тону вище рівня доцентровій частини. Тривалість приголосних і гласного центру збільшена в середньому в два рази в порівнянні з іншими ударними складами: за цей час можна вимовити ще один склад. Рівень тону між центрами вище в доцентровій частини, але нижче рівня першого центру. На гласному другого центру тон знижується. Обидва центру характеризуються також посиленням словесного наголосу. Позацентрова частина вимовляється нижче рівня доцентровій. ІК–5 вживається переважно при розповіді і частково при волевиявленні і питанні.
Рисунок 6 — П’ята інтонаційна конструкція
6. Шоста інтонаційна конструкція (ІК–6, див. Рис 7).
В доцентрової частини ІК–6 коливання тони зосереджені в середній смузі її діапазону. Гласний центру вимовляється з висхідним рухом тону вище рівня доцентрової частини. Більш високий рівень тону відрізняє ІК–6 від ІК–4. Позацентрова частина вимовляється вище рівня доцентрової частини. ІК–6 вживається переважно в оповіданні і частково в питанні. При оповіданні ІК–6, поряд з ІК–3 і ІК–4, сигналізує в не кінцевої синтагмі про незавершеність висловлювання. При цьому ІК–6 переважає в урочисто-піднятій мові.
Рисунок 7 — Шоста інтонаційна конструкція
7. Сьома інтонаційна конструкція (ІК–7, див. Рис 8).
В доцентровій частини ІК–7 коливання тони зосереджені в середній смузі її діапазону. Гласний центру вимовляється з висхідним рухом тону вище рівня доцентровій частини; гласний закінчується смичкою голосових зв’язок, і це відрізняє ІК–7 від ІК–3. В результаті смички відкритий склад стає закритим, а в закритому складі голосний сполучається з приголосною через артикуляцію смички. Смичка голосових зв’язок акустично сприймається як різка перерва звучання гласного і добре прослуховується в запереченні не-а
. У цьому запереченні дефіс показує розділення двох голосних смичним елементом. Позацентрова частина ІК–7 вимовляється на рівні тони нижче доцентровій. ІК–7 вживається в оповіданні. У пропозиціях з займенниковими словами, функціонуючими як частки, ІК–7 сигналізує неможливість або заперечення.
Рисунок 8 — Сьома інтонаційна конструкція
6. Огляд методів синтезу мовлення з інтонаційним забарвленням
6.1. Синтез інтонаційної складової мовного сигналу з застосуванням сплайнової інтерполяції
У даному підході [17] для синтезу мовного сигналу по компілятивному принципу необхідно попередньо отримати формалізований опис його фонетичних та інтонаційних властивостей. Для всіх фонем необхідно вказати інтонаційні характеристики. У їх число входить і множина опорних точок параметричних кривих. При цьому параметри сусідніх фонем повинні бути плавно узгоджені.
На рисунку 9 показані основні етапи синтезу мовного сигналу по компілятивному принципу із застосуванням гладких параметричних кривих заданих обмеженою множиною опорних точок.
Для досягнення якісного синтезу важливо плавно регулювати такі параметри мовного сигналу:
- Контур частоти основного тону — це головна інтонаційна складова мови.
- Амплітудні огинаючі, основним призначенням яких є динамічний регулювання амплітудного рівня сигналу. Спільне збільшення амплітуди і частоти сигналу призводить до збільшення його гучності.
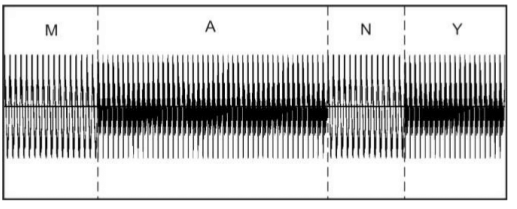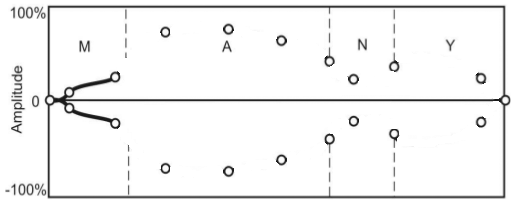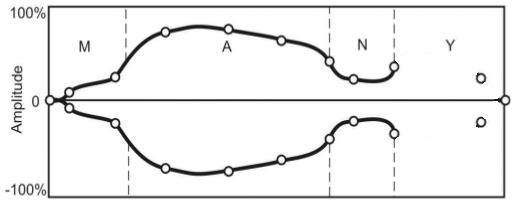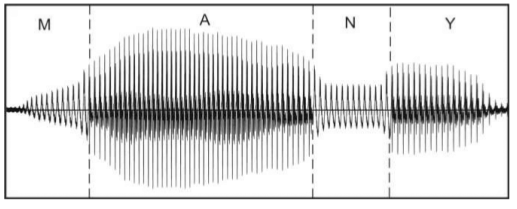
Рисунок 9 — Етапи накладення інтонаційної конструкції на мовний сигнал (анімація: 8 кадрів, 5 циклів повторення, 145 кілобайт)
При компілятивному синтезі [8] на основі базових фрагментів мови шляхом різних алгоритмічних маніпуляцій звуковому сигналу надають необхідну форму. Задана форма мовного сигналу може залежати від безлічі різних чинників: від мови, індивідуальних особливостей голосу, тексту, необхідної інтонації, швидкості і гучності вимови і т. д.
Заздалегідь підготовлений, нормалізований по тривалості фонем, загальному рівню амплітуд і плавно сполучений з різних фрагментів мовний сигнал подається на вхід системи регулювання параметрів. В залежності від необхідних інтонаційних характеристик формується контур частоти основного тону і накладається на вихідний мовної сигнал. Потім на сигнал накладаються амплітудні огинаючі.
Для завдання кривої виділяється обмежена кількість опорних точок. Вибирається їх оптимальне розташування так щоб найкращим чином апроксимувати вихідну функцію контрольованого параметра. Спочатку в якості опорних точок вибираються екстремуми апроксимованої функції.
6.2. Синтез монотонної і виразної мови методом Unit Selection
Інший підхід до синтезу мови з інтонаційним забарвленням методом Unit Selection описаний в статті [15]. В даний час цей підхід є найбільш поширеним [27]. Він заснований на генерації мовного сигналу шляхом конкатенації природних мовних відрізків, вибираних з мовної бази даних. Як правило, використовуються мовні відрізки, що відповідають окремим звукам або діфонам. Велика кількість елементів бази даних, що розрізняються спектральними і просодичними характеристиками, дозволяє синтезувати мову з високим ступенем природності. Чим більше об’єм мовної бази даних, тим з більшою вірогідністю в ній будуть знайдені необхідні для синтезу мовні відрізки і менше доведеться модифікувати синтезований сигнал, домагаючись необхідних значень тривалості, частота основного тону (F0) і плавних переходів від одного звуку до іншого. Відомо, що будь-яка модифікація мовного сигналу негативно позначається на якості його звучання.
Важливою складовою методу Unit Selection є алгоритм вибору елементів з бази даних. Проблема полягає в тому, що доводиться вирішувати, які критерії вибору важливіше: контекст, інтонація, тривалість і т.д. Оскільки збалансованість критеріїв не досягнута, а вибір здійснюється автоматично, процес синтезу мови іноді виходить з-під контролю
[28], і синтезована мова сприймається як неврівноважена
.
В системі синтезу української мови [16] використовується розроблений в МНУЦІТіС фонемно-трифонов метод синтезу мови в амплітудно-часової області, який є варіантом методу Unit Selection. Об’єднання методу синтезу до розроблених індивідуалізованими просодичними моделями дозволяє озвучувати тексти відповідно до обраних голосів і стилів читання.
Розроблена система синтезу індивідуалізованої української мови (рис. 10) складається з наступних компонентів: мовних баз даних, лінгвістичного процесора, модуля вибору елементів з мовної бази даних, акустичного процесора.
Мовні бази даних використовуються не тільки в процесі синтезу мови. Інформація, що міститься в їх анотаціях інформація служить для попереднього налаштування моделей вимови диктора. У процесі синтезу мови налаштований лінгвістичний процесор генерує фонемно-просодичну транскрипцію вхідного тексту у вигляді послідовності фонем з обчисленими просодичними характеристиками тривалості і інтонаційного контура.
Модуль вибору елементів з бази даних порівнює фонемно-просодичну транскрипцію вхідного тексту (тобто інформацію про те, що і як має синтезуватися) з анотацією бази даних (тобто з інформацією про те, який мовний матеріал є в наявності). Модуль вибору оцінює і вибирає елементи мовної бази даних відповідно до характеристиками, визначеними при аналізі тексту.
Вибрані елементи конкатенуються акустичним процесором і озвучуються акустичною системою.
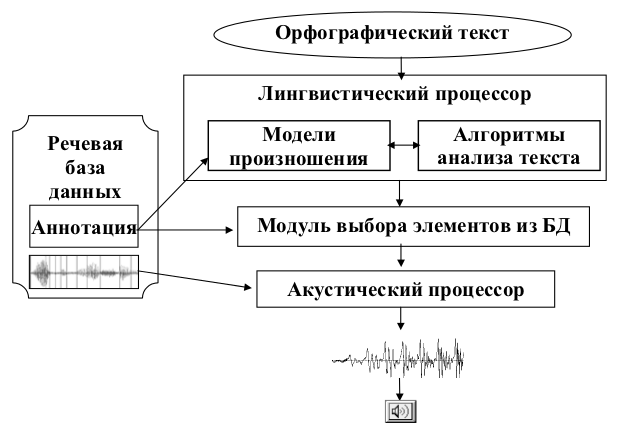
Рисунок 10 — Блок-схема системи синтезу української мови за текстом
Обчислення тривалості фонем здійснюється за допомогою моделі, параметрами якої є: середня тривалість фонеми (по анотації МБД), тип контексту, в якому вона знаходиться в синтезуємому висловлюванні, і набору коефіцієнтів тривалості для даної фонеми, відповідних типом контексту. У процесі синтезу мови тип контексту встановлюється з урахуванням комунікативного типу синтагми, наявності в синтагмі логічного наголосу, позиції фонеми по відношенню до початку/кінця синтагми, типу складу (відкритий, закритий) і сегментного типу безпосереднього лівого і правого оточення (з наголосом/без наголосу голосна, приголосні фонеми). Для обчислення тривалості фонеми її середня тривалість множиться на коефіцієнт, який відповідає типу контексту.
Модель інтонування використовується для обчислення інтонаційних контурів — послідовностей значень F0 протягом тексту. Модель базується на тому, що головною інтонаційною одиницею мови вважається синтагма — частина фрази, що має виражений інтонаційний контур. Синтагма складається з однієї або декількох акцентних груп. Акцентна група (акцентні одиниця) — це одне або кілька слів, об’єднаних загальним наголосом. Розроблена модель інтонування близька до моделі інтонаційних портретів акцентних одиниць, запропонованої Б.М. Лобановим [8].
Параметрами інтонаційної моделі є:
- комунікативний тип синтагми, який визначається в даний час по знаку пунктуації та деяким лексико-граматичними показниками (питальні слова, сполучники тощо);
- кількість акцентних груп в синтагмі;
- місце ядерної (головної) акцентної групи в синтагмі;
- набори цільових значень F0 для кожної акцентної групи.
У любій синтагмі обов’язково присутня ядерна акцентна група (АГ), що несе головний (синтагматичний) наголос. У загальному випадку, якщо в синтагмі два АГ, то перша з них є початковою, а друга — ядерною. Якщо акцентних груп три або більше, то перша з них є початковою, з другої по передостанню включно — пред’ядерною, остання — ядерна. Наявність логічного наголосу в синтагмі може зробити ядерною будь яку АГ, в цьому випадку усі АГ, наступні за ядерною, вважаються заядерними.
Кожен комунікативний тип синтагми має свій інтонаційний контур, що складається з інтонаційних контурів що входять до неї АГ. Кожна АГ синтагми складається з ядра — ударної гласною, пред’ядра — всіх фонем АГ, що знаходяться перед ударною гласною, і заядра — всіх фонем АГ, що знаходяться після ударної гласної. Головне припущення моделі інтонування полягає в тому, що топологічні властивості просодичних характеристик не змінюються (або змінюються незначно) зі змінами фонетичного контексту і числа фонем в пред- та заядрі АГ [8].
Контур АГ задається послідовністю 10 значень F0. Контур синтагми задається 10n значеннями F0, де n — кількість АГ в синтагмі. Інтонаційні контури акцентних груп синтагми накладаються
на їх фонемні транскрипції, кожне з 10 цільових значень F0 приписується відповідним цільовим точкам АГ. Перші два з 10 цільових значень F0 задають рух F0 на пред’ядре АГ; значення F0 з 3 по 8 задають зміну F0 на ядрі (ударною гласною); останні два значення F0 описують рух F0 на заядрі АГ.
Висновки
Синтез мови є актуальною задачею. На момент написання даного реферату отримані наступні результати:
- розроблено алгоритм сегментації мовного сигналу для автоматизованого наповнення бази звуків синтезатора;
- розглянуті інтонаційні конструкції російської мови;
- розглянуті існуючі підходи до створення інтонаційного забарвлення.
Подальші дослідження спрямовані на наступні аспекти:
- визначення інтонаційної конструкції тексту;
- приведення мовного сигналу до заданого мелодійного контуру.
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2012 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.
Перелік посилань
- Сорокин В.К. Синтез речи / Сорокин В.К. — М. : Наука, 1992. — 392 с.
- Вишнякова О.А. Автоматическая сегментация речевого сигнала на базе дискретного вейвлет-преобразования / О.А. Вишнякова, Д.Н. Лавров // Математические структуры и моделирование — 2011, — Выпуск 23. С. 43–48.
- Давыдов А.Г. Использование периодичности речевого сигнала при фонемной сегментации речи / А.Г. Давыдов, Б.М. Лобанов // Доклады Белорусского государственного университета информатики и радиоэлектроники, № 2, 2006. — С. 69–74.
- Колоков А.С. Предварительная обработка и сегментация речевого сигнала в частотной области для распознавания речи / Колоков А.С. // Автоматика и телемеханика, № 6, 2003. — С. 152–162.
- Д. Фланаган Анализ, синтез и восприятие речи / Д. Фланаган — М. : Связь, 1968. — 395 с.
- Фант Г. Анализ и синтез речи / Фант Г. — Новосибирск : Наука, 1970 — 167 с.
- Фант Г. Акустическая теория речеобразования / Фант Г. — М : Наука, 1964. — 329 с.
- Лобанов Б.М. Компьютерный синтез и клонирование речи / Б.М. Лобанов, Л.И. Цирульник — Минск : Белорусская наука, 2008. — 316 с.
- Буланин Л.Л. Фонетика современного русского языка / Буланин Л.Л. — М. : Высшая школа, 1970. — 208 с.
- Бондарко Л.Б. Звуковой строй современного русского языка. / Бондарко Л.Б. — М. : Просвещение, 1977. — 175 с.
- Бондарко Л.В. Фонетическое описание языка и фонологическое описание речи / Бондарко Л.В. — Л. : ЛГУ, 1981. — 199 с.
- Брызгунова Е. А. Интонация. Русская грамматика / Брызгунова Е. А. — М. : Наука, 1980. — 378 с.
- Пешковский А.М. Интонация и грамматика. / Пешковский А.М. — М. : Избр. Труды, 1959. — 247 с.
- Цеплитис Л.К. Анализ речевой интонации / Цеплитис Л.К. — Рига : Зинтарис, 1974. — 270 с.
- Людовик Т.В. Автоматический синтез нейтральной и выразительной речи / Людовик Т.В. // Искусственный интеллект, № 1, 2010. — С. 9-02.
- Lyudovyk T. Unit Selection Speech Synthesis Using Phonetic-Prosodic Description of Speech Databases / Lyudovyk T., Sazhok M. // Proceedings of the International Conference
Speech and Computer
(SPECOM’2004). — St.-Petersburg (Russia), 2004. — Р. 594-599. - Калимолдаев М.Н. Синтез интонационной составляющей речевого сигнала с применением сплайновой интерполяции / М.Н. Калимолдаев, Е.Н. Амиргаливев, Р.Р Мусабаев [Электронный ресурс]. — Режим доступа : http://conf.nsc.ru/files/conferences/MIT-2011/fulltext/58039/58041/Калимолдаев_Статья.pdf
- Ермоленко Т.В. Алгоритмы сегментации с применением быстрого вейвлет-преобразования [Электронный ресурс]. — Режим доступа : http://www.dialog-21.ru/Archive/2003/Ermolenko.htm
- Ермоленко Т.В. Классификация фреймов речевого сигнала в задачах дикторонезависимого распознавания речи / Т.В. Ермоленко, А.В. Жук // Искусственный интеллект. — 2011. — № 3 — C. 152–161.
- Сорокин В.Н. Сегментация и распознавание гласных / В.Н. Сорокин, А.И. Цыплихин // Информационные процессы. — 2004. — Т. 4, № 2. — С. 20-04.
- Сергиенко А. Б. Цифровая обработка сигналов / Сергиенко А. Б. — СПб : Питер, 2006. — 751 с.
- Р. Лайонс Цифровая обработка сигналов / Р Лайонс — М : Бином-Пресс, 2011. — 654 с.
- Э. Айфичер Цифровая обработка сигналов. Практический подход / Э. Айфичер, Б. Джервис — М : Вильямс, 2004. — 992 с.
- Умняшкин С.В. Теоретические основы цифровой обработки и представления сигналов / Умняшкин С.В. — М : Форум, 2007. — 304 с.
- Дремин И.М. Вейвлеты и их использование / И.М. Дремин, О.В. Иванов, В.А. Нечитайло // Успехи физических наук. — 2001. — Т. 171, № 5. — С. 465-500.
- Taylor P. Text to Speech Synthesis / University of Cambridge, — 2007. 597 pp.
- Hunt A. Unit selection in a concatenative speech synthesis system using a large speech database / Hunt A., Black A. // Proceedings of the International Conf. on Acoustics, Speech, and Signal Processing. — Atlanta (USA), 1996. — Vol. 1. — P. 373-376.
- Perspective on the Next Challenges for TTS Research / [Schroeter J., Conkie A., Syrdal A. и др.] // Proceedings of the IEEE Workshop on Speech Synthesis. — 2002. — P. 211-214.