Исследование алгоритмического обеспечения интеллектуальной системы
классификации политематических гипертекстовых документов
Содержание
- Цель и задачи
- Актуальность темы работы
- Предполагаемая научная новизна
- Планируемые практические результаты
- Глобальный уровень исследований и разработок по теме
- Национальный уровень исследований и разработок по теме
- Локальный обзор исследований и разработок
- Cобственные результаты
- Выводы
- Литература
1 Цель и задачи
Целью работы является разработка и исследование
алгоритмического обеспечения интеллектуальной системы классификации
политематических гипертекстовых документов с изменяемым множеством категорий
Для достижения поставленной цели требуется решение следующих задач:
- Провести анализ существующих методов классификации политематических документов
- Выбрать и модифицировать модели представления документов и гиперссылок вних
- Выбрать критерии оценки эффективности алгоритмов классификации
- Модифицировать алгоритмы классификации путем сочетания методов бинарной классификации и ранжирования с пороговой функцией
- Оценить эффективность предложенных модифицированных алгоритмов
Объектом данного исследования являются системы анализа
содержимого Internet трафика и больших коллекций электронных гипертекстовых документов.
Предметом исследования выступает алгоритмическое
обеспечение классификации гипертекстовых документов, основанной на машинном
обучении, в условиях существенно пересекающихся классов, когда документ может
быть отнесен к некоторому множеству уместных для него классов.
2 Актуальность темы работы
Всемирная паутина, несомненно, является самой большой базой данных, созданной
человечеством. Огромное количество данных создает в результате много новых
проблем по их использованию. Основными проблемами является систематизация, в целях
облегчения ручного просмотра и создание инструментов эффективного поиска по
запросам. Для решения этих проблем создаются каталоги веб-страниц [1]. Вначале каталоги строились вручную, затем были
разработаны средства для автоматизации этого процесса. Тем не менее, трудно
представить как, например, крупнейший www.dmoz.org, который содержит более пяти
миллионов страниц отсортированных в более чем миллион категорий, мы можем просмотреть
на домашней странице Open Directory Project [2].
Второй подход заключается в использовании полнотекстового поиска. Он начинался с
обычного поиска соответствия слов, теперь состоит из многих специализированных
компонентов, которые выполняют переформулировку запроса, на основе выяснения его
семантики [3].
Кроме категоризации и поиска есть еще одна задача, которая включает в себя знание
содержимого документа – фильтрация веб-страниц. Она может быть использована для
разных целей: фильтрации материалов для взрослых и детей, обеспечения контроля
использования интернет ресурсов в офисах, предотвращения утечки
конфиденциальной информации, осуществления мониторинга запрещенной активности
пользователей или даже блокирования неудобных страниц тоталитарных государств.
Проблема с фильтрацией веб-страниц может решаться как задача классификации,
которая характерна для Data Mining и использует методы машинного
обучения. Основным отличием такой задачи классификации от традиционной является
то, что классы в ней не являются взаимоисключающими [4].
Классификация политематических текстовых документов не является тривиальной задачей,
поскольку в небольшом фрагменте текста может содержаться весьма ценная
информация, и отнесение к соответствующему классу нельзя игнорировать, а близко
расположенные классы могут пересекаться и/или сливаться. К такого рода
документам могут относиться так же новостные потоки в сети Интернет, обзоры,
формируемые новостными агентствами, научные публикации, посвященные нескольким
областям исследований, причем как близким, так и далеким (например,
искусственный интеллект и информационные технологии, онтологические инжиниринг
и автоматическая обработка текстов, медико-биологические, физико-химические). Специфика
перечисленных прикладных задач такова, что набор интересующих тематик
классификации может динамически изменяться. Примеров подобного рода становится
все больше. Таким образом, чрезвычайно актуальным направлением исследований
является разработка методов классификации политематических документов.
3 Предполагаемая научная новизна
Разработка и исследование новых и модификация известных алгоритмов классификации политематических
документов путем определения множества релевантных классов.
4 Планируемые практические результаты
Практическая значимость исследования заключается в повышении эффективности классификации
политематических гипертекстовых документов.
Разработанное алгоритмическое обеспечение может использоваться при программной реализации
интеллектуальной системы классификации, ориентированной на решение задач анализа
контента Internet трафика и корпоративных коллекций
электронных гипертекстовых документов.
5 Глобальный уровень исследований и разработок по теме
Разработка подходов и алгоритмов решения задачи классификации документов смешанной
тематической направленности – это относительно новое направление исследований,
которое в настоящее время активно развивается за рубежом и в России. Большинство
существующих подходов является альтернативой непосредственного сведения данной
задачи к традиционной задаче классификации Современные методы
классификационного поиска, фильтрации Internet-трафика
основаны на механизме автоматической классификации текстов. Данный подход, как
правило, подразумевает применение методов категоризации, которые распределяют
документы по предопределенному набору рубрик на основе знания, полученного из
обучающего множества. Разработке и тестированию алгоритмов данного вида, а
также связанным с ними алгоритмам представления текстов посвящены труды таких
авторов как Bezdek J.C., Kohonen T., Krishnapuram R., Keller J., Desjardins G.,
Zhang C., T. Joachims, D.D. Lewis, R.E. Schapire, H. Schutze, F. Sebastiani,
Y. Yang, I. Dagan, S.T. Dumais.
Среди российских исследователей следует выделить работы Айвазян С.А., Загоруйко М.Г. М. С.
Агеев, И. Е. Кураленок, И. С. Некрестьянов , В. И. Шабанов,Глазковой В.В.
В работе [5] рассмотрена технология (архитектура, алгоритмы и программные
средства) построения системы фильтрации Интернет-трафика локальных сетей на
основе методов машинного обучения. Предложена оригинальная архитектура,
использующая методы машинного обучения для решения задачи многотемной
классификации Интернет-ресурсов. Описаны основные модули системы, их алгоритмы
работы и способ организации базы знаний. Разработанная архитектура
экспериментально протестирована на эталонных тестовых наборах данных,
результаты экспериментов показали достаточно высокую точность и скорость
работы.
6 Национальный уровень исследований и разработок по теме
Теоретические алгоритмические и практические вопросы разработки
программных средств для задач классификации многотемных документов решаются учеными Харьковского
национального университета радиоэлектроники с использованием самоорганизующихся
нейронных сетей и генетических алгоритмов.
В работе [6] предложена адаптивная нечеткая самоорганизующаяся нейронная сеть, а
также модель системы кластеризации политематических текстовых документов на
основе разработанной нейронной сети, отличающиеся от существующих моделей своей
архитектурой и методами обучения. Разработан метод автоматической кластеризации
политематических текстовых документов на основе генетического алгоритма с
искусственным отбором. В отличие от существующих генетических алгоритмов, в данном
методе в процедуры генетической оптимизации вводятся элементы искусственного
отбора – операторы растяжения, сжатия и отображения.
В статье [7] рассматривается проблема интеллектуальной обработки текстовой
информации. Представлена архитектура нечеткой нейросетевой системы для
классификации текстовых документов и on-line алгоритм обучения сети адаптивного
нечеткого векторного квантования
7 Локальный обзор исследований и разработок
В работе [8] рассматривается классификация документов основанная
на знаниях. Предлагается механизм рубрикации текстов на основе построения семантических сетей. Рубрикации больших
текстовых коллекций осуществляется по заранее фиксируемому множеству рубрик.
8 Выбор метода и критериев оценки эффективности решения задачи классификации политематических
гипертекстовых документов
8.1 Традиционная постановка задачи
классификации текстовых документов
Объекты классификации текстовые и гипертекстовые
документы и их фрагменты являются слабо структурированными разнородными
данными. Предложено много методов для решения задачи классификации посредством
автоматических процедур. Их можно разделить на два принципиально различных
класса: методы машинного обучения (МО) и методы, основанные на знаниях (также
иногда именуемые «инженерный подход»). Предметом рассмотрения
настоящей работы являются методы машинного обучения.
Постановка задачи классификации. Пусть 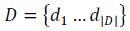 – множество документов,
– множество документов, 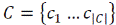 – множество тематик,
Φ: D × C→{0,1} – неизвестная целевая функция, которая для пары < Di, Cj> говорит,
принадлежитли документ Di тематике Cj. Задача состоит в построении функции Φ′, максимально близкой к Φ.
– множество тематик,
Φ: D × C→{0,1} – неизвестная целевая функция, которая для пары < Di, Cj> говорит,
принадлежитли документ Di тематике Cj. Задача состоит в построении функции Φ′, максимально близкой к Φ.
При машинном обучении классификатора предполагается еще наличие коллекции
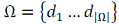 – заранее классифицированных
документов, т.е. с известным значением целевой функции. Обычно в
качестве обучающей выборки выступает массив текстовых документов,
классифицированный экспертами. Алгоритм машинного обучения строит процедуру
классификации документов на основе автоматического анализа заданного множества
исследованных текстов. Для проверки пригодности использования построенного
классификатора следует оценить точность предсказания. Для этого необходимо
иметь тестовую выборку.
– заранее классифицированных
документов, т.е. с известным значением целевой функции. Обычно в
качестве обучающей выборки выступает массив текстовых документов,
классифицированный экспертами. Алгоритм машинного обучения строит процедуру
классификации документов на основе автоматического анализа заданного множества
исследованных текстов. Для проверки пригодности использования построенного
классификатора следует оценить точность предсказания. Для этого необходимо
иметь тестовую выборку.
Таким образом, имеющиеся данные разделяют на две
группы – обучающую и тестовую выборки. Первая используется для построения
модели, вторая – для оценки эффективности
8.2 Характеристика методов, основанных на машинном обучении
Машинное обучение основывается на наличии исходного корпуса
документов, классификация которых была произведена заранее. Т.е. значение
функции F:D х C – > {T, F} известно для каждой пары (d, c) из W Í C. Документ dj – положительный
пример ci, если F(dj, ci)=T, и отрицательный в противном случае.
В процессе машинного обучения некоторый предварительный
процесс (называемый обучением) автоматически строит классификатор для категории
ci, наблюдая за характеристиками документов, которым была присвоена экспертом категория
ci или 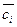 . Из их
характеристик выбираются те, которые должен иметь классифицируемый документ,
чтобы ему была присвоена категория ci.
В терминах машинного обучения – это процесс контролируемого обучения, т.к. в
процессе обучения известно к каким категориям относятся все документы из
тренировочной коллекции. Методы в которых рассматривается только два класса ci или
называются бинарными (рис 1).
. Из их
характеристик выбираются те, которые должен иметь классифицируемый документ,
чтобы ему была присвоена категория ci.
В терминах машинного обучения – это процесс контролируемого обучения, т.к. в
процессе обучения известно к каким категориям относятся все документы из
тренировочной коллекции. Методы в которых рассматривается только два класса ci или
называются бинарными (рис 1).
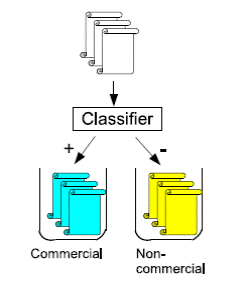
Рис.1 Бинарная классификация
Тексты не могут напрямую интерпретироваться алгоритмами
классификации, так как они оперируют числовыми данными, а текст это всего лишь
последовательность символов. Поэтому требуется процесс индексации, в результате
которого получается компактное представление документа dj,
удобное для дальнейшей обработки. Выбор представления текста зависит от того,
что считается несущими смысл частями текста, и какие правила обработки
естественного текста допустимо применять к этим частям.
Большинство алгоритмов классификации
работают с формальным описанием объектов на основе векторной модели
представления документа [10]. В этой модели документ описывается
числовым вектором a фиксированной длины п, где п – число признаков,
а i-я компонента вектора определяет вес i-го признака. Для реализации модели представления
необходимо выбрать признаковое пространство и определить алгоритм
вычисления весов.
Качество выбранной модели представления
при фиксированном алгоритме классификации и фиксированном эталонном тестовом
наборе документов можно оценить по следующим критериям:
точность классификации: основной
критерий (зависит также от алгоритма классификации);
размерность признакового пространства: при
одинаковой точности предпочтительнее признаковое пространство меньшей
размерности;
размер получаемой модели классификации:
при одинаковой точности предпочтительнее компактные модели;
время обучения и классификации: важный критерий, зависящий, в том числе, от двух
предыдущих;
поддержка
морфологии языка: этот критерий тесно связан со всеми предыдущими, в
частности, поддержка морфологии ведет к более точным и компактным моделям
классификации.
Все алгоритмы МО используют представление документа dj в виде вектора весов
термов dj= <wj,1,…, wj,|T|>, где T –
множество всех термов, которые учитываются в тексте. wj,k – вес k-го терма в документе
dj, показывает, насколько большую смысловую
нагрузку несёт k-й терм в документе. Есть два основных
различия в подходах к представлению текстов:
- что считается термом;
- как определяется вес терма.
Как правило, в качестве термов выбирают отдельные слова или
их основы. Эта модель носит название «bag-of-words», т.к. она не сохраняет
информации о порядке вхождения слов в документ.
Самым распространенным способом формирования признакового пространства является метод
ключевых слов [1, 2]. В качестве признаков в данном методе используются
лексемы, входящие в документы, а размерность признакового пространства равна
размерности словаря. Однако данный метод, например, не учитывает морфологию
языка, а также семантические связи между словами. Поддержку морфологии можно
реализовать с помощью методов стемминга [2], основанного на приведении слов к
их базовой словоформе. Но тогда для каждого языка необходим морфологический
анализатор, что, ведет к дополнительной вычислительной нагрузке и к задаче определения языка документа (если таковой
не указан в свойствах документа) и, в-третьих, для некоторых языков построение
морфологического анализатора является достаточно сложной задачей.
Проблему
зависимости модели представления от языка решает метод N-грамм
[3]. В данном методе в качестве признаков берутся подряд идущие буквосочетания
фиксированной длины N. При этом каждое слово разбивается на набор
признаков, а однокоренные слова образуют сходный набор признаков. Основным
достоинством данного метода представления является отсутствие необходимости
дополнительной лингвистической обработки текста и независимость от конкретного
языка. Разбиение на N-граммы гораздо проще, чем
выделение базовой словоформы, а из-за ограниченности алфавита во всех языках
максимальное число различных признаков также ограничено. В качестве недостатков
метода N-грамм можно указать увеличение числа непустых
признаков у документа, а также то, что в модели не учитываются семантические
связи между признаками.
При классификации текстов, как правило, известно несколько предопределенных
категорий к которым должны быть отнесены документы. В этом случае классификация
называется мультиклассовой (рис.2)
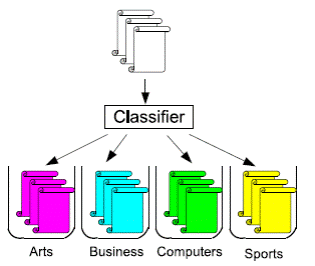
Рис.2 Мультиклассовая классификация
Помимо представления содержимого документов, важным моментом является учет в модели
наличия гиперссылок между документами. Одним из наиболее эффективных
современных подходов к данной проблеме является метод учeта
ссылочной структуры документов, предложенный в [11]. В этом методе сначала
классифицируются документы-соседи рассматриваемого документа, а затем каждая
гиперссылка в исходном документе заменяется идентификатором класса
документа-соседа, на который она указывает. Таким образом, гиперссылки
заменяются на специальные идентификаторы (или специальные лексемы), которые
характеризуют темы документов, на которые они ссылаются. Такое представление
документов основывается на информации, которая является как локальной, так и
нелокальной по отношению к данному документу. Важным недостатком данного
подхода является необходимость получения и классификации содержимого
документов-соседей, что вносит дополнительную вычислительную нагрузку, а иногда
оказывается невозможным, если документ, на который указывает ссылка,
недоступен.
8.3 Методы классификации политематических документов
Постановка задачи политематической (multi-label) классификации.
В обучающей совокупности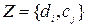 для каждого примера
для каждого примера 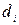 – задано множество релевантных
классов
– задано множество релевантных
классов 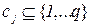 . Целью
алгоритма машинного обучения является построение классификатора ФZ : D® 2, предсказывающего все
релевантные классы, где D исходное пространство признаков и q число классов.
. Целью
алгоритма машинного обучения является построение классификатора ФZ : D® 2, предсказывающего все
релевантные классы, где D исходное пространство признаков и q число классов.
Существующие методы классификации политематических документов базируются , в основном, на трех
подходах:
- оптимизационном
- декомпозиции в набор бинарных проблем
- ранжировании.
На рис. 3 показаны два типа политематической классификации:
грубая классификация (устанавливается только список классов к которым можно
отнести документ) и мягкая классификация (определяется вероятность отнесения
документа к каждому из классов)
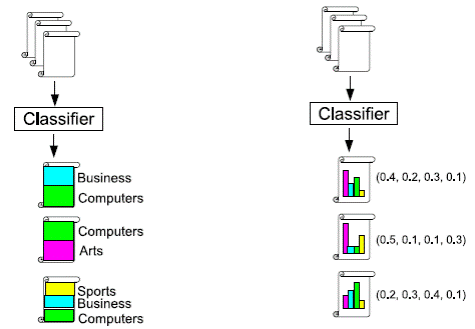
Рис 3. Типы политематической классификации
К методам классификации, основанным на оптимизационном
подходе, можно отнести следующие методы: AdaBoost.MH, ADTBoost.MH (минимизируется функция Hamming
Loss для оценки потерь multi-label классификации), метод Multi-Label-kNN (максимизируются
апостериорные вероятности принадлежности классам) и метод на основе модели
смешивания, обученной с помощью метода EM (параметры модели оцениваются на основе принципа
максимизации математического ожидания).
Методы, основанные на декомпозиции multi-label проблемы в набор независимых бинарных проблем
(«каждый-против-остальных»), создают одну бинарную проблему для каждого из
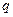 классов. В бинарной проблеме для
класса
классов. В бинарной проблеме для
класса 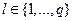 все
обучающие примеры, помеченные этим классом, считаются положительными, а все
остальные обучающие примеры считаются отрицательными. При классификации на
основе декомпозиции «каждый-против-остальных» решение о принадлежности объекта
конкретному классу принимается независимо от остальных классов. Ввиду такого
подхода декомпозиции методы этой группы имеют возможность добавления и удаления
классов без необходимости обучения модели классификации «с нуля». На
сегодняшний день декомпозиция «каждый-против-остальных» является наиболее
популярным подходом при решении задачи классификации политематических
документов в современных практических приложениях. Недостатком методов этой
группы является то, что строятся независимые классификаторы, которые не
учитывают корреляции между классами.
все
обучающие примеры, помеченные этим классом, считаются положительными, а все
остальные обучающие примеры считаются отрицательными. При классификации на
основе декомпозиции «каждый-против-остальных» решение о принадлежности объекта
конкретному классу принимается независимо от остальных классов. Ввиду такого
подхода декомпозиции методы этой группы имеют возможность добавления и удаления
классов без необходимости обучения модели классификации «с нуля». На
сегодняшний день декомпозиция «каждый-против-остальных» является наиболее
популярным подходом при решении задачи классификации политематических
документов в современных практических приложениях. Недостатком методов этой
группы является то, что строятся независимые классификаторы, которые не
учитывают корреляции между классами.
Решение задачи multi-label классификации на основе
ранжирования включает два этапа. Первый этап состоит в обучении алгоритма
ранжирования, который упорядочивает все классы по степени их релевантности для
заданного классифицируемого объекта. Для ранжирования классов политематических
объектов применяются следующие алгоритмы: ММР, k-NN, RankSVM. Второй этап заключается
в построении пороговой функции, отделяющей релевантные классы от нерелевантных.
8.4 Методика измерения характеристик классификатора
При исследовании и сравнении алгоритмов, после того как классификатор F был построен, необходимо каким-то образом
измерить его эффективность. Для этого, перед началом создания классификатора,
исходный корпус, на котором производится тестирование, делится на две части (не
обязательно одинакового размера):
- Тренировочная (и проверочная) коллекция TV.
Классификатор F строится на основе
обзора характеристик этих документов.
- Тестовая коллекция Te, используется для проверки эффективности классификатора. Каждый документ dj
из Te подаётся на вход классификатора и ответы классификатора F(dj, ci) сравниваются
с экспертными оценками F’(dj, ci).
Эффективность классификатора определяется на основе того, насколько часто эти
оценки совпадают.
Документы из Te ни в каком виде не должны участвовать в построении классификатора. Если это
условие не соблюдается, то наблюдаемые при тестировании результаты будут
слишком хороши [9]. При практическом применении классификатора, после того как
его характеристики были измерены, можно провести обучение, используя весь
исходный корпус, для повышения эффективности. В этом случае результаты
предыдущих измерений можно рассматривать как пессимистическую оценку реальной
эффективности, т.к. полученный в конечном итоге классификатор обучался на
большем количестве данных, чем классификатор, использовавшийся при
тестировании.
Подход с разделением исходной коллекции носит название
«обучение-и-тестирование», альтернативой ему является метод «кросс-валидации» [9],
при котором строится k различных классификаторов F1,…, Fk, при
разделении исходной коллекции на k непересекающихся частей Te>1, …, Tek и применении
«обучения-и-тестирования» на парах (TVi = W-Tei, Tei}. Конечная
эффективность определяется с помощью усреднения показателей отдельных классификаторов F1, …, Fk.
При обоих подходах в процессе обучения может возникнуть необходимость проверить,
как скажется изменение какого-либо параметра на эффективности. В этом случае
тренировочная и проверочная коллекция TV = d1, …, d| TV | разделяется
на две коллекции:
- Тренировочная коллекция Tr = d1, …, d|Tr|, на основе которой строится классификатор.
- Проверочная коллекция Va = d|Tr|+1, …, d |TV|, на которой проводятся повторяющиеся тесты
с целью оптимизации параметров классификатора.
8.5 Используемые метрики
Точность и полнота. Эффективность классификации, как правило, измеряется в классических метриках информационного
поиска – точности (precision) и полноте (recall), адаптированных к случаю ТК [13].
Точность pi-категории ci
определяется как условная вероятность P(F’(dx, ci) = T | F(dx, ci) = T),
т.е. вероятность того, что случайный документ dx будет корректно отнесён к категории ci.
Аналогично полнота ri категории ci
определяется, как P(F(x, ci) = T | F’(dx, ci) = T), т.е. вероятность
того, что документ dx, который должен быть отнесён к категорией ci, буде классифицирован под ней.
Вероятности pi и ri могут быть оценены с помощью таблицы
совпадений Таблица 1. Эта таблица содержит информацию о совпадениях решений классификатора и экспертов. Столбцы
соответствуют оценкам экспертов, строки – оценкам классификатора. На их
пересечениях находятся четыре значения:
- FPi< (false positives), число документов
некорректно отнесённых классификатором к категории ci;
- TPi (true positives), число документов корректно отнесённых к категории;
- TNi (true negatives), число документов корректно не отнесённых к категории;
- FNi (false negatives), число документов некорректно не отнесённых к категории.
|
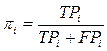
|
(1)
|
|
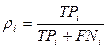
|
(2)
|
Таблица 1. Таблица совпадений для категории ci
|
|
Оценки экспертов
|
|
Да
|
Нет
|
|
Оценки классификатора
|
Да
|
TPi
|
FPi
|
|
Нет
|
FNi
|
TNi
|
Эти значения относительно категории могут быть усреднены,
для получения точности p и
полноты r на всём наборе категорий. Существует
две методики усреднения:
- Макроусреднение – сначала вычисляются точность pi и полнота r
i для каждой категории отдельно и затем усредняются по формулам (3) и (4).
|
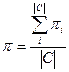
|
(3)
|
|
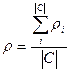
|
(4)
|
- Микроусреднение – вычисляется глобальная таблица совпадений (Таблица 2), p
и r вычисляются по формулам аналогичным для pi и ri.
|
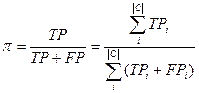
|
(5)
|
|
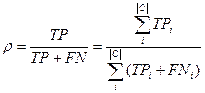
|
(6)
|
Эти методы дают значительно различающиеся результаты. При
микроусреднении вклад категории в конечный результат тем больше, чем больше
документов относятся к категории. При макроусреднении все категории в равных
пропорциях влияют на конечный результат. Выбор того или иного усреднения
зависит от области применения классификатора.
Таблица 2. Глобальная таблица совпадений
|
|
Оценки экспертов
|
|
Да
|
Нет
|
|
Оценки классификатора
|
Да
|
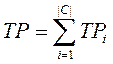
|
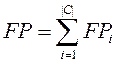
|
|
Нет
|
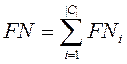
|
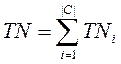
|
8.6 Предлагаемые направления совершенствования алгоритмов классификации
Для повышения эффективности классификации планируется
использовать сочетание методов бинарной классификации для классов и
ранжирование с пороговой функцией для выделения релевантных для документа
классов.
Планируется реализовать учет гиперссылок на этапе
построения векторной модели представления документа. При этом гиперссылки
анализируются как текстовые строки и определяются их классы, которые
учитываются при представлении текущего документа. При формировании
представления документа, каждая гиперссылка заменяется набором специальных
идентификаторов, соответствующих идентификаторам предсказанных классов. Это
позволит учитывать встречающиеся в документах гиперссылки без необходимости
получения и анализа содержимого документов-соседей.

Рис. 4. Способ учeта гиперссылок при представлении
документов
Выводы
Проведен анализ особенностей классификации документов в случае, когда классы могут
пересекаться и документ может быть отнесен к нескольким классам. Существующие
методы обеспечивают качество классификации, недостаточное для их применения в
современных прикладных системах. Рассмотрена методика измерения характеристик
классификатора и выбраны метрики для эффективности классификации. В дальнейшем
планируется разработать модель представления документов с учетом гиперссылок и
алгоритмы политематической классификации на основе бинарного метода и
ранжирования.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2013 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Литература
-
Gerhard K. H. Cataloguing Internet Resources: Practical Issues and Concerns /
K. H. Gerhard // Serials Librarian. — 1997. Vol. 32, № 1/2. — P. 123–137.
-
Open Directory Project. Интернет-ресурс. — Режим доступа: http://www.dmoz.org/
-
Кутовенко А. В. Профессиональный поиск в Интернете / А. В. Кутовенко.
— СПб.: Питер, 2011. — С. 256.
-
Comite F. D. Learning multi-label alternating decision tree from texts and data /
F. D. Comite, R. Gilleron, M. Tommasi // Machine Learning and Data Mining in Pattern Recognition,
MLDM 2003 Proceedings, Lecture Notes in Computer Science 2734. — Berlin, 2003. — P. 35–49.
-
Глазкова В. В. Система фильтрации Интернет-трафика на основе методов машинного обучения /
В. В. Глазкова, В. А. Масляков, И. В. Машечкин, М. И. Петровский // Вопросы
современной науки и практики. Университет им. В. И. Вернадского, серия «Технические науки»,
ассоциация «Объединённый университет им. В. И. Вернадского». — 2008. — том 2,
№2(12). — С. 155–168.
-
Волкова В. В. Методы нечеткой кластеризации политематических текстовых документов:
Автореф. дис. … канд. техн. наук: 05.13.23 «Системы и средства искусственного интеллекта» /
В. В. Волкова; Харьк. нац. ун-т радиоэлектроники. — Х., 2010. — С. 134.
-
Золотухин О. В. Классификация политематических текстовых документов с применением
нейро-фаззи технологий / О. В. Золотухин // Технологический аудит и резервы производства. — 2012.
— № 5/2(7). — C. 30.
-
Охрименко К. С. Рубрикация текстов на основе автоматического построения семантических сетей /
К. С. Охрименко, А. С. Калинин // Информатика и компьютерные технологии. — VIII, ДонНТУ
19-Сен-2012. — Интернет-ресурс. — Режим доступа:
http://ea.donntu.ru/handle/123456789/15560
-
Friedman J. Additive logistic regression: a statistical view of boosting / J. Friedman,
T. Hastie, R. Tibshirani // Annals of Statistics. — 2000. — Vol. 28, № 2. — P. 337–407.
-
Моченов С. В. Применение статистических методов для семантического анализа текста /
С. В. Моченов, А. М. Бледнов, Ю. А. Луговских. — Ижевск: НИЦ
«Регулярная и хаотическая динамика», 2005. — С. 408.
-
Chakrabarti S. Enhanced hypertext categorization using hyperlinks / S. Chakrabarti,
E. Byron, P. Indyk. // Proceedings of the ACM International Conference on Management of Data, SIGMOD.
— 1998. — P. 307–318.
-
Рассел С. Искусственный интеллект: современный подход, 2-е изд..: Пер с англ. /
С. Рассел, П. Норвиг – М.: Издательский дом «Вильямс», 2006. – С. 1408.
-
Baeza Y. Modern Information Retrieval / Y. Baeza, B. Ribeiro-Neto. —
Harlow: Addison-Wesley, 1999. — P. 357.
-
Венков А. Г. Построение и идентификация нечетких математических моделей технологических
процессов в условиях неопределенности: Автореф. дис. … канд. техн. наук. / А. Г. Венков. — Липецк: ЛГТУ, 2002. — С. 20.
-
Tsoumakas G. «Multi-Label Classification: An Overview»,
International Journal of Data Warehousing and Mining / G. Tsoumakas, I. Katakis. — 2007. — Vol. 3, №3 — Р. 1–13.
-
Глазкова В. В. Исследование и разработка методов построения программных средств
классификации многотемных гипертекстовых документов: Автореф. дис. … канд. физическо-мат. наук: 05.13.11 / В. В. Глазкова
— М.: МГУ, 2002. — С. 103.




