
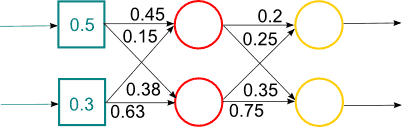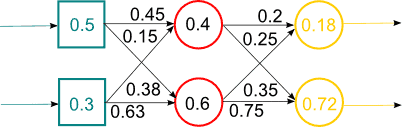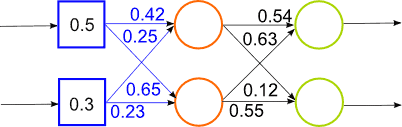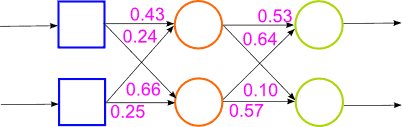
 Figure 1 – Work of a hybrid neural network (animation, 14 frames, 15 rep., 65.8 KB)
Figure 1 – Work of a hybrid neural network (animation, 14 frames, 15 rep., 65.8 KB)
Русский |
Українська |
English
Abstract
- Introduction
- Research goal
- 1. Review of research and development on the subject
- 1.1 World level
- 1.2 National level
- 1.3 Local level
- 2. The main content
- 2.1 Structure of modern speech recognition systems
- 2.2 Approaches to the recognition of phonemes
- 2.3 Neural network architectures
- 2.4 Practical experiment
- Conclusion
- References
Introduction
There are many ways to implement automated speech recognition systems: • voice control system for the Internet of Things; • automated call-centers; • search in video and audio files; • automatic transfer of information between its various forms.
Over the past sixty years, speech recognition systems have come a long way from recognition dozen words spoken by one speaker to speaker independent recognition systems with hundreds of thousands of words vocabulary.
During this time, the structure of the speech recognition system was formed. This system consists of two large blocks: acoustic-phonetic module for submitting the speech signal and linguistic module for the interpretation of the resulting acoustic model information and get result to the user.
If linguistic algorithms (N-grams, the Viterbi algorithm, the Baum–Welch, direct – reverse) worked well and did not require improvements, the acoustic- phonetic algorithms block still not good enough and have the potential for further improvement, as shown current results of the speaker phoneme recognition. Thus, the development of new and more efficient algorithms for recognition of phonemes is an urgent task. In the context of studies in recent years appears to be effective for its decision to use a hybrid neural network based on Bayesian belief networks.
Research goal
ВIn view of the above stated goal was set – to create speech recognition system based on the hybrid model with Bayesian networks.
In accordance with the goal is required to solve such problems:
1. Examine the structure of modern speech recognition systems. 2. Examine approaches to speech recognition. 3. Analyse existing speech recognition methods. 4. Develop new, more efficient model of speech recognition. 5. Apply this model to recognize the Ukrainian language. 6. Develop application for speech recognition.
1. Review of research and development on the subject
1.1 World level
In the scientific community very enthusiastic for Bayesian networks is Professor Geoffrey Hinton, University of Toronto. In his works [2,3], and the works of his colleagues [4,5] are often used these networks in conjunction with restricted Boltzmann machine.
1.2 National level
A leader in speech technologies in Ukraine is Department of sound pattern recognition of the International Research and Training Center of Information Technologies and Systems. Since the late 1960s in the department (then at the Glushkov Institute of Cybernetic) under the leadership of T.K. Vintsyuk (1988 to 2012) are working on speech recognition. Taras Klimovich Vintsyuk invented generative model for pattern recognition, known as Dynamic Time Wraping (DTW). The International Research and Training Center of Information Technologies and Systems Conference held "UkrObraz" dedicated to pattern recognition, as well as annual summer school seminars on speech technologies.
1.3 Local level
In the Donetsk National Technical University research related to speech recognition are conducted at the Department of Applied Mathematics and Computer Science under the direction of Oleg Ivanovich Fedjaev. We should also mention the work of this department graduate student Ivan Jurevich Bondarenko [7]. Also involved in this issue are students and post-graduate students of Department of artificial intelligence systems under the management of Vladislav Jurevich Shelepov. With the most important works of masters DNTU on this topic can be found in the library.
2. The main content
2.1 Structure of modern speech recognition systems
The architecture of a modern system of automatic speech recognition consists of typical units:
• The noise reduction and separation of the desired signal. • Acoustic-phonetic model. • Linguistic model. • Decoder.
As stated above, the main interest are methods to improve the efficiency of acoustic-phonetic model, as a linguistic unit would be useless if it is not achieved the required accuracy of the acoustic speech recognition. Further, a closer look at the acoustic-phonetic algorithms block.
2.2 Approaches to the recognition of phonemes
There are two approaches to the recognition of phonemes: generative (hidden Markov models, Gaussian mixture and CDP Vintsyuk approach) and discriminative (neural networks, support vector machines). Generative approach allows very efficient simulation of nonlinear time-varying processes. But at the same time discriminative ability of this class of algorithms is not high, in opposite to other algorithms described here.
Discriminative algorithms by separating planes split samples by classes in the feature space. A bad thing about discriminative algorithms is their low efficiency in recognition of time-varying images. But as phonemes in time stationary and not change as whole words, this disadvantage can be lowered within a solved problem.
2.3 Neural network architectures
Consider one of the options under the discriminative approach – multilayer perceptron neural network architecture.
Backpropagation algorithm allows to learn all the layers of the neural network and allow to solve with neural networks very complex tasks (eg such as the recognition of speech and writing). But increasing the number of layers network, complexity of required calculations grows exponentially.
The solution to this problem lies in finding a more efficient network architectures and algorithms for their learning. There are several solutions to this problem: use learning algorithms that allow to get out of local minima, use of neural networks (Convolutional Neural Networks, Time Delay Neural Networks), use special algorithms with initialize multilayer networks based on Bayesian algorithms. Such algorithms trained network layers and consistently without a teacher. Algorithm is to first consider the network as a Bayesian network and teach her before without a teacher. And when the weights are close to the values of the likelihood function, the survival learning with backpropagation algorithm. The algorithm is shown in Figure 1.
Figure 1 – Work of a hybrid neural network (animation, 14 frames, 15 rep., 65.8 KB)
2.4 Practical experiment
As an experiment, two programs have been written for training multilayer perceptron and sigmoid belief networks problem XOR. Both programs are based on the same network interface. The program works on the above learning algorithms networks. As desired error rate was chosen by 0.01. Weight adjusted after each training epoch.
The second subroutine sigmoidal network is used as a trust mechanism solution of the problem of retraining network XOR. As a result of the experiment, it was found that for training multilayer perceptrons took 228 epochs of training. At the same time as the sigmoid belief networks with post training took 106 epochs. Graphs of the average error for periods shown in Figure 2.
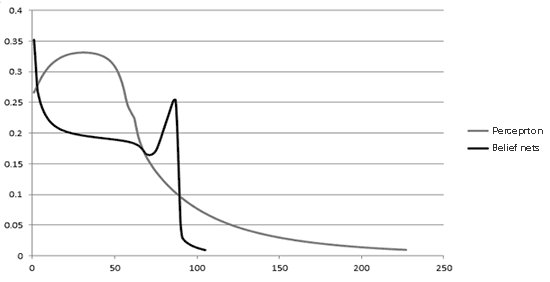 Figure 2 — Results of an experiment
Figure 2 — Results of an experiment
Conclusion
Based on the analysis of existing developments to date, we can conclude that the hybrid approach of using trust networks and multilayer perceptron is an effective tool for solving classification problems in general and speech recognition in particular. This conclusion is based on the results of practical experiments where it has been demonstrated that by using the multilayer perceptron in conjunction with Bayesian networks of trust, the training network accelerates 2 times. This means that this results requires further study and improvement of learning algorithms to use this neural network architecture to maximize quality of speech recognition.
Direction of future research should involve search approach in the application of Bayesian networks to build good acoustic- phonetic models of speech recognition and use this model to recognize Ukrainian speech.
At time of the writing this essay master's work is not yet complete. Due date: December 2014. Full text of the work and materials on the topic can be obtained from author after this date.
References
[1] Александр Пасечник История развития систем распознавания речи: как мы пришли к Siri [Электронный ресурс] – [Режим доступа:] http://habrahabr.ru/post/131945/ [2] Geoffrey Hinton. NISP tutorial on deep belief nets. – Canadian Institute for Advanced Research, 2007. – 100 p. [3] Geoffrey Hinton. To recognize shapes, first learn to generate images. — In P. Cisek, T. Drew and J. Kalaska (Eds.) Computational Neuroscience: Theoretical Insights into Brain Function. Elsevier., 2006. — pp. 17-34. [4] Deng, L., Hinton, G. E. and Kingsbury, B. New types of deep neural network learning for speech recognition and related applications: An overview – IEEE International Conference on Acoustic Speech and Signal Processing (ICASSP 2013) – Vancouver, 2013. – pp. 8599-8603. [5] Abdel-rahman Mohamed, Geoffrey Hinton, Gerald Penn. Understanding how Deep Belief Nets perform acoustic modeling. – ICASSP, 2012 – pp. 4273-4276. [6] Распознавание речи от Яндекса. Под капотом у Yandex.SpeechKit. [Электронный ресурс] [Режим доступа:] http://habrahabr.ru/company/yandex/blog/198556/ [7] О.І.Федяєв, І.Ю.Бондаренко. Розробка і дослідження нейромережевого алгоритму дикторонезалежного розпізнавання фонем в усному мовленні // Праці Одинадцятої всеукраїнської міжнародної конференції з оброблення сигналів і зображень та розпізнавання образів УкрОБРАЗ'2012. — К.: МННЦ ІТ та С, 2012. — С.71-74. [8] А.Л. Ронжин, А.А. Карпов, И.В. Ли Система автоматического распознавания русской речи SIRIUS — Искусственный интеллект выпуск 3, 2010. – C. 590-601. [9] T. Dutoit Reconnaissance automatique de la parole — Techniques de l’Ingénieur, 2010. – pp. 401-404. [10] С. Хайкин. Нейронные сети: полный курс, 2-е издание, : Пер. с англ. — М.: Издательский дом «Вильямс», 2006. — 1104 с. [11] Hinton, G., Deng, L., Yu, D., Dahl, G. E. et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. – Signal Processing Magazine, IEEE, 2012. – pp. 82-97. [12] Rasmus Berg Palm. Prediction as a candidate for learning deep hierarchical models of data. – Technical University of Denmark, 2012. – 80 p. [13] Брынза Т.А, Бондаренко И.Ю. Сигмоидальные сети доверия в решении задач классификации – Труды IV международной конференции «Информационно-управляющие системы и компьютерный мониторинг», 2013. – C. 422-427. [14] Брынза Т.А., Бондаренко И.Ю., Губенко Н.Е. Представление байесовских сетей доверия для решения задачи распознавания образов. – Труды IX международной научно-технической конференции студентов, аспирантов, молодых ученых «Информатика и компьютерные технологии», 2013. – C. 304-308. [15] Linda Otmani, Abdelkader Benyettou. Les réseaux neuro-bayésiens appliqués à la reconnaissance de la parole. – Université des sciences et de technologie d’ORAN -Mohamed Boudiaf- faculté des sciences, département d’informatique, 2007. – 7 p. [16] Gregoire Montavon. Deep learning for spoken language identification. – Machine Learning Group, Berlin Institute of Technology Germany, 2005. – 4 p. [17] Hinton, G.E., Dayan, P., Frey, B.J. & Neal, R. The wake-sleep algorithm for self-organizing neural network. — Science, 1995. — P. 1158-1161.