Система игрового искусственного интеллекта
Авторы: А. А. Алимов, О. А. Шабалина
Источник: Известия Волгоградского государственного технического университета. 2012. Т. 4. № 13. С. 166-169.
Авторы: А. А. Алимов, О. А. Шабалина
Источник: Известия Волгоградского государственного технического университета. 2012. Т. 4. № 13. С. 166-169.
искусственный интеллект, мультиагентные системы, виртуальная реальность.
В работе рассматривается программная система управления персонажами игрового виртуального мира на основе мультиагентного подхода. Внимание уделено управлению группами агентов, взаимодействию агентов и параллельному решению задач.
Разработка видеоигр – это активно развивающаяся индустрия. В компьютерных играх оппонентом человека часто выступает не другой человек, а искусственный интеллект (ИИ). Под игровым искусственным интеллектом понимают набор программных методик, которые используются в компьютерных играх для создания иллюзии интеллекта в поведении персонажей, управляемых компьютером, таких как юниты в стратегиях и несобственные персонажи в ролевых играх. Эти классы игр являются хорошей тестовой платформой для алгоритмов коллективного управления, поскольку позволяют наглядно отобразить результаты работы ИИ.
В общем случае все объекты виртуального мира игры можно классифицировать пассивные, интерактивные и активные. Пассивные объекты подчиняются только физике виртуального мира, активные действуют самостоятельно и принимают решения, интерактивные могут быть использованы активными.
Поведение активных объектов моделируется с использованием мульти-агентного подхода, и в дальнейшем активные объекты именуются агентами.
Спецификой игрового ИИ является сложность формализации поведения агентов. Пространство игры, как правило, не дискретно и количество состояний игры велико по сравнению с логическими играми. Сложность формализации не позволяется эффективно применять алгоритмы обучения и прогнозирования [1].
Целью работы является разработка программной системы, позволяющей эффективно реализовать поведение персонажей стратегических и ролевых игр.
В рассматриваемом классе игр агенты, как правило, выполняют [2]:
– решение задачи навигации: определение положения агента в пространстве и поиск пути между двумя точками в пространстве;
– реализацию индивидуальных действий агента: поведенческих реакций, принятия решений, выбор определенной тактики поведения или действия из нескольких возможных;
– параллельное решение задач: если у агента есть несколько целей, он должен уметь выбирать наиболее приоритетные или, по возможности, достигать их одновременно;
– реализацию коллективных действий: управление группами агентов, взаимодействие агентов, распределение целей, перемещение группами.
Исторически сложилось, что поведение оппонента программируется как частное решение, а не общее. На сегодняшний день существуют системы, решающие задачи игрового ИИ по отдельности, но систем, предлагающих эффективное комплексное решение, на момент проведения исследования обнаружено не было. Особого внимания заслуживают системы Unreal Development Kit (Epic games), Radiant AI (Bethesda Softworks) и A-Life (GSC).
UDK реализует конечно-автоматную модель поведения агентов и предлагает специализированный язык для реализации поведения [3]. Radiant AI определяет поведение агентов как последовательное решение определенных типовых задач. A-Life реализует управления группами агентов.
На основании анализа рассмотренных систем предложена концепция иерархической модели поведения, подробно описанная в [4]. Все действия агента можно классифицировать на элементарные, тактические и стратегические. Образуется иерархия уровней управления, где стратегические действия определяют цели агента и реализуют коллективное управление; тактические действия реализуют достижение цели; элементарные действия соответствуют состояниям агента (движение, ожидание). Параллельно агент может выполнять несколько действий на каждом уровне, что позволяет одновременно обрабатывать несколько целей.
Все объекты виртуального мира представлены как композиты графической, физической и поведенческой модели. Пассивные объекты не имеют поведенческой модели. Поведение интерактивных объектов не является интеллектуальным и представляет собой статически запрограммированные реакции на столкновение или использование другими объектами. Поведение активных объектов (агентов) можно представить следующей структурой:
Behaviour = FactBase, LogicSolver, PathMap, PathFinder, AIPackages, Actuators,
где FactBase – множество предикатов вида Statement (e1, e2, ... , en), в которых содержатся знания о мире и закономерности; LogicSolver – алгоритм логического вывода, входом которого является предикат, а выходом – логическое значение, соответствующее истинности предиката; Actuators – множество эффекторов (манипуляторов) агента; PathMap – карта путей, которая используется для решения задачи навигации; PathFinder – алгоритм поиска оптимального маршрута; AIPackages – множество используемых пакетов ИИ.
Пакеты ИИ в разрабатываемой системе аналогичны пакетам ИИ в системе Radiant AI и используются для хранения информации о доступных действиях агента. Каждый пакет описывается следующей структурой:
AIPackage = ActionType, TargetGenerator, Condition, Schedule, Flags,
где ActionType – класс действия, которое агент начнет выполнять; TargetGenerator – алгоритм выбора объекта, над которым производится действие; Condition – условие активизации пакета. Агент начинает выполнение нового действия как только выполнится это условие; Schedule – множество интервалов игрового времени, в которые может активизироваться пакет; Flags – множество модификаторов действия, уточняющих, каким способом должна быть достигнута цель.
В отличие от Radiant AI допускается одновременное выполнение нескольких пакетов, но только при условии, что инициируемые действия выполняются при помощи различных эффекторов. Структура пакетов ИИ определят тип агента; в нашем случае – это рефлексивный агент с моделью внешней среды [5]. Структура пакета может быть расширена (например, добавление функции предсказания «благополучия» агента после выполнения действия позволит применить машинное обучение) [1].
Агент изменяет свое состояние и состояние окружающей среды (виртуального мира) только при помощи действий. Действия агента имеют следующую структуру:
Action = Actuators, TimeLimit, FStart, FStop, FUpdate, Condition, Children,
где Actuators – множество эффекторов, которые необходимы для выполнения действия; TimeLimit – лимит времени, отпущенный на выполнение действия; FStart, FUpdate, FStop – функции, моделирующие начало выполнения и остановку действия; Condition – условие завершения действия; Children – дочерние действия.
Действия, которые могут быть выполнены одновременно (например, стрельба и перемещение) будут выполнены одновременно; в противном случае будет выполнятся наиболее приоритетное действие.
Существует два принципа организации управления группой агентов: централизованное и децентрализованное . Централизованное управление небольшой группой агентов реализуется проще, чем децентрализованное, но при увеличении размеров группы сложность алгоритма управления возрастает экспоненциально [5]. При децентрализованном управлении агенты должны знать о том, что они выполняют действие сообща, и, исходя из этого, принимать решение. При децентрализованном управлении страдает качество принимаемых решений.
Был разработан алгоритм управления, позволяющий пользоваться преимуществами как централизованного, так и децентрализованного способа управления. Агенты объединяются во фракции для решения некоторых задач; внутри фракции может быть организована иерархия.
Фракции могут создаваться статически (на этапе описания виртуального мира) и динамически (в процессе моделирования). Примером статической фракции являются команды агентов. Динамические фракции создаются агентами, решающими одну и ту же тактическую задачу. Фракции имеют следующую структуру:
Fraction = ID, Target, Members,
где ID – идентификатор фракции; Target – задача, решаемая фракцией; Members – множество пар агент-ранг, описывающее агентов, вступивших во фракцию.
Агент, занимающий более высокий ранг, может давать указания «подчиненным» агентам. Взаимодействие агентов осуществляется с помощью механизма сообщений, имеющих следующую структуру:
Message = Type, Timestamp, Sender, Data,
где Type – тип сообщения; Timestamp – время отправки; Sender – идентификатор отправителя; Data – произвольные данные сообщения;
Сообщение может содержать описание некоторых фактов, помещаемых в базу фактов, или указание в виде одного или нескольких пакетов ИИ.
Агент может отправить сообщение либо другому агенту (индивидуальная рассылка), либо группе агентов (массовая рассылка). Сообщения служат для координации действий агентов.
Для проверки основных положений концепции был спроектирован и реализован прототип системы, моделирующий поведение агентов в двумерном мире.
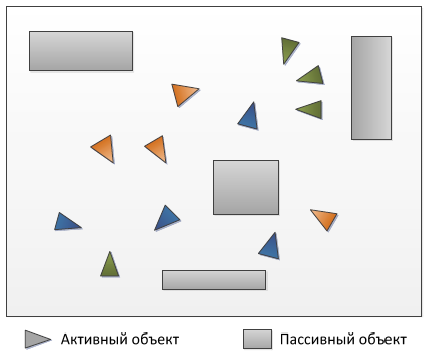
Рисунок 1 - Виртуальный мир. Цвет обозначает фракцию.
Физика виртуального мира представляет собой физику абсолютно твердых тел на плоскости. Есть множество одинаковых агентов. Агенты могут перемещаться по виртуальному миру, подбирать и использовать предметы – боеприпасы, оружие и аптечки. Агенты распределены по командам; задача команды: защитить союзников и уничтожить противника. Отношение между командами определяется целым числом в диапазоне [–100;100], где –100 соответствует противнику, а 100 – союзнику. На рисунке треугольниками обозначены агенты, цвет треугольника определяет принадлежность команде.
Разработаны следующие базовые тактики:
следование – один агент следует за другим;
избегание – один агент убегает от другого;
поиск – агент ищет другого агента или интерактивный объект с заданными характеристиками;
атака – один агент атакует другого;
сохранение здоровья – агент использует
предмет-аптечку при необходимости и пополняет ее запас;
сохранение боекомплекта – агент перезаряжает оружие и пополняет боекомплект.
Агенты имеют два эффектора: руки (Hands) и ноги (Legs), что позволяет им параллельно выполнять некоторые действия.
Основная проблема при организации иерархической системы действий – сложность условий завершения действий; необходимо все время проверять, имеет ли смысл дальнейшее выполнение действия; организовывать обратную связь между дочерним и родительским действием; координировать параллельные действий.
Результаты профилирования с помощью встроенного профилировщика MS Visual Studio показали, что условия завершения действий существенно влияли на производительность системы. Компромиссом между сложностью и адекватностью поведения можно считать применение иерархии действий в 3–4 уровня (элементарный, тактика, сценарий или стратегия); при этом агент параллельно выполняет 2–3 действия (управление боезапасом, сохранение здоровья, перемещение, атака).
Таким образом, концепция, предложенная в [4], была доработана и расширена. В концепцию добавлены эффекторы, и структурированная информация о действиях. Создан прототип системы, реализующий основные положения концепции. В ходе работы решены следующие проблемы:
– уменьшена потенциальная алгоритмическая сложность условий действий;
– разработан механизм синхронизации и решения конфликтов при параллельном выполнении задач;
– разработан механизм выполнения коллективных действий;
– разработан механизм взаимодействия агентов, позволяющий кооперироваться и передавать знания и решать конфликты при использовании общих ресурсов.
1. Крыжановский, А. И. Применение кооперативного
обучения и прогнозирования в мультиагентных системах /
А. И. Крыжановский, П. С. Пыхтин // Известия Волгоградского государственного технического университета :
межвуз. сб. науч. ст. № 6(66) / ВолгГТУ. – Волгоград :
ИУНЛ ВолгГТУ, 2010. – (Сер. Актуальные проблемы
управления, вычислительной техники и информатики в
технических системах. Вып. 8). – C. 106–109.
2. Шампандар, Д. А. Искуственный интеллект в компьютерных играх / Д. А. Шампандар. – М. : Вильямс, 2007. –
768 с.
3. Epic games. Unreal Development Kit [Электронный
ресурс]. – http ://www.udk.com
4. Шабалина, О. А. Исскуственный интеллект в компьютерных играх. Многоуровневое планирование и реактивное поведение агентов / О. А. Шабалина, А. А. Алимов //
Известия Волгоградского государственного технического
университета : межвуз. сб. науч. ст. № 3 (76) / ВолгГТУ. –
Волгоград : ИУНЛ ВолгГТУ, 2011. – (Сер. Актуальные
проблемы управления, вычислительной техники и информатики в технических системах. Вып. 10). – C. 90–93.
5. Рассел, С. Искусственный интеллект. Современный
подход / С. Рассел, П. Норвиг. – 2-е изд. – М. : Вильямс,
2007. – 1408 с.
6. Каляев, И. А. Модели и алгоритмы коллективного
управления в группах роботов / И. А. Каляев, А. Р. Гайдук, С. Г. Капустян. – М. : ФИЗМАТЛИТ, 2009. – 280 с.