
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі дослідження, заплановані результати
- 3. Огляд досліджень і розробок
- 3.1 Огляд міжнародних джерел
- 3.2 Огляд національних джерел
- 3.3 Огляд локальних джерел
- 4. Етапи та методи обробки зображень і розпізнавання номерних знаків транспортних засобів
- 4.1 Методи обробки зображень при локалізації номерного знака
- 4.2 Сегментація номерного знака
- 4.3 Методи розпізнавання образів
- 4.4 Розпізнавання символів
- Висновки
- Перелік посилань
Вступ
В даний час комп'ютеризація розвивається швидкими темпами та відіграє значну роль у суспільстві. Комп'ютерні технології допомагають автоматизувати широке коло процесів, які в недалекому минулому покладалися на людину. Інформаційні технології використовуються у промисловості, у транспорті, в побуті та ін.
Сьогодні важливим аспектом безпеки дорожнього руху та контролю є ідентифікація автомобілів за їх реєстраційним номерним знаком. Системи розпізнавання номерних знаків мають різні сфери застосування, такі як автотранспортні підприємства, контроль в'їзду на територію підприємства та переміщення транспортних засобів на об'єктах з обмеженим доступом, заправні станції, контроль швидкості руху, автомобільні стоянки [1].
1. Актуальність теми
Актуальність задачі розпізнавання номерних знаків транспортних засобів полягає в тому, що з кожним днем збільшується потреба автоматизації контролю в'їзду на територію підприємств, контролю швидкості руху та визначення порушення правил дорожнього руху.
В даний час існує досить велика кількість систем визначення номерних знаків, але не всі з них є якісною і надійної продукцією. Системи з високою швидкодією і точністю розпізнавання є комерційними, засекреченими і дорогими, що не дозволяє здійснити їх масове впровадження [1].
Важливим є визначення найбільш ефективних методів обробки зображень та розпізнавання автомобільних номерних знаків, а такожстворення нових комбінованих або модифікованих методів для якісного розпізнавання системи в реальному часі.
2. Мета і задачі дослідження, заплановані результати
Метою роботи є дослідження й аналіз методів обробки зображень та розпізнавання номерних знаків транспортних засобів, розробканових комбінованих або модифікованих методів.
Досягнення поставленої мети вимагає вирішення наступних завдань:
- Аналіз методів і здійснення обробки зображень при локалізації номерного знака.
- Аналіз методів сегментації.
- Дослідження методів розпізнавання образів.
- Розробка і дослідження алгоритмів розпізнавання символів.
- Вибір методів розпізнавання і оцінка їх ефективності.
- Розробка системи для обробки зображення з камер відеоспостереження для розпізнавання номерного знака транспортного засобу..
Задача розпізнавання номерних знаків розбивається на три етапи: попередня обробка зображення, сегментація, розпізнавання символів.
Попередня обробка зображення необхідна для поліпшення візуальної якості зображення і, в кінцевому підсумку, для локалізації номерний пластини.
Сегментація проводиться з метою виділення символів для подальшого розпізнавання обраним методом.
У рамках магістерської роботи планується дослідити методи розпізнавання номерних знаків транспортних засобів з метою знаходження ефективного алгоритму, а також реалізувати інформаційну систему, яка вирішуватиме перераховані вище завдання.
3. Огляд досліджень і розробок
У зв'язку зі складністю й актуальністю задачі визначення автомобільних номерів в її загальній постановці, рішенням як всієї задачі в цілому, так і окремих її аспектів присвячено велику кількість робіт.
3.1 Огляд міжнародних джерел
У світі вже існують розробки, які стосуються розпізнавання автомобільних номерних знаків. Розглянемо деякі з них.
Система «Авто-Інспектор» – програмно-апаратний комплекс, що забезпечує розпізнавання номерів рухомих автомобілів, надійно працює в широкому діапазоні зовнішніх умов, легко інтегрований з охоронним обладнанням, виконавчими пристроями і зовнішніми базами даних.
Ефективний для вирішення задач реєстрації, ідентифікації та забезпечення безпеки автомобілів, контролю транспортних потоків.
У системі «Авто-Інспектор» реалізовані функціональні можливості необхідні для ефективного вирішення завдань на різних об'єктах: від забезпечення збереження автомобілів в межах автостоянки до контролю за пересуванням транспорту в масштабах підприємства, окремої магістралі, цілого міста.
Основні функціональні можливості:
- розпізнавання реєстраційного номера автомобіля;
- виявлення появи автомобіля в кадрі;
- можливість адаптації до стандартів номерів будь-якої країни світу;
- успішна робота модуля в будь-яких погодних умовах;
- вибір кадру з оптимальним розміром і чіткістю реєстраційного номера;
- одночасне розпізнавання в зоні контролю декількох номерів (переклад відеозображення в текстовий формат);
- ефективна взаємодія з різними охоронними системами (охоронного телебачення, контролю доступу);
- запис кожного проїзду, в'їзду/виїзду транспортних засобів;
- зіставлення розпізнаного номера з інформацією бази даних (власної або зовнішньої) [2].
АПК «Автоураган» – апаратно-програмний комплекс автоматичного розпізнавання зображень державних реєстраційних знаків транспортних засобів.
За відеозображенням, що надходить на комп'ютер, відбувається розпізнавання реєстраційних знаків автомобілів, перевірка їхза підключеними базами даних з видачею повідомлення оператору та збереженням інформації про проїзд або з виконанням іншої призначеної дії.
Гнучкі налаштування ПО дозволяють використовувати АПК «Автоураган» для вирішення численних завдань пов'язаних з розпізнаванням автомобільних номерів.
Переваги модульної побудови системи:
- модулі можуть працювати як на різних комп'ютерах, утворюючи розподілену мережеву клієнт-серверну систему, так і одночасно на одномукомп'ютері, формуючи її локальний варіант;
- за необхідністю завжди можна додати нові функції або кількість оброблюваних каналів розпізнавання [3].
У цій області ведуться також і дослідження, розглянемо деякі з них. Fahmy [4] запропонував метод двобічноїасоціативної пам'яті нейронної мережі для читання номерних знаків. Цей метод підходить для невеликої кількості моделей. Nijhuis, Ter Brugge et al [5] пропонували використання нечіткої логіки і нейронних мереж для номерних знаків транспортних засобів. цей методвикористовував нечітку логіку для сегментації і дискретно-часові клітинні нейронні мережі для виділення ознак. Lotufo, Morgan и Johnson [6] представили автоматичну систему розпізнавання номерного знака за допомогою оптичних методів розпізнаваннясимволів. S.K. Kim, D.W. Kim и H.J. Kim [7] використовували генетичний алгоритм сегментації для локалізації області з номернимзнаком. Hontani [8] запропонував спосіб вилучення символів без знання їх положення і розмірів зображення.
3.2 Огляд національних джерел
На національному рівні розробляються системи розпізнавання автомобільних номерів компанією «ЕФ ЕФ», яка є провідним виробником на українському ринку, випусковий системи безпеки і відеоспостереження. Вони виробляють обладнання та програмно-апаратні комплекси, що покривають широкий спектр завдань в областях, де центральне місце займають безпека і керуваннятехнологічними і бізнес-процесами.
Система «НомерОК» проводить захоплення відеопотоку, розпізнавання автомобільних номерів в потоці, збереження події з записом номера, часу і кадру з номером. У програмі передбачена можливість внесення розпізнаних номерів у «білий» і «чорний» списки і додавання коментарів до номера. Всередині програми присутня як можливість налаштування «за замовчуванням», так і можливість налаштування до трьох зон розпізнавання і тонкого налаштування алгоритму [9].
3.3 Огляд локальних джерел
Животченко Олег Володимирович, «Розробка комп'ютерної системи обробки зображень з камер відеоспостереження для визначення номерного знака транспортного засобу» [10]. У магістерській роботі розглядаються основні етапи та методи розпізнавання автомобільних номерів. На відміну від моєї роботи, не проведене дослідження та аналіз методів розпізнавання номерних знаків, що не запропонованоновий модифікований або комбінований метод.
Федоров Антон Васильович, «Дослідження методів контурної сегментації для побудови системи оптичного розпізнавання символів» [11]. У роботі задача розпізнавання здійснюється тільки за допомогою нейронних мереж.
4. Етапи та методи обробки зображень і розпізнавання номерних знаків транспортних засобів
4.1 Методи обробки зображень при локалізації номерного знака
Вхідними даними є зображення з камери, які найчастіше зашумлені, розмиті, тому проводиться попередня обробка їх згладжуючими та ранговими фільтрами (гауссовский і медіанний фільтри) для усунення адитивного та імпульсного шуму. При фільтрації яскравість (сигнал) кожної точки вихідного зображення, викривленого перешкодою, замінюється деяким іншим значенням яскравості, яке вважається має найменший ступінь викривлення [12].
Згладжувальні та рангові фільтри
У обробці зображень використовується двовимірна дискретна функція Гаусса з нульовим середнім:
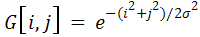
Фільтр, побудований на її основі, служить для згладжування. При цьому виконуються маніпуляції з параметром σ² (встановлене значення дисперсії зазвичай набагато більше обчисленого, що призводить до більш ефективного шумозаглушенню, але й збільшує ступінь розмивання зображення).
При медіанній фільтрації використовується двовимірне вікно (маска фільтра), що має центральну симетрію. Центр вікна розташовується в поточній точці фільтрації. Форма вікна може бути різною. Розміри апертури оптимізуються в процесі аналізу обробки, залежать від детальності зображення. Відліки, що опинилися в межах вікна, називаються робочої вибіркою поточного кроку.
Значення елементів робочої вибірки упорядковуються за зростанням. Вибирається елемент, який займає центральне положення в цій послідовності – медіана. Якщо центральне значення є шумовим викидом, то фільтр забезпечить його придушення.
Виявлення меж (контурів)
Для виконання подальших етапів необхідно виконати виділення на зображенні меж об'єктів – безперервних кривих, в яких спостерігається різкий стрибок яскравості.
Виділення меж здійснюється за допомогою градієнтних фільтрів першого і другого порядку. Застосуємо, наприклад, фільтр другого порядку – LoG-фильтр (Marr-Hildreth), який працює шляхом звіряння зображення з лапласіаном функції Гаусса. Він поєднує в собі виявлення меж зі згладжуванням. Використовується маска фільтра G:
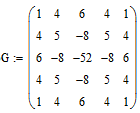
Результат роботи фильтру LoG представлений на рис. 1.

а) б)
Рисунок 1 – а) вихідне зображення, б) з виділеними межами
4.2 Сегментація номерного знака
Згідно з алгоритмом сегментації проводиться пошук координат передбачуваних символів на локалізованої зоні. На першому етапі сегментації обчислюються оцінки правдоподібності приналежності пікселів лініям символів, у найпростішому випадку використовуються або готові результати накладення фільтра H, або безпосередньо яскравість пікселів. Результатом першого етапу є масив оцінок правдоподібності EZhxw.
Другий етап – обчислення вектора середньої оцінки правдоподібності за стовпцями:
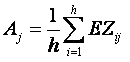
Вектор A дозволяє виявити проміжки фону між символами, які проявляються у вигляді екстремумів, якщо розглядати A як функцію.
На третьому етапі проводиться виявлення вертикальних роздільників – меж між символами. Для цього кожному елементу зіставляється оцінка правдоподібності Hi. Чим вище ця оцінка, тим вища ймовірність того, що в даному місці знаходиться проміжок фону між символами. Індекси i обраних Hi – це координати вертикальних роздільників (межі) між символами:
Dev = {dev1,dev2,…,devk}, где k – кількість знайдених роздільників.
На четвертому етапі здійснюється уточнення вертикальних і горизонтальних меж символів. Для цього методом Отсу обчислюється порогове значення яскравості для фрагмента зображення між двома роздільниками. Поріг дозволяє бінаризованими фрагмент і в результаті знайти координати виділеного на фрагменті об'єкта [13].
Для спрощення задачі розпізнавання символів номерного знака застосовується морфологічна ерозія. Мета такої обробки – отримання скелета символу (зображення шириною в 1 піксель).
Ерозія бінарного зображення А структуруючим елементом В позначається A θ B та задається виразом:
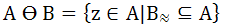
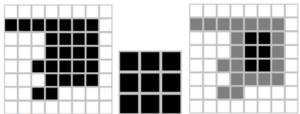
При виконанні операції ерозії структурний елемент проходить по всім пікселям зображення. Якщо в деякій позиції кожен одиничний піксель структурного елементу співпаде з одиничним пікселем бінарного зображення, то виконується логічне додавання центрального пікселя елемента з відповідним пікселем вихідного зображення (см. рис. 2).
а) б)в)
Рисунок 2 – а) бінарне зображення A, б) структурний елемент B, в) витончення зображення A структурним елементом B²
В результаті застосування операції ерозії всі об'єкти, менші, ніж структурний елемент, стираються, а об'єкти, з'єднані тонкими лініями стають роз'єднаними, та розміри всіх об'єктів зменшуються [14]. Якщо структурний елемент являє собою єдиний піксель, то в результаті виходиткістяккий остов об'єкта.
Після попередньої обробки та сегментації можна приступати до вирішення задачі розпізнавання.
4.3 Методи розпізнавання образів
Для реальних задач розпізнавання застосовуються, в основному, три підходи, які використовують методи: кореляційні, засновані на прийнятті рішень за критерієм близькості з еталонами; ознакові та синтаксичні – найменш трудомісткі.
При повністю заданому стандарті багатокрокова кореляція шляхом сканування вхідного поля зору є, по суті, повним перебором впросторі сигналів. Тому цю процедуру можна вважати базовою, потенційно найбільш перешкодостійкою, хоча і самої трудомісткою.
Найбільш перешкодостійкі при дії, як випадкових перешкод, так і локальних перешкод, є алгоритми, засновані на методі частних кореляцій. При цьому частні коефіцієнти кореляцій, отримані для окремих фрагментів еталона в сигнальному просторі, можуть розглядатися як ознаки. Обробка таких ознак, тобто їх згортка, залежить від типу зображень, присутності значних локальних перешкод і може бути здійснена методами перевірки статистичних гіпотез.
Розпізнавання зображень шляхом двовимірної кореляції полягає в знаходженні найбільш схожою пари зображень: еталон B0i – вхідне зображення B, i = 1,..,n0. Під максимальним схожістю розуміється визначення мінімального значення деякої міри схожості ρ(B,B0i). Розпізнавання в умовах геометричних спотворень здійснюється на підставі наступного правила:
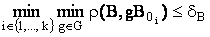
де G – група передбачуваних викривлень (наприклад, група зміщень); dВ – порогова величина, введення якої пояснюється наявністю на вхідному зображенні перешкод.
Міри схожості між зображеннями можуть визначатися по одній з наступних формул:
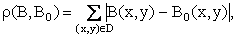
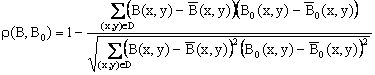
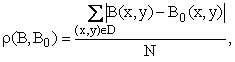
де B(x,y) и B0(x,y) – середні значення яскравостей зображень B и B0 відповідно; N – кількість точок області D.
В якості еталонних зображень пропонується розглядати сегментовані напівтонові зображення, відцентрувати по центру тяжкості.
Еталонні зображення повинні відповідати умові несхожості:
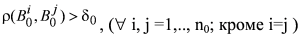
где n0 – кількість еталонних зображень; d0 – порогова величина.
Величина сигнал/шум визначається наступним чином:
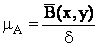
де B(x,y) – середня яскравість зображення; d – середньоквадратичне відхилення гауссова шуму (випадкова перешкода, розподілена за нормальним законом з нульовим математичним очікуванням і задається величиною дисперсії).
Ймовірність правильного розпізнавання при заданому рівні шуму визначається шляхом багаторазового повторення експериментів з даним рівнем шуму для різних зображень шляхом ділення кількості правильних результатів на кількість всіх експериментів.
Ознакові та синтаксичні методи найбільш розроблені в теорії розпізнавання образів. Вони засновані як на статистичних, так і детермінованих підходах. Головну складність в ознакових методах складає вибір ознак. При цьому виходять з природних правил: а) ознаки зображень одного класу можуть відрізнятися лише незначною мірою (за рахунок впливу перешкод), б) ознаки зображень різних класів повинні суттєво відрізнятися, в) набір ознак повинен бути мінімально можливим, тому від їх кількості залежить і надійність, і складність обробки.
У першому наближенні синтаксичні методи можна віднести до ознакових, вони засновані на отриманні структурно-лінгвістичних ознак, коли зображення дробиться на частини – непохідні елементи (ознаки). Вводяться правила з'єднання цих елементів, однакові для еталона і вхідного зображення. Аналіз отриманої таким чином граматики забезпечує прийняття рішень [15]. Усі розглянуті методи можуть бути застосовані для вирішення задачі локалізації номерний пластини, але найбільш ефективними є кореляційні методи.

Рисунок 3 – Візуальне представлення обробки зображення та розпізнавання номерного знака транспортного засобуа
(анімація: 10 кадрів, 5 циклів повторення, 132 кілобайт)
4.4 Розпізнавання символів
Задача безпосереднього розпізнавання номера вирішується за допомогою специфічних методів, до яких, зокрема, належать методи класифікаторів і нейронних мереж.
Існує три основних типи класифікаторів:
- шаблонний;
- ознаковий;
- структурний.
Шаблонні класифікатори перетворюють вихідне зображення символу в набір точок і потім накладають його на шаблони, наявні в базі системи. Шаблон, що має найменше відмінностей, і буде шуканим. У цих систем досить висока точність розпізнавання дефектних символів (склеєних або розірваних). Недолік – неможливість розпізнати шрифт, який хоч трохи відрізняється від закладеного в систему (розміром, нахилом або написанням).
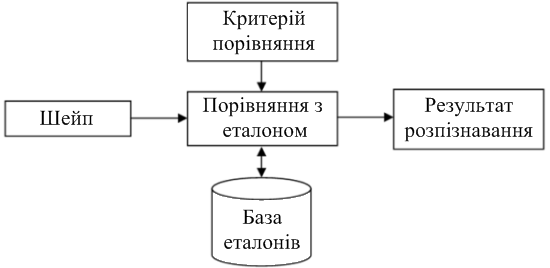
Рисунок 4 – Узагальнений алгоритм роботи шаблонного класифікатора
Ознакові класифікатори для кожного символу обчислюють набір чисел (ознак) і порівнюють ці набори. Недолік – на етапі вилучення ознак відбувається необоротна втрата частини інформації про символ.
Структурні класифікатори зберігають інформацію про топологію символу. Структурні методи являють об'єкт як граф, вузлами якогоє елементи вхідного об'єкта, а дугами – просторові відносини між ними. Цей спосіб теж має свої недоліки: труднощі прирозпізнаванні дефектних символів [16].
При вирішенні задачі розпізнавання символів активно використовуються типи нейронних мереж: багатошарові нейронні мережі, нейронні мережі Хопфілда, нейронні мережі Кохонена та ін.
Архітектура багатошарової нейронної мережі (БНМ) складається з послідовно з'єднаних шарів, де нейрон кожного шару своїми входами пов'язанийз усіма нейронами попереднього шару, а виходами – наступного.
Нейронна мережа Хопфілда є одношаровою і повнозв'язною (зв'язки нейронів на самих себе відсутні), її виходи пов'язані з входами. На відміну від БНМ є релаксационной, тобто будучи встановленою в початковий стан, функціонує до тих пір, поки не досягне стабільного стану, який і буде її вихідним значенням.
Нейронні мережі Кохонена забезпечують топологічне упорядкування вхідного простору образів. Вони дозволяють топологічно безперервно відображати вхідний n-мірний простір у вихідний m-мірний [17].
Ключовим аспектом нейронної мережі є її навчання, яке зводиться до визначення зв'язків (синапсів) між нейронами і встановленню сили цих зв'язків (вагових коефіцієнтів). Алгоритми навчання нейронної мережі спрощено зводяться до визначення залежності вагового коефіцієнта зв'язку двох нейронів від числа прикладів, що підтверджують цю залежність. Найбільш поширеним алгоритмом навчання нейронної мережі є алгоритм зворотного поширення помилки. Цільова функція за цим алгоритмом повинна забезпечити мінімізацію квадрата помилки в навчанні за всіма прикладам:
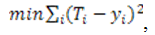
де Ti – задане значення вихідної ознаки за i-м прикладом; yi – обчислене значення вихідного ознаки за i-м прикладом [18].
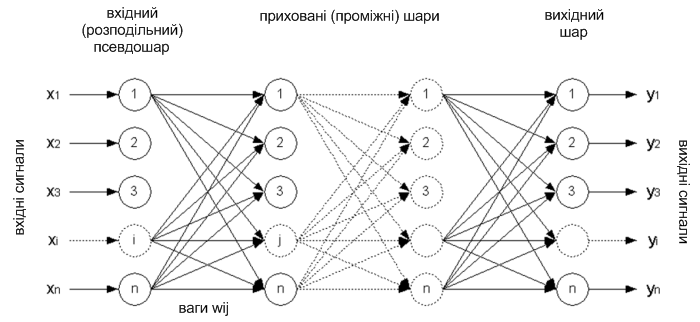
Рисунок 5 – Багатошарова нейронна мережа з зворотним поширенням помилки [19]
Сутність алгоритму зворотного поширення помилки зводиться до наступного:
- Задати довільно невеликі початкові значення ваг зв'язків нейронів.
- Для всіх навчальних пар «значення вхідних ознак – значення вихідної ознаки» (прикладів з навчальної вибірки) обчислити вихід мережі (Y).
- Виконати рекурсивний алгоритм, починаючи з вихідних вузлів у напрямку до першого прихованого шару, поки не буде досягнутий мінімальний рівень помилки [18].
Висновки
Мета даної дослідницької роботи – вивчення та аналіз методів обробки зображень та розпізнавання номерних знаків транспортних засобів.
Дослідження та визначення методів обробки зображення та сегментації символів, які ідеально підходять до конкретної задачі, дозволить знизити вимоги до умов розпізнавання, що дуже важливо в задачі розпізнавання номерних знаків транспортних засобів.
У рамках проведених досліджень виконано:
- На підставі аналізу літературних джерел виділено основні етапи реалізації та алгоритми, які можуть бути використані при проектуванні заданої системи. Необхідними для вирішення цього завдання є шумоподавляюча фільтрація, виявлення меж, скелетизація та сегментація, а найбільш придатними методами розпізнавання – кореляційні, шаблонні методи і нейронні мережі.
- Оцінені вимоги до програмного забезпечення, виконаний пошук функціонально подібних програмних продуктів та проведено аналіз переваг і недоліків.
- Реалізована попередня обробка зображень з метою поліпшення їх якості та зручною локалізації номерної пластини.
Подальші дослідження спрямовані на наступні аспекти:
- Глибокий аналіз основних методів обробки зображень та розпізнавання номерних знаків транспортних засобів.
- Розробка нових комбінованих або модифікованих методів для розпізнавання номерних знаків.
- На підставі проведеного дослідження буде розроблена функціональна система розпізнавання номерних знаків транспортних засобів, за допомогою якої можна буде перевірити вибрані методи розпізнавання на ефективність.
Перелік посилань
- И.С. Личканенко. Методы обработки изображений и распознавания образов для задачи обнаружения номерных знаков транспортных средств // Информатика и компьютерные технологии – 2013. – Донецк: Донецкий национальный технический университет, 2013
- Авто-Инспектор – система распознавания автомобильных номеров [Электронный ресурс]. – Режим доступа: http://www.iss.ru/products/intelligent/auto/
- АПК «АВТОУРАГАН» [Электронный ресурс]. – Режим доступа: http://www.recognize.ru/ node/23
- Fahmy M.M.M., 1994, Automatic Number-plate Recognition : Neural Network Approach, Proceedings of VNIS’94 Vehicle Navigation and Information System Conference, 3 1 Aug-2 Sept, pp.291-296, 1994
- Nijhuis J.A.G. , Brugge Ter M.H., Helmholt K.A., Pluim J.P.W., Spaanenburg L., Venema L., Westenberg M.A., 1995, Car License PlateRecognition with Neural Networks and Fuzzy Logic, IEEE International Conference on Neural Networks, pp.2232-2236, 1995
- Lotufo R.A., Morgan A.D., and Johnson AS., 1990, Automatic Number-Plate Recognition, Proceedings of the IEE Colloquium on Image analysis for Transport Applications, V01.035, pp.6/1-6/6, February 16, 1990.
- Kim S.K., Kim D.W., and Kim H.J., 1996, A Recognition of Vehicle License Plate Using a Genetic Algorithm Based Segmentation, Proceedings of 3rd IEEE International Conference on Image Processing, V01.2., pp.661-664, 1996
- Hontani H., and Koga T., (2001), Character extraction method without prior knowledge on size and information, Proceedings of the IEEE International Vehicle Electronics Conference (IVEC’01), pp. 67-72.
- Система распознавания автомобильных номеров «НомерОк» [Электронный ресурс]. – Режим доступа: http://avtonomerok.com/
- Животченко О.В. Реферат по теме выпускной работы: Разработка компьютерной системы обработки изображений с камер видеонаблюдения для определения номерного знака транспортного средства. – Портал магистров ДонНТУ [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2012/fknt/zhivotchenko/diss/index.htm
- Федоров А.В. Реферат по теме выпускной работы: Исследование методов контурной сегментации для построения системы оптического распознавания символов. – Портал магистров ДонНТУ [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/ 2010/fknt/fedorov/diss/index.htm
- Грузман И.С., Киричук В.С. Цифровая обработка изображений в информационных системах: Учебное пособие. – Новосибисрк: Изд-во НГТУ, 2002. – 352 c.
- Воскресенский Е.М., Царев В.А. Моделирование и адаптация систем распознавания текстовых меток на видеоизображениях. – Череповец: ИНЖЭКОН-Череповец. – 2009. – 154 с.
- Математическая морфология [Электронный ресурс]. – Режим доступа: http://habrahabr.ru/post/113626/
- Путятин Е.П. Нормализация и распознавание изображений [Электронный ресурс]. – Режим доступа: http://sumschool. sumdu.edu.ua/is-02/rus/lectures/pytyatin/pytyatin.htm
- Абраменко А. Компьютер читает [Электронный ресурс]. – Режим доступа: http://www.ocrai.narod.ru/fr.html
- Брилюк Д.В., Старовойтов В.В. Нейросетевые методы распознавания изображений [Электронный ресурс]. – Режим доступа: http://rusnauka.narod.ru/lib/author/briluk_d_b/1/
- Тельнов Ю.Ф. Интеллектуальные информационные системы / Московский государственный университет экономики, статистики и информатики. – М.: МЭСИ, 2004.
- Шитиков В.К., Розенберг Г.С., Зинченко Т.Д. Количественная гидроэкология: методы системной идентификации. – Тольятти: ИЭВБ РАН, 2003. – 463 с.