
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі дослідження
- 3. Передбачувана наукова новизна
- 4. Огляд існуючих алгоритмів побудови зважених вибірок
- 4.1 Алгоритм STOLP
- 4.2 Алгоритм FRiS-STOLP
- 4.3 Алгоритм NNDE
- 5. Метод побудови вибірки w-об'єктів
- Висновки
- Перелік посилань
- Важливе зауваження
Вступ
Системи розпізнавання знаходять все більшу область застосування в повсякденному житті (електронна пошта, бібліотеки в Інтернет, системи управління голосом). Системи розпізнавання є в медицині, в антивірусному захисту комп'ютера, в системах відеоспостереження.
Ознаки розпізнаваних об'єктів постійно змінюються, що ускладнює розпізнавання й вірну класифікацію. Тому постає питання про розробку таких систем, які з найменшими змінами могли б розпізнавати об'єкти з такою ж високою достовірністю як і колись, тобто адаптуватися до нових умов. Такі системи прийнято називати адаптивними системами розпізнавання [11].
Здатність до самонавчання в адаптивних системах зумовлена тим, що всі виявлені зміни в стані вже вивчених об'єктів додаються в навчальну вибірку. Перед тим як додати нову ознаку, потрібно визначити доцільність ії додавання. З кожним новим доданим елементом так само виникає необхідність у коригуванні існуючих вирішальних правил класифікації, а у разі глобальних змін – ще й потреба у створенні нового словника ознак [1].
1. Актуальність теми
Більшість сучасних прикладних завдань, що вирішуються шляхом побудови систем розпізнавання, характеризується великим обсягом вихідних даних і можливістю додавання нових даних вже в процесі роботи систем. Саме тому основними вимогами, що пред'являються до сучасних систем розпізнавання, є адаптивність (можливість системи в процесі роботи змінювати свої характеристики, а для навчаючихся систем розпізнавання – коригувати вирішальні правила класифікації, при зміні навколишнього середовища), робота в реальному часі (можливість формування рішень про класифікацію за обмежений час) і висока ефективність класифікації для лінійно роздільних і пересічних в просторі ознак класів [5].
Додавання нових об'єктів, що є для більшості прикладних завдань досить інтенсивним, призводить до істотного збільшення розміру навчальної вибірки, що, у свою чергу, призводить до:
- Збільшення часу коригування вирішальних правил (особливо, якщо використовуємий метод навчання вимагає побудови нового вирішального правила, а не його часткового коригування);
- Погіршення якості одержуваних рішень через проблеми перенавчання на вибірках великого об'єму.
Ці особливості адаптивних навчаючихся систем розпізнавання роблять необхідною передобробку навчальних вибірок шляхом скорочення їх розміру.
2. Мета і задачі дослідження
Метою випускної роботи магістра є розробка алгоритму побудови зважених темпоральних навчальних вибірок в адаптивних системах розпізнавання. У процесі роботи необхідно вирішити наступні завдання:
- Дослідити існуючі алгоритми побудови зважених навчальних вибірок;
- Дослідити методи застосування зважених навчальних вибірок в адаптивних системах розпізнавання;
- Розробити алгоритм побудови зважених темпоральних навчальних вибірок в адаптивних системах розпізнавання;
- Розробити прототип програмної системи тестування алгоритмів побудови зважених темпоральних навчальних вибірок в адаптивних системах розпізнавання;
- Виконати порівняльний аналіз запропонованого алгоритму та відомих алгоритмів вирішення даної задачі.
3. Передбачувана наукова новизна
Науковою новизною даної роботи є розробка методу побудови зважених темпоральних навчальних вибірок в адаптивних системах розпізнавання. Оскільки зростання розміру навчальної вибірки призводить до зростання часу навчання і погіршення його якості, передбачається, що на основі зважених темпоральних вибірок може бути побудований ефективний алгоритм вибору деякої кількості актуальних об'єктів вибірки і видалення інших.
4. Огляд існуючих алгоритмів побудови зважених вибірок
4.1 Алгоритм STOLP
Нехай дана навчальна вибірка:
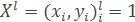
де xi – об'єкти, yi=y*(xi) – класи, яким належать ці об'єкти.
Крім того, задана метрика ρX*X→R, ттака, що виконується гіпотеза компактності. При класифікації об'єктів метричним класифікатором
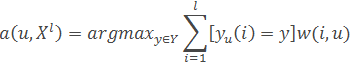
наприклад, методом найближчих сусідів необхідно рахувати відстані від класифікуємого об'єкта до всіх об'єктів навчальної вибірки. Час, що витрачається на це для кожного класифікуємого об'єкта, пропорційний розміру навчальної вибірки. Крім того, необхідно зберігати великий обсяг даних [8].
Але не всі об'єкти навчальної вибірки рівноцінні. Серед них є найбільш типові представники класів, тобто еталони; неінформативні об'єкти, при видаленні яких з навчальної вибірки якість класифікації не зміниться; викиди, або шумові об'єкти – об'єкти, що знаходяться в гущі «чужого» класу, тільки погіршують якість класифікації [7].
Тому необхідно зменшити обсяг навчальної вибірки, залишивши в ній тільки еталонні об'єкти для кожного класу.
Еталони – це така підмножина вибірки Xl, що всі об'єкти Xl (або їх більшість) класифікуються правильно при використанні як навчальної вибірки безлічі еталонів.
Eталонами i -го класу при класифікації методом найближчого сусіда може служити таке підмножина об'єктів Xl цього класу, що відстань від будь-якого належного йому об'єкта з вибірки до найближчого «свого» зразка менше, ніж до найближчого «чужого» еталона.
Простий перебір для відбору еталонів не ефективний, так як число способів вибору по t еталонів для кожного класу (число класів k) складає П(j=1)kCtmj.
Величина ризику (W ) — величина, що характеризує ступінь ризику для об'єкта бути класифікованими не в той клас, якому він належить.
При використанні методу найближчих сусідів можна вважати
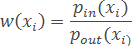
де pin – відстань від об'єкта xi до найближчого до нього об'єкта (або еталона) з «свого» класу; pout – до найближчого об'єкта (або еталона) «чужого» класу.
При використанні будь-якого метричного методу можна покласти

де M(xi ,μ)=Гyi - max(y∈Y\yi) Гy(xi) – відступ на об'єкті xi при навчальній вибірці μ (μ – множина еталонів).
Крім того, залежно від використовуваного методу класифікації можна підібрати й інші оцінки величини ризику. Головне, щоб вони брали великі значення на об'єктах-викидах, менші – на об'єктах, що знаходяться на кордоні класу, і ще менші – на об'єктах, що знаходяться в глибині свого класу [4].
На вхід алгоритму подається вибірка Xl, допустима доля помилок l0, поріг відсікання викидів δ, алгоритм класифікації і формула для розрахунку величини ризику W.
Спочатку потрібно відкинути викиди (об'єкти Xl, з W >δ), зпотім сформувати початкове наближення μ – з об'єктів вибірки Xl, вибрати по одному об'єкту кожного класу, котрий володіє серед об'єктів даного класу максимальною або мінімальною величиною ризику.
Далі нарощується множина еталонів (поки число об'єктів вибірки Xl, що розпізнаються неправильно, не стане менше l0,). Далі класифікують об'єктиXl, ивикористовуючи як навчальну вибірку μ, перераховують величини ризику для всіх об'єктів Xl \μ, з урахуванням зміни навчальної вибірки. Серед об'єктів кожного класу, розпізнаних неправильно, вибирають об'єкти з максимальною величиною ризику і додають їх до μ.
У результаті множина еталонів μ∈Xl, для кожного класу представляє собою деякий набір об'єктів, що знаходяться на кордоні класу, і, якщо в якості початкового наближення вибиралися об'єкти з мінімальною величиною ризику, один об'єкт, що знаходиться в центрі класу.
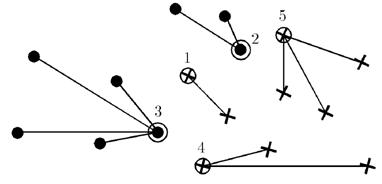
Малюнок 1 – Результат роботи алгоритму STOLP
4.2 Алгоритм FRiS-STOLP
Алгоритм FRiS-STOLP – алгоритм відбору еталонних об'єктів для метричного класифікатора на основі FRiS-функції. Від класичного алгоритму STOLP його відрізняє використання допоміжних функцій [10].
Функція NN(u,U) повертає найближчий до u об'єкт з множини U.
Функція FindEtalon (xy,μ) виходячи з набору вже наявних еталонів &;mu та набору Xy елементів класу Y, повертає новий еталон для классу Y за наступним алгоритмом:
- Для кожного об'єкту x∈Xy розраховуються дві характеристики - «обороноздатність» і «толерантність» (наскільки об'єкт в в ролі еталона одного класу не заважає еталонам інших класів) об'єкта:
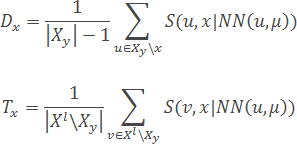
- На підставі отриманих характеристик розраховується «ефективність» об'єкта x:
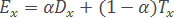
- Функція FindEtalon повертає об'єкт x∈Xl з максимальною ефективністю Ex:
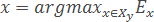
Параметр α∈[0,1] кількісно задає відносну «важливість» характеристик об'єктів («обороноздатності» і «толерантності»). Може бути обраний, виходячи із специфіки конкретного завдання.
4.3 Алгоритм NNDE
Метод найближчих сусідів – найпростіший метричний класифікатор, заснований на оцінюванні подібності об'єктів.
Класифікуємий об'єкт належить до того класу, якому належать найближчі до нього об'єкти навчальної вибірки. В завданнях з двома класами число сусідів беруть непарне, щоб не виникало колізій, коли однакове число сусідів належать різним класам. У завданнях з числом класів 3 і більше непарність вже не допомагає, і ситуації багатозначності все одно можуть виникати. Тоді i -му сусіду приписується вага w, як правило, вона зменшується із зростанням рангу сусіда i. Об'єкт відноситься до того класу, який набирає більшу сумарну вагу серед найближчих сусідів [9].
Нехай задана навчальна вибірка пар «об'єкт–відповідь» Xm={(x1,y1),…,(xm,ym)}.
Нехай на множині об'єктів задана функція відстані ρ(x,x′). Ця функція повинна бути достатньо адекватною моделлю подібності об'єктів. Чим більше значення цієї функції, тим менш схожими є два об'єкти (x,x′).
Для довільного об'єкта u розташуємо об'єкти навчальної вибірки xi в порядку зростання відстаней до u: ρ(u,x1;u)≤ρ(u,x2;u)≤...≤ρ(u,xm;u) де через xi;u позначається той об'єкт навчальної вибірки, який є i -м сусідом об'єкта u. Аналогічне позначення введемо і для відповіді на i -м сусіді: yi;u. Таким чином, довільний об'єкт u породжує свою перенумерацію вибірки.
У найбільш загальному вигляді алгоритм найближчих сусідів виглядає так:
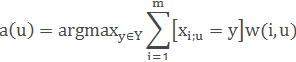
де w(i,u) — задана вагова функція, яка оцінює ступінь важливості i -го сусіда для класифікації об'єкта u. Природно вважати, що ця функція більше нуля і не зростає по i.
По-різному задаючи вагову функцію, можна отримувати різні варіанти методу найближчих сусідів.
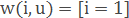 – найпростіший метод найближчих сусідів.
– найпростіший метод найближчих сусідів.
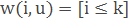 – метод k найближчих сусідів.
– метод k найближчих сусідів.
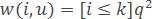 – метод k експоненціально зважених найближчих сусідів, де передбачається q<1.
– метод k експоненціально зважених найближчих сусідів, де передбачається q<1.
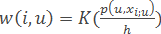 – метод парзенівського вікна постійної ширини h.
– метод парзенівського вікна постійної ширини h.
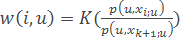 – метод парзенівського вікна змінної ширини.
– метод парзенівського вікна змінної ширини.
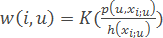 – метод потенційних функцій, в якому ширина вікна h(xi) залежить не від классифікумого об'єкта, а від навчального об'єкта xi.
– метод потенційних функцій, в якому ширина вікна h(xi) залежить не від классифікумого об'єкта, а від навчального об'єкта xi.
Тут K(r) – задана та більша за нуль монотонно незростаюча функція на [0,∞), ядро згладжування.
5. Метод побудови вибірки w-об'єктів
Розглянуті вище алгоритми не дозволяють враховувати щільність розподілу об'єктів вибірки в просторі ознак і динаміку зміни значень ознак додаються об'єктів. Використовуючи такий підхід, ми можемо скоротити ключові елементи вибірки.
Для уникнення цього можна використовувати метод скорочення вибірки шляхом побудови взваженої вибірки w-об'єктів [2], що дозволяє виконувати скорочення навчальної вибірки при непогіршенні якості класифікації. Також цей метод вирішує проблему додавання нових об'єктів у вибірку при мінімальному збільшенні її розміру.
Основою методу побудови виваженої навчальної вибірки w-об'єктів для скорочення вибірок великого обсягу в адаптивних системах розпізнавання є вибір множин близькоросташованних об'єктів вихідної вибірки та їх заміна одним зваженим об'єктом нової вибірки. Значення ознак кожного об'єкта нової вибірки є центрами мас значень ознак об'єктів вихідної вибірки, які він замінює. Введений додатковий параметр – вага визначається як кількість об'єктів вихідної вибірки, які були замінені одним об'єктом нової вибірки. Пропонуємий метод орієнтований як на скорочення вихідної навчальної вибірки, так і на аналіз необхідності коригування вибірки та швидке виконання такого коригування при поповненні вибірки в процесі роботи системи.
В якості вихідних даних для пропонованого методу візьмемо деяку множину об'єктів M, звану навчальною вибіркою. Кожний об'єкт Xi з M описується системою з n ознак, тобто Xi={xi1,xi2,...,xin}, та представляється точкою в лінійному просторі ознак, тобто Xi∈Rn. Для кожного об'єкта Xi відома його класифікація yi∈[1,l], l – число класів системи.
Побудова w-об'єкта складається з трьох послідовних етапів:
- Побудова утворюючої множини Wf, що містить деяку кількість d об'єктів вихідної вибірки, що належать одному класу;
- Формування вектора XiW={xi1,xi2,...,xin}, значень ознак w-об'єктаXiW й розрахунок його ваги pi ;
- Коригування вихідної навчальної вибірки – видалення об'єктів, включених до утворюючої множини X=X \Wf.
Побудова утворюючої множини Wf складається в находжені початкової точки Xf1 формуванні w-об'єкта, визначенні конкуруючої точки Xf2 та виборі в утворювальну множину Wf таких об'єктів вихідної вибірки, відстань до кожного з яких від початкової точки менше, ніж відстань від них до конкуруючої точки. В якості початкової точки Xf1 формування w-об'єкта використовується об'єкт вихідної навчальної вибірки, найбільш віддалений від усіх об'єктів інших класів. Конкуруюча точка Xf2 визначається шляхом знахождення найближчого до Xf1 об'єкта, який не належить до того ж класа, що й сам Xf1, тобто yf1≠yf2.
У випадку двух класів вибір об'єктів {Xf1,Xf2,...,Xd} утворюючої множини Wf здійснюється за наступним правилом: об'єктXi додається до Wf, якщо:
- Він належить до того ж класу, що і початкова точка Xf1;
- Відстань від розглянутого об'єкта до початкової точки Xf1 менше, ніж до конкуруючої точки Xf2;
- Відстань Ri,1 від розглянутого об'єкта до початкової точки менше відстані Ri,2 від розглянутого об'єкта до конкуруючої точки і менше відстані R1,2 між початковою і конкуруючої точками (для випадку, коли класи складаються з декількох окремих областей простору ознак).
Таким чином, утворююча множина Wf формується за правилом:
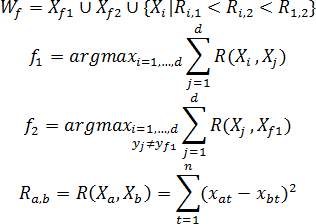
Значення ознак {xi1,xi2,...,xin} нового w-об'єкта XiW формуються за утворюючої множиною Wf та розраховуються як координати центру ваг системи зpf=|Wf|матеріальних точок (приймемо, що об'єкти вихідної навчальної вибірки, які є в просторі ознак матеріальними точками, мають масу, рівну 1), де |Wf| – потужність множини Wf, тобто:
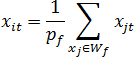
Після формування чергового w-об'єкта, всі об'єкти утворюючої його множини видаляються з вихідної навчальної вибірки, тобто X=X\Wf. Алгоритм закінчує свою роботу, коли у вихідній навчальній вибірці не залишиться жодного об'єкту X∈∅ [3].

Малюнок 2 – Побудова w-об'єкту (анімація: 5 кадрів, 5 циклів повторення, 73,5 кбайт)
Принцип формування утворюютчих множин, що вибирає близько розташовані у просторі ознак об'єкти, є ефективним способом розподілу вибірки на групи. Введення ваг дозволяє не тільки зберігати інформацію про кількість замінених об'єктів, а й характеризувати область, в якій ці об'єкти розташовані. Виходячи з цього представляється ефективним використання зважених навчальних вибірок w-об'єктів для вирішення завдання побудови зважених темпоральних вибірок в адаптивних системах розпізнавання.
Висновки
У даній роботі були досліджені різні алгоритми скорочення вибірок в адаптивних системах розпізнавання. Такі алгоритми як STOLP, FRiS-STOLP прості в реалізації, але дають велику помилку при вирішенні завдань з великим обсягом вхідних даних, алгоритм NNDE практично не пристосований для вирішення таких завдань [6]. У порівнянні з цими алгоритмами, метод групового обліку аргументів дає значно кращий результат, зважаючи на його гнучкість і можливість міняти параметри алгоритму під конкретні умови задачі.
Виходячи, з описаних алгоритмів скорочення адаптивних вибірок був зроблений висновок, що метод групового обліку аргументів найбільш гнучкий, універсальний і найкраще підходить для модифікації для вирішення завдань побудови зважених темпоральних вибірок в адаптивних системах розпізнавання.
Перелік посилань
- Александров А.Г. Оптимальные и адаптивные системы. / А.Г. Александров – М.: Высшая школа, 1989. – 263 с.
- Волченко Е.В. Расширение метода группового учета аргументов на взвешенные обучающие выборки w-объектов / Е.В. Волченко // Вісник Національного технічного університету "Харківський політехнічний інститут". Збірник наукових праць. Тематичний випуск: Інформатика i моделювання. – Харків: НТУ "ХПІ", 2010. – № 31. – С. 49 – 57.
- Волченко Е.В. Метод сокращения обучающих выборок GridDC / Е.В. Волченко, И.В. Дрозд // Штучний інтелект. –2010. – №4. – С. 185-189.
- Глушков В.М. Введение в кибернетику. / В.М. Глушков – К.: Изд-во АН УССР, 1964. – 324 с.
- Горбань А.Н. Обучение нейронных сетей. / А.Н. Горбань – М.: СП ПараГраф, 1990. – 298 с.
- Горелик А.Л. Методы распознавания. Учебное пособие для вузов. / А.Л. Горелик, В.А. Скрипкин – М.: Высшая школа, 1977 – 222 с.
- Кокрен У. Методы выборочного исследования. / У. Кокрен – М.: Статистика, 1976. – 440 с.
- Советов Б.Я. Моделирование систем. / Б.Я. Советов, С.А. Яковлев – М.: Высшая школа, 1985. – 271 с.
- Тынкевич М.А. Численные методы анализа. / М.А. Тынкевич – Кемерово: КузГТУ, 1997. – 122 с.
- Алгоритм FRiS-STOLP [Электронный ресурс]. – Режим доступа: http://www.machinelearning.ru/
- Теория распознавания образов [Электронный ресурс]. – Режим доступа: http://ru.wikipedia.org/
Важливе зауваження
При написанні даного автореферату магістерська робота ще не завершена. Можлива дата завершення – грудень 2013 року. Повний текст роботи, а також матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.