
Реферат за темою: «Дослідження та розробка програмного забезпечення системи синтезу та оптимізації топології мереж у классі деревоподібних структур»
Зміст
- 1. Актуальність теми
- 2. Мета і задачі дослідження та заплановані результати
- 3. Наукова новизна
- 4. Огляд досліджень та розробок
- 4.1 Алгоритм Прима
- 4.2 Алгоритм Крускала
- 4.3 Алгоритм оптимізації мурашиної колонії
- 4.4 Генетичні алгоритми
- 4.5 Нейронні мережі
- 5. Дослідження і аналіз алгоритмів побудови топології мереж у класі деревоподібних структур
- Висновки
- Перелік посилань
1. Актуальність теми
Завдання знаходження найкоротшого (або оптимального) шляху постійно актуальна. У наш час до області вирішення транспортних завдань додалася нова – доставка освіти в різні точки земної кулі. Однією з основних проблем для мереж дистанційного навчання став пошук оптимального маршруту пересилання даних, тому що для якісного дистанційного навчання ВНЗ повинен тісно співробітничати зі студентами. Важливим є можливість швидко й без втрат доставити вихідну інформацію.
2. Мета і задачі дослідження та заплановані результати
Метою дослідження є аналіз та розробка програмного забезпечення системи синтезу та оптимізації топології мереж у классі деревоподібних структур.
Завдання дослідження:
1. Огляд існуючих підходів до вирішення задачі синтезу топології мереж у классі деревоподібних структур
2. Аналіз конкретних алгоритмів синтезу топології мереж
3. Вибір оптимальної схеми синтезу топології мереж у классі деревоподібних структур
4. Програмна реалізація обраної схеми
5. Аналіз результатів роботи програмного забезпечення
Заплановані результати:
1. Вдосконалення існуючих методів синтезу топології мереж
2. Підвищення якості передачі данних в системах дистанційної освіти
3. Порівняння розробленої системи з існуючими аналогами
3. Наукова новизна
Для якісного дистанційного навчання ВНЗ повинен тісно співробітничати зі студентами. На данний момент існує не так багато систем, які можуть забезпечувати безперебійну доставку освіти в різні точки земної кулі. Недоліком існуючих систем є повільна робота та інколи втрата інформції. Система, яка розробляється, повинна позбутися існуючих на данний момент загальних джерел неефективної роботи.
4. Огляд досліджень та розробок
Перш ніж почати аналіз існуючих алгоритмів треба визначитися з деякими термінами. Кістякове дерево зв'язаного неорієнтованого графа – ациклічний зв'язний підграф цього графа, який містить всі його вершини. Кістякове дерево складається з деякої підмножини ребер графа, таких, що рухаючись цими ребрами можна з будь-якої вершини графа потрапити до будь-якої іншої. Кістякове дерево також називають каркасним деревом, покриваючим деревом, кістяком або каркасом графа.
4.1 Алгоритм Прима
Алгоритм Прима – алгоритм побудови мінімального кістякового дерева.
Принцип дії такого алгоритму полягає в тому що на кожному кроці ми додаємо до споруджуваного кістяка безпечне ребро. Алгоритм Прима відноситься до групи алгоритмів нарощування мінімального кістяка: на кожному кроці існує не більше однієї нетривіальної (не складається з однієї вершини) компоненти зв’язності, і кожний раз до неї додається ребро найменшої ваги, яке з'єднує вершини компоненти з іншими вершинами. За теоремою таке ребро є безпечним[2].
При реалізації треба вміти на кожному кроці швидко вибирати безпечне ребро. Для цього зручно використовувати чергу з пріоритетами (купу)[7]. Алгоритм одержує на вхід граф G і його корінь r – вершина, на якій буде нарощуватися мінімальний кістяк. Всі вершини G, що ще не потрапили в дерево, зберігаються в черзі із пріоритетом Ω. Пріоритет вершини v визначається значенням key[v], що дорівнює мінімальній вазі ребер, які з'єднують v з вершинами мінімального кістяка. Поле p[v] для вершин дерева вказує на батьків, а для вершин із черги, вказує на ноду дерева, до якого веде ребро з вагою key[v] (одне з таких ребер, якщо їх декілька)[13].
Загальна схема алгоритму:
MST-PRIM(G,w, r)
1: Ω < V[G]
2: foreach (для кожної) вершини u ∈ Ω
3: do key[u] < ∞
4: key[r] < 0
5: p[r] = NIL
6: while (пока) Ω ≠ 0
7: do u < EXTRACT-MIN(Ω)
8: foreach (для кожної) вершини v ∈ Adj(u)
9: do if v ∈ Ω и w(u,v) < key[v] then
10: p[v] < u
11: key[v] < w(u,v)
Алгоритм:
- Спочатку ребра сортують за зростанням ваги.
- Додають найменше ребро в дерево, пов’язане з вершиною графа.
- Зі списку ребер із найменшою вагою вибирають таке нове ребро, щоб одна з його вершин належала дереву, а інша – ні.
- Це ребро додають у дерево і знову переходять до кроку 3.
- Робота закінчується, коли всі вершини будуть у дереві.
Схема роботи алгоритму Прима з коренем r приведена на рисунку 1.
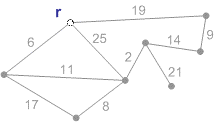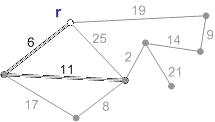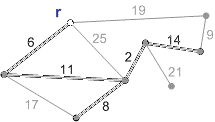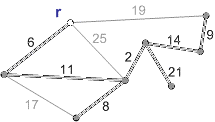
Рисунок 1 – Схема роботи алгоритму Прима (анімація – розмір: 215 x 122 px; обсяг: 19.9 kb; кадрів: 8; затримка між кадрами: 150мс.; кількість повторів: 5)
Час роботи алгоритму:
Час роботи алгоритму Прима залежить від того, як реалізована черга з пріоритетами ?. Якщо використати двійкову купу, ініціалізацію в рядках 1-4 можна виконати за час O(V). Далі цикл виконується |V| раз, і кожна операція EXTRACT-MІ забирає час O(Vlog). Цикл for у рядках 8-11 виконується в цілому O(E), оскільки сума ступенів вершин графа дорівнює 2|E|[14]. Перевірку приналежності в рядку 9 можна виконати за час O(1), якщо зберігати у стан черги ще і як бітовий вектор розміру |V|. Присвоювання в рядку 11 має на увазі виконання операції зменшення ключа (DECREASE-KEY), що для двійкової купи може бути виконана за час O(log). У такий спосіб усього одержуємо O(Vlog+Elog)=O(Elog).
Кращу оцінку можна одержати, якщо використати фібоначеві купи. За допомогою фібоначевих куп можна виконати операцію EXTRACT-MІ за розрахунковий час O(log), а операцію DECREASE-KEY – за розрахуноквий час O(1). У цьому випадку сумарний час роботи алгоритму Прима складе O(E+Vlog).
4.2 Алгоритм Крускала
Алгоритм Крускала – алгоритм побудови мінімального кістякового дерева зваженого неорієнтовного графа. Алгоритм було вперше описано Джозефом Крускалом 1956 року[8].
Алгоритм Крускала об’єднує вершини графа в кілька зв'язних компонентів, кожна з яких є деревом. На кожному кроці з усіх ребер, що з'єднують вершини з різних компонентів за рівнем зв’язку, вибирається ребро з найменшою вагою. Необхідно перевірити, що воно є безпечним. Безпека ребра гарантується теоремою про безпечні ребра. Тому що ребро є найлегшим із всіх ребер, які виходять з даної компоненти, воно буде безпечним.
Реалізація вибору безпечного ребра на кожному кроці. Для цього в алгоритмі Крускала всі ребра графа G перебираються за зростанням ваги. Для чергового ребра перевіряється, чи не лежать кінці ребра в різних компонентах рівня зв’язку, і якщо це так, ребро додається, і компоненти поєднуються[19].
Цей алгоритм зручно використати для зберігання компонент структури даних для непересічних множин, як, наприклад, списки або, що краще, ліс непересічних множин зі стиском шляхів і об'єднанням за рангом (один з найшвидших відомих методів). Елементами множин є вершини графа, кожна множина містить вершини однієї зв'язаної компоненти.
Для роботи з множинами використаються наступні процедури:
- Make-Set(v) – створення множини з набору вершин
- Fіnd-Set(v) – повертає множину, що містить дану вершину
- Unіon(u,v) – поєднує множини, що містять дані вершини.
Загальна схема алгоритму:
MST-KRUSKAL(G,w)
1: A < 0
2: foreach (для кожної) вершини v ∈ V[G]
3: do Make-Set(v)
4: упорядкувати ребра за вагою
5: for (u,v) ∈ E (у порядку зростання ваги)
6: do if Find-Set(u) ≠ Find-Set(v) then
7: A < A ∪ {(u,v)}
8: Union(u,v)
9: return A
Алгоритм:
- Спочатку ребра сортують за зростанням ваги.
- Додають в дерево ребро з найменшою вагою
- Зі списку ребер із найменшою вагою вибирають нове безпечне ребро
- Це ребро додають у дерево і знову переходять до кроку 3.
- Робота закінчується, коли всі вершини будуть у дереві.
Приклад виконування алгоритму представлений на рисунку 2.
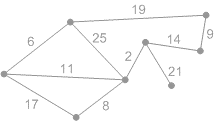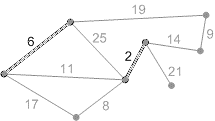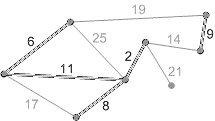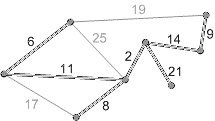
Рисунок 2 – Приклад виконування алгоритму Крускала (анімація – розмір: 215 x 121 px; обсяг: 17.7 kb; кадрів: 8; затримка між кадрами: 150мс.; кількість повторів: 5)
Час роботи алгоритму:
Для зберігання непересічних множин використається метод з об'єднанням за рангом і стиском шляхів , тому що це найшвидший спосіб з відомих на сьогоднішній день. Ініціалізація забирає час O(V), упорядкування ребер у рядку 4-O(Elog). Далі виконується O(E) операцій, які разом займають O(Eα’(E,V)), де α’ - функція, зворотна до функції Акермана[17]. Оскільки α’(E,V) = o(logE), загальний час роботи алгоритму Крускала становить O(Elog) (основний час витрачається на сортування).
4.3 Алгоритм оптимізації мурашиної колонії
Мурашиний алгоритм (алгоритм оптимізації мурашиної колонії, англ. ant colony optimization, ACO) – один з ефективних поліноміальних алгоритмів для знаходження наближених рішень задачі комівояжера, а також аналогічних завдань пошуку маршрутів на графах. Підхід запропонований бельгійським дослідником Марко Доріго[9]. Суть підходу полягає в аналізі та використанні моделі поведінки мурах, що шукають дороги від колонії до їжі.
У основі алгоритму лежить поведінка мурашиної колонії – маркування вдалих доріг великою кількістю феромону. Робота починається з розміщення мурашок у вершинах графа (містах), потім починається рух мурашок – напрям визначається імовірнісним методом, на підставі формули:
![]()
де:
Pi – вірогідність переходу по дорозі,
li – довжина i-ого переходу,
fi – кількість феромонів на i-ому переході,
q – величина, яка визначає «жадібність» алгоритму,
p – величина, яка визначає «стадність» алгоритму і q + p = 1.
Результат не є точним і навіть може бути одним з гірших, проте, в силу імовірності рішення, повторення алгоритму може видавати (досить) точний результат.
Алгоритм:
Оригінальна ідея виходить від спостереження за мурахами в процесі пошуку найкоротшого шляху від колонії до джерела харчування.
1. Перша мураха знаходить джерело їжі (F) будь-яким способом (а), а потім вертається до гнізда (N), залишивши за собою тропу з феромонов (b).
2. Потім мурахи вибирають один із чотирьох можливих шляхів, потім зміцнюють його й роблять привабливим.
3. Мурахи вибирають найкоротший маршрут, тому що у більш довгих феромони сильніше випаровуються.
Серед експериментів на вибір між двома шляхами нерівної довжини, ведучих від колонії до джерела харчування, біологи помітили, що, як правило, мурахи використають найкоротший маршрут. Модель такого поводження полягає в наступному:
– Мураха (так званий «Бліц») проходить випадковим образом від колонії
– Якщо він знаходить джерело їжі, то вертається в гніздо, залишаючи за собою слід з феромона
– Ці феромоны залучають інших мурах находящихся поблизу, які найімовірніше підуть по цьому маршруті
– Повернувшись у гніздо вони зміцнять феромонную тропу
– Якщо існує 2 маршрути, то більш коротким, за той самий час, встигнуть пройти більше мурах, аніж довгим
– Короткий маршрут стане більше привабливим
– Довгі шляхи, в остаточному підсумку, зникнуть через випар феромонів
Мурахи використають навколишнє середовище як засіб спілкування. Вони обмінюються інформацією непрямим шляхом, через феромони, у ході їх «роботи». Обмін інформації має локальний характер, тільки ті мурахи, які перебувають у безпосередній близькості до місця залишку феромонів – можуть довідатися про їх. Така система називається «Stіgmergy» і справедлива для багатьох соціальних тварин (був вивчений у випадку будівництва стовпів у гніздах термітів). Даний механізм рішення проблеми дуже складний і являє гарний приклад самоорганізації системи. Така система базується на позитивному (інші мурахи зміцнюють феромонну тропу) і негативному (випар феромонної тропи) зворотньому зв'язку. Теоретично, якщо кількість феромонів буде залишатися незмінною із часом по всіх маршрутах, то неможливо буде вибрати шлях. Однак через зворотний зв'язок, невеликі коливання приведуть до посилення одного з маршрутів і система стабілізується до найкоротшого шляху[18].
Механізм роботи данного алгориму зазданачено на рисунку 3.
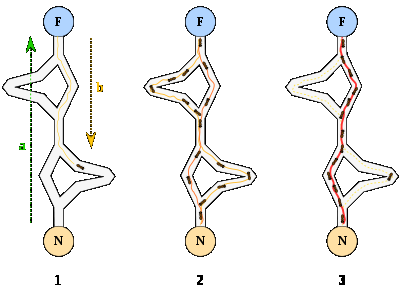
Рисунок 3 – Механізм роботи алгоритма оптимізації мурашиної колонії
Приклад: псевдо-код і формула:
procedure ACO_MetaHeurіstіc
whіle(not_termіnatіon)
generateSolutіons()
daemonActіons()
pheromoneUpdate()
end whіle
end procedure
Ребра:
Мураха буде рухатися від вузла i до вузла j з імовірністю
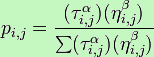
де:
τi,j – це кількість феромонів на краю i,j;
α – параметр впливу на τi,j;
ηi,j – бажаний край i,j (апріорного знання, майже завжди, 1 / di,j, де d відстань);
β – параметр впливу на ηi,j.
Оновлення феромонів
τi,j = (1 - ρ)τi,j + Δτi,j
де:
τi,j – кількість феромону на дузі i,j
ρ – швидкість випарення феромону
Δτi,j – кількість відкладеного феромону, зазвичай визначається як
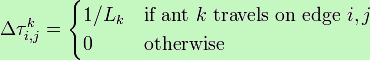
де:
Lk – вартість k-го шляху мурахи (зазвичай довжина).
Області застосування й можливі модифікації:
Оскільки в основі мурашиного алгоритму лежить моделювання пересування мурах по деяких шляхах, то такий підхід може стати ефективним способом пошуку раціональних рішень для завдань оптимізації, що допускають графовую інтерпретацію. Ряд експериментів показує, що ефективність мурашиних алгоритмів росте з ростом розмірності розв'язуваних завдань оптимізації. Гарні результати виходять для нестаціонарних систем зі змінюваними в часі параметрами, наприклад, для розрахунків телекомунікаційних і комп'ютерних мереж[20]. В цей час на основі застосування мурашиних алгоритмів отримані гарні результати для таких складних оптимізаційних завдань, як завдання комівояжера, транспортне завдання, завдання календарного планування, завдання розфарбування графа, квадратичне завдання про призначення, завдання оптимізації мережних трафиков і ряд інших.
Якість одержуваних рішень багато в чому залежить від параметрів налаштування у ймовірносно-пропорційному правилі вибору шляху на основі поточної кількості феромона й від параметрів правил відкладання й випарення феромона. Можливо, що динамічне адаптаційне настроювання цих параметрів може сприяти одержанню кращих рішень. Немаловажну роль відіграє й початковий розподіл феромона, а також вибір умовно оптимального рішення на кроці ініціалізації.
Перспективними шляхами поліпшення мурашиних алгоритмів є різні адаптації параметрів з використанням бази нечітких правил та їхня гібридизація, наприклад, з генетичними алгоритмами[10]. Як варіант, така гібридизація може складатися в обміні через певні проміжки часу поточними найкращими рішеннями.
Достоїнства та недоліки алгориму мураших колоній:
Якщо порівнювати алгоритм мурашиної колонії з генетичними алгоритмами то можна виділити ряд достоїнств:
– Беруть за основу пам'ять про всю колонію замість пам'яті тільки про попереднє покоління
– Менше піддані неоптимальним початковим рішенням (через випадковий вибір шляху й пам'яті колонії)
– Можуть використатися в динамічних додатках (адаптуються до змін)
– Застосовувалися до безлічі різних завдань
Також алгоритм мурашиної колонії має ряд недоліків:
1. Теоретичний аналіз більш важкий:
– В результаті послідовності випадкових (не незалежних) рішень;
– Розподілу ймовірностей міняється при ітераціях;
– Дослідження більше експериментальне, аніж теоретичне[5].
2. Збіжність гарантується, але час збіжності не визначено
3. Звичай необхідне застосування додаткових методів таких, як локальний пошук
4. Сильно залежать від параметрів налаштувань, які підбираються тільки виходячи з експериментів
4.4 Генетичні алгоритми
Генетичний алгоритм – це еволюційний алгоритм пошуку, що використовується для вирішення задач оптимізації і моделювання шляхом послідовного підбору, комбінування і варіації шуканих параметрів з використанням механізмів, що нагадують біологічну еволюцію.
Генетичний алгоритм розроблений Джоном Голландом в 1975 році в Мічіганскому університеті[11]. Надалі Д. Голдберг висунув ряд гіпотез і теорій, що допомагають глибше зрозуміти природу генетичних алгоритмів. К.Деджонг першим звернув увагу на важливість налаштування параметрів генетичного алгоритму для загальної ефективності роботи й запропонував свій оптимальний варіант підбора параметрів, що послугував основою для всіх подальших досліджень. Істотний внесок у ці дослідження внесли Дж. Грефенстетт та Г. Сесверда.
Генетичний алгоритм був отриманий у процесі узагальнення й імітації в штучних системах таких властивостей живої природи, як природний відбір, пристосовність до умов, що змінюються, середовища, спадкування нащадками життєво важливих властивостей від батьків тощо[4]. Через те, що алгоритм у процесі пошуку використає деяке кодування безлічі параметрів замість самих параметрів, тому він може ефективно застосовуватися для рішення завдань дискретної оптимізації, завданих як на числових множинах, так і на кінцевих множинах довільної природи. Оскільки для роботи алгоритму як інформація про оптимізаційну функцію використовуються лише її значення у розглянутих точках простору пошуку й не потрібно обчислень ні похідних, ні будь-яких інших характеристик, то даний алгоритм може бути застосований до широкого класу функцій, зокрема, до тих, які не мають аналітичного опису. Використання набору початкових точок дозволяє застосовувати для їхнього формування різні способи, які залежать від специфіки розв'язуваного завдання, у тому числі можливе завдання такого набору безпосередньо людиною.
Сила генетичних алгоритмів у тому, що цей метод дуже гнучкий, та, будучи побудованим у припущенні, що про навколишню середу нам відомо лише мінімум інформації, алгоритм успішно справляється із широким колом проблем, особливо в тих завданнях, де не існує загальновідомих алгоритмів рішення або високий ступінь апріорної невизначеності.
Загальне описання алгоритму:
Задача кодується таким чином, щоб її вирішення могло бути представлено в вигляді масиву подібного до інформації складу хромосоми. Цей масив часто називають саме так «хромосома»[12]. Випадковим чином в масиві створюється деяка кількість початкових елементів «осіб», або початкова популяція. Особи оцінюються з використанням функції пристосування, в результаті якої кожній особі присвоюється певне значення пристосованості, яке визначає можливість виживання особи. Після цього з використанням отриманих значень пристосованості вибираються особи допущені до схрещення (селекція). До осіб застосовується "генетичні оператори" (в більшості випадків це оператор схрещення (crossover) і оператор мутації (mutation), створюючи таким чином наступне покоління осіб. Особи наступного покоління також оцінюються застосуванням генетичних операторів і виконується селекція і мутація. Так моделюється еволюційний процес, який продовжується декілька життєвих циклів (поколінь), поки не буде виконано критерій зупинки алгоритму. Таким критерієм може бути:
– знаходження глобального, або надоптимального вирішення;
– вичерпання числа поколінь, що відпущені на еволюцію;
– вичерпання часу, відпущеного на еволюцію.
Генетичні алгоритми можуть використатися для пошуку рішень в дуже великих і тяжких просторах пошуку[16].
Для більш точного рішення задачу треба розділити. Можна виділити такі етапи генетичного алгоритму:
1. Створення початкової популяції;
2. Обчислення функції пристосованості (фітнес-функції) для осіб популяції (оцінювання);
3. Повторювання до виконання критерію зупинки алгоритму:
– Вибір індивідів із поточної популяції (селекція);
– Схрещення або/та мутація;
– Обчислення функції пристосовуваності для всіх осіб;
– Формування нового покоління.
Схема роботи генетичного алгоритму зазначено на рисунку 4.
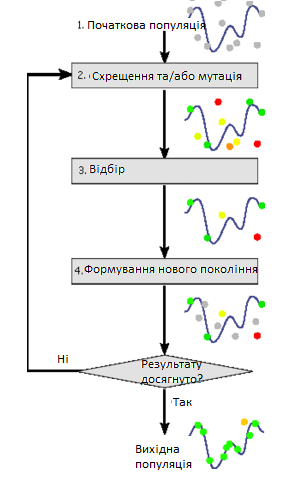
Рисунок 4 – Схема роботи генетичного алгоритму
4.5 Нейронні мережі
Штучні нейронні мережі – математичні моделі, а також їх програмна та апаратна реалізація, побудовані по принципу і функціонування біологічних нейронних мереж – мереж нервових клітин живого організму. Системи, архітектура і принцип дії базується на аналогії з мозком живих істот. Ключовим елементом цих систем виступає штучний нейрон як імітаційна модель нервової клітини мозку – біологічного нейрона. Даний термін виник при вивченні процесів, які відбуваються в мозку, та при спробі змоделювати ці процеси. Першою такою спробою були нейронні мережі Маккалока і Піттса[16]. Як наслідок, після розробки алгоритмів навчання, отримані моделі стали використовуватися в практичних цілях: в задачах прогнозування, для розпізнавання образів, в задачах керування та інші.
Напрямок зв'язку від одного нейрону до іншого є важливим аспектом нейромереж. У більшості мереж кожен нейрон прихованого прошарку отримує сигнали від всіх нейронів попереднього прошарку та звичайно від нейронів вхідного прошарку. Після виконання операцій над сигналами, нейрон передає свій вихід до всіх нейронів наступних прошарків, забезпечуючи шлях передачі вперед (feedforward) на вихід.
При зворотному зв'язку, вихід нейронів прошарку скеровується до нейронів попереднього прошарку, що відтворено на рисунку 5.
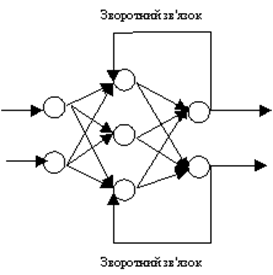
Рисунок 5 – Схема роботи нейронних мереж при зворотному зв'язку
Шлях, яким нейрони з'єднуються між собою має значний вплив на роботу мережі. Більшість пакетів професіональної розробки програмного забезпечення дозволяють користувачу додавати, вилучати та керувати з'єднаннями як завгодно[16]. Постійно корегуючи параметри, зв'язки можна робити як збуджуючими так і гальмуючими.
Етапи рішення завдань:
– Збір даних для навчання;
– Підготовка й нормалізація даних;
– Вибір топології мережі;
– Експериментальний підбір характеристик мережі;
– Експериментальний підбір параметрів навчання;
– Навчання;
– Перевірка адекватності навчання;
– Коректування параметрів, остаточне навчання
5. Дослідження і аналіз алгоритмів побудови топології мереж у класі деревоподібних структур
При організації дистанційного навчання можна використати як виділену мережу, так і всесвітню глобальну мережу Іnternet.
Оскільки мережі навчання зв'язуються в одному навчальному центрі в деревоподібну структуру, тому для формування мережі навчання можна використати алгоритми побудови мінімального остовного дерева. Існують точні та евристичні алгоритми що дозволяють вирішити це завдання. Найпоширенішими серед точних є алгоритми Прима, Крускала, Шарму, Исау-Вильямса й Фогеля[1,3].
Для вирішення поставленого завдання (організація комп'ютерної мережі навчання) на вхід необхідно подати зв'язаного неорієнтованого графа G=(V,E), де V – кількість вершин, а Е – кількість ребер (набір зв'язків), W(і,j) – вага ребра, показує вартість використання зв'язку з'єднання та і j. Потрібно знайти ациклічну підмножину, що з'єднує всі вершини, ту, загальна вага якої мінімальна.
Обчислювальна складність алгоритмів (час роботи) залежить від способу зберігання вершин. Якщо граф представлений у вигляді матриці суміжності, то час роботи алгоритму Прима буде становити O(V2). Теоретичний час роботи алгоритму Крускала прямо залежить від часу сортування ребер і становить O(E*lg(V)). При використанні фібоначчивих пірамід алгоритм Прима можна прискорити до O(E+V*lg(V)), що є доволі істотним прискоренням при |V|<<|E|.
Для практичного вирішення завдання розмірностей великого порядку звичайні традиційні методи синтезу топології мережі не придатні, виникає проблема – розробка ефективних наближених методів.
Серед безлічі евристичних алгоритмів, можна виділити два класи. Один заснований на алгоритмі знаходження мінімального стягуючого дерева (MST (Mіnіmum Spannіng Tree). Інший клас заснований на класичному підході знаходження найкоротшого маршруту –«від точки до точки» або алгоритмі побудови лісу (Forest Buіld Tree – FBT).
Два алгоритми, KMB (Kou, Markowsky, Berman) і RS (Rayward-Smіth) відомі як найбільш типові в цих двох класах[6].
До евристичних алгоритмів можна віднести генетичні алгоритми і алгоритми побудови мурашиної колонії.
Порівняльний аналіз роботи алгоритмів проводився в «Системі проектування топології та оптимізації мереж». Як середовище розробки програмного забезпечення було обране середовище Embarcadero® RAD Studіo 2010 версії 14.0 компанії Embarcadero Technologіes, Іnc. Для візуалізації результатів використовувалася система на робочій станції AMD Athlon Х2 (CPU 2200 MHz, RAM 2048 Mb).
В роботі приводиться оцінка роботи алгоритмів синтезу топології мереж у класі деревоподібних структур за відстаню (загальна довжина стягуючого дерева) і часу обчислень, а також зріст часу обчислень при збільшенні кількості вершин у графі.
Виходячи з отриманих результатів, можна зробити висновок, що для невеликого числа вузлів точні алгоритми застосовувати білш вигідно. Кращі показники серед точних дає алгоритм Прима.
Зі збільшенням кількості вершин, час обчислень зростає, тому евристичні методи дозволяють вирішувати завдання за розумний час обчислення. Двома основними критеріями, що оцінюють ці алгоритми, є швидкість збіжності і близькість одержуваного рішення до оптимального або ж до кращого рішення.
Обидва алгоритми KMB і RS мають нижчу продуктивність, ніж MST і FBT але дають рішення, ближче до оптимального.
При реалізації алгоритму побудови мурашиної колонії важливим показником від якого залежить обчислювальна складність є вибір стратегії пошуку.
Дослідження генетичного алгоритму показують, що для зменшення час обчислень доцільно виділяти області вихідних даних для створення початкових популяцій.
Висновки
Існує багато алгоритмів синтезу та оптимізації топології мереж у классі деревоподібних структур. В залежності від способу реалізації час праці кожного з них є різним.
В рамках проведених досліджень виконано:
1. Огляд точних та еврестичних алгоритмів вирішення задачі синтезу топології мереж у классі деревоподібних структур
2. Порівняно результати роботи точних і еврестичних алгоритмів, зроблено висновок щодо ефективності
3. Проаналізовано роботу алгоритмів Прима, Крускала, KMB, RS, MST и FBT
4. Розглянуто принцип дії і час роботи алгоритмів мурашиної колоніх та генетичних алгоритмів
5. Порівняно роботу перелічених алгоритмів, зроблено висновок щодо ефективності.
Подальші дослідження направлені на наступні аспекти:
- Виборі оптимальної схеми синтезу топології мереж у классі деревоподібних структур
- Програмній реалізації обраної схеми
- Аналізі результатів роботи програмного забезпечення
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2012 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після вказаної дати.
Перелік посилань
- Кормен Т. Аглоритмы: построение и анализ, 2-е издание. Пер. с англ. / Т.Кормен, Ч.Лейзерсон, Р.Ривест. – М. : Издательский дом «Вильямс», 2005. – 1296 с.
- Кристофидес Н. Теория графов. Алгоритмический подход [Електронний ресурс]. – Режим доступу: http://mirknig.com/knigi/nauka_ucheba/1529-teorija_grafov.html
- Ахо Альфред В. Структуры данных и алгоритмы / Альфред В. Ахо, Джон Э. Хопкрофт, Джеффри Д. Ульман – М. : Издательский дом «Вильямс», 2003. – 384 с.
- Лекции по курсу «Компьютерная дискретная математика» [Електронний ресурс]. – Режим доступу: http://itlcvs.wordpress.com/2011/09/06/лекции-по-курсу-компьютерная-дискрет/
- Бондаренко М. Ф., Білоус Н. В., Руткас А. Г. Комп'ютерна дискретна математика [Електронний ресурс]. – Режим доступу: http://pikkalo.com/2700-kompyuterna-diskretna-matematika.html
- Guo-Quing Hu. Forest build tree algorithms for multiple destinations // The Potential. №3, 1998.- с. 13-16.
- Алексеев В.Е. Графы. Модели вычислений. Структуры данных [Електронний ресурс]. – Режим доступу: http://mirknig.com/knigi/estesstv_nauki/1181451717-grafy-modeli-vychisleniy-struktury-dannyh.html
- Топп У. Структуры данных в С++ / У. Топп, У. Форд; [пер. с англ.] – М.: ЗАО «Издательство БИНОМ», 1999. – 816 с.
- Мартин Дж. Планирование развития автоматизированных систем / Мартин Дж. – М. : Финансы и статистика, 1984. – 196 с.
- Трамбле Ж., Соренсон П. Введение в структуры данных [Електронний ресурс]. – Режим доступу: http://mirknig.com/knigi/os_bd/1181478197-vvedenie-v-struktury-dannyh.html
- Руденко В.Д. Курс информатики / В.Д. Руденко, А.М. Макарчук, М.А. Патланжоглу. – К. : Феникс, 2000. – С. 230-235.
- Татт У. Теория графов [Електронний ресурс]. – Режим доступу: http://www.kodges.ru/15890-teorija-grafov.html
- Вирт Н. Алгоритмы и структуры данных / Вирт Н. – [2-е изд.] – СПб.: Невский Диалект, 2001. – 352 с.
- Седжвик Р. Фундаментальные алгоритмы на С++. Алгоритмы на графах / Седжвик Р. – СПб.: ООО «ДиаСофтЮП», 2002 – 496 с.
- Субботін С.О. Неітеративні, еволюційні та мультиагентні методи синтезу нечіткологічних і нейромережних моделей: Монографія / С.О. Субботін, А.О. Олійник, О.О. Олійник. – Запоріжжя: ЗНТУ, 2009. – 375 с.
- Зингеренко Ю. Основы построения телекоммуникационных систем и сетей [Електронний ресурс]. – Режим доступу: http://mirknig.com/knigi/seti/1181446491-osnovy-postroeniya-telekommunikacionnyh-sistem-i-setey.html
- Седжвик Р. Фундаментальные алгоритмы на С++. Анализ. Структуры данных. Сортировка. Поиск. / Седжвик Р. – К.: «ДиаСофт», 2001 – 688 с.
- Свами М., Тхуласираман К. Графы, сети, алгоритмы [Електронний ресурс]. – Режим доступу: http://www.kodges.ru/131137-grafy-seti-algoritmy.html
- Tree data structure [Електронний ресурс]. – Режим доступу: http://ideainfo.8m.com/
- Глебовский А.Ю. Исследование и разработка методов и средств повышения структурной и функциональной устойчивости научных и университетских сетей [Електронний ресурс]. – Режим доступу: http://www.dissercat.com/content/issledovanie-i-razrabotka-metodov-i-sredstv-povysheniya-strukturnoi-i-funktsionalnoi-ustoic