Автоматический синтез нейтральной и выразительной речи
Автор: Людовик Т.В.
Источник: Труды международной конференции Диалог 2006
|
Назад в библиотеку
Автоматический синтез нейтральной и выразительной речиАвтор: Людовик Т.В. АннотацияВ интеллектуальных приложениях, использующих речевые технологии, синтезированная речь должна звучать естественно и выразительно. В статье описана разработанная технология синтеза речи, обеспечивающая озвучивание произвольных орфографических текстов на украинском языке в нейтральном и выразительном стилях с сохранением индивидуальных особенностей голоса и произношения. Основное внимание уделено просодической модели интонирования, используемой для синтеза речи с нейтральной и выразительной интонацией. ВведениеТехнология автоматического синтеза речи по тексту (TTS, Тext-to-Speech) позволяет передавать голосовую информацию от компьютера к человеку, преобразовывая произвольный орфографический текст в звучащую речь. К современным системам синтеза речи (TTS-системам) предъявляются требования разборчивости и естественности (натуральности) звучания. Разборчивость подразумевает правильное распознавание человеком всех слов синтезированной речи. Большинство современных TTS-систем демонстрируют хорошую разборчивость, приближающуюся к разборчивости естественной речи. В то же время практика показывает, что разборчивая, но неестественно звучащая речь не удовлетворяет требованиям пользователей. Естественность синтезированной речи оценивается по тому, насколько она похожа на речь живого человека, насколько она выразительна и насколько в ней отражены индивидуальные особенности голоса и произношения. Индивидуальность естественной речи проявляется как в физиологических особенностях голоса, так и в приобретенных привычках произношения. Под выразительностью речи понимается выражение отношения читающего текст к содержанию этого текста и к аудитории. Как правило, стиль и смысл текста диктуют выбор стиля речи. В выразительной речи подчеркнуты отдельные слова, выделены паузами определенные участки текста и т.д. Между нейтральной и выразительной речью нет четких границ, речь может идти о различной степени выразительности. Эмоциональность речи связана с состоянием говорящего. Характеризуя в основном спонтанную речь, при чтении вслух эмоциональность, как правило, имитируется, добавляя выразительности. В большинстве приложений, не требующих интерактивного взаимодействия человека с компьютером, уместна нейтрально звучащая синтезированная речь (озвучивание новостной, навигационной, деловой информации). Более выразительная речь необходима для озвучивания художественной литературы и в ситуациях живого общения человека с компьютером: в интерактивных образовательных программах, играх, в разговоре с роботами-собеседниками. В этих и иных интерактивных приложениях, таких как автоматизация работы call-центров, внимание в основном уделяется проблеме распознавания речи и эмоций. Однако адекватный синтез речи дружелюбным, уместно жизнерадостным или сочувственным голосом также играет большую роль. Выразительная речь компьютера стимулирует пользователя поддерживать с ним взаимодействие. Крупные фирмы, работающие в области синтеза речи, активно разрабатывают и рекламируют Синтез нейтральной и выразительной речи методом Unit SelectionРазличие между нейтральным и выразительным стилями чтения проявляется в основном на уровне просодики — интонации, ритмики, паузации, темпа произнесения текста и его отдельных частей, а также степени ударения отдельных слов и слогов. В речевом сигнале просодическим характеристикам соответствуют акустические характеристики: частота основного тона (fundamental frequency, F0), длительность и интенсивность (амплитуда). Исследования, посвященные синтезу выразительной речи, можно разделить на несколько направлений: синтез речи в определенном стиле [1], синтез эмоциональной речи [2], синтез эмфатической речи (с логическим выделением отдельных слов) [3], синтез характерной речи (с признаками индивидуальных особенностей характера) [4]. Объединяет эти исследования то, что в обязательном порядке моделируются интонация (контур F0), а также длительность звуков и пауз. Тестирование синтезированной речи [5] показало, что спектральные характеристики, в отличие от просодических, менее важны. В настоящее время наиболее распространенным методом синтеза речи является метод Unit Selection [6], основанный на генерации речевого сигнала путем конкатенации естественных речевых отрезков, выбираемых из речевой базы данных. В речевой базе данных, содержащей отрезки речи конкретного диктора и имеющей большой объем (5 — 15 часов акустических записей), отражаются как особенности голоса этого диктора, так и используемый им стиль чтения. Как правило, используются речевые отрезки, соответствующие отдельным звукам или дифонам (участкам речи от середины одного звука до середины следующего). Большое количество элементов (units) базы данных, различающихся спектральными и просодическими характеристиками, позволяет синтезировать речь с высокой степенью естественности. Чем больше объем речевой базы данных, тем с большей вероятностью в ней будут найдены необходимые для синтеза речевые отрезки и меньше придется модифицировать синтезированный сигнал, добиваясь необходимых значений длительности, F0 и плавных переходов от одного звука к другому. Известно, что любая модификация речевого сигнала отрицательно сказывается на качестве его звучания. Речь, синтезируемая методом Unit Selection, сохраняет индивидуальные особенности голоса и произношения диктора. Важной составляющей метода Unit Selection является алгоритм выбора элементов из базы данных. Проблема состоит в том, что приходится решать, какие критерии выбора важнее: контекст, интонация, длительность и т.д. Поскольку сбалансированность критериев не достигнута, а выбор осуществляется автоматически, процесс синтеза речи иногда Теоретически существует три способа, не отказываясь от метода Unit Selection, обеспечивающего естественное звучание, синтезировать речь в различных стилях:
Более перспективными представляются второй и третий, наименее трудоемкий, подходы. Цель исследованияЦелью данной работы является разработка технологии синтеза речи, обеспечивающей озвучивание произвольных орфографических текстов на украинском языке в нейтральном и выразительном стилях с сохранением индивидуальных особенностей голоса и произношения. Основное внимание уделено разработке просодической модели интонирования, позволяющей синтезировать речь с нейтральной и выразительной интонацией. Синтез украинской нейтральной и выразительной речи по текстуВ системе синтеза украинской речи [8] используется разработанный в МНУЦИТиС фонемно-трифонный метод синтеза речи в амплитудно-временной области, являющийся вариантом метода Unit Selection. Объединение метода синтеза с разработанными индивидуализированными просодическими моделями позволяет озвучивать тексты в соответствии с выбранными голосами и стилями чтения. Разработанная система синтеза индивидуализированной украинской речи (рис. 1) состоит из следующих компонентов:
Речевые базы данных используются не только в процессе синтеза речи. Содержащаяся в их аннотациях информация служит для предварительной настройки моделей произношения диктора. В процессе синтеза речи настроенный лингвистический процессор генерирует фонемно-просодическую транскрипцию входного текста в виде последовательности фонем с вычисленными просодическими характеристиками длительности и интонационного контура. 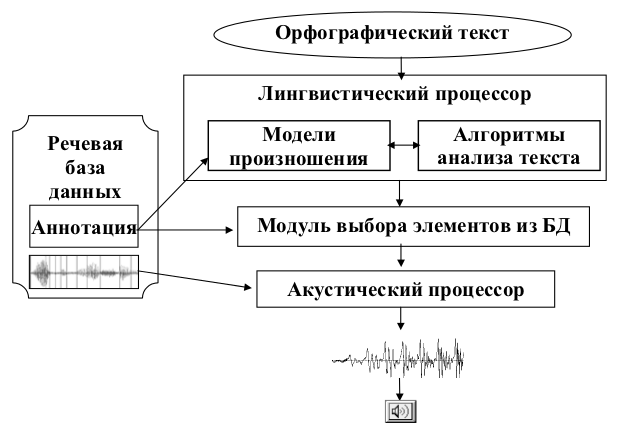
Рисунок 1 — Блок-схема системы синтеза украинской речи по тексту Модуль выбора элементов из базы данных сравнивает фонемно-просодическую транскрипцию входного текста (то есть информацию о том, что и как должно синтезироваться) с аннотацией базы данных (то есть с информацией о том, какой речевой материал имеется в наличии). Модуль выбора оценивает и выбирает элементы речевой базы данных в соответствии с характеристиками, определенными при анализе текста. Выбранные элементы конкатенируются акустическим процессором и озвучиваются акустической системой. Речевые базы данныхКачество синтезированной речи зависит от объема и покрытия речевой базы данных (РБД), то есть от того, насколько полно в ней представлены звуковые, темпоральные и интонационные варианты речевых единиц. Элементами РБД являются аллофоны (фонемы-трифоны), то есть фонемы в сегментном контексте, указывающем, какие фонемы находятся в речевом сигнале слева и справа от данной фонемы. Каждый элемент аннотирован идентификатором, именем, состоящим из трех частей (имя предыдущей, текущей и последующей фонемы), длительностью, значениями интенсивности, для гласных и звонких согласных также последовательностью длин периодов основного тона и количеством периодов. На данный момент разработаны 7 РБД: 4 мужских голоса, 2 женских и 1 детский (табл. 1). Наименее естественно звучит речь, синтезируемая на основе РБД, состоящей из прочитанного диктором словаря объемом около 300 слов. Разборчивость такой речи, тем не менее, довольно высокая благодаря тому, что в словаре представлены все фонемы украинского языка в наиболее часто встречающихся контекстах. Наиболее естественно звучит речь, синтезируемая с использованием РБД, разработанной на основе текстов различных типов. РБД диктора НАТАЛКИ содержит речь различных стилей чтения, что позволяет синтезировать речь в дипазоне от наиболее нейтральной (прогноз погоды) до наиболее выразительной (диалоги).
Таблица 1 — Речевые базы данных, используемые в системе синтеза украинской речи
Лингвистический анализВ процессе лингвистического анализа входного текста задействованы дикторонезависимые алгоритмы обработки текста и дикторозависимые модели произношения. Для настраивания моделей используются аннотации индивидуальных РБД. Учитывается, как диктор произносит те или иные звукосочетания (ассимиляция, редукция), где ставит ударения (например, Модель длительности фонемВычисление длительности фонем осуществляется с помощью модели, параметрами которой являются: средняя длительность фонемы (по аннотации РБД), тип контекста, в котором она находится в синтезируемом высказывании, и набора коэффициентов длительности для данной фонемы, соответствующих типу контекста. В процессе синтеза речи тип контекста устанавливается с учетом коммуникативного типа синтагмы, наличия в синтагме логического ударения, позиции фонемы по отношению к началу/концу синтагмы, типа слога (открытый, закрытый) и сегментного типа непосредственного левого и правого окружения (ударная/безударная гласная, согласная фонемы). Для вычисления длительности фонемы ее средняя длительность умножается на коэффициент, соответствующий типу контекста. Модель длительности фонем индивидуализируется автоматически. Модель интонированияМодель интонирования используется для вычисления интонационных контуров — последовательностей значений F0 на протяжении текста. Модель основана на том, что главной интонационной единицей речи считается синтагма — часть фразы, имеющая выраженный интонационный контур. Синтагма состоит из одной или нескольких акцентных групп. Акцентная группа (акцентная единица) — это одно или несколько слов, объединенных общим ударением. Разработанная модель интонирования близка к модели интонационных портретов акцентных единиц, предложенной Б.М. Лобановым [9]. Параметрами интонационной модели являются:
В любой синтагме обязательно присутствует ядерная акцентная группа (АГ), несущая главное (синтагматическое) ударение. В общем случае, если в синтагме две АГ, то первая из них является начальной, а вторая — ядерной. Если акцентных групп три или больше, то первая из них является начальной, со второй по предпоследнюю включительно — предъядерной, последняя — ядерной. Наличие логического ударения в синтагме может сделать ядерной любую АГ, в этом случае все АГ, следующие за ядерной, считаются заядерными. Каждый коммуникативный тип синтагмы имеет свой интонационный контур, состоящий из интонационных контуров входящих в нее АГ. Каждая АГ синтагмы состоит из ядра — ударной гласной, предъядра — всех фонем АГ, находящихся перед ударной гласной, и заядра — всех фонем АГ, находящихся после ударной гласной. Главное предположение модели интонирования состоит в том, что топологические свойства просодических характеристик не изменяются (или изменяются незначительно) с изменениями фонетического контекста и числа фонем в предъ- и заядре АГ [9]. Контур АГ задается последовательностью 10 значений F0. Контур синтагмы задается 10n значениями F0, где n — количество АГ в синтагме. Интонационные контуры акцентных групп синтагмы На первом этапе индивидуализации проводится классификация синтагм, произнесенных диктором и хранящихся в РБД, по их коммуникативному типу (КТ). Минимальный набор учитываемых коммуникативных типов: завершенность ( Синтагмы выделяются в автоматизированном режиме с последующим аудитивным и визуальным контролем. Далее проводится классификация синтагм в рамках одного КТ по количеству АГ и месту ядерной АГ. Каждый подтип имеет название, состоящее из трех частей: кода КТ, количества АГ и места ядерной АГ в синтагме, например, Z-3–2 (завершенный тип, три АГ в синтагме, вторая АГ является ядерной). На следующем этапе индивидуализации модели интонирования проводится стилизация (упрощение) интонационных контуров синтагм с помощью программных средств обработки интонационной части аннотаций РБД. Стилизация осуществляется в соответствии с описанной моделью интонирования: определяются значения F0 в целевых точках акцентных групп синтагмы: для каждой АГ определяются два значения на предъядре, шесть значений на ядре и два значения на заядре. Результаты стилизации удобно представлять в виде таблиц и графиков, где на оси абсцисс отложены целевые точки АГ (A(1,1), A(1,2), ... A(n,9), A(n,10), где n — количество АГ в синтагме), а на оси ординат — целевые значения F0 в Гц. Стилизация дает возможность сравнивать интонационные контуры синтагм различного сегментного (фонемного) состава, а также интонационные контуры разных дикторов. На рис. 2 приведены стилизованные интонационные контуры синтагмы завершенного типа Особенности произношения проявляются в том, что дикторы по-разному интерпретируют одну и ту же фразу: РУСЛАН и АЛЕКСАНДР произносят нейтрально (движение F0 восходящее — восходящее — нисходящее у АЛЕКСАНДРА и восходящее — ровное — нисходящее у РУСЛАНА), а СВЯТОСЛАВ и МАКСИМ выделяют слово 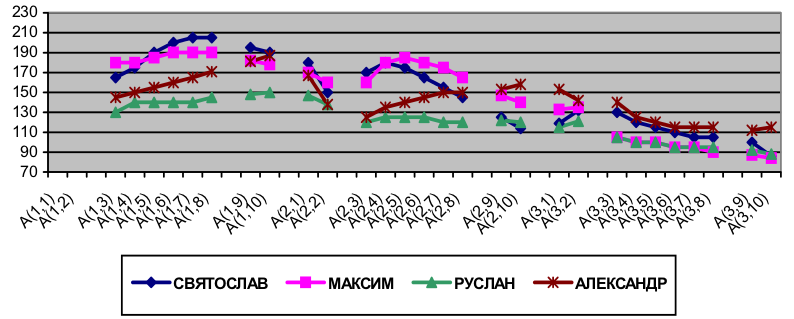
Рисунок 2 — Стилизованные интонационные контуры синтагмы завершенного типа Скоро всю землю розгородимо.в произнесении четырех дикторов Выразительность речи связана не только с переносом ядерной АГ с конца синтагмы. Как правило, выразительный характер синтагмы проявляется в более широком диапазоне F0 всей синтагмы или ее отдельных АГ по сравнению с нейтральной речью. На рис. 3 приведены интонационные контуры нейтрально прочитанной диктором НАТАЛКОЙ синтагмы завершенного типа Z-3–3 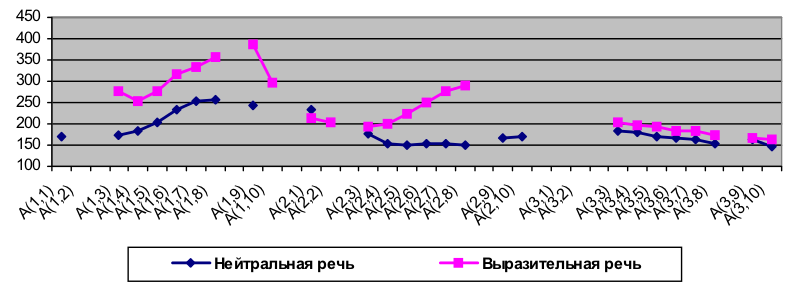
Рисунок 3 — Интонационные контуры нейтральной и выразительной речи диктора НАТАЛКИ Рис. 4 свидетельствует о вариативности речи одного и того же диктора. Интонационные контуры одного подтипа в произнесении одного диктора различаются уровнем и диапазоном и направлением движения F0 на начальной и предъядерной АГ, однако общим для всех приведенных контуров является восходящее движение F0 на ядерной АГ, что и позволяет воспринимать интонацию синтагмы как незавершенную. После распределения всех синтагм РБД диктора по коммуникативным подтипам, классификации синтагм в соответствии с нейтральным/выразительным стилем и стилизации интонационных контуров синтагм выводится интонационная модель данного диктора. Это происходит либо путем усреднения значений F0 в целевых точках синтагмы, либо в качестве модельного контура синтагмы эмпирическим путем выбирается один из стилизованных контуров. 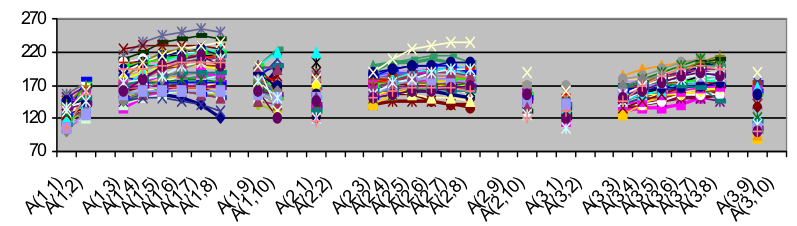
Рисунок 4 — Стилизованные интонационные контуры синтагм подтипа незавершенности N-3-3 в произнесении диктора СВЯТОСЛАВА Множество модельных интонационных контуров диктора, репрезентирующих все коммуникативные подтипы и стили (нейтральный и выразительный), представ- ляет собой индивидуализированную модель интонации этого диктора. На рис. 5 приведены модельные интонационные контуры синтагмы нейтральной завершенности подтипа Z-3-3 в произнесении двух дикторов. Приведенные контуры нормированы: ось ординат соответствует не абсолютным, а нормированным значениям F0. Нормированное значение 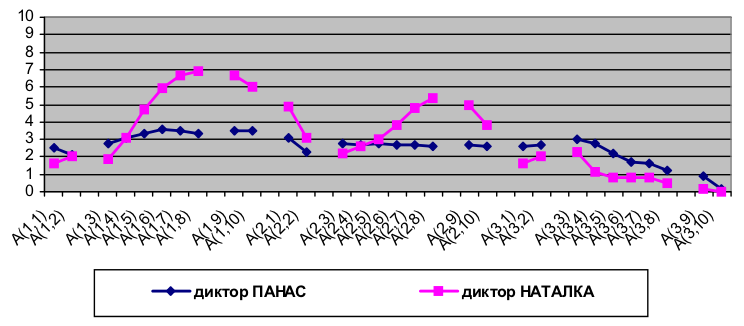
Рисунок 5 — Модельные интонационные контуры завершенности подтипа Z-3-3 дикторов ПАНАСА и НАТАЛКИ В процессе синтеза речи индивидуализированные модели интонации используются лингвистическим процессором для интонирования входного орфографического текста. Решение о том, контур какого коммуникативного подтипа выбирать для озвучивания синтагмы в процессе синтеза речи, принимается с учетом знака пунктуации и количества акцентно-ударных гласных в синтагме после ее вычленения в тексте. По умолчанию ядерной считается последняя акцентная группа синтагмы. Однако пользователю системы синтеза речи предоставляется возможность при вводе текста обозначать логическое выделение особым знаком логического ударения. Результаты тестирования синтезированной речиБыло проведено формальное тестирование образцов синтезированной речи с целью определить, какой из голосов, ПАНАС или НАТАЛКА, звучит естественнее. В частности, обоими голосами были озвучены отрывки из художественного, публицистического и научного текстов, а также тексты 33 SMS-сообщений. В тестировании методом средней оценки (MOS, mean opinion score) [10] участвовали сотрудники МНУЦИТиС (5 человек), а также преподаватели и студенты специальности 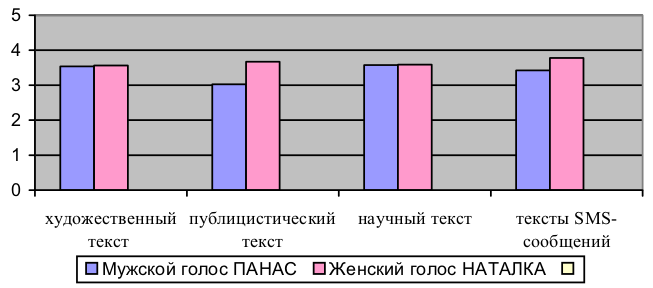
Рисунок 6 — Результаты тестирования естественности синтезированной речи Обе группы аудиторов отдали незначительное предпочтение женскому голосу НАТАЛКА. Наименьшее различие (0,01 балла) наблюдается в оценке научного текста. Это может быть объяснено тем, что научный стиль не требует выразительного чтения, присущего НАТАЛКЕ, а строгость этого стиля в большей степени ассоциируется с мужским голосом. Незначительное различие (0,03 балла) в оценке художественного текста может быть объяснено тем, что желательная выразительность женского голоса нивелируется недостаточной степенью контроля над просодикой при выборе единиц конкатенации, в результате чего нарушается восприятие тонких смысловых связей, присущих художественным текстам. Предпочтение женского выразительного, хотя и более ВыводыСинтезированная речь может считаться качественной, если она не только разборчива, но и звучит естественно. Естественность синтезированной речи связана с ее выразительностью и отображением индивидуальных особенностей произношения. Разработанная технология синтеза речи решает проблему индивидуализации и стиля чтения (нейтральный/выразительный) благодаря предварительному настраиванию системы синтеза речи. Тестирование системы синтеза украинской речи независимыми экспертами дало положительные результаты. Литература
|