
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования
- 3. Научная новизна
- 4. Обзор исследований и разработок
- 4.1 Нейронные сети
- 4.2 Использование нейронных сетей и генетических алгоритмов
- 4.3 Генетические алгоритмы
- 5. Разработка алгоритма отбора оптимальной регрессионной модели с помощью метода группового учета аргументов
- Выводы
- Список источников
Введение
В настоящее время в медицине особое значение приобретает направление, связанное со снижением перинатальной смертности. Перинатальным периодом называется период, начинающийся с 28-й недели внутриутробного развития, когда масса плода достигает 1000 г и более, и продолжающийся до 8-го дня (168 ч) жизни новорожденного. При всей своей относительной непродолжительности перинатальный период является важнейшим этапом в жизни человека, так как смертность в этот период такая же, как смертность в возрасте человека от 8 дней и до 40 лет, а опасность тяжелых неврологических нарушений в этот период даже превышает таковую в последующие десятилетия жизни человека.
Наиболее действенный путь в снижении смертей лежит в разработке программ прогнозирования. Сложность их разработки заключается в необходимости научного анализа большого количества клинических и лабораторных показателей, которые находятся в сложной зависимости друг от друга и не всегда поддаются количественной оценке. Поэтому не менее важной является задача определения факторов риска, так как анализ всей доступной информации, как правило, вызывает существенные затруднения при разработке и реализации методов прогнозирования при создании аналитической системы.
1. Актуальность темы
Последние десятилетия XX и начало XXI века ознаменовались четкой тенденцией снижения основных показателей, как в демографии, так и в родовспоможении практически во всем мире. На фоне снижения интенсивности прироста населения увеличиваются показатели материнской, перинатальной, младенческой и детской смертности.
Возможность прогнозирования перинатального риска накануне родов позволит своевременно снизить материнскую заболеваемость и смертность новорожденных, а также оказать адекватную терапию с привлечением высококвалифицированных акушеров-гинекологов.
2. Цель и задачи исследования
Целью данной работы является получить полезную информацию из набора параметров (факторов риска) и разработать аналитическую систему для прогнозирования перинатального риска.
Для разработки аналитической системы прогнозирования перинатального риска необходимо решить следующие задачи:
- Разработка структуры системы.
- Разработка методов прогнозирования на основе МГУА.
- Реализация методов прогнозирования на основе МГУА.
Объект исследования: процесс проектирования и разработки методов извлечения знаний для медицинских аналитических систем.
Предмет исследования: методы разработки извлечения знаний для аналитической системы прогнозирования перинатального риска.
3. Научная новизна
Научная новизна заключается в применении метода группового учета аргументов для отбора оптимальной регрессионной модели, а также решается сопутствующая задача отбора факторов риска, влияющих на перинатальный риск у женщин.
4. Обзор исследований и разработок
4.1 Нейронные сети
Нейронные сети можно рассматривать как современные вычислительные системы, которые преобразуют информацию по образу процессов, происходящих в мозгу человека. Обрабатываемая информация имеет численный характер, что позволяет использовать нейронную сеть, например, в качестве модели объекта с совершенно неизвестными характеристиками. Другие типовые приложения нейронных сетей охватывают задачи распознавания, классификации, анализа и сжатия образов.
В самом упрощенном виде нейронную сеть можно рассматривать как способ моделирования в технических системах принципов организации и механизмов функционирования головного мозга человека. Согласно современным представлениям, кора головного мозга человека представляет собой множество взаимосвязанных простейших ячеек – нейронов, количество которых оценивается числом порядка 1010. Технические системы, в которых предпринимается попытка воспроизвести, пусть и в ограниченных масштабах, подобную структуру (аппаратно или программно), получили наименование нейронные сети.
Данный метод сложно реализуем, так как практически тяжело отследить правильность работы данного метода на этапе отладки. А так же невозможность интерпретации промежуточных данных и сложность разъяснения результатов работы сети делает данный метод крайне неудобным для применения в данном случае.
4.2 Использование нейронных сетей и генетических алгоритмов
Отбор информативных параметров выполняется с помощью нейронных сетей [1-2] и генетических алгоритмов [3-4]. Такой подход (совместное использование) позволит не просто выполнить отбор факторов риска, а выбрать информативный набор данных, сохранив взаимосвязанные переменные.
Для реализации такого подхода сначала необходимо разработать НС для определения риска развития акушерских кровотечений. Для практики самым важным является определение риска потери крови при родах более чем 0,5% от массы тела, с целью принятия соответствующих мер. В этом случае, по сути, выполняется классификация на два класса: патологическое кровотечение и допустимое. Для реализации поставленной задачи в такой форме целесообразно использовать многослойную НС прямого распространения. Такой тип НС показывает хорошие результаты при обучении с учителем, а так как имеется обучающая выборка с реальными медицинскими данными, то выберем многослойную НС для классификации на патологическую и обычную потерю крови при родах. Таким образом, на первом этапе необходимо выбрать архитектуру нейронной сети и обучить ее. Учитывая то, что в дальнейшем (при отборе факторов риска) на каждом шаге выполнения ГА будет происходить обучение НС, целесообразно выбирать архитектуру сети с минимальной сложностью, что позволит уменьшить время выполнения программы. Под сложностью сети будем предполагать вычислительную сложность алгоритма обучения НС. Под вычислительной сложностью алгоритма обучения будем понимать количество операций за один шаг обучения. Известно, что для алгоритма обратного распространения количество операций связано линейной зависимостью с синаптическими весами (включая пороги) [5]. Т. е. вычислительную сложность определяет число скрытых слоев и число нейронов на каждом из них. В результате была выбрана архитектура НС, представленная на рис. 1. Количество входов обусловлено максимальным количеством факторов риска (после кодирования их получили 99). Выбранные активационные функции – гиперболический тангенс и линейная функция.
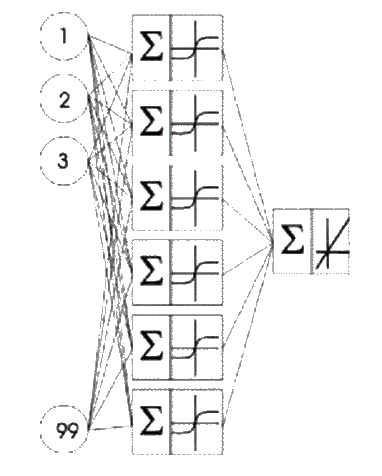
Рисунок 1 – Архитектура нейронной сети
После того как определена и успешно обучена НС, выполняется ГА, который подает различные комбинации факторов риска на входы НС и затем выполняется попытка обучить сеть при такой комбинации отобранных факторов риска. Принцип реализации кодирования хромосомы представлен на рис. 2. Каждая хромосома представляет собой последовательность определенного количества битов (определяется максимальным количеством факторов риска). Значение каждого бита равно 1, если фактор с соответствующим номером присутствует в данном наборе, и 0, если этот фактор отсутствует.
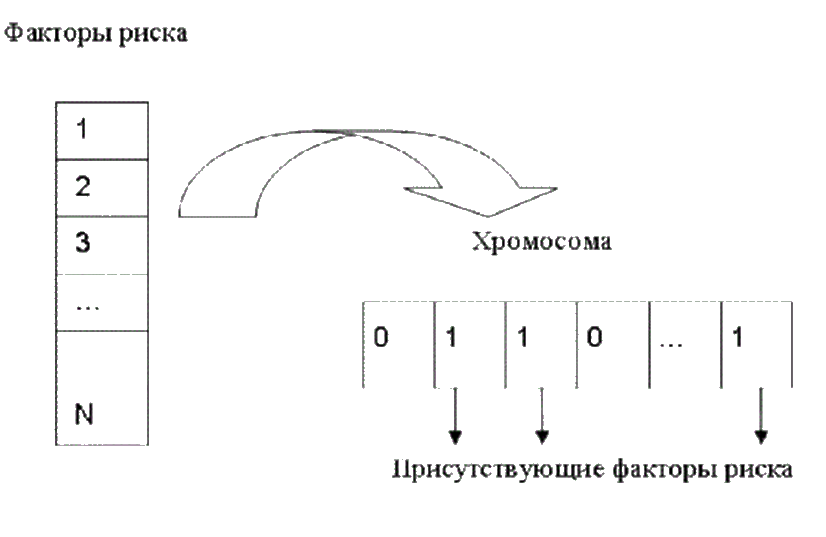
Рисунок 2 – Кодирование хромосомы
В предлагаемом подходе для выделения признаков использован генетический алгоритм, который имеет модифицированную схему реализации применительно к задаче многокритериальной оптимизации. В то время как большинство подобных методов, используемых для решения таких задач, использует единый, составной оптимизируемый критерий [1]. Решением задачи в данном случае является несколько недоминируемых подмножеств признаков. Разработана фитнесс-функция (1), которая предполагает поиск решения, являющегося оптимальным согласно двум критериям – учитывается точность классификации и количество факторов риска. К тому же данная фитнесс-функция позволяет задавать желаемое соотношение точности классификации и количества факторов риска.
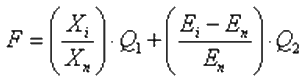 , , |
(1) |
где Xi – количество присутствующих факторов риска в i-й хромосоме, Xn – максимальное количество факторов риска, Ei – ошибка обучения НС для i-й хромосомы, En – ошибка обучения НС при использовании максимального количества факторов, Q1 и Q2 – коэффициенты, с помощью которых регулируется соотношение между точностью классификации и числом факторов риска. Рекомендуется выбирать диапазон значений (2), и придерживаться условия (3).
| |
(2) |
| |
(3) |
После этапа подготовки данных получили обучающий массив размером 99 х 100, где 99 входных параметров и 100 обучающих примеров. Данная выборка разделена на две – по 50 примеров в каждой. По первой выборке проводилось обучение нейронной сети и отбор признаков с помощью генетических алгоритмов. В результате количество факторов уменьшилось практически в два раза. Затем, на второй выборке успешно протестирована нейронная сеть, с использованием только выделенных факторов.
4.3 Генетические алгоритмы
Генетические алгоритмы (ГА) используют принципы и терминологию, заимствованные у биологической науки – генетики. В ГА каждая особь представляет потенциальное решение некоторой проблемы. В классическом ГА особь кодируется строкой двоичных символов – хромосомой, каждый бит которой называется геном. Множество особей – потенциальных решений составляет популяцию. Поиск (суб) оптимального решения проблемы выполняется в процессе эволюции популяции - последовательного преобразования одного конечного множества решений в другое с помощью генетических операторов репродукции, кроссинговера и мутации.
ГА берет множество параметров оптимизационной проблемы и кодирует их последовательностями конечной длины в некотором конечном алфавите (в простейшем случае двоичный алфавит «0» и «1»).
Предварительно простой ГА случайным образом генерирует начальную популяцию стрингов (хромосом). Затем алгоритм генерирует следующее поколение (популяцию), с помощью трех основных генетических операторов:
- Оператор репродукции (ОР).
- Оператор кроссинговера (ОК).
- Оператор мутации (ОМ).
Генетические операторы являются математической формализацией приведенных выше трех основополагающих принципов Дарвина, Менделя и де Вре естественной эволюции.
ГА работает до тех пор, пока не будет выполнено заданное количество поколений (итераций) процесса эволюции или на некоторой генерации будет получено заданное качество или вследствие преждевременной сходимости при попадании в некоторый локальный оптимум.
Впервые подобный алгоритм был предложен в 1975 году Джоном Холландом (John Holland) в Мичиганском университете. Он получил название «репродуктивный план Холланда» и лег в основу практически всех вариантов генетических алгоритмов [6]. Стандартный ГА [4] предполагает следующую последовательность, (рис.3).

Рисунок 3 – Простой генетический алгоритм
В каждом поколении множество искусственных особей создается с использованием старых и добавлением новых с хорошими свойствами. Генетические алгоритмы – не просто случайный поиск, они эффективно используют информацию, накопленную в процессе эволюции.
В отличие от других методов оптимизации ГА оптимизируют различные области пространства решений одновременно и более приспособлены к нахождению новых областей с лучшими значениями целевой функции за счет объединения квазиоптимальных решений из разных популяций.
5. Разработка алгоритма отбора оптимальной регрессионной модели с помощью метода группового учета аргументов
В большинстве случаев, в медицинских задачах, результат прогнозирования зависит от большого количества неодинаковых по значимости факторов, которые к тому же могут быть взаимосвязаны. Этот факт значительно усложняет этап отбора данных, исключая возможность использовать большую часть известных методов.
Однако выделение факторов риска является не единственной задачей, так же необходимо оценить роль каждого из них. Из этого следует, что значимость каждого фактора на риск развития различных акушерских осложнений будет различна [1]. Тем не менее, отбор факторов риска является одним из самых важных этапов построения прогнозирующей модели и в значительной степени определяет ее качество. Таким образом, при построении оптимальной модели выполним и отбор факторов перинатального риска, из параметров первоначально предложенных врачами, при этом будем учитывать взаимосвязанные между собой переменные.
Полный перебор регрессионных моделей, даже в пределах заданной опорной функции, при достаточно большом наборе входных параметров на практике реализовать не представляется возможным. Для достаточно сложных задач моделирования (например, большой набор обучающих данных) применяются многорядные алгоритмы метода группового учета аргументов (МГУА) [7]. Многорядный алгоритм МГУА исключает из перебора некоторые модели благодаря наличию порогов.
Предварительно в многорядном (пороговом) алгоритме МГУА на вход подается некоторый вектор входных переменных x = x1, x2,..., xn. На первом ряду селекции образуются «частные описания» (4) – (6), объединяющие входные переменные по две:
| |
(4) |
| |
(5) |
...
| |
(6) |
Из них выбирается некоторое число моделей наиболее удовлетворяющих внешнему критерию селекции. В нашем случае в качестве такого критерия будет среднеквадратичная ошибка (7) на проверочных данных.
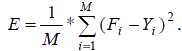 |
(7) |
где М – количество обучающих примеров, F – полученный результат, Y – действительный результат.
На втором ряду образуются «частные описания» второго ряда:
| |
(8) |
...
| |
(9) |
...
| |
(10) |
Из них также выбирается некоторое количество наилучших для использования в следующем, третьем ряду и т.д. Для каждого ряда находится наилучшая (по критерию селекции) модель (рис. 4). Ряды селекции наращиваются, пока оценка критерия уменьшается («правило останова»). На последнем ряду лучшая модель будет оптимальной. Коэффициенты в регрессионных моделях рассчитываются методом наименьших квадратов (МНК).

Рисунок 4 – Многорядный МГУА
(анимация: 6 кадров, 5 циклов повторения, 32,1 килобайт)
Выводы
На основе поставленных целей и задач была рассмотрена актуальная задача отбора оптимальной регрессионной модели, для прогнозирования перинатального риска включая задачу отбора факторов риска. В дальнейшем планируется реализовать рассмотренный математический аппарат и протестировать на реальных медицинских данных, предоставленных сотрудниками центра материнства и детства. Также планируется разработка и внедрение системы прогнозирования перинатального риска.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2013 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Т.А. Васяева Анализ методов отбора факторов риска развития патологий в акушерстве и гинекологии / Т. А. Васяева, Д.Е. Иванов, И.В. Соков, А.С. Сокова // Збірка матеріалів ІІ Всеукраїнської науково-технічної конферен.
- Т.А. Васяева Отбор факторов риска потери крови при родах / Т.А. Васяева, Д.Е. Иванов, И.В. Соков. // Інтелектуальні системи прийняття рішень і проблеми обчислювального інтелекту: Матеріали міжнародної наукової конференції. – Херсон: ХНТУ, 2011. – № 1. – 472 с.
- Д. Рутковская Нейронные сети, генетические алгоритмы и нечеткие системы / Д. Рутковская М. Пилиньский, Л. Рутковский. – М.: 2004. – 452 c.
- Ю.О. Скобцов Основи еволюційних обчислень / Ю. О. Скобцов. – Донецьк: ДонНТУ, 2009. – 316 с.
- Саймон Хайкин Нейронные сети: полный курс, 2-е издание. : Пер. с англ. – М. : Издательский дом «Вильямс», 2006. – 1104 с.
- Г.К. Вороновский Генетические алгоритмы, искусственные нейронные сети и проблемы виртуальной реальности / Г.К. Вороновский, К.В. Махотило, С.Н. Петрашев, С.А. Сергеев // заказное. – Х.: ОСНОВА, 1997. – 112 с.
- Радзинский В.Е. Акушерский риск. Максимум информации минимум опасности для матери и младенца. / В.Е. Радзинский, С.А. Князев, И.Н. Костин. - Изд: Эксмо.. - 2009 г. - С. 285
- Ивахненко А.Г. Самоорганизация прогнозирующих моделей / Ивахненко А.Г., Мюллер И.А. - К: Техника, 1985.. - 223 с.
- МГУА [Электронный ресурс]. – Режим доступа: http://www.gmdh.net/gmdh.htm.
- Метод наименьших квадратов [Электронный ресурс]. – Режим доступа: http://users.kpi.kharkov.ua/fmp/biblio/book1/2-3.html.