
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования
- 3. Предполагаемая научная новизна
- 4. Обзор существующих алгоритмов построения взвешенных выборок
- 4.1 Алгоритм STOLP
- 4.2 Алгоритм FRiS-STOLP
- 4.3 Алгоритм NNDE
- 5. Метод построения выборки w-объектов
- Выводы
- Список источников
- Важное замечание
Введение
Системы распознавания находят все большую область применения в повседневной жизни (электронная почта, библиотеки в интернет, системы управления голосом). Системы распознавания есть в медицине, в антивирусной защите компьютера, в системах видеонаблюдения.
Признаки распознаваемых объектов постоянно меняются, что усложняет распознавание и правильную классификацию. Поэтому встает вопрос о разработке таких систем, которые при минимальных изменениях могли бы распознавать объекты с такой же высокой достоверностью как и прежде, то есть адаптироваться к новым условиям. Такие системы принято называть адаптивными системами распознавания [11].
Способность к самообучению в адаптивных системах обусловлена тем, что все обнаруженные изменения в состоянии уже изученных объектов добавляются в обучающую выборку. Перед тем как добавить новый признак, нужно определить целесообразность его добавления. С каждым новым добавленным элементом так же возникает необходимость в корректировке существующих решающих правил классификации, а в случае глобальных отличий – еще и потребность в создании нового словаря признаков [1].
1. Актуальность темы
Большинство современных прикладных задач, решаемых путем построения систем распознавания, характеризуется большим объемом исходных данных и возможностью добавления новых данных уже в процессе работы систем. Именно поэтому основными требованиями, предъявляемыми к современным системам распознавания, являются адаптивность (возможность системы в процессе работы изменять свои характеристики, а для обучающихся систем распознавания – корректировать решающие правила классификации, при изменении окружающей среды), работа в реальном времени (возможность формирования решений о классификации за ограниченное время) и высокая эффективность классификации для линейно разделимых и пересекающихся в признаковом пространстве классов [5].
Добавление новых объектов, являющееся для большинства прикладных задач достаточно интенсивным, приводит к существенному увеличению размера обучающей выборки, что, в свою очередь, приводит к:
- увеличению времени корректировки решающих правил (особенно, если используемый метод обучения требует построения нового решающего правила, а не его частичной корректировки);
- ухудшению качества получаемых решений из-за проблемы переобучения на выборках большого объема.
Эти особенности адаптивных обучающихся систем распознавания делают необходимой предобработку обучающих выборок путем сокращения их размера.
2. Цель и задачи исследования
Целью выпускной работы магистра является разработка алгоритма построения взвешенных темпоральных обучающих выборок в адаптивных системах распознавания. В процессе работы необходимо решить следующие задачи:
- исследовать существующие алгоритмы построения взвешенных обучающих выборок;
- исследовать методы применения взвешенных обучающих выборок в адаптивных системах распознавания;
- разработать алгоритм построения взвешенных темпоральных обучающих выборок в адаптивных системах распознавания;
- разработать прототип программной системы тестирования алгоритмов построения взвешенных темпоральных обучающих выборок в адаптивных системах распознавания;
- выполнить сравнительный анализ предложенного алгоритма и известных алгоритмов решения данной задачи.
3. Предполагаемая научная новизна
Научной новизной данной работы является разработка метода построения взвешенных темпоральных обучающих выборок в адаптивных системах распознавания. Поскольку рост размера обучающей выборки приводит к росту времени обучения и ухудшению его качества, предполагается, что на основе взвешенных темпоральных выборок может быть построен эффективный алгоритм выбора некоторого подмножества актуальных объектов выборки и удалении остальных.
4. Обзор существующих алгоритмов построения взвешенных выборок
4.1 Алгоритм STOLP
Пусть дана обучающая выборка:
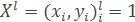
где xi – объекты, yi=y*(xi) – классы, которым принадлежат эти объекты.
Кроме того, задана метрика ρX*X→R, такая, что выполняется гипотеза компактности. При классификации объектов метрическим классификатором
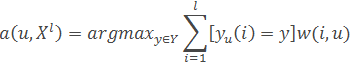
например, методом ближайших соседей необходимо вычислять расстояния от классифицируемого объекта до всех объектов обучающей выборки. Время, затрачиваемое на это для каждого классифицируемого объекта, пропорционально размеру обучающей выборки. Кроме того, оказывается необходимым хранить большой объем данных [8].
Но не все объекты обучающей выборки равноценны. Среди них есть наиболее типичные представители классов, то есть эталоны; неинформативные объекты, при удалении которых из обучающей выборки качество классификации не изменится; выбросы, или шумовые объекты — объекты, находящиеся в гуще «чужого» класса, только ухудшающие качество классификации [7].
Поэтому необходимо уменьшить объем обучающей выборки, оставив в ней только эталонные объекты для каждого класса.
Эталоны – это такое подмножество выборки Xl, что все объекты Xl (или их большая часть) классифицируются правильно при использовании в качестве обучающей выборки множества эталонов.
Эталонами i -го класса при классификации методом ближайшего соседа может служить такое подмножество объектов Xl этого класса, что расстояние от любого принадлежащего ему объекта из выборки до ближайшего «своего» эталона меньше, чем до ближайшего «чужого» эталона.
Простой перебор для отбора эталонов не эффективен, так как число способов выбора по t эталонов для каждого класса (число классов k) составляет П(j=1)kCtmj.
Величина риска (W ) — величина, характеризующая степень риска для объекта быть классифицированным не в тот класс, которому он принадлежит.
При использовании метода ближайшего соседа можно считать
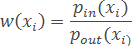
где pin – расстояние от объекта xi до ближайшего к нему объекта (или эталона) из «своего» класса; pout – до ближайшего объекта (или эталона) «чужого» класса.
При использовании любого метрического метода можно положить

где M(xi ,μ)=Гyi - max(y∈Y\yi) Гy(xi) – отступ на объекте xi при обучающей выборке μ (μ – множество эталонов).
Кроме того, в зависимости от используемого метода классификации можно подобрать и другие оценки величины риска. Главное, чтобы они принимали большие значения на объектах-выбросах, меньшие – на объектах, находящихся на границе класса, и еще меньшие – на объектах, находящихся в глубине своего класса [4].
На вход алгоритма подается выборка Xl, допустимая доля ошибок l0, порог отсечения выбросов δ, алгоритм классификации и формула для вычисления величины риска W.
Вначале нужно отбросить выбросы (объекты Xl, с W >δ), затем сформировать начальное приближение μ – из объектов выборки Xl, выбрать по одному объекту каждого класса, обладающему среди объектов данного класса максимальной величиной риска либо минимальной величиной риска.
Далее наращивается множество эталонов (пока число объектов выборки Xl, распознаваемых неправильно, не станет меньше l0,). Далее классифицируют объекты Xl, используя в качестве обучающей выборки μ, пересчитывают величины риска для всех объектов Xl \μ, с учетом изменения обучающей выборки. Среди объектов каждого класса, распознанных неправильно, выбирают объекты с максимальной величиной риска и добавляют их к μ.
В результате множество эталонов μ∈Xl, для каждого класса представляет собой некоторый набор объектов, находящихся на границе класса, и, если в качестве начального приближения выбирались объекты с минимальной величиной риска, один объект, находящийся в центре класса.
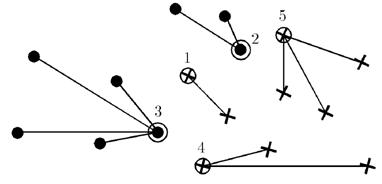
Рисунок 1 – Результат работы алгоритма STOLP
4.2 Алгоритм FRiS-STOLP
Алгоритм FRiS-STOLP – алгоритм отбора эталонных объектов для метрического классификатора на основе FRiS-функции. От классического алгоритма STOLP его отличает использование вспомогательных функций [10].
Функция NN(u,U) возвращает ближайший к u объект из множества U.
Функция FindEtalon (xy,μ) исходя из набора уже имеющихся эталонов &;mu и набора Xy элементов класса Y, возвращает новый эталон для класса Y по следующему алгоритму:
- Для каждого объекта x∈Xy вычисляются две характеристики – «обороноспособность» и «толерантность» (насколько объект в в роли эталона одного класса не мешает эталонам других классов) объекта:
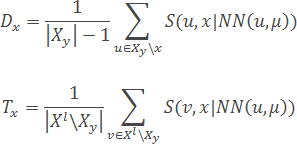
- На основании полученных характеристик вычисляется «эффективность» объекта x:
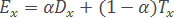
- Функция FindEtalon возвращает объект x∈Xl с максимальной эффективностью Ex:
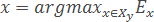
Параметр α∈[0,1] количественно задаёт относительную «важность» характеристик объектов («обороноспособности» и «толерантности»). Может быть выбран, исходя из специфики конкретной задачи.
4.3 Алгоритм NNDE
Метод ближайших соседей – простейший метрический классификатор, основанный на оценивании сходства объектов.
Классифицируемый объект относится к тому классу, которому принадлежат ближайшие к нему объекты обучающей выборки. В задачах с двумя классами число соседей берут нечётным, чтобы не возникало ситуаций неоднозначности, когда одинаковое число соседей принадлежат разным классам. В задачах с числом классов 3 и более нечётность уже не помогает, и ситуации неоднозначности всё равно могут возникать. Тогда i -му соседу приписывается вес w, как правило, убывающий с ростом ранга соседа i. Объект относится к тому классу, который набирает больший суммарный вес среди ближайших соседей [9].
Пусть задана обучающая выборка пар «объект—ответ» Xm={(x1,y1),…,(xm,ym)}.
Пусть на множестве объектов задана функция расстояния ρ(x,x′). Эта функция должна быть достаточно адекватной моделью сходства объектов. Чем больше значение этой функции, тем менее схожими являются два объекта (x,x′).
Для произвольного объекта u расположим объекты обучающей выборки xi в порядке возрастания расстояний до u: ρ(u,x1;u)≤ρ(u,x2;u)≤...≤ρ(u,xm;u) где через xi;u обозначается тот объект обучающей выборки, который является i -м соседом объекта u. Аналогичное обозначение введём и для ответа на i -м соседе: yi;u. Таким образом, произвольный объект u порождает свою перенумерацию выборки.
В наиболее общем виде алгоритм ближайших соседей есть:
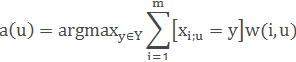
где w(i,u) — заданная весовая функция, которая оценивает степень важности i -го соседа для классификации объекта u. Естественно полагать, что эта функция неотрицательна и не возрастает по i.
По-разному задавая весовую функцию, можно получать различные варианты метода ближайших соседей.
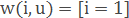 – простейший метод ближайшего соседа.
– простейший метод ближайшего соседа.
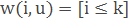 – метод k ближайших соседей.
– метод k ближайших соседей.
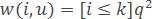 – метод k экспоненциально взвешенных ближайших соседей, где предполагается q<1.
– метод k экспоненциально взвешенных ближайших соседей, где предполагается q<1.
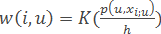 – метод парзеновского окна фиксированной ширины h.
– метод парзеновского окна фиксированной ширины h.
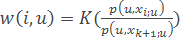 – метод парзеновского окна переменной ширины.
– метод парзеновского окна переменной ширины.
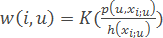 – метод потенциальных функций, в котором ширина окна h(xi) зависит не от классифицируемого объекта, а от обучающего объекта xi.
– метод потенциальных функций, в котором ширина окна h(xi) зависит не от классифицируемого объекта, а от обучающего объекта xi.
Здесь K(r) – заданная неотрицательная монотонно невозрастающая функция на [0,∞), ядро сглаживания.
5. Метод построения выборки w-объектов
Рассмотренные выше алгоритмы не позволяют учитывать плотность распределения объектов выборки в пространстве признаков и динамику изменения значений признаков добавляемых объектов. Используя такой подход, мы можем сократить ключевые элементы выборки.
Для избежания этого можно использовать метод сокращения выборки путем построения взвешенной выборки w-объектов [2], позволяющий выполнять сокращение обучающей выборки при неухудшении качества классификации. Также этот метод решает проблему добавления новых объектов в выборку при минимальном увеличении ее размера.
Основой метода построения взвешенной обучающей выборки w-объектов для сокращения выборок большого объема в адаптивных системах распознавания является выбор множеств близкорасположенных объектов исходной выборки и их замена одним взвешенным объектом новой выборки. Значения признаков каждого объекта новой выборки являются центрами масс значений признаков объектов исходной выборки, которые он заменяет. Введенный дополнительный параметр – вес определяется как количество объектов исходной выборки, которые были заменены одним объектом новой выборки. Предлагаемый метод ориентирован как на сокращение исходной обучающей выборки, так и на анализ необходимости корректировки выборки и быстрое выполнение такой корректировки при пополнении выборки в процессе работы системы.
В качестве исходных данных для предлагаемого метода возьмем некоторое множество объектов M, называемое обучающей выборкой. Каждый объект Xi из M описывается системой из n признаков, т.е. Xi={xi1,xi2,...,xin}, и представляется точкой в линейном пространстве признаков, т.е. Xi∈Rn. Для каждого объекта Xi известна его классификация yi∈[1,l], l – число классов системы.
Построение w-объекта состоит из трех последовательных этапов:
- Построение образующего множества Wf, содержащее некоторое количество d объектов исходной выборки, принадлежащих одному классу;
- Формирование вектора XiW={xi1,xi2,...,xin}, значений признаков w-объекта XiW и расчет его веса pi ;
- Корректировка исходной обучающей выборки – удаление объектов, включенных в образующее множество X=X \Wf.
Построение образующего множества Wf состоит в нахождении начальной точки Xf1 формирования w-объекта, определении конкурирующей точки Xf2 и выборе в образующем множестве Wf таких объектов исходной выборки, расстояние до каждого из которых от начальной точки меньше, чем расстояние от них до конкурирующей точки. В качестве начальной точки Xf1 формирования w-объекта используется объект исходной обучающей выборки, наиболее удаленный от всех объектов других классов. Конкурирующая точка Xf2 выбирается путем нахождения ближайшего к Xf1 объекта, не принадлежащего тому же классу, что и сам Xf1, т.е. yf1≠yf2.
Для случая двух классов выбор объектов {Xf1,Xf2,...,Xd} образующего множества Wf осуществляется по следующему правилу: Xi включается в Wf, если:
- Он принадлежит тому же классу, что и начальная точка Xf1;
- Расстояние от рассматриваемого объекта до начальной точки Xf1 меньше, чем до конкурирующей точки Xf2;
- Расстояние Ri,1 от рассматриваемого объекта до начальной точки меньше расстояния Ri,2 от рассматриваемого объекта до конкурирующей точки и меньше расстояния R1,2 между начальной и конкурирующей точками (для случая, когда классы состоят из нескольких отдельных областей признакового пространства).
Таким образом, образующее множество Wf формируется по правилу:
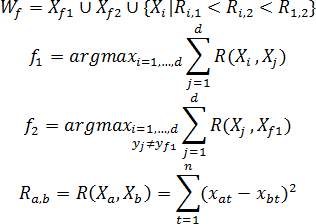
Значения признаков {xi1,xi2,...,xin} нового w-объекта XiW формируются по образующему множеству Wf и рассчитываются как координаты центра масс системы из pf=|Wf|материальных точек (примем, что объекты исходной обучающей выборки, являющиеся в признаковом пространстве материальными точками, имеют массу, равную 1), где |Wf| – мощность множества Wf, т.е.
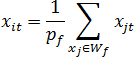
После формирования очередного w-объекта, все объекты образующего его множества удаляются из исходной обучающей выборки, т.е. X=X\Wf. Алгоритм заканчивает свою работу, когда в исходной обучающей выборке не останется ни одного объекта X∈∅ [3].

Рисунок 2 – Построение w-объекта (анимация: 5 кадров, 5 циклов повторения, 73,5 килобайт)
Принцип формирования образующих множеств, выбирающий близкорасположенные в пространстве признаков объекты, является эффективным способом деления выборки на группы. Введение весов позволяет не только сохранять информацию о количестве заменяемых объектов, но и характеризовать область, в которой эти объекты расположены. Исходя из этого представляется эффективным использование взвешенных обучающих выборок w-объектов для решения задачи построения взвешенных темпоральных выборок в адаптивных системах распознавания.
Выводы
В данной работе были исследованы различные алгоритмы сокращения выборок в адаптивных системах распознавания. Такие алгоритмы как STOLP, FRiS-STOLP просты в реализации, но дают большую погрешность при решении задач с большим объемом входных данных, алгоритм NNDE практически не приспособлен для решения таких задач [6]. По сравнению с этими алгоритмами, метод группового учета аргументов дает значительно лучший результат, ввиду его гибкости и возможности менять параметры алгоритма под конкретные условия задачи.
Исходя, из описанных алгоритмов сокращения адаптивных выборок был сделан вывод, что метод группового учета аргументов наиболее гибок, универсален и лучше всего подходит для модификации для решения задач построения взвешенных темпоральных выборок в адаптивных системах распознавания.
Список источников
- Александров А.Г. Оптимальные и адаптивные системы. / А.Г. Александров – М.: Высшая школа, 1989. – 263 с.
- Волченко Е.В. Расширение метода группового учета аргументов на взвешенные обучающие выборки w-объектов / Е.В. Волченко // Вісник Національного технічного університету "Харківський політехнічний інститут". Збірник наукових праць. Тематичний випуск: Інформатика i моделювання. – Харків: НТУ "ХПІ", 2010. – № 31. – С. 49 – 57.
- Волченко Е.В. Метод сокращения обучающих выборок GridDC / Е.В. Волченко, И.В. Дрозд // Штучний інтелект. –2010. – №4. – С. 185-189.
- Глушков В.М. Введение в кибернетику. / В.М. Глушков – К.: Изд-во АН УССР, 1964. – 324 с.
- Горбань А.Н. Обучение нейронных сетей. / А.Н. Горбань – М.: СП ПараГраф, 1990. – 298 с.
- Горелик А.Л. Методы распознавания. Учебное пособие для вузов. / А.Л. Горелик, В.А. Скрипкин – М.: Высшая школа, 1977 – 222 с.
- Кокрен У. Методы выборочного исследования. / У. Кокрен – М.: Статистика, 1976. – 440 с.
- Советов Б.Я. Моделирование систем. / Б.Я. Советов, С.А. Яковлев – М.: Высшая школа, 1985. – 271 с.
- Тынкевич М.А. Численные методы анализа. / М.А. Тынкевич – Кемерово: КузГТУ, 1997. – 122 с.
- Алгоритм FRiS-STOLP [Электронный ресурс]. – Режим доступа: http://www.machinelearning.ru/
- Теория распознавания образов [Электронный ресурс]. – Режим доступа: http://ru.wikipedia.org/
Важное замечание
При написании данного автореферата магистерская работа еще не завершена. Предположительная дата завершения – декабрь 2013 г. Полный текст работы, а также материалы по теме могут быть получены у автора или его руководителя после указанной даты.