
Реферат по теме: «Исследование и разработка программного обеспечения системы синтеза и оптимизации топологии сетей в классе древовидных структур»
Содержание
- 1. Актуальность темы
- 2. Цель и задачи исследования и запланированные результаты
- 3. Научная новизна
- 4. Обзор исследований и разработок
- 4.1 Алгоритм Прима
- 4.2 Алгоритм Крускала
- 4.3 Алгоритм оптимизации муравьиной колонии
- 4.4 Генетические алгоритмы
- 4.5 Нейронные сети
- 5. Исследование и анализ алгоритмов построения топологии сетей в классе древовидных структур
- Выводы
- Перечень ссылок
1. Актуальность темы
Задача нахождения кратчайшего (или оптимального) пути постоянно актуальна. В настоящее время в области решения транспортных задач добавилась новая – доставка образования в разные точки земного шара. Одной из основных проблем для сетей дистанционного обучения стал поиск оптимального маршрута передачи данных, так как для качественного дистанционного обучения ВУЗ должен тесно сотрудничать со студентами. Важным является возможность быстро и без потерь доставить исходную информацию.
2. Цель и задачи исследования и запланированные результаты
Целью исследования являтеся анализ и разработка программного обеспечения системы синтеза и оптимизации топологии сетей в классе древовидных структур.
Задачи исследования:
1. Обзор существующих подходов к решению задачи синтеза топологии сетей в классе древовидных структур
2. Анализ конкретных алгоритмов синтеза топологии сетей
3. Выбор оптимальной схемы синтеза топологии сетей в классе древовидных структур
4. Программная реализация выбранной схемы
5. Анализ результатов работы программы
Планируемые результаты:
1. Совершенствование существующих методов синтеза топологии сетей
2. Повышение качества передачи данных в системах дистанционного образования
3. Сравнение разработанной системы с существующими аналогами
3. Научная новизна
Для качественного дистанционного обучения ВУЗ должен тесно сотрудничать со студентами. На данный момент существует не так много систем, которые могут обеспечивать бесперебойную доставку образования в разные точки земного шара. Недостатком существующих систем является медленная работа и иногда потеря информции. Система, которая разрабатывается, должна избавиться от существующих на данный момент источников неэффективной работы.
4. Обзор исследований и разработок
Прежде чем начать анализ существующих алгоритмов нужно определиться с некоторыми терминами. Скелетное дерево связанного неориентированного графа – ациклический связный подграф этого графа, содержащий все вершины. Скелетное дерево состоит из некоторого подмножества ребер графа, таких, двигаясь которыми можно с любой вершины графа попасть в любую другую. Скелетное дерево также называют каркасным деревом, покрывающим деревом, костяком или каркасом графа.
4.1 Алгоритм Прима
Алгоритм Прима – алгоритм построения минимального скелетного дерева.
Принцип действия такого алгоритма заключается в том, что на каждом шаге мы добавляем к строящемуся скелету безопасное ребро. Алгоритм Прима относится к группе алгоритмов наращивания минимального остова: на каждом шагу существует не более одной нетривиальной (не состоит из одной вершины) компоненты связности, и каждый раз к ней добавляется ребро наименьшей тяжести, которое соединяет вершины компоненты с другими вершинами. По теореме такое ребро является безопасным [2].
При реализации нужно уметь на каждом шагу быстро выбирать безопасное ребро. Для этого удобно использовать очередь с приоритетами (кучу) [7]. Алгоритм получает на вход граф G и корень r – вершина, на которой будет наращиваться минимальный остов. Все вершины G, еще не попали в дерево, сохраняются в очереди с приоритетом Ω. Приоритет вершины v определяется значением key [v], равному минимальному весу ребер, соединяющих v с вершинами минимального остова. Поле p [v] для вершин дерева указывает на родителей, а для вершин из очереди, указывает на ноду дерева, к которому ведет ребро с весом key [v] (одно из таких ребер, если их несколько) [13].
Общая схема алгоритма:
MST-PRIM(G,w, r)
1: Ω < V[G]
2: foreach (для каждой) вершины u ∈ Ω
3: do key[u] < ∞
4: key[r] < 0
5: p[r] = NIL
6: while (пока) Ω ≠ 0
7: do u < EXTRACT-MIN(Ω)
8: foreach (для каждой) вершины v ∈ Adj(u)
9: do if v ∈ Ω и w(u,v) < key[v] then
10: p[v] < u
11: key[v] < w(u,v)
Алгоритм
- Сначала ребра сортируют по возрастанию веса.
- Добавляют меньше ребро в дерево, связанное с вершиной графа.
- Из списка ребер с наименьшим весом выбирают такое новое ребро, чтобы одна из его вершин принадлежала дереву, а другая – нет.
- Это ребро добавляют в дерево и снова переходят к шагу 3.
- Работа заканчивается, когда все вершины будут в дереве.
Схема работы алгоритма Прима с корнем r приведена на рисунке 1.
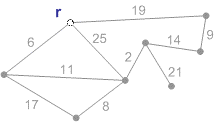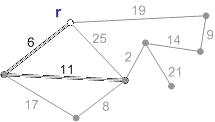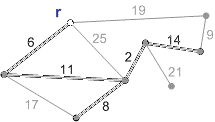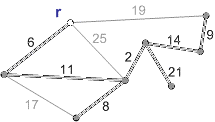
Рисунок 1 - Схема работы алгоритма Прима (анимация - размер: 215 x 122 px, объем: 19.9 kb; кадров: 8; задержка между кадрами: 150мс., количество повторов 5)
Время работы алгоритма:
Время работы алгоритма Прима зависит от того, как реализована очередь с приоритетами Ω. Если использовать двоичную кучу, инициализацию в строках 1-4 можно выполнить за время O(V). Далее цикл выполняется |V| раз, и каждая операция EXTRACT-MІ отнимает время O (Vlog). Цикл for в строках 8-11 выполняется в целом O (E), поскольку сумма степеней вершин графа равна 2 |E| [14]. Проверку принадлежности в строке 9 можно выполнить за время O(1), если сохранять в состояние очереди еще и как битовый вектор размера |V|. Присвоение в строке 11 подразумевает выполнение операции уменьшения ключа (DECREASE-KEY), что для двоичной кучи может быть выполнено за время O (log). Таким образом всего получаем O (Vlog + Elog) = O (Elog).
Лучшую оценку можно получить, если использовать Фибоначчи кучи. С помощью фибоначевих куч можно выполнить операцию EXTRACT-MI за расчетное время O (log), а операцию DECREASE-KEY - за расчетное время O (1). В этом случае суммарное время работы алгоритма Прима составит O (E + Vlog).
4.2 Алгоритм Крускала
Алгоритм Крускала – алгоритм построения минимального скелетного дерева взвешенного неориентовного графа. Алгоритм был впервые описан Йозефом Крускалом в 1956 году[8].
Алгоритм Крускала объединяет вершины графа в несколько связных компонентов, каждый из которых является деревом. На каждом шагу по всем реберам, соединяющим вершины из разных компонентов по степени связи, выбирается ребро с наименьшим весом. Необходимо проверить, что оно является безопасным. Безопасность ребра гарантируется теоремой о безопасных ребрах. Потому что ребро является самым легким из всех ребер, выходящих из данной компоненты, оно будет безопасным.
Реализация выбора безопасного ребра на каждом шагу. Для этого в алгоритме Крускала все ребра графа G перебираются по возрастанию веса. Для очередного ребра проверяется, лежат ли концы ребра в различных компонентах уровня связи, и если это так, ребро добавляется и компоненты сочетаются [19].
Этот алгоритм удобно использовать для хранения компонент структуры данных для непересекающихся множеств, таких как, к примеру, списки или, что лучше, лес непересекающихся множеств со сжатием путей и объединением по рангу (один из самых быстрых известных методов). Элементами множеств являются вершины графа, каждое множество содержит вершины одной связанной компоненты.
Для работы с множествами используются следующие процедуры:
- Make-Set (v) - создание множества из набора вершин
- Fиnd-Set (v) - возвращает множество, содержащее данную вершину
- Union (u, v) - объединяет множества, содержащие данные вершины.
Общая схема алгоритма:
MST-KRUSKAL(G,w)
1: A < 0
2: foreach (для каждой) вершины v ∈ V[G]
3: do Make-Set(v)
4: сортироваль ребра по весу
5: for (u,v) ∈ E (в порядке увеличения веса)
6: do if Find-Set(u) ≠ Find-Set(v) then
7: A < A ∪ {(u,v)}
8: Union(u,v)
9: return A
Алгоритм
- Сначала ребра сортируют по возрастанию веса.
- Добавляют в дерево ребро с наименьшим весом
- Из списка ребер с наименьшим весом выбирают новое безопасное ребро
- Это ребро добавляют в дерево и снова переходят к шагу 3.
- Работа заканчивается, когда все вершины будут в дереве.
Пример выполнение алгоритма представлен на рисунке 2.
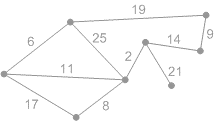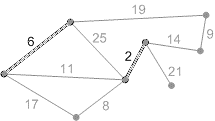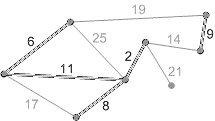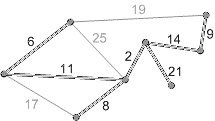
Рисунок 2 - Пример выполнение алгоритма Крускала (анимация - размер: 215 x 121 px, объем: 17.7 kb; кадров: 8; задержка между кадрами: 150мс., количество повторов 5)
Время работы алгоритма:
Для хранения непересекающихся множеств используется метод с объединением по рангу и сжатием путей, потому что это самый быстрый способ из известных на сегодняшний день. Инициализация занимает время O (V), упорядочения ребер в строке 4-O (Elog). Далее выполняется O (E) операций, которые вместе занимают O (Eα '(E, V)), где α' - функция, обратная к функции Аккермана [17]. Поскольку α'(E, V) = o (logE), общее время работы алгоритма Крускала составляет O (Elog) (основное время тратится на сортировку).
4.3 Алгоритм оптимизации муравьиной колонии
Муравьиный алгоритм (алгоритм оптимизации муравьиной колонии, англ. ant colony optimization, ACO) – один из эффективных полиномиальных алгоритмов для нахождения приближенных решений задачи коммивояжера, а также аналогичных задач поиска маршрутов на графах. Подход предложен бельгийским исследователем Марко Дориго[9]. Суть подхода заключается в анализе и использовании модели поведения муравьев, ищущих пути от колонии до еды.
В основе алгоритма лежит поведение муравьиной колонии – маркировка удачных дорог большим количеством феромона. Работа начинается с размещения муравьев в вершинах графа (городах), затем начинается движение муравьев – направление определяется вероятностным методом, на основании формулы:
![]()
где
Pi – вероятность перехода по пути
li – длина i-го перехода,
fi – количество феромонов на i-ом переходе
q – величина, определяющая «жадность» алгоритма,
p – величина, определяющая «стадность» алгоритма и q + p = 1.
Результат не является точным и даже может быть одним из худших, однако, в силу вероятности решения, повторение алгоритма может выдавать (достаточно) точный результат.
Алгоритм
Оригинальная идея исходит от наблюдения за муравьями в процессе поиска кратчайшего пути от колонии к источнику питания.
1. Первая муравей находит источник пищи (F) любым способом (а), а затем возвращается к гнезду (N), оставив за собой тропу с феромонов (b).
2. Затем муравьи выбирают один из четырех возможных путей, затем укрепляют его и делают привлекательным.
3. Муравьи выбирают кратчайший маршрут, потому что в более длинных феромоны сильнее испаряются.
Среди экспериментов на выбор между двумя путями неравной длины, ведущих от колонии к источнику питания, биологи заметили, что, как правило, муравьи используют кратчайший маршрут. Модель такого поведения заключается в следующем:
– Муравей (так называемый "Блиц") проходит случайным образом от колонии
– Если он находит источник пищи, то возвращается в гнездо, оставляя за собой след из феромона
– Эти феромоны привлекают других муравьев находящихся поблизости, которые вероятнее всего пойдут по этому маршруту
– Вернувшись в гнездо они укрепят феромонную тропу
– Если существует 2 маршрута, то более коротким, за то же время, успеют пройти больше муравьев, чем долгим
– Короткий маршрут станет более привлекательным
– Длинные пути, в конечном итоге, исчезнут через испарение феромонов
Муравьи используют окружающую среду как средство общения. Они обмениваются информацией косвенным путем, через феромоны, в ходе их «работы» . Обмен информации имеет локальный характер, только те муравьи, которые находятся в непосредственной близости к месту остатка феромонов – могут узнать о них. Такая система называется « Stigmergy » и справедлива для многих социальных животных (была изучена в случае строительства столбов в гнездах термитов). Данный механизм решения проблемы очень сложный и представляет хороший пример самоорганизации системы. Такая система базируется на положительном (другие муравьи укрепляют феромонные тропу) и отрицательном (испарение феромоны тропы) обратной связи. Теоретически, если количество феромонов будет оставаться неизменным со временем по всем маршрутам, то невозможно будет выбрать путь. Однако через обратную связь, небольшие колебания приведут к усилению одного из маршрутов и система стабилизируется к кратчайшему пути[18].
Механизм работы данного алгориму показан на рисунке 3.
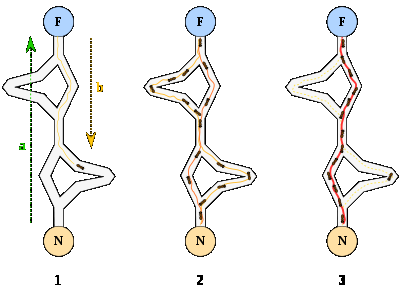
Рисунок 3 - Механизм работы алгоритма оптимизации муравьиной колонии
Пример: псевдо-код и формула
procedure ACO_MetaHeurіstіc
whіle(not_termіnatіon)
generateSolutіons()
daemonActіons()
pheromoneUpdate()
end whіle
end procedure
Ребра:
Муравей будет двигаться от узла i к узлу j с вероятностью
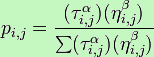
где
τi, j – количество феромонов на краю i, j
α – параметр воздействия на τi, j
ηi, j –желаемый край i, j (априорного знания, почти всегда, 1 / di, j, где d расстояние)
β – параметр воздействия на ηi, j.
Обновление феромонов
τi, j = (1 - ρ) τi, j + Δτi, j
где
τi, j – количество феромона на дуге i, j
ρ – скорость испарения феромона
Δτi, j – количество отложенного феромона, обычно определяется как
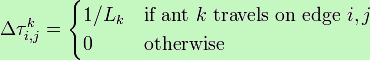
где
Lk – стоимость k-го пути муравья (обычно длина).
Области применения и возможные модификации:
Поскольку в основе муравьиного алгоритма лежит моделирование передвижения муравьев по некоторым путям, то такой подход может стать эффективным способом поиска рациональных решений для задач оптимизации, которые допускают графовую интерпретацию. Ряд экспериментов показывает, что эффективность муравьиных алгоритмов растет с ростом размерности решаемых задач оптимизации. Хорошие результаты получаются для нестационарных систем с меняющимися во времени параметрами, например, для расчетов телекоммуникационных и компьютерных сетей[20]. В настоящее время на основе применения муравьиных алгоритмов получены хорошие результаты для таких сложных оптимизационных задач, как задача коммивояжера, транспортная задача, задача календарного планирования, задача раскраски графа, квадратичное задача о назначении, задача оптимизации сетевых трафиков и ряд других.
Качество получаемых решений во многом зависит от настроек в вероятностно-пропорциональном правиле выбора пути на основе текущего количества феромона и от параметров правил отложения и испарения феромона. Возможно, что динамическое адаптационное настройки этих параметров может способствовать получению лучших решений. Немаловажную роль играет и начальное распределение феромона, а также выбор условно оптимального решения на этапе инициализации.
Перспективными путями улучшения муравьиных алгоритмов являются различные адаптации параметров с использованием базы нечетких правил и их гибридизация, например, с генетическими алгоритмами[10]. Как вариант, такая гибридизация может состоять в обмене через определенные промежутки времени текущими лучшими решениями.
Достоинства и недостатки алгорима муравиьных колоний
Если сравнивать алгоритм муравьиной колонии с генетическими алгоритмами то можно выделить ряд достоинств:
– Берут за основу память всей колонии вместо памяти только о предыдущее поколение
– Меньше подвержены неоптимальным начальным решениям (через случайный выбор пути и памяти колонии)
– Могут использоваться в динамических приложениях (адаптируются к изменениям)
– Применялись к множеству различных задач
Также алгоритм муравьиной колонии имеет ряд недостатков:
1. Теоретический анализ более тяжелый
– В результате последовательности случайных (не независимых) решений
– Распределения вероятностей меняется при итерациях
– Исследование более экспериментальное, чем теоретическое [5].
2. Сходимость гарантируется, но время сходимости не определено
3. Обычно необходимо применение дополнительных методов таких, как локальный поиск
4. Сильно зависят от параметров настройки, которые подбираются только исходя из экспериментов
4.4 Генетические алгоритмы
Генетический алгоритм – это эволюционный алгоритм поиска, который используется для решения задач оптимизации и моделирования путем последовательного подбора, комбинирования и вариации искомых параметров с использованием механизмов, напоминающих биологическую эволюцию.
Генетический алгоритм разработан Джоном Холланд в 1975 году в Мичиганского университете[11]. В дальнейшем Д. Голдберг выдвинул ряд гипотез и теорий, которые помогают глубже понять природу генетических алгоритмов. К.Деджонг первым обратил внимание на важность настройки параметров генетического алгоритма для общей эффективности работы и предложил свой оптимальный вариант подбора параметров который послужил основой для всех дальнейших исследований. Существенный вклад в эти исследования внесли Дж. Грефенстетт и Г. Сесверда.
Генетический алгоритм был получен в процессе обобщения и имитации в искусственных системах таких свойств живой природы, как естественный отбор, приспособляемость к изменяющимся условиям, среде, наследование потомками жизненно важных свойств от родителей и т.д.[4]. Из-за того, что алгоритм в процессе поиска использует некоторое кодирование множества параметров вместо самих параметров, он может эффективно применяться для решения задач дискретной оптимизации, нанесенных как на числовых множествах, так и на конечных множествах произвольной природы. Поскольку для работы алгоритма как информация об оптимизации функции используются лишь ее значения в рассматриваемых точках пространства поиска и не требуется вычислений ни производных, ни каких-либо других характеристик, то данный алгоритм может быть применен к широкому классу функций, в частности, к тем, которые не имеют аналитического описания. Использование набора начальных точек позволяет применять для их формирования различные способы, которые зависят от специфики решаемой задачи, в том числе возможно задание такого набора непосредственно человеком.
Сила генетических алгоритмов в том, что этот метод очень гибкий, и, будучи построенным в предположении, что об окружающей среде нам известно лишь минимум информации, алгоритм успешно справляется с широким кругом проблем, особенно в тех задачах, где не существует общеизвестных алгоритмов решения или высока степень априорной неопределенности.
Общее описание алгоритма:
Задача кодируется таким образом, чтобы ее решения могло быть представлено в виде массива подобной информации о составе хромосомы. Этот массив часто называют именно так «хромосома»[12]. Случайным образом в массиве создается некоторое количество начальных элементов «особей», или начальную популяцию. Особи оцениваются с использованием функции приспособления, в результате которой каждой особи присваивается определенное значение приспособленности, которое определяет возможность выживания особи. После этого с использованием полученных значений приспособленности выбираются особи допущеные к скрещиванию (селекции). К особам применяется «генетические операторы» (в большинстве случаев это оператор скрещивания (crossover) и оператор мутации (mutation), создавая таким образом следующее поколение особей. Особи следующего поколения также оцениваются применением генетических операторов и выполнением селекции и мутации. Так моделируется эволюционный процесс, который продолжается несколько жизненных циклов (поколений), пока не будет выполнено критерий остановки алгоритма. Таким критерием может быть:
– нахождение глобального или надоптимального решения
– исчерпание числа поколений, которые отпущены на эволюцию
– заданного времени, отпущенного на эволюцию.
Генетические алгоритмы могут использоваться для поиска решений в очень больших и тяжелых просторах поиска[16].
Для более точного решения задачу надо разделить. Можно выделить следующие этапы генетического алгоритма.
1. Создание начальной популяции
2. Вычисление функции приспособленности (фитнес-функции) для особей популяции (оценки)
3. Повторение к выполнению критерия остановки алгоритма
– Выбор индивидов из текущей популяции (селекция)
– Скрещение и/или мутация
– Вычисление функции приспособляемости для всех особей
– Формирование нового поколения.
Схема работы генетического алгоритма показана на рисунке 4.
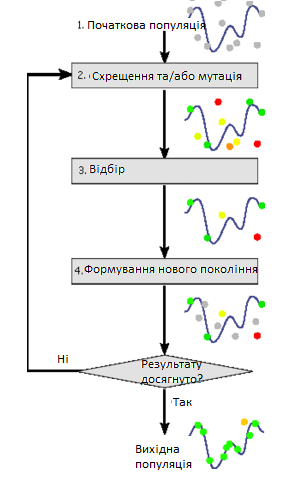
Рисунок 4 - Схема работы генетического алгоритма
4.5 Нейронные сети
Искусственные нейронные сети – математические модели, а также их программная и аппаратная реализация, построенные по принципу и функционирования биологических нейронных сетей – сетей нервных клеток живого организма. Системы, архитектура и принцип действия основан на аналогии с мозгом живых существ. Ключевым элементом этих систем выступает искусственный нейрон как имитационная модель нервной клетки мозга – биологического нейрона. Данный термин возник при изучении процессов, происходящих в мозгу, и при попытке смоделировать эти процессы. Первой такой попыткой были нейронные сети Маккалока и Питтса[16]. Как следствие, после разработки алгоритмов обучения, полученные модели стали использоваться в практических целях: в задачах прогнозирования, для распознавания образов, в задачах управления и других.
Направление связи от одного нейрона к другому является важным аспектом нейросетей. В большинстве сетей каждый нейрон скрытого слоя получает сигналы от всех нейронов предыдущего слоя и обычно от нейронов входного слоя. После выполнения операций над сигналами, нейрон передает свой выход для всех нейронов следующих слоев, обеспечивая путь передачи вперед (feedforward) на выход.
При обратной связи, выход нейронов слоя направляется к нейронам предыдущего слоя, что показано на рисунке 5.
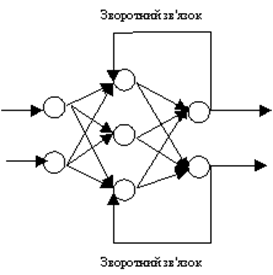
Рисунок 5 - Схема работы нейронных сетей при обратной связи
Путь, которым нейроны соединяются между собой имеет значительное влияние на работу сети. Большинство пакетов профессиональной разработки программного обеспечения позволяют пользователю добавлять, удалять и управлять подключениями как угодно[16]. Постоянно корректируя параметры связи можно делать как возбуждающими так и тормозящими.
Этапы решения задач
– Сбор данных для обучения
– Подготовка и нормализация данных
– Выбор топологии сети
– Экспериментальный подбор характеристик сети
– Экспериментальный подбор параметров обучения
– Обучение
– Проверка адекватности обучения
– Корректировка параметров, окончательное обучения
5. Исследование и анализ алгоритмов построения топологии сетей в классе древовидных структур
При организации дистанционного обучения можно использовать как выделенную сеть, так и всемирную глобальную сеть Internet.
Поскольку сети обучения связываются в одном обучающем центре в древовидную структуру, поэтому для формирования сети обучения можно использовать алгоритмы построения минимального остовного дерева. Существуют точные и эвристические алгоритмы позволяют решить эту задачу. Наиболее распространенными среди точных являются алгоритмы Прима, Крускала, Шарма, Исау-Вильямса и Фогеля [1,3].
Для решения поставленной задачи (организация компьютерной сети обучения) на вход необходимо подать связанного неориентированного графа G = (V, E), где V – число вершин, а Е – количество ребер (набор связей), W (и, j) – вес ребра, показывает стоимость использования связи соединения i и j. Нужно найти ациклические подмножество, соединяющая все вершины, ту, общий вес которой минимален.
Вычислительная сложность алгоритмов (время работы) зависит от способа хранения вершин. Если граф представлен в виде матрицы смежности, то время работы алгоритма Прима будет составлять O (V2). Теоретический время работы алгоритма Крускала напрямую зависит от времени сортировки ребер и составляет O (E * lg (V)). При использовании фибоначчивих пирамид алгоритм Прима можно ускорить до O (E + V * lg (V)), что является достаточно существенным ускорением при | V | << | E |.
Для практического решения задачи размерностей большого порядка обычные традиционные методы синтеза топологии сети не пригодны, возникает проблема – разработка эффективных приближенных методов.
Среди множества эвристических алгоритмов, можно выделить два класса. Один основан на алгоритме нахождения минимального стягивающего дерева (MST (Mиnиmum Spannиng Tree). Другой класс основан на классическом подходе нахождения кратчайшего маршрута – «от точки к точке» или алгоритме построения леса (Forest Buиld Tree – FBT).
Два алгоритмы, KMB (Kou, Markowsky, Berman) и RS (Rayward-Smith) известны как наиболее типичные в двух классах[6].
К эвристическим алгоритмам можно отнести генетические алгоритмы и алгоритмы построения муравьиной колонии.
Сравнительный анализ работы алгоритмов проводился в «Системе проектирования топологии и оптимизации сетей» . Как среда разработки программного обеспечения была выбрана среда Embarcadero ® RAD Studиo 2010 Версия 14.0 компании Embarcadero Technologies, Inc. Для визуализации результатов использовалась система на рабочей станции AMD Athlon Х2 (CPU 2200 MHz, RAM 2048 Mb).
В работе приводится оценка работы алгоритмов синтеза топологии сетей в классе древовидных структур с расстоянием (общая длина стягивающей дерева) и времени вычислений, а также рост времени вычислений при увеличении числа вершин в графе.
Исходя из полученных результатов, можно сделать вывод, что для небольшого числа узлов точные алгоритмы применять более выгодно. Лучшие показатели среди точных дает алгоритм Прима.
С увеличением количества вершин, время вычислений растет, поэтому эвристические методы позволяют решать задачи за разумное время вычисления. Двумя основными критериями, которые оценивают эти алгоритмы, является скорость сходимости и близость полученого решения к оптимальному или к лучшему решению.
Оба алгоритма KMB и RS имеют низкую производительность, чем MST и FBT но дают решения, ближе к оптимальному.
При реализации алгоритма построения муравьиной колонии важным показателем от которого зависит вычислительная сложность является выбор стратегии поиска.
Исследование генетического алгоритма показывают, что для уменьшения времени вычислений целесообразно выделять области исходных данных для создания начальных популяций.
Выводы
Существует много алгоритмов синтеза и оптимизации топологии сетей в классе древовидных структур. В зависимости от способа реализации время работы каждого из них различно.
В рамках проведенных исследований выполнено:
1. Обзор точных и еврестичних алгоритмов решения задачи синтеза топологии сетей в классе древовидных структур
2. Были сравнены результаты работы точных и еврестичних алгоритмов, сделан вывод об эффективности
3. Проанализирована работа алгоритмов Прима, Крускала, KMB, RS, MST и FBT
4. Рассмотрен принцип действия и время работы алгоритмов муравьиных колоний и генетических алгоритмов
5. Была сравнена работа перечисленных алгоритмов, сделан вывод об эффективности.
Дальнейшие исследования направлены на следующие аспекты:
- Выборе оптимальной схемы синтеза топологии сетей в классе древовидных структур
- Программной реализации выбранной схемы
- Анализе результатов работы программного обеспечения
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2012 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Перечень ссылок
- Кормен Т. Аглоритмы: построение и анализ, 2-е издание. Пер. с англ. / Т.Кормен, Ч.Лейзерсон, Р.Ривест. – М. : Издательский дом «Вильямс», 2005. – 1296 с.
- Кристофидес Н. Теория графов. Алгоритмический подход [Электронный ресурс]. – Режим доступа: http://mirknig.com/knigi/nauka_ucheba/1529-teorija_grafov.html
- Ахо Альфред В. Структуры данных и алгоритмы / Альфред В. Ахо, Джон Э. Хопкрофт, Джеффри Д. Ульман – М. : Издательский дом «Вильямс», 2003. – 384 с.
- Лекции по курсу «Компьютерная дискретная математика» [Электронный ресурс]. – Режим доступа: http://itlcvs.wordpress.com/2011/09/06/лекции-по-курсу-компьютерная-дискрет/
- Бондаренко М. Ф., Білоус Н. В., Руткас А. Г. Комп'ютерна дискретна математика [Электронный ресурс]. – Режим доступа: http://pikkalo.com/2700-kompyuterna-diskretna-matematika.html
- Guo-Quing Hu. Forest build tree algorithms for multiple destinations // The Potential. №3, 1998.- с. 13-16.
- Алексеев В.Е. Графы. Модели вычислений. Структуры данных [Электронный ресурс]. – Режим доступа: http://mirknig.com/knigi/estesstv_nauki/1181451717-grafy-modeli-vychisleniy-struktury-dannyh.html
- Топп У. Структуры данных в С++ / У. Топп, У. Форд; [пер. с англ.] – М.: ЗАО «Издательство БИНОМ», 1999. – 816 с.
- Мартин Дж. Планирование развития автоматизированных систем / Мартин Дж. – М. : Финансы и статистика, 1984. – 196 с.
- Трамбле Ж., Соренсон П. Введение в структуры данных [Электронный ресурс]. – Режим доступа: http://mirknig.com/knigi/os_bd/1181478197-vvedenie-v-struktury-dannyh.html
- Руденко В.Д. Курс информатики / В.Д. Руденко, А.М. Макарчук, М.А. Патланжоглу. – К. : Феникс, 2000. – С. 230-235.
- Татт У. Теория графов [Электронный ресурс]. – Режим доступа: http://www.kodges.ru/15890-teorija-grafov.html
- Вирт Н. Алгоритмы и структуры данных / Вирт Н. – [2-е изд.] – СПб.: Невский Диалект, 2001. – 352 с.
- Седжвик Р. Фундаментальные алгоритмы на С++. Алгоритмы на графах / Седжвик Р. – СПб.: ООО «ДиаСофтЮП», 2002 – 496 с.
- Субботін С.О. Неітеративні, еволюційні та мультиагентні методи синтезу нечіткологічних і нейромережних моделей: Монографія / С.О. Субботін, А.О. Олійник, О.О. Олійник. – Запоріжжя: ЗНТУ, 2009. – 375 с.
- Зингеренко Ю. Основы построения телекоммуникационных систем и сетей [Электронный ресурс]. – Режим доступа: http://mirknig.com/knigi/seti/1181446491-osnovy-postroeniya-telekommunikacionnyh-sistem-i-setey.html
- Седжвик Р. Фундаментальные алгоритмы на С++. Анализ. Структуры данных. Сортировка. Поиск. / Седжвик Р. – К.: «ДиаСофт», 2001 – 688 с.
- Свами М., Тхуласираман К. Графы, сети, алгоритмы [Электронный ресурс]. – Режим доступа: http://www.kodges.ru/131137-grafy-seti-algoritmy.html
- Tree data structure [Электронный ресурс]. – Режим доступа: http://ideainfo.8m.com/
- Глебовский А.Ю. Исследование и разработка методов и средств повышения структурной и функциональной устойчивости научных и университетских сетей [Электронный ресурс]. – Режим доступа: http://www.dissercat.com/content/issledovanie-i-razrabotka-metodov-i-sredstv-povysheniya-strukturnoi-i-funktsionalnoi-ustoic