
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, планируемые результаты
- 3. Обзор исследований и разработок
- 3.1 Обзор международных источников
- 3.2 Обзор национальных и локальных источников
- 4. Исследование кольцевого теста на SMP системе
- Выводы
- Список источников
Введение
Прошло немногим более 50 лет с момента появления первых электронных вычислительных машин–компьютеров. За это время сфера их применения охватила практически все области человеческой деятельности. Сегодня невозможно представить себе эффективную организацию работы без применения компьютеров в таких областях, как планирование и управление производством, проектирование и разработка сложных технических устройств, издательская деятельность, образование — словом, во всех областях, где возникает необходимость в обработке больших объемов информации. Однако наиболее важным по-прежнему остается использование их в том направлении, для которого они собственно и создавались, а именно, для решения больших задач, требующих выполнения громадных объемов вычислений. Такие задачи возникли в середине прошлого века в связи с развитием атомной энергетики, авиастроения, ракетно-космических технологий и ряда других областей науки и техники.
В наше время круг задач, требующих для своего решения применения мощных вычислительных ресурсов, еще более расширился. Это связано с тем, что произошли фундаментальные изменения в самой организации научных исследований. Вследствие широкого внедрения вычислительной техники значительно усилилось направление численного моделирования и численного эксперимента.
Вычислительное направление применения компьютеров всегда оставалось основным двигателем прогресса в компьютерных технологиях. Не удивительно поэтому, что в качестве основной характеристики компьютеров используется такой показатель, как производительность — величина, показывающая, какое количество арифметических операций он может выполнить за единицу времени. Именно этот показатель с наибольшей очевидностью демонстрирует масштабы прогресса, достигнутого в компьютерных технологиях. Так, например, производительность одного из самых первых компьютеров EDSAC составляла всего около 100 операций в секунду, тогда как пиковая производительность такого суперкомпьютера Earth Simulator оценивается в 40 триллионов операций/сек. Т.е. произошло увеличение быстродействия в 400 миллиардов раз! Невозможно назвать другую сферу человеческой деятельности, где прогресс был бы столь очевиден и так велик [1].
Естественно, что у любого человека сразу же возникает вопрос: за счет чего это оказалось возможным? Как ни странно, ответ довольно прост: примерно 1000-кратное увеличение скорости работы электронных схем и максимально широкое распараллеливание обработки данных.
Идея параллельной обработки данных как мощного резерва увеличения производительности вычислительных аппаратов была высказана Чарльзом Бэббиджем примерно за сто лет до появления первого электронного компьютера. Однако уровень развития технологий середины 19-го века не позволил ему реализовать эту идею. С появлением первых электронных компьютеров эти идеи неоднократно становились отправной точкой при разработке самых передовых и производительных вычислительных систем. Без преувеличения можно сказать, что вся история развития высокопроизводительных вычислительных систем — это история реализации идей параллельной обработки на том или ином этапе развития компьютерных технологий, естественно, в сочетании с увеличением частоты работы электронных схем.
1. Актуальность темы
Вычислительная техника в своем развитии по пути повышения быстродействия ЭВМ приблизилась к физическим пределам. Время переключения электронных схем достигло долей наносекунды, а скорость распространения сигналов в линиях, связывающих элементы и узлы машины, ограничена значением 30 см/нс (скоростью света). Поэтому дальнейшее уменьшение времени переключения электронных схем не позволит существенно повысить производительность ЭВМ. В этих условиях требования практики (сложные физико-технические расчеты, многомерные экономико-математические модели и другие задачи) по дальнейшему повышению быстродействия ЭВМ могут быть удовлетворены только путем распространения принципа параллелизма на сами устройства обработки информации и создания многомашинных и многопроцессорных (мультипроцессорных) вычислительных систем. Такие системы позволяют распараллелить выполнение программы или одновременно выполнять несколько программ.
Одной из разновидностей таких систем является SMP система. Характерной чертой многопроцессорных систем SMP архитектуры является то, что все процессоры имеют прямой и равноправный доступ к любой точке общей памяти. Первые SMP системы состояли из нескольких однородных процессоров и массива общей памяти, к которой процессоры подключались через общую системную шину. Однако очень скоро обнаружилось, что такая архитектура непригодна для создания сколь либо масштабных систем. Первая возникшая проблема — большое число конфликтов при обращении к общей шине. Остроту этой проблемы удалось частично снять разделением памяти на блоки, подключение к которым с помощью коммутаторов позволило распараллелить обращения от различных процессоров. Однако и в таком подходе неприемлемо большими казались накладные расходы для систем более чем с 32-мя процессорами [1].
Магистерская работа посвящена актуальной научной задаче — повышение эффективности и расширение класса решаемых задач путем разработки специального программного обеспечения планировщика и монитора выполнения SMP системы для многоядерных компьютеров. Исследование сложной динамической системы на основе многоядерного компьютера позволит проанализировать существующие конфликты работы с общей виртуальной памятью, рассмотреть особенности организации современной архитектуры кэш памяти, а также разработать методики распараллеливания данных в потоках и оптимизировать производительность при реализации сложной динамической системы на многоядерной SMP-платформе.
2. Цель и задачи исследования, планируемые результаты
Целью исследования является разработка специального программного обеспечения планировщика и монитора выполнения SMP системы для многоядерных компьютеров.
Основные задачи исследования:
- Аналитический анализ описания модели динамической системы.
- Разработка структурной схемы параллельной модели динамической системы и повышение эффективности обмена информацией в этой модели.
- Реализация монитора управления многочастотной динамической системой.
- Исследование временных характеристик вычислений и обменов стандартными средствами программирования.
- Разработка программного планировщика и монитора управления многочастотной динамической системой.
- Исследование модели и специального программного обеспечения планировщика и расширение класса решаемых задач.
Объект исследования: сложная динамическая система на многоядерной SMP-платформе.
Предмет исследования: разработка модели и специального программного обеспечения планировщика, расширение класса решаемых задач.
Научная новизна состоит в синтезе и исследовании циклического временного расписания для динамических систем.
В рамках магистерской работы планируется получение актуальных научных результатов по следующим направлениям:
- Повышение эффективности обмена информацией в параллельной модели динамической системы.
- Методика распараллеливания данных в потоках с учетом не больших объемов.
- Расширение класса решаемых задач на SMP-платформе и методика создания программ для такого типа задач.
Для экспериментальной оценки полученных теоретических результатов и формирования фундамента последующих исследований, в качестве практических результатов планируется разработка и реализация специального программного обеспечения планировщика и монитора выполнения SMP системы для многоядерных компьютеров
3. Обзор исследований и разработок
Поскольку вопросы исследования параллельной модели динамической системы и повышения эффективности обмена информацией в этой модели являются важной частью решения сложных вычислительных задач с помощью параллельного моделирования, то проблемы их оптимизации, организации, повышение класса решаемых такими системами были широко исследованы как зарубежными, так и отечественными специалистами.
3.1 Обзор международных источников
Вопросами исследования многоядерной SMP платформы занимались множество западных ученых.
Одна из ведущих групп исследователей на территории США состоит из В.Ванга, П. Мишра и С. Ранка. Они опубликовали статью «Динамическая реконфигурация кэша и разметка с целью оптимизации энергопотребления в многоядерных системах реального времени» [7] посвященную многоядерным архитектурам, особенно мультипроцессорам. В данной статье разработан подход, позволяющий с помощью управляемого разбиения общей кэш-памяти уменьшить количество внутренних помех в кэше, так что и производительность, и энергоэффективность улучшаются.
Ведущая европейская группа испанских исследователей опубликовала статью «Анализ локальности данных SPECfp95».[8] Авторы этой статьи И. Санчез и А. Гонсалез. Эта статья представляет собой подробный анализ локальности, основанный на наборе тестов SPECfp95, а также отображает основные типы информации, которые могут потребоваться пользователю в целях оптимизации программы.
3.2 Обзор национальных и локальных источников
Особенности исследований динамических систем широко рассматриваются в ведущих технических ВУЗах Украины. В их числе и Донецкий национальный технический университет.
Планирование и синхронизация процессов интенсивно изучается д.т.н., профессором Святным Владимиром Андреевичем и его аспирантами. Активно этим вопросом занимается аспирант ДонНТУ Иванов Юрий Александрович. Основные его аспекты он раскрыл в своей магистерской работе [6].
Также среди преподавателей ДонНТУ работой с численными методами и решением ОДУ для параллельного моделирования занимается доцент Дмитриева Ольга Анатольевна [10], опубликовавшая более 30 статей в журналах «Математическое моделирование», «Электронное моделирование», сборниках факультета КНТ и др. Для работы над моим дипломным проектом одним из основных пособий для решения дифференциальных уравнений считаю книгу "Чисельні методи в інформатиці" Фельдман Л.П., Дмитриева О.А.
4. Исследование кольцевого теста на SMP системе [5]
Анализ применимости проектных технических решений заключается в проведении моделирования на разработанной системе и оценке либо сравнении результатов с другими моделями и реальными показателями работы. Однако, учитывая разнообразие проектов, разрабатываемых для них моделей и областей применения, очень сложно оценить работоспособность модели с помощью универсального теста. Возмущения в системах полунатурного моделирования принято реализовывать генератором синусоидальных сигналов с помощью модели гармонического осциллятора. Одновременно с этим временное профилирование полунатурных моделей, а также определение предельных характеристик самих архитектурных решений вычислительных систем эффективно выполнить с помощью кольцевого теста [2].
SMP — симметричное мультипроцессирование. Существует два вида архитектур реализации такого вида систем. Для нашего исследования была выбрана архитектура многопроцессорных компьютеров (рисунок 1), в которой два или более одинаковых процессоров подключаются к общей памяти. Характерной чертой таких систем является то, что все процессоры имеют прямой и равноправный доступ к любой точке общей памяти. Первая возникшая проблема — большое число конфликтов при обращении к общей шине. Поэтому существуют альтернативы этой системы — это MPP системы и системы с архитектурой NUMA (где виртуальная память делится на раздельные блоки).
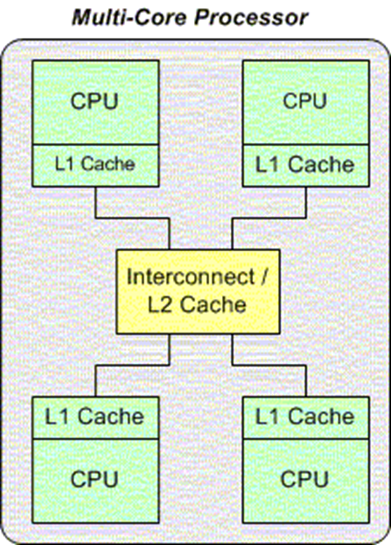
Рисунок 1 — Реализация SMP-системы на архитектуре многопроцессорных компьютеров
Гармонический осциллятор — это система, которая при смещении из положения равновесия испытывает действие возвращающей силы, пропорциональной смещению, согласно закону Гука [3] : F = -k*x, где k – коэффициент жесткости пружины. Механическими примерами гармонического осциллятора являются математический маятник (с малыми углами отклонения), груз на пружине, торсионный маятник и акустические системы.
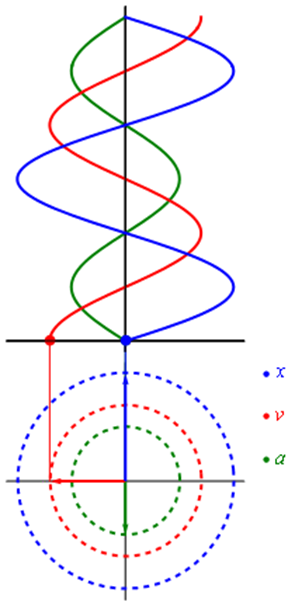
Рисунок 2 — Гармонический осциллятор
Уравнение движение груза с координатой x, согласно второму закону Ньютона может быть записано следующим образом:
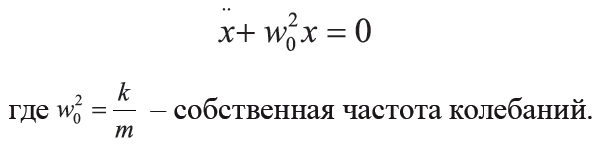
Для создания программной модели ГО выполняется численное интегрирование системы дифференциальных уравнений, полученных понижением порядка уравнения гармонического осциллятора:
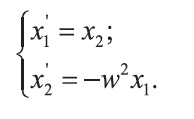
Многопоточная реализация модели гармонического осциллятора
Существуют такие основные группы численных методов решения систем дифференциальных уравнений: численные методы Рунге–Кутты, численные методы Адамса–Бошфорта и численные методы Эйлера. Нами был выбран численный метод Эйлера формула трапеций, из-за простоты программной реализации в виде итерационного цикла. Для нас не является критичной погрешность данного метода.
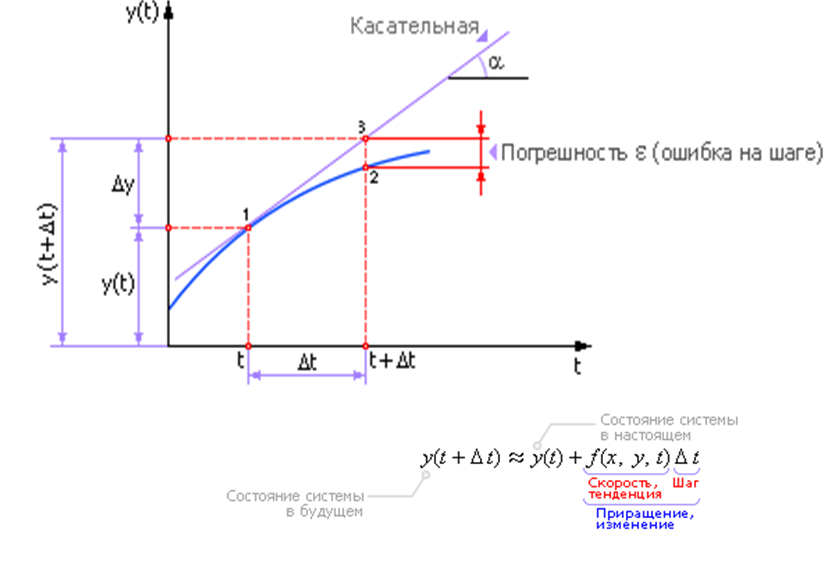
Рисунок 3 — Численный метод Эйлера формула трапеций
Для исследования кольцевого теста в одной модели были использованы два гармонических осциллятора с отличающимися собственными частотами. Была разработана модель, в которую вошли две системы уравнений, для решения которых был использован метод Эйлера. Программная реализация модели выполнена средствами MSVS C++. При этом использованы механизмы работы с потоками WinAPI. Каждый из осцилляторов реализован как отдельный поток, запуск которых выполняется в бесконечном цикле реального времени.
Экспериментальным путем получено максимальное значение времени соответствующее задержке переключения контекста потока и равное используемому шагу численного метода, при котором результаты моделирования просчитываются верно. Определяется логарифмически декремент затухания. Для подтверждения правильности работы системы выполнялось сравнение результатов моделирования разработанной программы с аналогичной моделью построенной средствами MATLAB.
SMP реализация модели гармонического осциллятора
При исследовании SMP-систем[4], в качестве инструмента использовалась система с четырехядерным процессором Intel i7 3770-K. Для реализации многоядерной модели использовались функции API для работы с потоками. Дополнительные вычислительные ресурсы при этом не приводят к линейному увеличению быстродействия для конкретной задачи.
Параметры функции CreateThread():LpThreadAttributes — является указателем на структуру LPSECURITY_ATTRIBUTES. Для присвоения атрибутов защиты по умолчанию, передавайте в этом параметре NULL. DwStackSize — параметр определяет размер стека, выделяемый для потока из общего адресного пространства процесса. При передаче 0 — размер устанавливается в значение по умолчанию. LpStartAddress — указатель на адрес входной функции потока. LpParameter — параметр, который будет передан внутрь функции потока. DwCreationFlags — принимает одно из двух значений: 0 — исполнение начинается немедленно, или CREATE_SUSPENDED — исполнение приостанавливается до последующих указаний. LpThreadId — Адрес переменной типа DWORD в который функция возвращает идентификатор, приписанный системой новому потоку. Завершать поток достаточно закрытием хэндла, созданного для данного потока, используя функцию CloseHandle().
Для привязки потока к конкретному ядру процессора используется функция SetThreadAffinityMask(). Параметры этой функции: дескриптор потока и маска родственности потока. Маской родственности потока является битовый вектор, каждый бит которого обозначает процессоры, на которых потоку разрешается запуститься. Маска родственности потока должна быть собственным подмножеством маски родственности процесса для процесса содержащего поток. Потоку позволяется запуститься только на процессорах, на которых запущен его процесс.

Рисунок 4 — Результат анализа Intel VTune Performance Analyzer 9.1
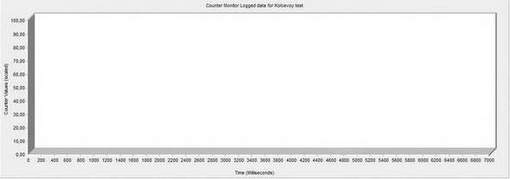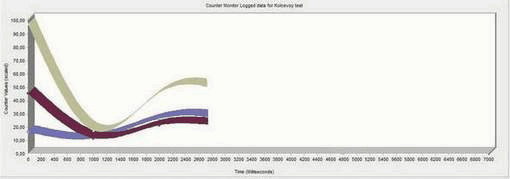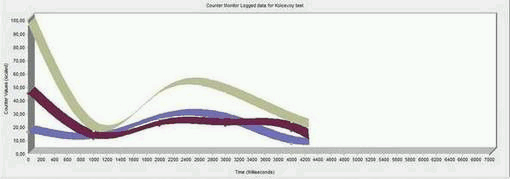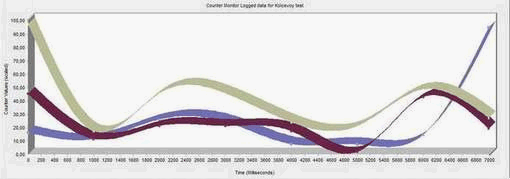
Рисунок 5 — График числа обращений к кэшу
(анимация: 6 кадров, 7 циклов повторения, 144 килобайт)

Рисунок 6 — Пояснения к графику
Временные задержки определяется способом доступа к виртуальной памяти через кэши L1 и L2 процессора. Причем способ реализации кэша накладывает ограничения на структуры данных обмениваемых (запись, чтение) между ядрами.
В результате проведения исследования разработанной модели мы столкнулись с проблемой общей виртуальной памяти (стандартная проблема SMP–систем), что приводило к выводу начальных («непосчитанных») значений, а уже затем правильных дальнейших в зависимости от того какое из ядер первым получало доступ для копирования значений из кэша в виртуальную память. Решением данной проблемы могла бы стать синхронизация потоков, но это решение не подходит, если для нас критично время выполнения этой модели. Ведутся дальнейшие исследования в данной сфере.
Выводы
Проведенные исследования показали работоспособность программных многопоточных моделей гармонического осциллятора и могут быть использованы для временного профилирования пользовательских приложений и получений сравнительных характеристик вычислительных систем.
Магистерская работа посвящена актуальной научной задаче синтез и исследование циклических временных расписаний для динамических систем. В рамках проведенных исследований выполнено:
- Анализ математического описания модели динамической системы.
- Аналитическое решение системы дифференциальных уравнений.
- Проведен ряд экспериментов по исследованию работы кольцевого теста.
- Рассмотрены и исследованы временные характеристики вычислений и обменов стандартными средствами программирования.
Дальнейшие исследования направлены на следующие аспекты:
- Реализация монитора управления многочастотной динамической системой.
- Разработка программного планировщика и монитора управления многочастотной динамической системой
- Исследование модели и специального программного обеспечения планировщика и расширение класса решаемых задач.
- Повышение эффективности обмена информацией в SMP системе для исследования модели динамики электроподвижного состава.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2013 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Букатов А.А., Дацюк В.Н., Жегуло А.И. "Программирование многопроцессорных вычислительных систем", Ростов-на-Дону, 2003 г.
- Беки Дж.А. Теория и применения гибридных вычислительных систем / Беки Дж.А., Карплюс У.Дж // Перевод с англ. под ред. д.т.н., проф. Б.Я. Когана – М.: Мир, – 1970. – 483 с.
- Материалы из свободной энциклопедии "Википедия" — Гармонический осциллятор [Электронный ресурс]. – Рeжим дoступa к ресурсу: http://ru.wikipedia.org/wiki/Гармонический_осциллятор.
- Эхтер Ш. Многоядерное программирование / Ш. Эхтер, Дж. Робертс – СПб.: Питер, 2010. – 316 с.
- Первусяк А.И., Иванов Ю.А. "Исследование кольцевого теста на SMP системе".
- Магистерская работа Ю.А. Иванова "Исследование и разработка алгоритмов планирования процессов реального времени моделирования сложных динамических систем".
- Ванг В., Мишр П. и Ранк С. "Динамическая реконфигурация кэша и разметка с целью оптимизации энергопотребления в многоядерных системах реального времени".
- Санчез И., Гонсалез А. "Анализ локальности данных SPECfp95".
- Иванов А.Ю. "Построение службы синхронизации процессов".
- Информация о преподавателе Дмитриевой О.А.[электронный ресурс] / Сайт кафедры прикладной математики и информатики ДонНТУ, - http://pmi.donntu.ru/text/prepod/dmitrieva.html
