Интеллектуальный анализ данных
пользовательских шаблонов навигации
Авторы: Jose Borges, Mark Levene
Перевод с английского: Д.М. Мазур
Описание:В статье рассматривается модель интеллектуального анализа данных, которая фиксирует шаблоны в навигации пользователей.
Источник: CiteSeerX
Аннотация
Мы предлагаем модель интеллектуального анализа данных, которая фиксирует шаблоны в поведении пользователей при навигации. Пользовательские сессии навигации моделируются как гипертекстовая вероятностная грамматика, где более высокие ряды вероятности соответствуют предпочтительным путям пользователей. Предложен алгоритм эффективного анализа таких путей. Мы используем модель N грамм, которая предполагает, что последние просмотренные N страницы влияют на вероятность посещения следующей страницы. Модель основана на теории вероятностной грамматики, предоставляющую ей прочную теоретическую основу для будущих усовершенствований. Кроме того, мы предлагаем использование энтропии в качестве оценки статистических свойств грамматики. Были проведены обширные эксперименты, и результаты показывают, что алгоритм работает в линейном времени, грамматическая энтропия является хорошей оценкой количества полученных путей и правила реальных данных подтверждают эффективность модели.
1. Введение
Интеллектуальный анализ данных и обнаружение знаний является действующей исследовательской дисциплиной, включающей в себя изучение методов, которые ищут шаблоны в больших наборах данных. Между тем, стремительный рост Всемирной паутины (известной как Интернет) в последние годы превратил ее в крупнейший источник данных, доступных в Интернете. Таким образом, применение методов интеллектуального анализа данных в Интернете, называемое интеллектуальным анализом веб-данных, было естественным следующим шагом, и теперь является центром внимания все большего числа исследователей.
В настоящее время в интеллектуальном анализе веб-данных есть три основных направления исследований: (I) извлечение информации, (II), извлечение структуры веб-ссылки, и (III) анализ моделей поведения пользователей. Извлечение информации фокусируется на разработке методов для содействия пользователям в обработке больших объемов данных, с которыми они сталкиваются при навигации, и в помощи им найти информацию, которую они ищут, см., например, [11]. Извлечение структуры ссылки направлено на разработку методов для использования коллективного мнения о качестве веб страницы в виде гиперссылок, которые можно рассматривать как механизм неявного одобрения, см. [5]. Цель состоит в том, чтобы определить для данного объекта авторитетные страницы и страницы-концетраторы. Авторитетными страницами являются те, которым были присвоены значения по существующим на них ссылкам. Концентраторы страниц – страницы, которые содержат набор ссылок на соответствующие значения. Наконец, еще одним направлением исследований, которым занимается все большее число исследователей, является нахождение шаблонов навигации пользователя. Это исследование фокусируется на методах, которые изучают поведение пользователя при навигации по сайту. Понимание предпочтений посетителей в навигации является важнейшим шагом в повышении качества услуг электронной коммерции. Фактически, понимание наиболее вероятных шаблонов доступа пользователей позволяет провайдеру настроить и адаптировать интерфейс сайта для отдельного пользователя [16], а также улучшить статическую структуру сайта в пределах лежащей в основе гипертекстовой системы [19].
Когда веб-пользователи взаимодействуют с сайтом, запись их поведения хранится в журналах веб-серверов, которые для сайта среднего размера могут составлять до нескольких мегабайт в день. Кроме того, поскольку данные журнала собраны в необработанном формате – это идеальная мишень для анализа автоматизированными средствами. В настоящее время доступно несколько коммерческих инструментов анализа журналов [23]; однако эти инструменты имеют ограниченные возможности анализа, которые выдают только такие результаты, как сводная статистика и частота посещений страниц. Между тем научное сообщество занимается изучением методов интеллектуального анализа данных, чтобы в полной мере воспользоваться информацией, доступной в файлах журнала. До сих пор были два основных подхода к извлечению моделей навигации пользователей из данных журнала. В первом подходе данные журнала отображаются в реляционных таблицах и адаптированной версии стандартных методов анализа данных, таких как добыча ассоциативных правил, см., например, [8]. Во втором подходе разработаны методы, которые могут быть использованы непосредственно на данных журнала, см., например, [2] или [21].
В этой статье мы предлагаем новую модель для подхода к решению проблемы интеллектуального анализа данных журнала, которая непосредственно отражает семантику пользовательских сессий навигации. Мы моделируем записи пользовательской навигации, выведенные из данных журнала, как гипертекстовую вероятностную грамматику, сгенерированные с более высокой вероятностью ряды которой соответствуют предпочтительным путям пользователей. Таким образом, предоставляются компактные и автономные модели взаимодействия пользователя с сетью. Есть два условия, в которых такая модель является потенциально полезной. С одной стороны, это может помочь сервисному провайдеру понять потребности пользователей и, как следствие, улучшить качество своих услуг. Качество обслуживания может быть улучшено путем предоставления адаптивных страниц, подходящих отдельному пользователю, путем создания динамических страниц заблаговременно, чтобы сократить время ожидания, или путем предоставления теоретического сервиса, который наряду с запрашиваемым документом посылает ряд других документов, на которые может поступить запрос в ближайшем будущем. С другой стороны, такая модель может быть полезна для отдельных пользователей сети, выступая в качестве личного помощника, интегрированного с его/ее веб-браузером.
В самом деле, если браузер хранит файл журнала пользователя, который характеризует его/ее взаимодействия с сетью, постепенно может быть построена гипертекстовая вероятностная грамматика. Такая грамматика стала бы представлением знаний пользователя о сети, которое могло бы выступать в качестве памятки; могла бы быть проанализированной с целью вывода предпочтительных путей пользователя для данного объекта, или работать как инструмент прогноза для предварительной выборки интересных страниц.
Раздел 2 представляет предлагаемую гипертекстовую грамматическую модель, а в разделе 3 представлены результаты проведенных экспериментов. В разделе 4 обсуждается соответствующая работа, в разделе 5 представлены предварительные обсуждения последних усовершенствований в модели. Наконец, в разделе 6 мы представляем наши заключительные замечания и обсуждаем дальнейшую работу.
2. Гипертекстовая вероятностная грамматика
Файл журнала можно рассматривать в качестве упорядоченного по каждому пользователю множества запросов веб-страниц, из которых можно сделать вывод о сессиях пользовательской навигации. В этой работе мы просто определяем сессии пользовательской навигации в виде последовательности запросов страниц так, что нет двух последовательных запросов, разделенных более Х минутами, где X является параметром. В работе [4] авторы предложили для X значения в 25,5 минут, что соответствует 1,5 стандартных отклонений от среднего времени между событиями пользовательского интерфейса. С тех пор многие авторы приняли значение 30 минут. Отметим, однако, что более продвинутые методы подготовки данных, такие, как описаны в [9], могут быть использованы на стадии предварительной обработки данных для того, чтобы в полной мере воспользоваться всей информацией, имеющейся в файлах журнала.
Сессии навигации пользователя, выведенные из данных журнала, моделируются как гипертекстовый вероятностный язык, порожденный гипертекстовой вероятностной грамматикой (или просто ГВГ) [14], которая является собственным подклассом вероятностных регулярных грамматик [24]. ГВГ является вероятностной регулярной грамматикой, которая имеет соответствие один-к-одному между набором неконечных символов и набором конечных символов. Каждый неконечный символ соответствует веб-странице и производное правило соответствует связи между страницами. Кроме того, есть два дополнительных состояния, S и F, которые представляют собой начальное и конечное состояния сессий навигации.
Из множества пользовательских сессий мы получаем сколько раз страница была запрошена, сколько раз она была первым состоянием в сессии, и сколько раз она была последним состоянием в сессии. Число раз, которое последовательность из двух страниц появляется в сессиях, дает число раз, сколько по соответствующей ссылке перешли. Вероятность перехода из состояния, которое соответствует веб-странице, пропорциональна количеству раз, которое соответствующая ссылка была выбрана по отношению к количеству раз, которое пользователь посетил страницу.
Вероятность перехода с начального состояния пропорциональна количеству раз, которое посетили соответствующее состояние, подразумевая, что назначение узла перехода с высокой вероятностью соответствует состоянию, которое посетили чаще. Мы определяем a в качестве параметра, который назначает нужный вес состоянию, которое является первым в сессии навигации пользователей. Если a = 0 единственные состояния, которые были первыми в сессии, имеют вероятность больше нуля, будучи в переходе с начального состояния, с другой стороны, если a = 1 все состояния визитов даны пропорционально весу. Отметим, что при a> 0 каждое грамматическое состояние имеет начальную вероятность больше нуля. Вероятности переходов из начального состояния соответствует вектору начальных вероятностей, pi, и вероятности других переходов соответствуют матрице перехода цепи Маркова [12].
В примере, приведенном на рисунке 1, у нас есть 6 пользовательских сессий в общей сложности с 24 запросами страниц, где состояние A1 посетили 4 раза, 2 из которых являются первым состоянием в сессии пользователя, поэтому, так как a = 0,5 имеем pi(A1) = 0,5*4/24 + 0,5*2/6 = 0,25.
На рисунке 2 показана грамматика, выведенная из данного набора путей для N = 1 и a = 0,5.
(Мы свободно используем в наших цифрах двойственность между грамматикой и автоматами [13]).

Рис. 1 – Пример набора путей пользователей
В ГВГ вероятность первого шага решения определяется как предел поддержки, T, и не учитывается при выводе вероятности. Таким образом, вероятности перехода из начального состояния используются для сокращения рядов, которые в противном случае могут иметь высокую вероятность, но соответствуют подмножеству редко посещаемой гипертекстовой системы. Кроме того, ряд включается в язык грамматики, если вероятность его вывода выше границы разделения, L, где граница разделения соответствует грамматическому пределу доверия. Значения пределов поддержки и доверия дают пользователю контроль над количеством и качеством путей, которые будут включены в множество правил. Ряды, сгенерированные грамматикой, соответствуют путям навигации пользователя, и цель заключается в выявлении подмножества тех рядов, которые лучше всего характеризуют поведение пользователя при посещении сайта. Такие параметры, как доверие и поддержка, определяются как предпочтительные меры, которые оценивают сгенерированные ряды. Алгоритм, используемый для выработки правил, имеющих доверие и поддержку выше указанного предела, является частным случаем ориентированного графа «Поиск в глубину», который выполняет перебор всех рядов с требуемыми характеристиками, ср. [2].
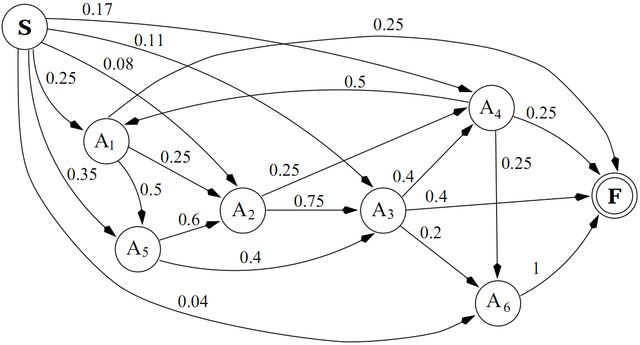
Рис. 2 – Гипертекстовая грамматика для N = 1 и a = 0,5
На рисунке 3 мы показываем правила, полученные при различных конфигурациях модели. Из первых двух множеств правил мы можем видеть, как и ряд правил, и его средняя длина уменьшается, когда граница разделения увеличивается. Отметим, что хотя A3 никогда не было первым состоянием в сессии навигации, оба ряда правил включают в себя правила, начинающиеся с этого. Это происходит потому, что A3 имеет высокую частоту обхода и значение параметра a = 0,5 дает ей положительный вес. Третье множество правил имеет более высокий предел поддержки и, как следствие, правила, начинающиеся с A3 состояния, исключены. Наконец, множество правил 4 соответствует грамматике, выведенной в то время, как присвоен одинаковый вес для всех обходов, т. е. a = 1,0 и, следовательно, правила, начинающиеся с A2 и A3 включены, хотя эти состояния никогда не были первыми в сессии навигации.
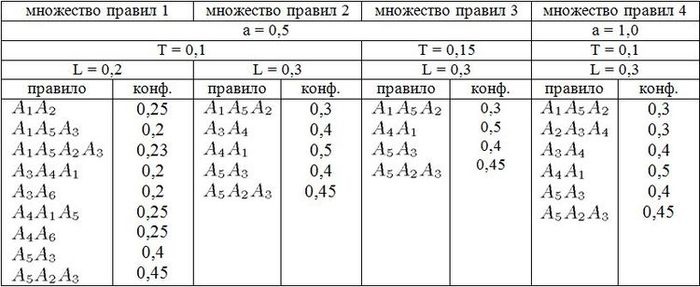
Рис. 3 – Правила, полученные при различных конфигурациях модели
Заключительные замечания
Мы предложили модель гипертекста для захвата пользовательских предпочтений при навигации в Интернете. Мы утверждаем, что преимуществом нашей модели является компактность, автономность, последовательность, и то, что она основана на хорошо организованной работе в вероятностной грамматике, предоставляя прочную основу для будущих усовершенствований, включая изучение ее статистических свойств. Фактически, размер модели зависит только от количества страниц и ссылок на анализируемом веб-сайте, а не от количества собранных данных.
Список литературы
- Azer Bestavros. Using speculation to reduce server load and service time on the www. In Proc. of the fourth ACM International Conference on Information and Knowledge Management, pages 403{410, Baltimore,MD, 1995.
- J. Borges and M. Levene. Mining association rules in hypertext databases. In Proc. of the fourth Int. Conf. on Knowledge Discovery and Data Mining, pages 149{153, August 1998.
- Jose Borges and Mark Levene. Heuristics for mining high quality user web navigation patterns. Research Note RN/99/68, Department of Computer Science, University College London, Gower Street, London, UK, October 1999.
- Alex G. Buchner, M. Baumgarten, S.S. Anand, Maurice D. Mulvenna, and J.G. Hughes. Navigation pattern discovery from internet data. In Proc. of the Web Usage Analysis and User Profiling Workshop, pages 25{30, San Diego, California, August 1999.
- Alex G. Buchner, Maurice D. Mulvenna, Sarab S. Anand, and John G. Hughes. An internet-enabled knowledge discovery process. In Proc. of 9th International Database Conference, pages 13{27, Hong Kong, July 1999.
- Lara D. Catledge and James E. Pitkow. Characterizing browsing strategies in the world wide web. Computer Networks and ISDN Systems, 27(6):1065{1073, April 1995.
- Soumen Chakrabarti, Byron E. Dom, David Gibson, Jon Kleinberg, Ravi Kumar, Prabhakar Raghavan, Sridhar Rajagopalan, and Andrew S. Tomkins. Mining the link structure of the world wide web. IEEE Computer, 32(8):60{67, August 1999.
- E. Charniak. Statistical Language Learning. The MIT Press, 1996.
- Christopher Chatfield. Statistical inferences regarding markov chain models. Applied Statistics, 22:7{20, 1973.
- M.-S. Chen, J. S. Park, and P. S. Yu. Eficient data mining for traversal patterns. IEEE Trans. on Knowledge and Data Eng., 10(2):209{221, March/April 1998.
- R. Cooley, B. Mobasher, and J. Srivastava. Data preparation for mining world wide web browsing patterns. Knowledge and Information Systems, 1(1):5{32, February 1999.
- T. Cover and J. Thomas. Elements of Information Theory. John Wiley & Sons, 1991.
- M. Craven, D. DiPasquo, D. Freitag, A. McCallum, T. Mitchell, K. Nigam, and S. Slattery. Learning to extract symbolic knowledge from the world wide web. In Proc. of the 15th National Conf. on Arti_cial Intelligence, pages 509{516, July 1998.
- W. Feller. An Introduction to Probability Theory and Its Applications. John Wiley & Sons, second edition, 1968.
- J. Hopcroft and J.Ullman. Introduction to Automata Theory, Languages, and Computation. Addison-Wesley, 1979.
- M. Levene and G. Loizou. A probabilistic approach to navigation in hypertext. Information Sciences, 114:165{186, 1999.
- Venkata N. Padmanabhan and Jeffrey C. Mogul. Using predictive prefetching to improve world wide web latency. Computer Communications Review, 26, 1996.
- Mike Perkowitz and Oren Etzioni. Adaptive web sites: an AI challenge. In Proc. of Fifteenth International Joint Conference on Artificial Intelligence (IJCAI-97), pages 16{21, Nagoya, Japan, August 1997.
- Mike Perkowitz and Oren Etzioni. Adaptive sites: Automatically synthesizing web pages. In Proc. of the Fifteenth National Conference on Artificial Intelligence (AAAI-98), pages 727{732, Madison, Wisconsin, July 1998.
- Peter L.T. Pirolli and James E. Pitkow. Distributions of surfers' paths through the world wide web: Empirical characterizations. World Wide Web, 2:29{45, 1999.
- L. Rosenfeld and P. Morville. Information Architecture for the World Wide Web. O'Reilly, 1998.
- S. Schechter, M. Krishnan, and M. D. Smith. Using path profiles to predict http requests. Computer Networks and ISDN Systems, 30:457{467, 1998.
- M. Spiliopoulou, L. C. Faulstich, and K. Wilkler. A data miner analyzing the nav-igational behaviour of web users. In Proc. of the Workshop on Machine Learning in User Modelling of the ACAI99, Greece, July 1999.
- Myra Spiliopoulou and Lukas C. Faulstich. WUM: a tool for web utilization analysis. In Proc. of the International Workshop on the Web and Databases (WebDB'98), pages 184{203, Valencia, Spain, March 1998.
- R. Stout. Web Site Stats: tracking hits and analyzing trafic. Osborne McGraw-Hill, 1997.
- C. S. Wetherell. Probabilistic languages: A review and some open questions. Computing Surveys, 12(4):361{379, December 1980.
- T. W. Yan, M. Jacobsen, H. Garcia-Molina, and U. Dayal. From user access patterns to dynamic hypertext linking. In Proc. of the 5th Int. World Wide Web Conference, pages 1007{1014, 1996.
- O. R. Zaane, M. Xin, and J. Han. Discovering web access patterns and trends by applying olap and data mining technology on web logs. In Proc. Advances in Digital Libraries Conf., pages 12{29, Santa Barbara, CA, April 1998.