Research of the algorithmic providing of the intellectual system
classifications of multidisciplinary hypertext documents
Table of contents
- Aim and tasks
- Actuality of theme of work
- Supposed scientific novelty
- Planned practical results
- Global level of research and developments on the topic
- National level of research and developments on the topic
- Local review of research and developments
- Own results
- Conclusions
- Literature
1 Aim and tasks
The aim of work are development and research
algorithmic providing of the intellectual system of classification
multidisciplinary hypertext documents with the changeable great number of categories
For the achievement of the put aim the decision of next tasks is required:
- To conduct the analysis of existent methods of classification of multidisciplinary documents
- To choose and modify the models of presentation of documents and hyperlinks of in there
- To choose the criteria of estimation of efficiency of algorithms of classification
- To modify the algorithms of classification by combination of methods of binary classification and ranging with a threshold function
- To estimate efficiency of the offered modified algorithms
The object of this research are the systems of analysis
contained Internet traffic and large collections of electronic hypertext documents.
The algorithmic comes forward the article of research
providing of the classification of hypertext documents, based on machine
educating, in the conditions of substantially intersecting classes, when a document can
to be attributed to some great number of appropriate for him classes.
2 Actuality of theme of work
A world wide web, undoubtedly, is the greatest database created
by humanity. The enormous amount of data creates as a result much new
problems on their use. Basic problems is systematization, in aims
facilitations of the manual viewing and creation of instruments of effective search on
to the queries. For the decision of these problems the directories of web pages are created [1]. In the beginning directories were built by hand, were after
tools are worked out for automation of this process. Nevertheless, difficult
to present as, for example, largest www.dmoz.org, that contains more than five
millions of pages assorted in more than million categories, we can look over
on the homepage of Open Directory Project [2].
The second approach consists in the use of fulltext search. He began with
ordinary search of accordance of words, now consists of many specialized
components that execute reformulation query, on the basis of finding out of him
semantics [3].
Except categorizing and search there is another task that plugs in itself knowledge
contained document – filtration of web pages. It can be used for
different aims: filtrations of materials for adults and children, providing of control
the uses are the internet of resources in offices, prevention of loss
confidential information, realization of monitoring of the forbidden activity
users or even blocking of uncomfortable pages of the totalitarian states. A problem with filtration of web pages can decide as a task of classification that is characteristic for Data Mining and uses methods machine
educating. The basic difference of such task of classification from traditional is
that classes in it are not mutually exclusive [4].
Classification of multidisciplinary text documents is not a banal task,
as in the small fragment of text can be contained very valuable
information, and attributing it is impossible to ignore to the corresponding class, and close
the located classes can intersect and/or meet. To such
news threads can belong similarly documents in a network the Internet, reviews,
formed by news agencies, scientific publications devoted a few
to the areas of researches, thus both near and distant(for example,
artificial intelligence and information technologies, ontological engineering
and automatic text manipulation, Biomedical, physical and chemical). Specific
enumerated applied tasks such, that set of interesting subjects
can classification dinamically change. Examples of similar family becomes
all anymore. Thus, by extraordinarily actual direction of researches
there is development of methods of classification of multidisciplinary documents.
3 the Supposed scientific novelty
Development and research of new and modification of the known algorithms of classification of multidisciplinary
documents by determination of great number of relevant classes.
4 Planned practical results
Practical meaningfulness of research consists in the increase of efficiency of classification
multidisciplinary hypertext documents.
The worked out algorithmic providing can be used for programmatic realization
intellectual system of classification decision-oriented tasks of analysis
content of Internet of traffic and corporate collections
electronic hypertext documents.
5 the Global level of research and developments on the topic
Development of approaches and algorithms of decision of task of classification of documents of mixed
to the thematic orientation – this relatively new direction of researches,
that presently actively develops abroad and in Russia. Majority
existent approaches is the alternative of the direct taking of given
tasks to the traditional task of classification the Modern methods
classification search, filtration of Internet-of traffic
based on the mechanism of automatic classification of texts. This approach, as
governed, application of methods implies categorizing that distribute
documents on the predefined set of heading on the basis of the knowledge got from
teaching great number. To development and testing of algorithms of this kind, and
the algorithms of presentation of texts also related to them labours are sanctified to such
authors as Bezdek J.C., Kohonen T., Krishnapuram R., Keller J., Desjardins G., Zhang C., T. Joachims, D.D. Lewis, R.E. Schapire, H. Schutze, F. Sebastiani,
Y. Yang, I. Dagan, S.T. Dumais.
Among the Russian researchers it is necessary to extract works of Айвазян С. А., Загоруйко М. Г. М. С. Агеев, И. Е. Кураленок, И. С. Некрестьянов, В. И. Шабанов, Глазковой В. В.
In-process [5] technology(architecture, algorithms and programmatic
tools) of construction of the system of filtration of Internet-traffic of local networks is considered on
to basis of methods of computer-aided instruction. Original architecture is offered,
using the methods of computer-aided instruction for the decision of task multitopicality
classifications of internet resource. The basic modules of the system, their algorithms, are described
works and method of organization of base of knowledge. Worked out architecture
experimentally tested on the standard test sets of data,
the results of experiments showed high enough exactness and speed
works.
6 the National level of research and developments on the topic
Theoretical algorithmic and practical questions of development
programmatic tools for the tasks of classification of multitopicality documents decide scientists Kharkov
national university of radio electronics with the use of self-organizing organized
neural networks and genetic algorithms.
In-process [6] an adaptive unclear self-organizing organized neural network is offered, and
also model of the system of clusterization of multidisciplinary text documents on
to basis of the worked out neural network, different from existent models to it
by architecture and methods of educating. The method of automatic clusterization is worked out
multidisciplinary text documents on the basis of genetic algorithm with
by a rogueing. Unlike existent genetic algorithms, in given
method in procedures of genetic optimization elements are entered artificial
selection – operators of tension, compression and displaying.
In the article [7] the problem of intellectual treatment text is examined
to information. Architecture of the unclear neural network system is presented for
classifications of text documents and on are a line algorithm of educating of network adaptive
unclear vectorial quantum
7 the Local review of research and developments
In-process [8] classification of documents is examined founded
on knowledge. The mechanism of dividing according to subject headings of texts is offered on the basis of construction of semantic networks. Dividing according to subject headings of large
text collections comes true on the beforehand fixed great number of heading.
8 Choice of method and criteria of estimation of efficiency of decision of task of classification multidisciplinary
hypertext documents
8.1 the Traditional raising of task
classifications of text documents
The objects of classification are text and hypertext
documents and their fragments are poorly structured heterogeneous
by data. Many methods are offered for the decision of task of classification by means of
automatic procedures. They can be divided on two fundamentally different
class: methods of computer-aided instruction (MC) and methods based on knowledge(also
sometimes named “engineering approach”). By the article of consideration
real work there are methods of computer-aided instruction.
Raising of task of classification. Let 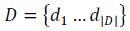 – great number of documents,
– great number of documents, 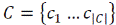 – great number of subjects, Φ: D × C→{0,1} – unknown objective function that for the pair
<Di, Cj> talks, belongs document Di to the subjects Cj. A task consists of construction of function Φ′, maximally near by Φ.
– great number of subjects, Φ: D × C→{0,1} – unknown objective function that for the pair
<Di, Cj> talks, belongs document Di to the subjects Cj. A task consists of construction of function Φ′, maximally near by Φ.
At computer-aided instruction of classifier the presence of collection is assumed yet
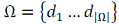 – beforehand classified
documents, i.e. with the known value of objective function. Usually in
quality of teaching selection the array of text documents comes forward,
classified by experts. The algorithm of computer-aided instruction builds procedure
classifications of documents on the basis of automatic analysis of the set great number
investigational texts. For verification of fitness of the use built
a classifier it is necessary to estimate exactness of prediction. It is necessary for this purpose
to have a test selection.
– beforehand classified
documents, i.e. with the known value of objective function. Usually in
quality of teaching selection the array of text documents comes forward,
classified by experts. The algorithm of computer-aided instruction builds procedure
classifications of documents on the basis of automatic analysis of the set great number
investigational texts. For verification of fitness of the use built
a classifier it is necessary to estimate exactness of prediction. It is necessary for this purpose
to have a test selection.
Thus, present data divide on two
groups – teaching and test selections. The first is used for a construction
models, second – for the estimation of efficiency
8.2 Description of the methods based on computer-aided instruction
Computer-aided instruction is base on presence of initial corps
documents classification of that was made beforehand. Т. е. value
functions of F : D х C – > {T, F} it is known for every pair(d, c) from W Í C. Document of dj – positive
example of ci, if F=T, and negative otherwise.
In the process of computer-aided instruction some preliminary
a process(named educating) automatically builds classifier for a category
ci, watching descriptions of documents that was appropriated by an expert category
ci or 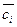 . From their
descriptions those that the classified document must have get out,
that a category was appropriated him ci. In terms of computer-aided instruction – it is a process of the controlled educating, as in the process of educating it is known to what categories all documents belong from
to training collection. Methods two classes are examined in that only ci or
named binary(image 1).
. From their
descriptions those that the classified document must have get out,
that a category was appropriated him ci. In terms of computer-aided instruction – it is a process of the controlled educating, as in the process of educating it is known to what categories all documents belong from
to training collection. Methods two classes are examined in that only ci or
named binary(image 1).
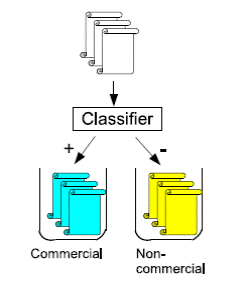
Image 1. Binary classification
Texts can not be straight interpreted by algorithms
classifications, because they operate numeric data, and text it just
sequence of symbols. The process of indexation is therefore required, as a result
that compact presentation of document of d turns outj,
comfortable for further treatment. The choice of presentation of text depends on that,
that is considered bearing sense parts of text, and what rules of treatment
natural text it is possible to apply to these parts.
Most algorithms of classification
work with the formal specification of objects on the basis of vectorial model
presentations of document [10]. In this model a document is described
by the numerical vector of an of the fixed length п, where п – number of signs,
and i-I the component of vector determines the weight of i sign. For realization of model of presentation
it is necessary to choose attributive space and define an algorithm
calculations of scales.
Quality of the chosen model of presentation
at the fixed algorithm of classification and fixed benchmark test
typing document it is possible to estimate on next criteria:
exactness of classification : basic
criterion(depends also on the algorithm of classification);
dimension of attributive space : at
to identical exactness preferably attributive space less
dimensions;
size of the got model of classification :
at identical exactness preferably compact models;
time of educating and classification : important criterion depending, including, from two
previous;
support
to morphology of language : this criterion is closely related to all previous, in
details, support of morphology conduces to more exact and compact models
classifications.
All algorithms of MC use presentation of document of dj as a vector of scales
therms of dj= <wj, 1,., wj,|T|>, where T –
great number of all therms that is taken into account in text. wj, k – weight of k therm is in a document
dj, shows, as far as large semantic
loading is carried by a k-й therm in a document. I am two basic
distinctions in going near presentation of texts :
- that is considered a therm;
- as the weight of therm is determined.
As a rule, as therms choose separate words or
their bases. This model carries the name “bag-of-words”, as it does not save
to information about the order of including of words in a document.
The most widespread method of forming of attributive space is a method
keywords [1, 2]. As signs in this method used
lexemes included in documents, and the dimension of attributive space is equal
dimensions of dictionary. However this method, for example, does not take into account morphology
language, and also semantic connections interword. Support of morphology it is possible
to realize by means of methods of Stemming [2], based on bringing words over to
to their base word-part. But then for every language the morphological is needed
an analyzer, that, conduces to the additional calculable loading and to the task of determination of language of document(if such
not indicated in properties of document) and, thirdly, for some languages construction
morphological analyzer is an intricate enough problem.
Problem
dependences of model of presentation on a language are decided by the method of N-gramme [3]. In this method in succession going letter combinations of the fixed length N undertake as signs. Thus every word is broken up on a set
signs, and paronymous words form the similar set of signs. Basic
dignity of this method of presentation is absence of necessity
linguistic aftertreatment of text and independence from concrete
language. Breaking up on N-grammes are much simpler, than
selection of base word-part, and from the limited nature of alphabet in all languages
the maximal number of different signs is also limited. As defects
method of N-a gramme can be specified increase of number unempty
signs at a document, and also that the semantic are not taken into account in a model
connections between signs.
During classification of texts, as a rule, it is known a few predefined
categories to that documents must be taken. In this case classification
named multiclass(image 2)
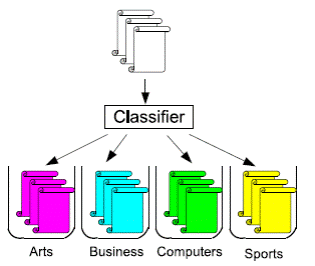
Image 2. Multiclass classification
Besides presentation of content of documents, an important moment is an account in a model
presences of hyperlinks between documents. One of most effective
modern approaches there is a method of accounting to this problem
reference structure of documents, offered in [11]. In this method at first
the documents-neighbours of the examined document are classified, and then each
a hyperlink in an initial document is replaced by the identifier of class
document-neighbour it specifies on that. Thus, hyperlinks
substituted by the special identifiers(or the special lexemes) that
characterize the themes of documents to that they allude. Such presentation
documents is base on information, that is both local and
unlocal in relation to this document. By the important lack of given
approach there is a necessity of receipt and classification of content
documents-neighbours, that brings in the additional calculable loading, and sometimes
appears impossible, if document reference specifies on that,
inaccessible.
8.3 Methods of classification of multidisciplinary documents
Raising of task of polythematic(multi-label) classification.
In teaching totality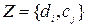 for every example
for every example 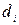 – the great number of relevant is set
classes
– the great number of relevant is set
classes 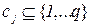 . By an aim
algorithm of computer-aided instruction there is a construction of classifier ФZ : D® 2, predictive all
relevant classes, where D initial space of signs and q number of classes.
. By an aim
algorithm of computer-aided instruction there is a construction of classifier ФZ : D® 2, predictive all
relevant classes, where D initial space of signs and q number of classes.
The existent methods of classification of multidisciplinary documents are based, mainly, on three
approaches:
- optimization
- decoupligs in the set of binary problems
- ranging.
On a fig. 3 two types of polythematic classification are shown:
rough classification(the list of classes is set it is only possible to that
to take a document) and soft classification(probability of taking is determined
document to each of classes)
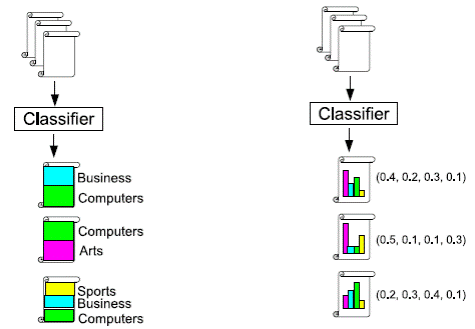
Image 3. Types of polythematic classification
To the methods of classification, based on optimization
approach, it is possible to take next methods: AdaBoost.MH, ADTBoost.MH(the function of Hamming Loss is minimized for the estimation of losses of multi-label classification), method of Multi-Label-kNN(a posteriori probabilities of belonging are maximized to the classes) and method on the basis of model
mixing, EM(model parameters are estimated on the basis of principle
maximizations of the expected value) trained by means of method.
The methods based on the decouplig of multi are label problems in the set of independent binary problems
(“one-versus-rest”), create one binary problem for each of
 classes. In a binary problem for
class
classes. In a binary problem for
class  all
the teaching examples noted by this class are considered positive, and all
other teaching examples are considered negative. During classification on
to basis of decouplig “one-versus-rest” decision about belonging of object
accepted a concrete class regardless of other classes. Because of such
approach of decouplig the methods of this group have the opportunity of addition and moving away
classes without the necessity of educating of model to classification “from the ground up”. On
today is a decouplig “one-versus-rest” it is most
by popular approach at the decision of task of classification multidisciplinary
documents in modern practical applications. By the lack of methods to it
groups there is that independent classifiers that not are built
take into account correlations between classes.
all
the teaching examples noted by this class are considered positive, and all
other teaching examples are considered negative. During classification on
to basis of decouplig “one-versus-rest” decision about belonging of object
accepted a concrete class regardless of other classes. Because of such
approach of decouplig the methods of this group have the opportunity of addition and moving away
classes without the necessity of educating of model to classification “from the ground up”. On
today is a decouplig “one-versus-rest” it is most
by popular approach at the decision of task of classification multidisciplinary
documents in modern practical applications. By the lack of methods to it
groups there is that independent classifiers that not are built
take into account correlations between classes.
A decision of task of multi is label classifications on basis
ranging includes two stages. The first stage consists of educating of algorithm
ranging, that puts in order all classes on the degree of them relevance for
set classified object. For ranging of classes multidisciplinary
objects next algorithms are used : ММР, k-NN, RankSVM. The second stage consists
in the construction of threshold function dissociating relevant classes from unrelevant one.
8.4 Methodology of measuring of descriptions of classifier
At research and comparison of algorithms, since a classifier F was built, it is necessary in somewise
to measure its efficiency. For this purpose, before the beginning of creation of classifier,
an initial corps on that testing is made is divided by two parts (not
necessarily identical size) :
- Training(and verification) collection of TV. A classifier F is built on the basis of review of descriptions of these documents.
- Test collection of Te, used for verification of efficiency of classifier. Every document of dj
from Te given on the entrance of classifier and answers of classifier F(dj, ci) compared
with the expert estimations of F(dj, ci). Efficiency of classifier is determined on the basis of that, as far as often these
estimations coincide.
Documents from Te in no shape or form must not participate in the construction of classifier. If it
a condition is not observed, then the results looked after at testing will be
too good [9]. At practical application of classifier, since
its descriptions were measured, it is possible to conduct educating, using all
initial corps, for the increase of efficiency. In this case results
previous measuring it is possible to examine as a pessimistic estimation real
to efficiency, as the classifier got in the end studied on
greater amount of data, than the classifier used for
testing.
Approach with the division of initial collection carries the name
“Training and Testing”, by an alternative there is a method “ Cross-validation” [9],
at that built k different classifiers of F1,., Fk, at
division of initial collection on k non-overlapping parts of Te>1, ., Tek and application
“Training and Testing” on the pairs (of TVi = W-Tei, Tei}. Eventual
efficiency is determined by means of аveraging of indexes of separate classifiers of F1, ., Fk.
At both approaches in the process of educating there can be a necessity to check,
as a change of some parameter will affect on efficiency. In this case
training and verification collection of TV = d1, ., d| TV | divided
on two collections:
- Training collection of Tr = d1, ., d|Tr|, on the basis of that a classifier is built.
- Verification collection of Va = d|Tr|+1, ., d |TV|, on that repetitive tests are conducted
with the purpose of optimization of parameters of classifier.
8.5 Used birth-certificates
Exactness and plenitude. Efficiency of classification, as a rule, is measured in classic birth-certificates informative
search – exactnesses(precision) and full(recall), ТК adapted to the case [13].
Exactness of pi-categoty ci
determined as conditional probability of P(F = T | F = T),
i.e. probability that casual document of dx will be correctly subsumed ci.
Like plenitude of ri categories of ci
determined, as P(F = T | F = T), i.e. probability
that document of dx, that must be taken to the category of ci, be is classified under it.
Probabilities of pi and ri can be appraised by means of table
coincidences Table 1. This table contains information about the coincidences of decisions of classifier and experts. Columns
correspond to the estimations of experts, line – to the estimations of classifier. On their
crossing there are four values:
- FPi< (false positives), number of documents
uncorrectly taken by a classifier to the category of ci;
- TPi (true positives), the number of documents is correct subsumed;
- TNi (true negatives), the number of documents is correct not subsumed;
- FNi (false negatives), the number of documents is improper not subsumed.
|
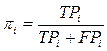
|
(1)
|
|
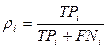
|
(2)
|
Table 1. Table of coincidences for the category of ci
|
|
Estimations of experts
|
|
Yes
|
No
|
|
Estimations of classifier
|
Yes
|
TPi
|
FPi
|
|
No
|
FNi
|
TNi
|
These values in relation to a category can be аveraging,
for the receipt of exactness of p and
plenitudes of r on all set of categories. Exists
two methodologies of аveraging :
- macro averaging – at first calculated exactness of pi and plenitude of r
i for every category separately and then аveraging on formulas(3) and(4).
|
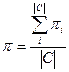
|
(3)
|
|
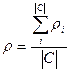
|
(4)
|
- micro averaging – the global table of coincidences(Table 2) is calculated, p
and r is calculated on formulas analogical for pi and ri.
|
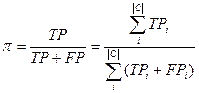
|
(5)
|
|
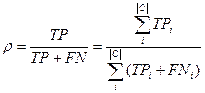
|
(6)
|
These methods give considerably differentiating results. At
micro averaging contribution of category to end-point the more than anymore
documents fall into a category. At macro averaging all categories are in equal
proportions influence on end-point. Choice of one or another аveraging
depends on an application of classifier domain.
Table 2. Global table of coincidences
|
|
Estimations of experts
|
|
Yes
|
No
|
|
Estimations of classifier
|
Yes
|
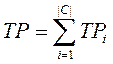
|
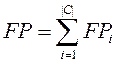
|
|
No
|
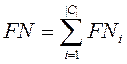
|
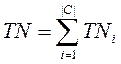
|
8.6 Offered directions of perfection of algorithms of classification
For the increase of efficiency of classification planned
to use combination of methods of binary classification for classes and
ranging with a threshold function for a selection relevant for a document
classes.
It is planned to realize the account of hyperlinks on the stage
constructions of vectorial model of presentation of document. Thus hyperlinks
analysed as text strings and their classes that are determined
taken into account at presentation of current document. At forming
presentations of document, every hyperlink is replaced by the set of the special
identifiers corresponding to the identifiers of the predicted classes. It
will allow to take into account meeting in documents hyperlinks without a necessity
receipt and analysis of content of documents-neighbours.

Image 4. Method of accounting hyperlinks at presentation
documents
Conclusions
The analysis of features of classification of documents is conducted in the case when classes can
to intersect and a document can be attributed to a few classes. Existing
methods provide quality of classification, insufficient for their application in
modern application systems. Methodology of measuring of descriptions is considered
classifier and birth-certificates are chosen for efficiency of classification. In future
it is planned to work out the model of presentation of documents taking into account hyperlinks and
algorithms of polymathematic classification on the basis of binary method and
ranging.
In writing this essay master's work is not yet complete. Final completion: December 2013. Full text of the work and materials on the topic can be obtained from the author or his manager after that date.
Literature
-
Gerhard K. H. Cataloguing Internet Resources: Practical Issues and Concerns /
K. H. Gerhard // Serials Librarian. — 1997. Vol. 32, № 1/2. — P. 123–137.
-
Open Directory Project. Интернет-ресурс. — Режим доступа: http://www.dmoz.org/
-
Кутовенко А. В. Профессиональный поиск в Интернете / А. В. Кутовенко.
— СПб.: Питер, 2011. — С. 256.
-
Comite F. D. Learning multi-label alternating decision tree from texts and data /
F. D. Comite, R. Gilleron, M. Tommasi // Machine Learning and Data Mining in Pattern Recognition,
MLDM 2003 Proceedings, Lecture Notes in Computer Science 2734. — Berlin, 2003. — P. 35–49.
-
Глазкова В. В. Система фильтрации Интернет-трафика на основе методов машинного обучения /
В. В. Глазкова, В. А. Масляков, И. В. Машечкин, М. И. Петровский // Вопросы
современной науки и практики. Университет им. В. И. Вернадского, серия «Технические науки»,
ассоциация «Объединённый университет им. В. И. Вернадского». — 2008. — том 2,
№2(12). — С. 155–168.
-
Волкова В. В. Методы нечеткой кластеризации политематических текстовых документов:
Автореф. дис. … канд. техн. наук: 05.13.23 «Системы и средства искусственного интеллекта» /
В. В. Волкова; Харьк. нац. ун-т радиоэлектроники. — Х., 2010. — С. 134.
-
Золотухин О. В. Классификация политематических текстовых документов с применением
нейро-фаззи технологий / О. В. Золотухин // Технологический аудит и резервы производства. — 2012.
— № 5/2(7). — C. 30.
-
Охрименко К. С. Рубрикация текстов на основе автоматического построения семантических сетей /
К. С. Охрименко, А. С. Калинин // Информатика и компьютерные технологии. — VIII, ДонНТУ
19-Сен-2012. — Интернет-ресурс. — Режим доступа:
http://ea.donntu.ru/handle/123456789/15560
-
Friedman J. Additive logistic regression: a statistical view of boosting / J. Friedman,
T. Hastie, R. Tibshirani // Annals of Statistics. — 2000. — Vol. 28, № 2. — P. 337–407.
-
Моченов С. В. Применение статистических методов для семантического анализа текста /
С. В. Моченов, А. М. Бледнов, Ю. А. Луговских. — Ижевск: НИЦ
«Регулярная и хаотическая динамика», 2005. — С. 408.
-
Chakrabarti S. Enhanced hypertext categorization using hyperlinks / S. Chakrabarti,
E. Byron, P. Indyk. // Proceedings of the ACM International Conference on Management of Data, SIGMOD.
— 1998. — P. 307–318.
-
Рассел С. Искусственный интеллект: современный подход, 2-е изд..: Пер с англ. /
С. Рассел, П. Норвиг – М.: Издательский дом «Вильямс», 2006. – С. 1408.
-
Baeza Y. Modern Information Retrieval / Y. Baeza, B. Ribeiro-Neto. —
Harlow: Addison-Wesley, 1999. — P. 357.
-
Венков А. Г. Построение и идентификация нечетких математических моделей технологических
процессов в условиях неопределенности: Автореф. дис. … канд. техн. наук. / А. Г. Венков. — Липецк: ЛГТУ, 2002. — С. 20.
-
Tsoumakas G. «Multi-Label Classification: An Overview»,
International Journal of Data Warehousing and Mining / G. Tsoumakas, I. Katakis. — 2007. — Vol. 3, №3 — Р. 1–13.
-
Глазкова В. В. Исследование и разработка методов построения программных средств
классификации многотемных гипертекстовых документов: Автореф. дис. … канд. физическо-мат. наук: 05.13.11 / В. В. Глазкова
— М.: МГУ, 2002. — С. 103.




