
Реферат за темою випускної роботи
Зміст
- Мета та задачi
- Актуальність теми
- Планована наукова новiзна
- Плануемi практичнi результати
- Огляд дослiдженнь i розробок iз теми. Глобальний рiвень
- Огляд дослiдженнь i розробок iз теми. Нацiональний рiвень
- Огляд дослiдженнь i розробок iз теми. Локальний рiвень
- Короткий виклад власних результатiв
- Висновки
- Список використанних джерел
Мета та задачi
Основною метою даної магістерської роботи є
розробка
семантичної моделі розпізнавання природно-мовних речень в системах
тестування.
Для виконання поставленої мети виділено наступні завдання:
- Аналіз принципів обробки тексту;
- Аналіз iснуючих семантичних моделей;
- Аналiз принципiв
природно-мовного спiлкування в системах тестування;
- Розробка алгоритмiв та программного
забеспечення для систем тестування знаннь у заданiй предметнiй областi;
- Проведення перевiрки отриманних результатiв.
Актуальнiсть теми дослiдження
Наприкінці 60-х років у
дослідженнях зі штучного інтелекту
сформувався самостійний напрямок, який одержав назву «обробка
природної мови» (Natural Language Processing) [1]. Завданням даного напрямку є дослідження
методів та розробка систем, що забезпечують реалізацію процесу
спілкування з
комп'ютерними системами природною мовою
(систем природно-мовного
(ПМ) – спілкування
або ПМ-систем).
Проблема взаємодії людини з комп'ютером існує
з
моменту появи обчислювальної техніки. На початковому етапі безпосередню
взаємодію з електронною обчислювальною
машиною (ЕОМ)
здійснювали тільки програмісти [2]. У міру
розширення сфери використання
комп'ютера та збільшення масштабів їх застосування кінцеві користувачі
стали
втягуватися в процес безпосередньої взаємодії з комп'ютером, що
призвело до
появи масової категорії користувачів – прямих
кінцевих користувачів, що працюють в діалоговому
режимі.
Складність створення засобів спілкування,
призначених
для кінцевих користувачів, обумовлена значною мірою відсутністю
єдиної теорії мовного спілкування, що охоплює всі аспекти взаємодії
комунікантів.
Тому при розробці засобів спілкування кінцевих користувачів на процес
взаємодії
часто накладаються різні
«спонтанні» обмеження,
наслідки яких не до кінця усвідомлюються розробниками. Ці обмеження
приводять
до того, що багато людино-машинних систем, на розробку яких
витрачаються
величезні кошти, не задовольняють вимогам кінцевих користувачів.
Природно-мовні системи використовуються для
пошуку в
текстах, розпізнавання мови, голосового
управління і
обробки даних.
Примітно, що функція пошуку в тексті може
бути
використана в досить широкій області. Однією зі
сфер
застосування є системи тестування. Подібні системи застосовуються в
дистанційному навчанні, перекладаючи обов'язок перевірки
відповідей на ЕОМ. Однак слід зауважити, що
розвиток
подібних систем спостерігається лише у сфері тестових завдань, де вже
визначені
готові відповіді. Засоби природно-мовного пошуку в текстах здатні здійснювати за запитами користувачів пошук,
фільтрацію і сканування текстової інформації. При цьому засоби даної категорії здійснюють пошук в
неструктурованих
текстах, оформлених відповідно до правил граматики тієї чи іншої природної мови.
Іншими словами, застосування системи аналізу
природної
мови в системах тестування дозволило б користувачеві вводити свою
відповідь, а
не вибирати одну із запропонованих, маючи
можливість вгадати правильну. Пряме введення тексту надало би більш точне оцінювання знань, при цьому
дозволяло би користувачеві більш гнучко відповідати на
запитання – у сенсі свого розуміння. Порiвняння сенсу отриманої відповіді iз сенсом відповіді-єталону і визначатиме її правильність, а тому застосування систем природно-мовного
аналізу
тексту має пряме практичне застосування в цій області.
Планована наукова новiзна
Передбачається, що
дана магістерська робота дозволить розширити
існуючі моделі семантичного
аналізу, збільшивши їх гнучкість і
сприйнятливість у межах
деякої предметної області.
Плануемi практичнi результати
В якості
основних запланованих результатів
передбачається досягнення поставленої
мети: розробка алгоритму
нової семантичної моделі
розпізнавання природно-мовних
виразів, яка може
бути використана в
системах тестування знань.
Іншими словами,
передбачається створення алгоритму,
що
дозволяє здійснювати не прямий
пошук сенсу в
тексті, орієнтуючись
на
якийсь заданий шаблон.
Крім того, алгоритм повинен забезпечувати порівняння
шаблону із
знайденими результатами для
визначення ступеня відповідності.
Ступінь відповідності,
в
даному випадку, може
грати роль оцінки
знань.
Огляд дослiдженнь i розробок iз теми. Глобальний рiвень
На даний момент розроблено безліч моделей
лінгвістичного аналізатора, які здатні в тій чи іншій мірі
виконувати аналіз природно-мовного тексту, визначати зміст і генерувати
висловлювання. При цьому підходи до
моделювання
процесу спілкування дуже різноманітні. Основні відмінності цих підходів
полягають в методах реалізації компоненту розуміння змісту, що
використовуеться
в засобах аналізу, а також в обсязі і способах представлення знань,
оскільки
саме знання, представлені в різній формі, є базою, від якої залежить
процес
спілкування, глибина проникнення в зміст і,
відповідно,
якість самої моделі лінгвістичного аналізатора. Від
виконання окремих функціональних компонент залежить практична
реалізація
моделей у різних системах спілкування (системи спілкування з базами
даних,
системи машинного перекладу та ін.). Деякі з них лягли в основу
конкретних
систем формування семантичного уявлення на основi обробки текстів (наприклад, модель
«сенс-текст» в системі
«Поет»).
Проаналізуємо найбільш опрацьовані моделі
лінгвістичного процесора.
У завдання аналізу входить виділення сенсу
вхідного
тексту (під сенсом будемо розуміти
семантику – інформацію,
яку користувач хотів передати системі) та
вираження цього змісту внутрішньою мовою системи. Інтерпретація полягає
у
відображенні вхідного тексту на знання системи. Одним з основних
параметрів
аналізу тексту є розуміння сенсу вхідного речення, що включає
в себе опис сутностей вхідного тексту, визначення їх
властивостей і
відносин між ними. Від цього параметра часто
залежить
глибина проникнення в зміст вхідного тексту.
В існуючих моделях лінгвістичного аналізатора
можна
виділити наступні способи виділення і подання сенсу: компонентний
аналіз;
мережа концептуалізацій; ідентифікація сенсу за зразком; інтегральний підхід (див. рис. 1).
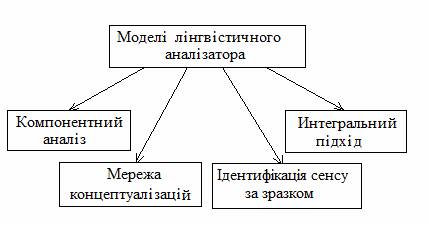
Рисунок 1 – Моделi лiнгвiстичного аналiзатора
Модель компонентного аналізу
Одна з перших спроб
формалізації
вхідного тексту належить компонентному аналізу, який виходить з
передумови, що
семантика природних мов може бути виражена в термінах кінцевого
неструктурованого набору семантичних одиниць (атомів сенсу). У процесі розгляду слів
виділяються ознаки, які розбивають слова на окремі групи. За усiеї природності даний метод пов'язаний з
істотними
труднощами при реалізації і не позбавлений недоліків. Він стає складним
при
вираженні сенсу цілого речення і громіздким при аналізі багатозначних слів, при цьому немає достатнього пояснення
слова, що може
привести до неправильного його вживання.
Надалі ідея опису вхідного тексту за
допомогою компонентного
аналізу знайшла своє продовження в моделі «Семантичні відмінки
(ролі)» Ч. Філмора [3].
Але на відміну від
попередньої моделі в предикатах вказується не тільки аргументна
структура і
кількість, але і їх семантичний зміст (ролі). Філмор
виділяє наступні семантичні ролі: агент, контрагент, об'єкт, адресат,
паціенс,
результат, інструмент, джерело. У моделі запропонована більш детальна
концепція
сенсу висловлювання. Кожне поняття розщеплюється на дві сутності:
значення і
пресуппозицiю.
Відмінності між пресупозицією і значенням у власному розумінні слова
виявляються, наприклад, в різному впливі на
них
заперечення. В область дії заперечення
потрапляє
тільки значення, а не пресуппозицiя. У результаті
досліджень була розроблена класифікація семантичних елементів, що
привело до
перегляду звичайної схеми словникової статті в тлумачному словнику (словник став основним засобом завдання
семантичних структур
і правил їх переведення в поверхневі структури).
Продовженням цієї теорії є метод відмінкової
граматики
iнших дослiдникiв, де спеціальна синтаксична мова, словар і
правила,
встановлюють відповідність між
природно-мовними
виразами і їх семантичним представленням.
Модель мережі концептуалізацій
До другого класу відносяться моделі, в яких
зміст тексту представляється у вигляді
мережі концептуалізацій.
У таких моделях явища розглядаються тільки на одному рівні
детальності, що не дозволяє, як описувати складні події в термінах
більш
простих пiдподiй, так і дiлити при
необхідності примітивні дії (атоми). Найчастіше ці моделі є моделлю
мови, а не
моделлю спілкування, що призводить до нечіткого виділення мовних
засобів і
засобів для опису модельованого оточення.
Серед
моделей даного класу найбільший інтерес представляє модель
«Концептуальної
залежності».
Основою семантичного представлення моделі
«Концептуальної залежності» (Р. Шенк [4])
є мережа концептуалізацій. Мережа
концептуалізаций є квазіграф, подібний розміченому орієнтованого графу,
в
якому, крім бінарних відносин, iснують тернарнi і кварнарнi, а дуги
пов'язують не лише вершини, а i інші дуги.
Концептуалізація в моделі концептуальної
залежності
визначається як основна одиниця семантичного рівня.
З таких одиниць конструюються думки.
Концептуалізація включає
в себе дію, множину її концептуальних
відмінків і
учасників дії (їх станів).
Будучи моделлю мови, вона не враховує моделі
користувача, що призводить до повного перебору при побудові
умозаключень.
Наявність моделі користувача дозволила б визначити його цілі (наміри) в
діалозі і використовувати їх для направлення
процедури
побудови умозаключень.
Модель ідентифікації сенсу
Інша модель –
«Семантика переваги» відноситься до класу моделей,
ідентифікація сенсу в яких здійснюється за зразками. Відмінною рисою
таких
моделей є те, що в них відсутні блоки морфологічного і синтаксичного
аналізів,
що є принциповим їх недоліком, так як не забезпечується глибина аналізу
значень
слів, що необхідна для точного встановлення
семантичної зв'язності тексту.
У цій моделі Уїлкса текст характеризується
наступними
сутностями: смислами слів, повідомленнями,
фрагментами
тексту і семантичною сумісністю. Повідомлення розглядається як
теоретичний
конструкт, за допомогою якого для кожного слова, що входить у
фрагмент тексту, може бути обраний один зi сенсiв слова, за
допомогою чого знімається багатозначність.
Слову призначається той з його багатьох сенсів, який утворює
«повідомлення», що
зрештою узгоджуються, з даним фрагментом тексту. Якщо слово може підійти до кількох повідомлень, то вибирається
таке, яке
узгоджується з даним текстом.
Аналіз фрагмента тексту вiдбуваеться за наступною схемою. За допомогою
спеціальних слів-маркерів виконується
фрагментація
тексту, потім до слiв приписують зі словника всi їх значення. Далі на аналізований фрагмент
тексту по черзі
накладаються прості шаблони, що відомі системі. За допомогою
спеціальних правил
розширення простий зразок перетвориться в повний зразок шляхом
додавання слів з тексту, які не увійшли до
зразка. Зазначена процедура
ускладнена тим, що може підійти не один
простий
зразок. Використовуючи процедури встановлення семантичної близькості
отриманих
зразків, формується остаточне уявлення оброблюваного тексту. До
недоліків
аналізу слід віднести те, що аналіз тексту
здійснюється за допомогою словника шаблонів, які здатні розрізняти
тільки клас
подій, а не самі конкретні події.
Інший підхід до
способу
аналізу за зразком представлений в моделях, які використовують
табличний пiдхiд. Він
заснований на аналізі ключових слів, що
зустрічаються у
реченнях. Сутнiсть табличного пiдходу полягає в ідентифікації сенсу всього
речення на підставі кількох ключових слів
або їх груп. Після процесу ідентифікації
слова речення замінюються на їх
канонічну форму – коди.
Заміна здійснюється за допомогою словника словоформ. При цьому
також виділяються деякі групи слів, що
несуть
тематичне навантаження. Далі виробляється розпізнавання і заміна
стандартних
словосполучень. Даний метод має низку недоліків,
перевагою є його простота для однозначних природно-мовних речень, в
яких не
вимагається повного розуміння змісту речення (наприклад, запити до бази
даних).
Модель інтегрального підходу
Моделі, в яких досить глибоко продумані
процедури
морфологічного, синтаксичного і проблемного аналізів, можна віднести до
моделей, заснованих на інтегральному підході
опису
мови. Це модель «Сенс-текст» і модель контекстного
фрагментирования.
Модель «Сенс-текст» (І.А.
Мельчук) являє собою
багаторівневий транслятор текстів у сенси і
навпаки. Виділяються
чотири основні рівні – фонетичний,
морфологічний, синтаксичний і проблемний.
Кожен з них, за винятком проблемного, підрозділяється
на два інших рівня – поверхневий
і глибинний.
Дана модель може бути застосовна в системах,
де
необхідне розуміння тексту в повному сенсі (наприклад,
питально-відповідні
системи, системи прийняття рішень). Але для
реалізації
повної схеми аналізу та синтезу моделі «Сенс-текст»
доведеться врахувати
індивідуальні властивості сотень тисяч словникових, морфологічних і
лексичних
одиниць і індивідуальні властивості величезного числа пар одиниць. Їх
повний
формальний опис являє собою величезну і об'ємну теоретичну роботу,
поставлену в
лінгвістиці останнім часом і ще далеку від
вирішення.
Модель контекстного
фрагментування
розроблялася для аналізу та синтезу природно-мовних речень, але її
опрацювання
стосується в основному аналізу. Завдання лінгвістичної трансляції
природно-мовного тексту розглядається окремо від
інших
завдань спілкування природною мовою і від завдань самої обчислювальної
системи.
Аналіз і трансляція тексту здійснюються при наявності досить потужних
засобів
опису і фрагментації лінгвістичних знань. Основу моделі контекстного
фрагментування становить трирівнева система: лінгвістична модель,
базові
механізми опрацювання пропозицій та асоційовані процедури. Лінгвістична
модель містить інформацію про морфологію,
синтаксис і семантику пiдмножини природної
мови. У моделі виконується дуже
глибокий синтаксичний аналіз з одночасним перетворенням розпізнаваних
синтаксичних відносин в семантичні. Перевагою даного методу є те, що
існує
можливість динамічно змінювати стратегію обробки природно-мовного
тексту
залежно від необхідної глибини і
послідовності етапів
трансляції та розширювати метод при включенні нових конструкцій
природної мови
і редукувати його для спрощених підмножин
природної
мови і проблемних областей.
Огляд дослiджень i розробок iз теми. Нацiональний рiвень
Серед
робіт українських вчених, спрямованих
у цю сферу,
важливий внесок був зроблений Святогоров Л. А. і Гладуном В. П. В їх роботі
«Семантичний аналіз текстів природної
мови: цілі та засоби» [5]
пропонується розширене тлумачення
поняття «текст природної
мови» і пропонується схема повного освоєння його семантичного ресурсу за рахунок
«комп'ютерного розуміння» і діалогу. Вказуються засоби
досягнення зазначеної мети в процесі семантичної обробки текстів –
використання трирівневої онтології для вилучення з тексту онтологічного сенсу, а також
введення зворотного зв'язку для додаткового уточнення в діалозі змісту дискурсу.
На початку і в
кінці
семантичного аналізу природно-мовних текстів стоїть слово. Методи
аналізу різноманітні і залежать від
розв'язуванного в прикладній
області завдання, і існує не один напрямок обробки текстової
інформації. В
умовному поділі можна виділити методи семантичної обробки текстів, які
націлені
на «лінгвістичні перетворення» – методи
концептуального аналізу. При цьому можна помітити оформлення
двох проблем: синтез систем представлення знань – онтологій і
розробка систем семантичного аналізу і машинного
«розуміння» текстів за допомогою онтологій.
Проблема сiнтезу
систем представлення знань вирішується широким фронтом; з останніх,
практично
успішних робіт можна вказати на дослідження [6],
де з корпусу професійних
текстів автоматично витягується підструктура
знань в
одному з розділів предметної області (ПрО)
«Матеріалознавство». Для
синтезу онтології використовуються формально-логічні та
синтаксичні засоби аналізу.
У проблемі розробки систем семантичного аналiзу I машинного розумiння текстiв підхід полягає в наступному [7,
6]. Якщо опис ситуації,
викладеної в тексті, може бути досягнутий суто лінгвістичними засобами,
то
розуміння ситуації можливе за рамками лінгвістичного ресурсу
тексту –
мобілізацією когнітивних зусиль людини і її
індивідуальних знань.
Аналогічно тому, як людське розуміння
народжується при
узгодженні зовнішньої інформації з її ментальною (когнітивною) моделлю світу, «комп'ютерне розуміння» може
бути досягнуто
відображенням інформації на певну і формально-задану систему знань. Простіше кажучи, щоб «розуміти» щось,
треба його
«впізнавати». У машинній обробці текстової інформації роль
пам'яті людини
виконує комп'ютерна система формальної репрезентації знань – онтологія:
саме вона дозволяє поєднати аналіз тексту
з його комп'ютерним «розумінням». Процедурно це досягається
досить просто:
необхідно знайти проекцію тексту на комп'ютерну онтологію.
Вирішенню завдання повного розкриття
семантичного
ресурсу тексту, сприяє така система семантичного аналізу ПМ текстів (Система), яка
задовольняє
вимогам, наведеним далi.
1.
Перше. Партнери інтелектуального спілкування разом
з
текстом занурені в єдину комп'ютерну середу онтологічного знання.
2.
Друге. Попередня лінгвістична обробка вихідного
тексту
(морфологічний, синтаксичний і семантичний аналіз речень) необхідна для
зняття
«лексичної оболонки» і виділення термів, що несуть
змістовне навантаження.
3.
Третє. Результатом
комп'ютерного семантичного аналізу зв'язного тексту повинен бути
формальний або
адаптований ПМ текст, який виражає його смисловий зміст.
4.
Четверте.
Система повинна забезпечувати самоконтроль
авторського наміру – наскільки
адекватно він висловлює свої думки.
5.
П'яте. Система повинна багаторазово активізувати
текст з
метою більш глибокого проникнення в зміст
повідомлення.
У результаті самого загального погляду на
бажані
якості Системи семантичного аналізу, можна зробити висновок, що
потенційні
можливості тексту реалізуються за допомогою двох механізмів: аналізу
через
онтологію та активного діалогу.
Перша вимога – розуміння
партнерів комунікації –
забезпечується єдиною системою подання загальних і
професійних знань, накопичених в соціумі. У
якостi контекстного середовища спілкування
пропонується формальна
семантична мережа – ієрархічна
трирівнева онтологія (див. нижче), сформульована в роботі [8],
яка може бути розширена і доповнена спектром будь-яких
предметно-орієнтованих
онтологій [6, 9, 10].
Друга теза – попередній
розбір тексту – виконується
лінгвістичним процесором, орієнтованим на
семантичний аналіз звичайної текстової інформації. У самому простому
випадку
від лінгвістичного процесора потрібно: побудувати дерево синтаксичного
розбору,
виділити ядерні конструкції пропозицій, побудувати вiдношення, визначити «значимі»
лексичні групи, зокрема – ключові
слова тексту [6].
Третя умова означає,
що з
тексту необхідно витягти його смисловий зміст. Сенс зв'язного тексту,
формалізується через онтологію – як
сукупність пiдграфiв концептуального
графа. Завдання виявлення сенсу в
деякому текстовому фрагменті (і в цілому тексті) покладається
на смисловий процесор.
У четвертiй вимозі передбачена сервісна можливість
корекції
тексту його автором. При бажанні він
порівнює
результат автоматичного виділення сенсу зі своїми внутрішніми намірами.
Нарешті, для більш глибокого розкриття
змісту,
уточнення фактів та інших даних (п'ята умова) передбачений режим діалогу, який реалізується природною мовою
діалоговим
процесором. В процесі діалогу сенс може
істотно
змінитися, що, в свою чергу, може служити приводом для коригування
онтології
(активність тексту).
Як смисловий, так і діалоговий
процесори виконують інтелектуальну місію, залучаючи позалінгвістичннi знання. До них слід
додати
допоміжний транслятор «сенс-текст», він (у необхідних
випадках) допоможе людині
більш змістовно витлумачити формальний пiдграф сенсу.
На рисунку 2 зображенна
блок-схема Системи семантичного аналізу природно-мовних текстів, в якій взаємодіють зазначені вище
функціональні
компоненти.
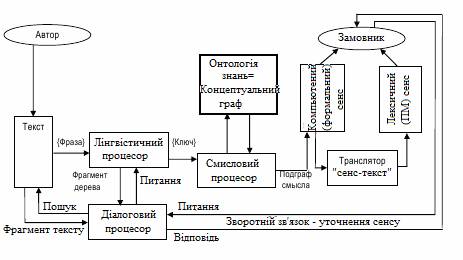
Рис. 2 Блок-схема
Системи семантичного аналізу ПМ
текстів
Базисом Системи служить
нова
ієрархічна трирівнева онтологія –
«ИО*3» [8]. Вона відрізняється
двома особливостями: а) мережева структура дає принципову можливість
об'єднати – в рамках
єдиної конструкції – знання
вищого рівня абстракції, загальнодоступні
(повсякденні та актуальні) знання середнього рівня та професійні знання
нижнього рівня; б) одночасно вона орієнтована на роботу з конкретними
текстами.
Крім того, показано, що результатом вилучення з тексту знань повинен
бути «онтологічний сенс». Цей сенс піддається
строгiй формалізації та комп'ютернiй обробцi [11].
Онтологія «ИО*3» організована як
«піраміда
концептуальних знань». Концепти мають різний
ступiнь узагальнення. Найбільш абстрактні
категорії
утворюють верхній рівень онтології;
відповідно до
парадигми академіка В.І.Вернадського про біосферу і ноосферу, це – Матерія,
Речовина, Життя, Розум i т.д.
Концепти середнього рівня утворюють
описовий контiнуум знань. Вони розкривають значення
категорій
верхнього рівня через більш вживану в
актуальній
діяльності товариства лексику, наприклад: Час, Рух, Порядок, Людина,
Суспільство, Організація, Розвиток, Управління, Транспорт, Біологія,
Боротьба
за існування та інші. На нижньому рівні
піраміди знань
розташовуються концепти двох типів: частина з них позначають обігові
поняття
повсякденного життя, звичні об'єкти і ситуації (кімната, ложка i т.д.),
інші концентруються навколо професійних знань ПрО (концепт, вiдношення, онтологія i т.д.). Множина
концептів ПрО може бути порожньою.
На допомогу у визначенні поняття
«сенс» приходить
онтологія «ИО*3». Ідея
полягає в тому, що якщо «пропустити» текст через онтологію,
яка є структурою
знань, то на виході отримаємо концентроване знання, яке корелює з
текстом. Концептуальний
фільтр онтології дасть на виході
концептуальний, або
онтологічний сенс.
У заданному
концептуальному
онтологічному графi «ИО*3», елементарний сенс
визначається як пара
сполучених сусідніх вузлів.
Зв'язки не обов'язково називаються, вони
можуть лише фіксувати факт деякої взаємодії
двох слів (наприклад,
ворона-птиця, пасажир-літак, розвиток-прогрес). Онто-граф складається з
множини
пов'язаних між собою елементарних смислів, які вступають в дозволені
комбінації. Зв'язкова частина онто-графа, що з'єднує два віддалених
вузла,
утворює пiдграф; при зміні в ньому стрілок
на протилежні (знизу - вгору) виходить ланцюжок пiдграфа.
Ланцюжок пов'язаних елементарних смислів,
який починається в деякому
«активному» вузлі і закінчується у
вершині онтології, утворює онтологічний ланцюжок активного вузла.
Ланцюжок, що
виділяється активним вузлом на онтологічному графі, трактується як
смислова траєкторія і називається
онтологічним змістом активного
слова.
Процес збуждення смисловий траєкторії
починається з того, що в реченні з ядерної конструкції виділяється
деяке
«ключове слово». Якщо воно присутнє в онтологічному графі,
то активне слово
збуджує сусідній концепт, збудження передається далі на вищі рівні
онтології – аж до
вершини піраміди.
Результатом процесу є ланцюжок, тобто – дискретна
упорядкована послідовність
взаємопов'язаних концептів; вона є формальним онтологічним змістом
вхідного
слова в заданій «картині знань» (див. рис. 3).
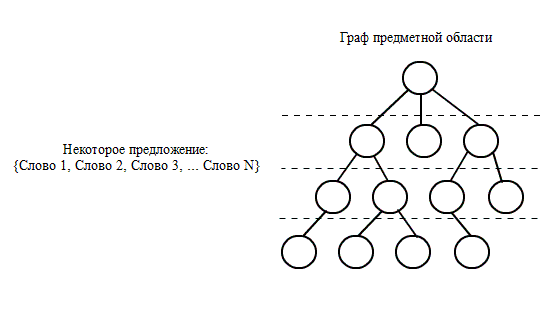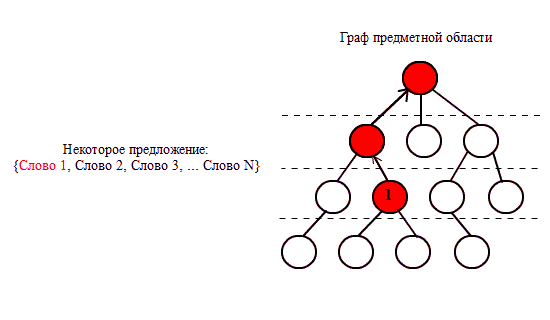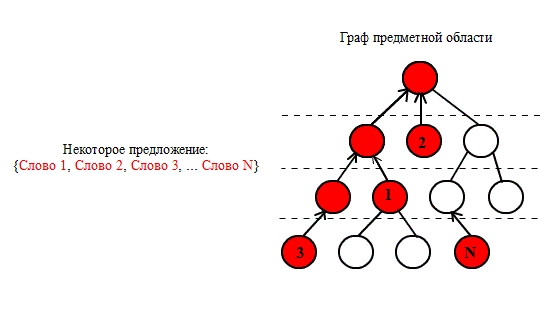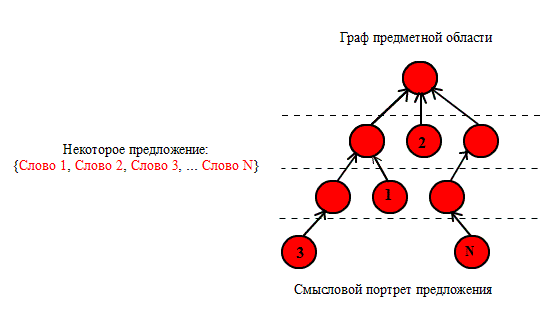
Рисунок 3 –
Побудова сенсових траекторiй NO3
(анiмацiя: 10 кадрiв, 5 циклiв
повтору, 16 кiлобайт)
Результатом повного перегляду тексту є
множина –
«пучок смислових траєкторій»,
який можна трактувати як «семантичний портрет тексту».
Онтологічний сенс може бути метою і
результатом
семантичного аналізу ПМ тексту завдяки таким властивостям:
-
ключові
слова у смисловому ланцюжку витягуються
безпосередньо з тексту;
-
ці
слова поміщають в контекст загальних знань, які
організовані як концептуальне смислове середовище (онтологія);
-
множина
смислових ланцюжків дає короткий, дискретний і
формалізований опис тексту (фрагмента тексту) –
«семантичний портрет тексту» в термінах загальних
знань.
Функцію виділення в тексті значущого слова
виконує
лінгвістичний процесор. Функція виділення в онтологічному графі
смислової траєкторії покладається на
смисловий процесор.
Функцію адаптованого подання сенсу виконує
транслятор
«сенс-текст» (див. рис. 2).
Онтологічний сенс, витягнутий з текстового
документа
комп'ютерною системою, стає елементом Бази знань, яка доступна
всім партнерам комунікації.
Фундаментальна цінність механізму виявлення онтологічного
сенсу
криється в тому, що він, створюючи графічний портрет тексту і описуючи
його
метамовою онтології, дозволяє людині скласти хоч і саме загальне і
схематичне,
але цілком адекватне уявлення про ситуацію.
У результаті споживач отримує певну ясність – в чому полягає суть повідомлення. Що стосується людського розуміння онтологічного сенсу, формат якого незвичний для (сучасної) людини, то для його перетворення в граматичну мовну форму передбачений, як зазначено вище, спеціальний транслятор «сенс-текст». Принципи трансляції розроблені в лінгвістичнiй моделі «сенс-текст» [12].
Огляд дослiджень i розробок iз теми. Локальний рiвень
Будучи одним із
дуже помітних і значущих, Донецький національний технічний університет так само веде свої
дослідження у сфері семантичного аналізу природно-мовних
висловлювань. Однією з
найбільш помітних, є робота Лук'яненко С.А., Безсонової А.В. і Казакової Є.І. [13].
Згідно з
їх дослідженням, природна мова містить
всі засоби для вираження алгоритмів і всіляких даних при їх машинній
обробці, вона
може служити прекрасним засобом комунікації людини і електронної
обчислювальної
машини. Будь-яка автоматизована
інформаційна система повинна мати у своєму складі набір
засобів автоматичної обробки природно-мовних повідомлень. Але в силу
того, що
природна мова складається зі словника та граматики – будь-яка автоматизована
система обробки природно-мовних повідомлень повинна мати у своєму
складі
«засоби граматичної обробки» і «засоби словникової
(семантичної) обробки».
Системи подібного роду прийнято називати інтелектуальним інтерфейсом.
Засобами граматичної обробки природної мови є
формалізований набір правил граматики української мови. Але так як зміна слів
не завжди вкладається в рамки регулярності, то формалізованою може бути
не вся
граматика. Формалізований набір може бути не
повним також
і через недостатнiсть моделей граматики. Таким
чином, всі невраховані правила можна вважати неприпустимими.
При формалізації словника найбільш прийнятною
є порівнева обробка лексичних
одиниць. Для кожної предметної області має бути визначений словник
вихідних лексичних
одиниць (нижній рівень), за допомогою якого
з
використанням інформації про наявні афікси можна
обчислювати семантику будь-якого утвореного слова, при цьому, також,
засобами
системи можна отримувати нові слова, маючи їх семантичне відображення.
Отже, будь-який вид машинної обробки
повідомлень
природної мови включає в себе обробку
окремих
лексичних одиниць. У свою чергу, обробка окремих слів
являє
собою обробку складаючих слово частин: кореня і афіксiв.
Структура підсистеми для семантичної обробки природно-мовних
-
Модель
тексту.
-
Модель
фрази (групи слів).
-
Модель
словосполучення (пари слів).
-
Модель
словa:
1)
моделі
афіксів;
2)
модель
коренiв.
Структура системи автоматизованої обробки
природної
мови продиктована структурою змісту тексту, бо будь-який текст поділяеться на частини саме сенсом. Саме слово, наприклад, нероздільне на
частини і саме зміст елементарних морфів дозволяє
виділити в ньому мінімальні значимі одиниці.
При моделюванні всіх рівнів
підсистеми семантичної обробки природно-мовних повідомлень
використовується
єдиний підхід. Ця обставина й дозволяє створити загальну модель сенсу у
вигляді
системи алгебри кінцевих предикатів. Окрема система рівнянь алгебри
кінцевих
предикатів описує словозміну.
Природна мова представлена, з точки зору морфології, одноморфними і многоморфними словами. З точки зору словотворення
одноморфні слова це базові лексичні
одиниці, многоморфнi – утворені від
базових. Семантика утворенного
слова спирається, як правило, на сенс базових
лексичних одиниць, що входять до складу цього
слова, і семантику аффiксального
оточення (префікси, суфікси). Іншими словами, зміст
утворенного слова виходить з семантики морфів, що
входять до
складу утворенного слова, тому природною частиною моделі мови є
модель її словотвірного рівня.
Модель семантики утворенного слова представлена комплексом незалежних
математичних моделей. Це модель префікса, модель кореня, модель
суфікса. Аналіз
семантики будь якої
утворенної лексичної одиниці починається з розбиття її на морфи. Пiсля виконання цієї операції, функціонування
перерахованих вище моделей, можливо в паралельному режимі. При цьому спочатку
обчислюється сенс кореня, потім з урахуванням його семантики, внаслідок
паралельної роботи підсистем моделей
афіксів,
обчислюється сенс утворенного слова. Така
організація систем семантичного аналізу дозволяє істотно прискорити
автоматичну
обробку текстів.
Різні моделі семантики утворенних слів можуть бути використані в будь-яких
автоматизованих системах обробки природної мови. При цьому слід
мати на увазі, що кожен конкретний варіант системи обробки природних
мов зовсім
необов'язково повинен містити в собі засоби, здатні актуалізувати всі
можливі
семантичні реалізації того чи іншого слова. У кожному
конкретному випадку система може являти собою якусь редуційовану модель, орієнтовану на конкретну предметну
область.
Залишкова неоднозначність мови, зокрема явища омонімії, усуваються за
рахунок
відповідних технологічних заходів: поєднанням даного слова з іншими
так, щоб
словосполучення в цілому стало однозначним. У ряді випадків, значення слів у словнику можна обмежити одним
значенням – єдино
можливим в даному варіанті системи.
Застосування цих моделей можливо в різних
системах обробки текстів російської та української мови. Це може бути
широкий
клас діалогових систем; можливе
застосування
розроблених моделей в системах автоматичного редагування, в системах
автоматичного коригування для виявлення помилок у вхідних текстах, у
всіляких
автоматизованих системах інформаційного пошуку, в автоматизованих
навчальних
системах. Особливу роль пропоновані моделі зіграють у тестування знань.
Отримання відповіді природною мовою можна
звести до
отримання семантичного еквівалента, який буде порівнюватися з
еквівалентом
відповіді. При цьому одночасно буде здійснюватися семантичний контроль
як
вхідних, так і вихідних текстових конструкцій.
Короткий виклад власних результатів
На основі
проведеного аналізу,
для подальшого розвитку
була обрана відмінкова
модель
Ч. Філлмора. Глибокий розгляд
даної моделі,
дозволило прийти до
висновку,
що вона може
бути розширена і використана до складних
речень на природній
мові. При цьому,
вона як і раніше має діяти
тільки в рамках деякої предметної області
для забезпечення відсутності
двозначностей при виявленні смислового змісту
тексту відповідей в
системах тестування.
Висновок
Отже,
було встановлено, що в
якості основи аналізу
тексту лежить виявлення
у ньому сенсових складових. Виявлення цих складникiв у тексті і оперування з ними є основою смисловоi
обробки текстів. При цьому, слiд зауважити, що значення сенсових
складникiв тiсно пов’язане iз обраною предметною
областю.
На
закінчення огляду різних підходів та
напрямів реалізації моделей лінгвістичного процесора
можна зробити висновок про те, що
до теперішнього часу моделі здатні: витягати
знання із заданого тексту і
будувати правильні пропозиції природної
мови за заданим значенням сенсу; перефразувати ці
пропозиції, оцінювати їх з точки зору зв'язності і
виконувати ряд інших завдань.
Список використанних джерел
1.
Manning C.D. Foundation of ststustical nature language
processing / C.D. Manning. – 1992. – Vol.12, N 4. –
P.89-94.
2.
Воропаев
А.С. Эволюция
вычислительных машин [Электронный ресурс].
– Режим доступа: http://www.snkey.net/books/samxp/ch1-1.html
3.
Filmor C. Frames and the semantics of understanding /
C. Filmor // Quaderni di semantica.Vol 4 / 2 December 1985 – p.
222-254
4.
Shank R. Conceptual information processing / R. Shank
– Norh-
5. Святогор Л. Семантический анализ текстов естесственного языка: цели и средства / Л. Святогор, В. Гладун // XV th International Conference “Knowledge-Dialogue-Solution” KDS-2 2009, Киев, Украина, Октябрь, 2009.
6.
Палагин
А. К анализу
естественно-языковых объектов / А. Палагин, С. Крывый, В. Величко, Н.
Петренко
// International Book Series, Number 9. Intelligent Processing.
Supplement to the
International Journal “Information Technologies &
Knowledge” Volume 3 /
2009. – ITHEA,
7.
Кибрик
А.Е. Семантическая проблематика
гетерологического кодирования / А.Е. Кибрик – М.: Наука 1965.
– С. 67-83
8.
Гладун
В. Структурирование
онтологии ассоциаций для конспектирования естественно–языковых
текстов / В. Гладун,
В. Величко, Л. Святогор // International Book Series, Number 2. Advanced Research in
Artificial Intelligence. Supplement to the International Journal
“Information
Technologies & Knowledge” Volume 2 / 2008. – ITHEA,
9.
Поспелов
Г.С. Искусственный интеллект – основа новой
информационной технологии / Г.С. Поспелов – М.: Наука, 1988.
– 279 с.
10.
Гаврилова
Т.А. Базы знаний интеллектуальных
систем / Т.А. Гаврилова, В.Ф. Хорошевский – СПб.: Питер, 2001.
– 384 с.
11.
Святогор
Л.
Определение понятия «Смысл» через онтологию. Семантический
анализ текстов естественного
языка. / Л. Святогор, В. Гладун // International Book Series, Number 9. Intelligent
Processing. Supplement to the International Journal “Information
Technologies
& Knowledge” Volume 3 / 2009. – ITHEA,
12. Мельчук И.А. Опыт теории
лингвистических моделей «Смысл – Текст» / И.А.
Мельчук – М.: Школа «Языки русской
культуры», 1999. – 346 с.
13. Лукьяненко С.А., Бессонов А.В., Казакова
Е.И. Моделирование
семантики естественно языковых высказываний в автоматизированных
информационных
системах [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2006/fema/lukyanenko/library/art03.htm