
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, планируемые результаты
- 3. Обзор исследований и разработок
- 3.1 Обзор международных источников
- 3.2 Обзор национальных источников
- 3.3 Обзор локальных источников
- 4. Этапы и методы обработки изображений и распознавания номерных знаков транспортных средств
- 4.1 Методы обработки изображений при локализации номерного знака
- 4.2 Сегментация номерного знака
- 4.3 Методы распознавания образов
- 4.4 Распознавание символов
- Выводы
- Список источников
Введение
В настоящее время компьютеризация развивается быстрыми темпами и играет значительную роль в обществе. Компьютерные технологии помогают автоматизировать широкий круг процессов, которые в недалеком прошлом возлагались на человека. Информационные технологии используются в промышленности, в транспорте, в быту и др.
Сегодня важным аспектом безопасности дорожного движения и контроля является идентификация автомобилей по их регистрационному номерному знаку. Системы распознавания номерных знаков имеют различные сферы применения, такие как автотранспортные предприятия, контроль въезда на территорию предприятия и перемещения транспортных средств на объектах с ограниченным доступом, заправочные станции, контроль скорости движения, автомобильные стоянки [1].
1. Актуальность темы
Актуальность задачи распознавания номерных знаков транспортных средств состоит в том, что с каждым днем увеличивается потребность автоматизации контроля въезда на территорию предприятий, контроля скорости движения и определения нарушения правил дорожного движения.
В настоящее время существует достаточно большое количество систем определения номерных знаков, но не все из них являются качественной и надежной продукцией. Системы с высоким быстродействием и точностью распознавания являются коммерческими, засекреченными и дорогими, что не позволяет осуществить их массовое внедрение [1].
Важным является определение наиболее эффективных методов обработки изображений и распознавания автомобильных номерных знаков, а также создание новых комбинированных или модифицированных методов для качественного распознавания системы в реальном времени.
2. Цель и задачи исследования, планируемые результаты
Целью работы является исследование и анализ методов обработки изображений и распознавания номерных знаков транспортных средств, разработка новых комбинированных или модифицированных методов.
Достижение поставленной цели требует решения следующих задач:
- Анализ методов и осуществление обработки изображений при локализации номерного знака.
- Анализ методов сегментации.
- Исследование методов распознавания образов.
- Разработка и исследование алгоритмов распознавания символов.
- Выбор методов распознавания и оценка их эффективности.
- Разработка системы для обработки изображения с камер видеонаблюдения для распознавания номерного знака транспортного средства.
Задача распознавания номерных знаков разбивается на три этапа: предварительная обработка изображения, сегментация, распознавание символов.
Предварительная обработка изображения необходима для улучшения визуального качества изображения и, в конечном итоге, для локализации номерной пластины.
Сегментация проводится с целью выделения символов для дальнейшего распознавания выбранным методом.
В рамках магистерской работы планируется исследовать методы распознавания номерных знаков транспортных средств с целью нахождения эффективного алгоритма, а также реализовать информационную систему, решающую перечисленные выше задачи.
3. Обзор исследований и разработок
В связи со сложностью и актуальностью задачи определения автомобильных номеров в ее общей постановке, решению как всей задачи в целом, так и отдельных ее аспектов посвящено большое количество работ.
3.1 Обзор международных источников
В мире уже существуют разработки, которые касаются распознавания автомобильных номерных знаков. Рассмотрим некоторые из них.
Система «Авто-Инспектор» – программно-аппаратный комплекс, обеспечивающий распознавание номеров движущихся автомобилей, надежно работающий в широком диапазоне внешних условий, легко интегрируемый с охранным оборудованием, исполнительными устройствами и внешними базами данных.
Эффективен для решения задач регистрации, идентификации и обеспечения безопасности автомобилей, контроля транспортных потоков.
В системе «Авто-Инспектор» реализованы функциональные возможности необходимые для эффективного решения задач на различных объектах: от обеспечения сохранности автомобилей в пределах автостоянки до контроля за передвижением транспорта в масштабах предприятия, отдельной магистрали, целого города.
Основные функциональные возможности:
- распознавание регистрационного номера автомобиля;
- обнаружение появления автомобиля в кадре;
- возможность адаптации к стандартам номеров любой страны мира;
- успешная работа модуля в любых погодных условиях;
- выбор кадра с оптимальным размером и четкостью регистрационного номера;
- одновременное распознавание в зоне контроля нескольких номеров (перевод видеоизбражения в текстовой формат);
- эффективное взаимодействие с различными охранными системами (охранного телевидения, контроля доступа);
- запись каждого проезда, въезда/выезда транспортных средств;
- сопоставление распознанного номера с информацией базы данных (собственной или внешней) [2].
АПК «Автоураган» – аппаратно-программный комплекс автоматического распознавания изображений государственных регистрационных знаков транспортных средств.
По видеоизображению, поступающему на компьютер, происходит распознавание регистрационных знаков автомобилей, проверка их по подключенным базам данных с выдачей сообщения оператору и сохранением информации о проезде или с выполнением другого назначенного действия.
Гибкие настройки ПО позволяют использовать АПК «Автоураган» для решения многочисленных задач связанных с распознаванием автомобильных номеров.
Преимущества модульного построения системы:
- модули могут работать как на различных компьютерах, образуя распределенную сетевую клиент-серверную систему, так и одновременно на одном компьютере, формируя ее локальный вариант;
- при необходимости всегда можно добавить новые функции или количество обрабатываемых каналов распознавания [3].
В этой области ведутся также и исследования, рассмотрим некоторые из них. Fahmy [4] предложил метод двунаправленной ассоциативной памяти нейронной сети для чтения номерных знаков. Этот метод подходит для небольшого количества моделей. Nijhuis, Ter Brugge et al [5] предлагали использование нечеткой логики и нейронных сетей для номерных знаков транспортных средств. Этот метод использовал нечеткую логику для сегментации и дискретно-временные клеточные нейронные сети для выделения признаков. Lotufo, Morgan и Johnson [6] представили автоматическую систему распознавания номерного знака при помощи оптических методов распознавания символов. S.K. Kim, D.W. Kim и H.J. Kim [7] использовали генетический алгоритм сегментации для локализации области с номерным знаком. Hontani [8] предложил способ извлечения символов без знания их положения и размеров изображения.
3.2 Обзор национальных источников
На национальном уровне разрабатываются системы распознавания автомобильных номеров компанией «ЭФ ЭФ», которая является ведущим производителем на украинском рынке, выпускающий системы безопасности и видеонаблюдения. Они производят оборудование и программно-аппаратные комплексы, покрывающие широкий спектр задач в областях, где центральное место занимают безопасность и управление технологическими и бизнес-процессами.
Система «НомерОК» производит захват видеопотока, распознавание автомобильных номеров в потоке, сохранение события с записью номера, времени и кадра с номером. В программе предусмотрена возможность внесения распознанных номеров в «белый» и «чёрный» списки и добавления комментария к номеру. Внутри программы присутствует как возможность настройки «по умолчанию», так и возможность настройки до трёх зон распознавания и тонкой подстройки алгоритма [9].
3.3 Обзор локальных источников
Животченко Олег Владимирович, «Разработка компьютерной системы обработки изображений с камер видеонаблюдения для определения номерного знака транспортного средства» [10]. В магистерской работе рассматриваются основные этапы и методы распознавания автомобильных номеров. В отличие от моей работы, не проведено исследование и анализ методов распознавания номерных знаков, не предложен новый модифицированный или комбинированный метод.
Фёдоров Антон Васильевич, «Исследование методов контурной сегментации для построения системы оптического распознавания символов» [11]. В работе задача распознавания осуществляется только с помощью нейронных сетей.
4. Этапы и методы обработки изображений и распознавания номерных знаков транспортных средств
4.1 Методы обработки изображений при локализации номерного знака
Входными данными являются изображения с камеры, которые чаще всего зашумленные, размытые, поэтому проводится предварительная обработка их сглаживающими и ранговыми фильтрами (гауссовский и медианный фильтры) для устранения аддитивного и импульсного шума. При фильтрации яркость (сигнал) каждой точки исходного изображения, искаженного помехой, заменяется некоторым другим значением яркости, которое считается имеющим наименьшую степень искажения [12].
Сглаживающие и ранговые фильтры
В обработке изображений используется двумерная дискретная функция Гаусса с нулевым средним:
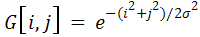
Фильтр, построенный на ее основе, служит для сглаживания. При этом выполняются манипуляции с параметром σ² (установленное значение дисперсии обычно намного больше вычисленного, что приводит к более эффективному шумоподавлению, но и увеличивает степень размывания изображения).
При медианной фильтрации используется двумерное окно (маска фильтра), имеющее центральную симметрию. Центр окна располагается в текущей точке фильтрации. Форма окна может быть различна. Размеры апертуры оптимизируются в процессе анализа обработки, зависят от детальности изображения. Отсчеты, оказавшиеся в пределах окна, называются рабочей выборкой текущего шага.
Значения элементов рабочей выборки упорядочиваются по возрастанию. Выбирается элемент, занимающий центральное положение в этой последовательности – медиана. Если центральное значение является шумовым выбросом, то фильтр обеспечит его подавление.
Обнаружение границ (контуров)
Для выполнения последующих этапов необходимо выполнить выделение на изображении границ объектов – непрерывных кривых, в которых наблюдается резкий скачок яркости.
Выделение границ осуществляется при помощи градиентных фильтров первого и второго порядка. Применим, например, фильтр второго порядка – LoG-фильтр (Marr-Hildreth), который работает путем сверки изображения с лапласианом функции Гаусса. Он сочетает в себе обнаружение границ со сглаживанием. Используется маска фильтра G:
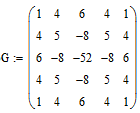
Результат работы фильтра LoG представлен на рис. 1.

а) б)
Рисунок 1 – а) исходное изображение, б) с выделенными границами
4.2 Сегментация номерного знака
Согласно алгоритму сегментации производится поиск координат предполагаемых символов на локализованной зоне. На первом этапе сегментации вычисляются оценки правдоподобия принадлежности пикселей линиям символов, в простейшем случае используются либо готовые результаты наложения фильтра H, либо непосредственно яркость пикселей. Результатом первого этапа является массив оценок правдоподобия EZhxw.
Второй этап – вычисление вектора средней оценки правдоподобия по столбцам:
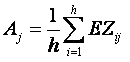
Вектор A позволяет обнаружить промежутки фона между символами, которые проявляются в виде экстремумов, если рассматривать A как функцию.
На третьем этапе производится обнаружение вертикальных разделителей – границ между символами. Для этого каждому элементу сопоставляется оценка правдоподобия Hi. Чем выше эта оценка, тем выше вероятность того, что в данном месте находится промежуток фона между символами. Индексы i выбранных Hi – это координаты вертикальных разделителей (границы) между символами:
Dev = {dev1,dev2,…,devk}, где k – количество найденных разделителей.
На четвертом этапе осуществляется уточнение вертикальных и горизонтальных границ символов. Для этого методом Отсу вычисляется пороговое значение яркости для фрагмента изображения между двумя разделителями. Порог позволяет бинаризовать фрагмент и в результате найти координаты выделенного на фрагменте объекта [13].
Для упрощения задачи распознавания символов номерного знака применяется морфологическая эрозия. Цель такой обработки – получение скелета символа (изображения шириной в 1 пиксель).
Эрозия бинарного изображения А структурирующим элементом В обозначается A θ B и задается выражением:
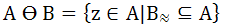
При выполнении операции эрозии структурный элемент проходит по всем пикселям изображения. Если в некоторой позиции каждый единичный пиксель структурного элемента совпадет с единичным пикселом бинарного изображения, то выполняется логическое сложение центрального пикселя элемента с соответствующим пикселем выходного изображения (см. рис. 2).
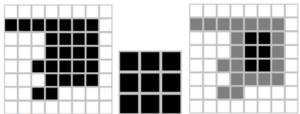
а) б)в)
Рисунок 2 – а) бинарное изображение A, б) структурный элемент B, в) утончение изображения A структурным элементом B²
В результате применения операции эрозии все объекты, меньшие, чем структурный элемент, стираются, а объекты, соединённые тонкими линиями становятся разъединенными, и размеры всех объектов уменьшаются [14]. Если структурный элемент представляет собой единственный пиксель, то в результате получается тонкий остов объекта.
После предварительной обработки и сегментации можно приступать к решению задачи распознавания.
4.3 Методы распознавания образов
Для реальных задач распознавания применяются, в основном, три подхода, использующие методы: корреляционные, основанные на принятии решений по критерию близости с эталонами; признаковые и синтаксические – наименее трудоемкие.
При полностью заданном эталоне многошаговая корреляция путем сканирования входного поля зрения является, по сути, полным перебором в пространстве сигналов. Поэтому эту процедуру можно считать базовой, потенциально наиболее помехоустойчивой, хотя и самой трудоемкой.
Наиболее помехоустойчивы при действии, как случайных помех, так и локальных помех, являются алгоритмы, основанные на методе частных корреляций. При этом частные коэффициенты корреляций, полученные для отдельных фрагментов эталона в сигнальном пространстве, могут рассматриваться как признаки. Обработка таких признаков, т.е. их свертка, зависит от типа изображений, присутствия значительных локальных помех и может быть осуществлена методами проверки статистических гипотез.
Распознавание изображений путем двумерной корреляции заключается в нахождении наиболее похожей пары изображений: эталон B0i – входное изображение B, i = 1,..,n0. Под максимальным сходством понимается определение минимального значения некоторой меры сходства ρ(B,B0i). Распознавание в условиях геометрических искажений осуществляется на основании следующего правила:
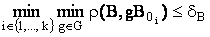
где G – группа предполагаемых искажений (например, группа смещений); dВ – пороговая величина, введение которой объясняется наличием на входном изображении помех.
Меры сходства между изображениями могут определяться по одной из следующих формул:
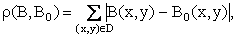
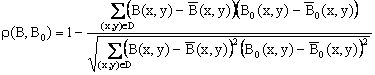
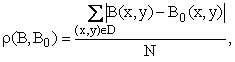
где B(x,y) и B0(x,y) – средние значения яркостей изображений B и B0 соответственно; N – количество точек области D.
В качестве эталонных изображений предлагается рассматривать сегментированные полутоновые изображения, отцентрированные по центру тяжести.
Эталонные изображения должны соответствовать условию непохожести:
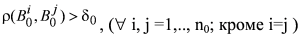
где n0 – количество эталонных изображений; d0 – пороговая величина.
Величина сигнал/шум определяется следующим образом:
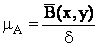
где B(x,y) – средняя яркость изображения; d – среднеквадратическое отклонение гауссова шума (случайная помеха, распределенная по нормальному закону с нулевым математическим ожиданием и задаваемой величиной дисперсии).
Вероятность правильного распознавания при заданном уровне шума определяется путем многократного повторения экспериментов с данным уровнем шума для разных изображений путем деления количества правильных результатов на количество всех экспериментов.
Признаковые и синтаксические методы наиболее разработаны в теории распознавания образов. Они основаны как на статистических, так и детерминированных подходах. Главную трудность в признаковых методах составляет выбор признаков. При этом исходят из естественных правил: а) признаки изображений одного класса могут различаться лишь незначительно (за счет влияния помех); б) признаки изображений разных классов должны существенно различаться; в) набор признаков должен быть минимально возможным, т.к. от их количества зависит и надежность, и сложность обработки.
В первом приближении синтаксические методы можно отнести к признаковым, они основаны на получении структурно-лингвистических признаков, когда изображение дробится на части – непроизводные элементы (признаки). Вводятся правила соединения этих элементов, одинаковые для эталона и входного изображения. Анализ полученной таким образом грамматики обеспечивает принятие решений [15]. Все рассмотренные методы могут быть применены для решения задачи локализации номерной пластины, но наиболее эффективными являются корреляционные методы.

Рисунок 3 – Визуальное представление обработки изображения и распознавания номерного знака транспортного средства
(анимация: 10 кадров, 5 циклов повторения, 132 килобайт)
4.4 Распознавание символов
Задача непосредственного распознавания номера решается при помощи специфических методов, к которым, в частности, относятся методы классификаторов и нейронных сетей.
Существует три основных типа классификаторов:
- шаблонный;
- признаковый;
- структурный.
Шаблонные классификаторы преобразуют исходное изображение символа в набор точек и затем накладывают его на шаблоны, имеющиеся в базе системы. Шаблон, имеющий меньше всего отличий, и будет искомым. У этих систем достаточно высокая точность распознавания дефектных символов (склеенных или разорванных). Недостаток – невозможность распознать шрифт, хоть немного отличающийся от заложенного в систему (размером, наклоном или начертанием).
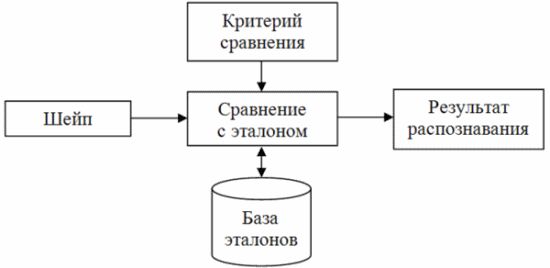
Рисунок 4 – Обобщенный алгоритм работы шаблонного классификатора
Признаковые классификаторы по каждому символу вычисляют набор чисел (признаков) и сравнивают эти наборы. Недостаток – на этапе извлечения признаков происходит необратимая потеря части информации о символе.
Структурные классификаторы хранят информацию о топологии символа. Структурные методы представляют объект как граф, узлами которого являются элементы входного объекта, а дугами – пространственные отношения между ними. Этот способ тоже имеет свои недостатки: трудности при распознавании дефектных символов [16].
При решении задачи распознавания символов активно используются типы нейронных сетей: многослойные нейронные сети, нейронные сети Хопфилда, cамоорганизующиеся нейронные сети Кохонена и др.
Архитектура многослойной нейронной сети (МНС) состоит из последовательно соединённых слоёв, где нейрон каждого слоя своими входами связан со всеми нейронами предыдущего слоя, а выходами – следующего.
Нейронная сеть Хопфилда является однослойной и полносвязной (связи нейронов на самих себя отсутствуют), её выходы связаны с входами. В отличие от МНС является релаксационной, т.е. будучи установленной в начальное состояние, функционирует до тех пор, пока не достигнет стабильного состояния, которое и будет являться её выходным значением.
Самоорганизующиеся нейронные сети Кохонена обеспечивают топологическое упорядочивание входного пространства образов. Они позволяют топологически непрерывно отображать входное n-мерное пространство в выходное m-мерное [17].
Ключевым аспектом нейронной сети является ее обучение, которое сводится к определению связей (синапсов) между нейронами и установлению силы этих связей (весовых коэффициентов). Алгоритмы обучения нейронной сети упрощенно сводятся к определению зависимости весового коэффициента связи двух нейронов от числа примеров, подтверждающих эту зависимость. Наиболее распространенным алгоритмом обучения нейронной сети является алгоритм обратного распространения ошибки. Целевая функция по этому алгоритму должна обеспечить минимизацию квадрата ошибки в обучении по всем примерам:
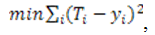
где Ti – заданное значение выходного признака по i-му примеру; yi – вычисленное значение выходного признака по i-му примеру [18].
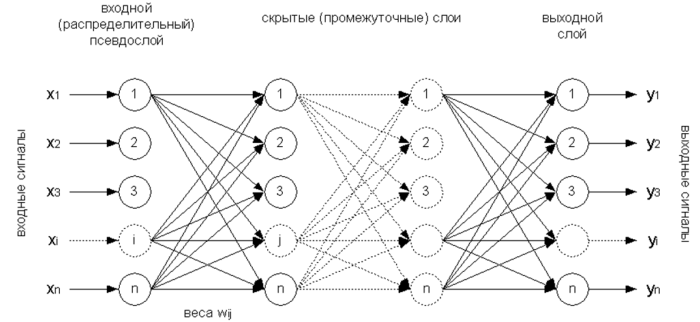
Рисунок 5 – Многослойная нейронная сеть с обратным распространением ошибки [19]
Сущность алгоритма обратного распространения ошибки сводится к следующему:
- Задать произвольно небольшие начальные значения весов связей нейронов.
- Для всех обучающих пар «значения входных признаков – значение выходного признака» (примеров из обучающей выборки) вычислить выход сети (Y).
- Выполнить рекурсивный алгоритм, начиная с выходных узлов по направлению к первому скрытому слою, пока не будет достигнут минимальный уровень ошибки [18].
Выводы
Цель данной исследовательской работы – изучение и анализ методов обработки изображений и распознавания номерных знаков транспортных средств.
Исследование и определение наиболее подходящих к конкретной задаче методов обработки изображения и сегментации символов позволит снизить требования к условиям распознавания, что очень важно в задаче распознавания номерных знаков транспортных средств.
В рамках проведенных исследований выполнено:
- На основании анализа литературных источников выделены основные этапы реализации и алгоритмы, которые могут быть использованы при проектировании заданной системы. Необходимыми для решения этой задачи являются шумоподавляющая фильтрация, обнаружение границ, скелетизация и сегментация, а наиболее подходящими методами распознавания – корреляционные, шаблонные методы и нейронные сети.
- Оценены требования к программному обеспечению, выполнен поиск функционально подобных программных продуктов и проведен анализ преимуществ и недостатков.
- Реализована предварительная обработка изображений с целью улучшения их качества и удобной локализации номерной пластины.
Дальнейшие исследования направлены на следующие аспекты:
- Глубокий анализ основных методов обработки изображений и распознавания номерных знаков транспортных средств.
- Разработка новых комбинированных или модифицированных методов для распознавания номерных знаков.
- На основании проведенного исследования будет разработана функциональная система распознавания номерных знаков транспортных средств, с помощью которой можно будет проверить выбранные методы распознавания на эффективность.
Список источников
- И.С. Личканенко. Методы обработки изображений и распознавания образов для задачи обнаружения номерных знаков транспортных средств // Информатика и компьютерные технологии – 2013. – Донецк: Донецкий национальный технический университет, 2013
- Авто-Инспектор – система распознавания автомобильных номеров [Электронный ресурс]. – Режим доступа: http://www.iss.ru/products/intelligent/auto/
- АПК «АВТОУРАГАН» [Электронный ресурс]. – Режим доступа: http://www.recognize.ru/ node/23
- Fahmy M.M.M., 1994, Automatic Number-plate Recognition : Neural Network Approach, Proceedings of VNIS’94 Vehicle Navigation and Information System Conference, 3 1 Aug-2 Sept, pp.291-296, 1994
- Nijhuis J.A.G. , Brugge Ter M.H., Helmholt K.A., Pluim J.P.W., Spaanenburg L., Venema L., Westenberg M.A., 1995, Car License PlateRecognition with Neural Networks and Fuzzy Logic, IEEE International Conference on Neural Networks, pp.2232-2236, 1995
- Lotufo R.A., Morgan A.D., and Johnson AS., 1990, Automatic Number-Plate Recognition, Proceedings of the IEE Colloquium on Image analysis for Transport Applications, V01.035, pp.6/1-6/6, February 16, 1990.
- Kim S.K., Kim D.W., and Kim H.J., 1996, A Recognition of Vehicle License Plate Using a Genetic Algorithm Based Segmentation, Proceedings of 3rd IEEE International Conference on Image Processing, V01.2., pp.661-664, 1996
- Hontani H., and Koga T., (2001), Character extraction method without prior knowledge on size and information, Proceedings of the IEEE International Vehicle Electronics Conference (IVEC’01), pp. 67-72.
- Система распознавания автомобильных номеров «НомерОк» [Электронный ресурс]. – Режим доступа: http://avtonomerok.com/
- Животченко О.В. Реферат по теме выпускной работы: Разработка компьютерной системы обработки изображений с камер видеонаблюдения для определения номерного знака транспортного средства. – Портал магистров ДонНТУ [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2012/fknt/zhivotchenko/diss/index.htm
- Федоров А.В. Реферат по теме выпускной работы: Исследование методов контурной сегментации для построения системы оптического распознавания символов. – Портал магистров ДонНТУ [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/ 2010/fknt/fedorov/diss/index.htm
- Грузман И.С., Киричук В.С. Цифровая обработка изображений в информационных системах: Учебное пособие. – Новосибисрк: Изд-во НГТУ, 2002. – 352 c.
- Воскресенский Е.М., Царев В.А. Моделирование и адаптация систем распознавания текстовых меток на видеоизображениях. – Череповец: ИНЖЭКОН-Череповец. – 2009. – 154 с.
- Математическая морфология [Электронный ресурс]. – Режим доступа: http://habrahabr.ru/post/113626/
- Путятин Е.П. Нормализация и распознавание изображений [Электронный ресурс]. – Режим доступа: http://sumschool. sumdu.edu.ua/is-02/rus/lectures/pytyatin/pytyatin.htm
- Абраменко А. Компьютер читает [Электронный ресурс]. – Режим доступа: http://www.ocrai.narod.ru/fr.html
- Брилюк Д.В., Старовойтов В.В. Нейросетевые методы распознавания изображений [Электронный ресурс]. – Режим доступа: http://rusnauka.narod.ru/lib/author/briluk_d_b/1/
- Тельнов Ю.Ф. Интеллектуальные информационные системы / Московский государственный университет экономики, статистики и информатики. – М.: МЭСИ, 2004.
- Шитиков В.К., Розенберг Г.С., Зинченко Т.Д. Количественная гидроэкология: методы системной идентификации. – Тольятти: ИЭВБ РАН, 2003. – 463 с.