
Abstract
Content
- Purpose and tasks
- The relevance of the research topic
- The scientific novelty
- Expected practical results
- A review of research and development on the subject. Global level
- A review of research and development on the subject. National level
- A summary of the results of their own
- Conclusion
- References
Purpose and tasks
The main goal of master's
work is to improve the efficiency of testing systems. The development component
semantic models of natural language answers analyze is the basis for this.
To achieve this purpose
it is necessary to solve the following tasks:
- An analyze the
semantic analysis techniques of sentences and natural language text models;
- Analyze the
principles of natural-language communication in testing systems;
- To develop a
component model questions and answers;
- To develop
algorithms and software for knowledge testing system in a given subject area;
- To conduct an
experimental test of results.
The relevance of the research topic
At present, the testing system based on modifications of the choice the correct answer from the proposed set. This is a significant limitation of testing systems. On the one hand, we can guess the answer, on the other hand, the amount of tested knowledge is limited. Entry the answer would avoid guessing, increase flexibility and diversity of questions and the objectively of the answers estimate. Therefore, the use of natural language text analysis in testing systems is important.
The
scientific novelty
-
The improving method of the component analysis model is
proposed.
-
An algorithm that carries out a non direct search for
meaning in the text is proposed.
-
The estimation criterion of the reliability natural
language answers is proposed.
Expected practical results
The main expected
results is development of a new semantic model for the analyze
of natural language utterance, which can be used in knowledge testing systems.
This model will be
implemented as a software package and used by the cathedra, "Artificial
Intelligence Systems" in
Interaction with
the model will be implemented through a user interface that displays the
knowledge level of the testing user.
A review of research and development on the subject. Global level
Currently,
the development of many models of linguistic analyzer. These models are
able to perform the analysis of natural language text, to determine the meaning
and generate statements, within certain limits. But this approach of modeling
the communication process is very diverse. The main difference between these
approaches lie in the methods of the component implementation understanding the
meaning, analysis tools, as well as the extent and methods of knowledge
representation.
Currently,
can highlight such models of selection and presentation of meaning: a component
analysis, a network of conceptualizations, meaning identification of the
pattern, an integrated approach (look draw 1).
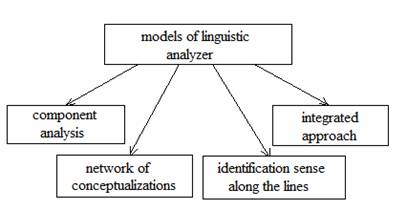
Draw
1 – models of linguistic analyzer.
Component approach
is based on the premise that the semantics of natural languages
can be expressed in terms of a semantic factor set (atoms of the
meaning). In reviewing the words stand out features (animate, inanimate and so
on), which divide the word into separate groups. The best known representative
of this trend is Charles Fillmore [3].
The basis of the
semantic representation of the model of "conceptual dependency" (R.
Schenk [4]) is a network of conceptualizations. The network conceptualizations
are kvazigraf similar marked up oriented graph, in
which, except for binary relations, present ternary and kvarnarnye,
and the arcs are connected not only to the top, but the other arc.
In the model
identification of the pattern meaning (Wilks), the
text is characterized by the following entities: the meaning of words,
messages, text fragments, and semantic interoperability. For each word, which
is part of a piece of text can be selected by one of the meanings of words,
whereby ambiguity is removed.
Model of an
integrated approach, (I. Mel'chuk [12]) is a
multi-layered transformer meanings in the text and
vice versa. There are four basic levels: phonetic, morphological, syntactic and
problematic. Each of them, except the problematic is divided into two other
levels - superficial and deep.
A review of research and development on the subject. National level
Among the works of
Ukrainian scientists in this field, an important contribution was made Svyatogor L. [11] and Gladun V.
[8]. In their paper offers an expanded interpretation of "natural language
text." In addition, this work contains a complete scheme of development of
the semantic resources of language due to "computer meaning" and the
dialogue. In this article means of achieving this purpose in the process of
semantic word processing is presented. Word Processing is performed by using a three-level ontology to extract from the text the
ontological sense. It is also proposed putting additional feedback to refine
the content through dialogue.
A summary of the results of their own
Further development
was chosen model-case Charles Fillmore [3]. A deep review of the model, allowed
to come to the conclusion that it can be expanded and
applied to complex in natural language sentences. These proposals are answers
to questions-definitions in the knowledge testing systems. This
model remain valid only within a certain domain. This limitation ensures
the absence of ambiguity in obtaining the semantic content of the text answers
in testing systems.
The ideas of the research
included in proceeding of the international scientific-technical conference of
students and young scientists 16 April 2012, and the international
scientific-practical conference of young scientists April 21 2012, Donetsk.
Conclusion
In research of
existing semantic analysis models of natural language text, highlighted the
following ways to get meaning: component analysis, a network of
conceptualizations, identification meaning on the pattern, an integrated
approach. To date, these models are only able to partially extract knowledge
from a given text and to construct correct sentences of natural language for
given meaning; to paraphrase these sentences, evaluate them in terms of
connectivity and perform other tasks. However, sphere of their application is very
narrow.
The use of such models
in the knowledge testing systems was showed that the basis for the analysis of
the text is splitting it into separate fixed lexical units. At the same time,
these units have a formative elements, which
complicates the analysis. Identification of these lexical units in the text and
handling them is the basis for text analyze.
The application
component model for the implementation of knowledge testing has the greatest
prospects. Despite the limitations, this model can be improved. This will allow
to process complex sentences that are answer-definitions in natural language.
The disadvantage is
the limitation of testing a subject area and the types of questions. This
restriction is necessary for eliminate ambiguity, the extraction of meaning
from the answers.
References
1.
Manning C.D. Foundation of ststustical nature language
processing / C.D. Manning. – 1992. – Vol.12, N 4. –
P.89-94.
2.
Воропаев
А.С. Эволюция
вычислительных машин [Электронный ресурс].
– Режим доступа: http://www.snkey.net/books/samxp/ch1-1.html
3.
Filmor C. Frames and the semantics of understanding /
C. Filmor // Quaderni di semantica.Vol 4 / 2 December 1985 – p.
222-254
4.
Shank R. Conceptual information processing / R. Shank
– Norh-
5. Святогор Л. Семантический анализ текстов естесственного языка: цели и средства / Л. Святогор, В. Гладун // XV th International Conference “Knowledge-Dialogue-Solution” KDS-2 2009, Киев, Украина, Октябрь, 2009.
6.
Палагин
А. К анализу
естественно-языковых объектов / А. Палагин, С. Крывый, В. Величко, Н.
Петренко
// International Book Series, Number 9. Intelligent Processing.
Supplement to the
International Journal “Information Technologies &
Knowledge” Volume 3 /
2009. – ITHEA,
7.
Кибрик
А.Е. Семантическая проблематика
гетерологического кодирования / А.Е. Кибрик – М.: Наука 1965.
– С. 67-83
8.
Гладун
В. Структурирование
онтологии ассоциаций для конспектирования естественно–языковых
текстов / В. Гладун,
В. Величко, Л. Святогор // International Book Series, Number 2. Advanced Research in
Artificial Intelligence. Supplement to the International Journal
“Information
Technologies & Knowledge” Volume 2 / 2008. – ITHEA,
9.
Поспелов
Г.С. Искусственный интеллект – основа новой
информационной технологии / Г.С. Поспелов – М.: Наука, 1988.
– 279 с.
10.
Гаврилова
Т.А. Базы знаний интеллектуальных
систем / Т.А. Гаврилова, В.Ф. Хорошевский – СПб.: Питер, 2001.
– 384 с.
11.
Святогор
Л.
Определение понятия «Смысл» через онтологию. Семантический
анализ текстов естественного
языка. / Л. Святогор, В. Гладун // International Book Series, Number 9. Intelligent
Processing. Supplement to the International Journal “Information
Technologies
& Knowledge” Volume 3 / 2009. – ITHEA,
12. Мельчук И.А. Опыт теории
лингвистических моделей «Смысл – Текст» / И.А.
Мельчук – М.: Школа «Языки русской
культуры», 1999. – 346 с.
13. Лукьяненко С.А., Бессонов А.В., Казакова
Е.И. Моделирование
семантики естественно языковых высказываний в автоматизированных
информационных
системах [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2006/fema/lukyanenko/library/art03.htm