
Кисниченко Екатерина Александровна
Факультет компьютерных наук и технологий
Кафедра систем искусственного интеллекта
Специальность «Системы искусственного интеллекта»
Разработка и исследование алгоритма формирования семантического ядра веб–сайта на основе методов Data Mining
Научный руководитель: д.ф.–м.н., проф. Шелепов Владислав Юрьевич
Реферат по теме выпускной работы
Введение
1. Актуальность темы
2. Цель и задачи исследования
3. Предполагаемая научная новизна
4. Обзор исследований и разработок по теме
4.1 Глобальный уровень
4.2 Национальный уровень
4.3 Локальный уровень
5. Анализ работы поисковых систем и традиционного подхода к разработке семантического ядра сайта
6. Алгоритм формирования семантического ядра для сайтов с динамическим контентом
7. Направления дальнейших исследований
Выводы
Список литературы
Введение
Интернет – это обширное информационное поле, огромная база знаний, содержащая подробные сведения научного, исторического, политического, повседневного характера. Интернет можно сравнить с огромным словарем, описывающим нашу планету и все процессы, сопутствующие развитию человеческой цивилизации, которые происходили, происходят и могут произойти в будущем.
На сегодняшний день практически вся информация, доступная во всемирной паутине не содержит семантики и поэтому ее поиск, релевантный запросам пользователя, а также интеграция в рамках конкретной предметной области затруднены. Для обеспечения эффективного поиска, веб–приложение должно четко понимать семантику документов, представленных в сети. В связи с этим, можно наблюдать бурный рост и развитие технологий Semantic Web, происходящий в настоящее время. Консорциумом W3C была разработана концепция, которая базируется на активном использовании метаданных, языке разметки XML, языке RDF (Resource Definition Framework – Среда Описания Ресурса) и онтологическом подходе. Все предложенные средства позволяют осуществлять обмен данными и их многократное использование.
1. Актуальность темы
В век информационных технологий успех бизнеса в значительной степени зависит от способов виртуального представления фирмы в сети Интернет. При этом целью разработки контента веб–ресурса фирмы является предоставление информации, которая была бы способна заставить пользователя думать и вести себя в направлении, выгодном реальному бизнесу. С другой стороны, известно, что доля «поискового трафика» любого сайта (отношение числа посетителей, пришедших от поисковых выдач, к общей посещаемости сайта) является преобладающей. Поэтому при разработке контента сайта большое внимание уделяется поисковой оптимизации (seo – search engine optimization) – комплексу мер, направленных на продвижение веб–ресурса к верхним позициям поисковой системы (ПС) с целью увеличения его посещаемости. Одним из ключевых этапов SEO является разработка семантического ядра (СЯ) сайта, которая, как правило, выполняется специалистами вручную и требует больших временных затрат [1,2].
Семантическое ядро – такой набор ключевых слов и словосочетаний, которые запрашивают пользователи в поисковых системах, на этапе поиска информации, напрямую связанной с содержанием ресурса. Данное ядро ключей – основа внутренней оптимизации сайта: мета-описаний, текстов, тегов заголовков и тегов акцентирования.
Ручной подход неприемлем при создании семантического ядра для сайтов с динамическим контентом из-за большого временного запаздывания в обновлении СЯ SEO–специалистами, сложности учета предпочтений и действий пользователей. Поэтому актуальным является создание алгоритма и методики разработки СЯ, применение которых позволило бы сократить время на достижение и поддержание лидирующих позиций сайта в поисковых выдачах.
2. Цель и задачи исследования
Цель работы состоит в разработке и исследовании алгоритма формирования семантического ядра сайтов с динамическим контентом на основе методов Data Mining.
Для достижения поставленной цели необходимо решить следующие задачи:
– проанализировать работу поисковых систем и установить связь между этапами и процедурами работы ПС и разработкой СЯС;
– рассмотреть традиционные алгоритмы формирования СЯ;
– определить требования к формированию транзакционной базы данных в терминах анализа связей и разработать базу данных для поисковых транзакций;
– разработать алгоритм создания и обновления СЯ на основе применения анализа связей в транзакционной базе поисковых запросов.
3. Предполагаемая научная новизна
Модифицированный алгоритм разработки и обновления семантического ядра сайта, на основе создания ассоциативных правил с помощью алгоритма поиска популярных наборов в транзакционной базе данных поисковых запросов методами Data Mining.
Предлагаемый алгоритм может быть внедрен в системы администрирования сайтов или в средства поддержки работы seo специалистов для повышения полноты, точности и снижения времени разработки СЯ сайтов с динамическим контентом.
4. Обзор исследований и разработок по теме
4.1 Мировой уровень
На ранних стадиях эволюции поисковых систем учитывалось малое количество факторов, влияющих на ранжирование в выдаче результатов поиска, поэтому, зная базовые принципы работы поисковых систем, можно было достаточно легко манипулировать результатами. При дальнейшей эволюции число таких факторов росло в геометрической прогрессии, постоянно увеличивался уровень конкуренции и, в некоторый момент времени, этап развития технологии продвижения сайтов вышел на новый виток – начало автоматизации процессов.
Исследование работы поисковых систем [3] и вопросы повышения релевантности документов запросам пользователей проводились В. Д. Байковым [4], Д.Н. Колисниченко, Н.В. Евдокимовым [5, 6, 7, 8], И.С.Ашмановым, A.A. Ивановым, A.A. [9], Яковлевым [10,11]. В них рассматривались факторы, влияющие на ранжирование в поисковых системах. Формулы ранжирования поисковых систем претерпели значительные изменения за последние 2–3 года, и результаты работ вышеперечисленных авторов неактуальны.
В работах зарубежных авторов Agrawal R., Srikant R. [12], Aizawa A. [13], Тероу Ш. [14] подробно рассмотрены тонкости оптимизации сайтов и блогов, а также динамических сайтов, которые обеспечивают поисковую видимость в интернете текстов, видео и аудиофайлов. Большое внимание уделено проблеме нечистых методов раскрутки сайта, а также рекомендациям, как, не используя данные методы, раскрутить сайт.
Для построения семантического ядра существует ряд программных инструментов.
Самая простая, но вполне приемлемая программа для подбора практически всех имеющихся запросов в Яндекс.Вордстате – Key Collector (http://www.key-collector.ru/). Она, по словам разработчиков, имеет более 70 параметров для оценки ключевых фраз, 4 способа работы с Яндекс.Вордстатом, а также возможность проведения экспресс–анализа сайта на соответствие семантическому ядру, интеграции со ссылочными брокерами и многое другое. С помощью нее можно выгрузить все запросы, содержащие введенное вами слово, а также поисковые подсказки и запросы из правой колонки Вордстата. Имеется подробная инструкция с описанием всех функций. Программа постоянно обновляется и совершенствуется.
Вторым инструментом для составления семантического ядра являются «Базы Пастухова». Это архив, состоящий из ключевых слов, которые запрашивают пользователи в Google, Яндексе, Rambler. Здесь содержатся домены с подробной информацией о каждом из них. То есть это не программа, которая парсит Вордстат или поисковые подсказки, а база данных ключевых слов, которые запрашивались в определенный период. Преимуществом «Баз Пастухова» является возможность увидеть практически все уникальные пользовательские запросы, которых нет в Яндекс.Вордстате.
4.2 Национальный уровень
На национальном уровне работы по разработке семантических ядер сайтов ведуться в Одесском национальном политехническом университете авторами Е.А. Арсирий, О.А. Игнатенко, А.А. Леус [15]. Авторами предложена методика разработки семантического ядра сайта на основе создания ассоциативных правил с помощью алгоритма поиска популярных наборов Apriori в базе данных поисковых запросов.
4.3 Локальный уровень
В Донецком Национальном Техническом Университете изучением факторов продвижения интернет–магазина с помощью аппарата мультимножеств занимался Павленко Антон Игоревич[16]. Разработкой методики продвижения сайта в поисковой системе Google занимался Халыгов Артем Азимович [17].
5. Анализ работы поисковых систем и традиционного подхода к разработке семантического ядра сайта
ПС представляет собой сайт, состоящий из веб–интерфейса для пользователя и поисковой машины, которая является движком, обеспечивающим функциональность ПС. Поисковая машина состоит из модуля индексирования, базы данных (БД) проиндексированных документов и поискового сервера, занимающегося анализом и обработкой запросов пользователей. Модуль индексирования состоит из трех вспомогательных программ (роботов) – spider (паук), crawler (путешествующий паук) и indexer (индексатор). Паук скачивает веб–документы с помощью протокола НТТР, извлекает ссылки и перенаправления и сохраняет текст в следующем формате: URL, дата скачивания, http–заголовок ответа сервера, тело страницы (html–код). Crawler обрабатывает найденные пауком ссылки и осуществляет дальнейшее направление паука. Indexer разбирает html–код страницы на составные части, такие как заголовки (title), подзаголовки (subtitles), метатэги (meta tags), текст, ссылки, структурные и стилевые особенности и т.д, анализирует их на основе различных лексических и морфологических алгоритмов с целью последующего ранжирования по степени важности. При этом найденным словам и словосочетаниям присваиваются весовые коэффициенты в зависимости от того, сколько раз и где они встречаются (в заголовке страницы, в начале или в конце страницы, в ссылке, в метатэге и т.п.). В результате формируется файл, содержащий индекс, который может быть довольно большим. Для уменьшения его размеров прибегают к минимизации объема информации и сжатию файла, а также решают задачи определения дубликатов и «почти дубликатов». Результаты индексирования записываются в базу данных (БД) проиндексированных документов (рис.1).
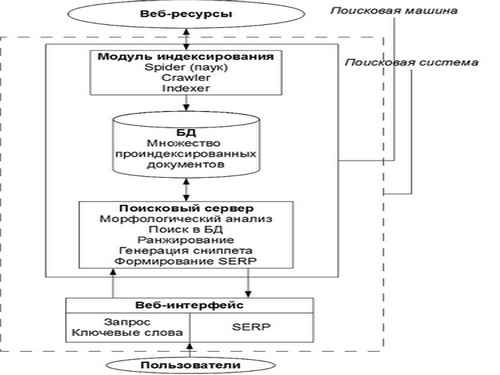
Рисунок 1 – Этапы работы поисковой системы
Разработка СЯС состоит из ряда интеллектуальных, трудноформализуемых этапов и процедур, для реализации которых необходимы большие временные и человеческие ресурсы. Этапы традиционного подхода к созданию СЯ представлены на рис 2.
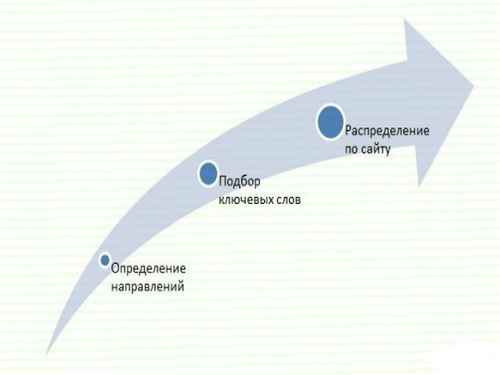
Рисунок 2 – Этапы создания семантического ядра
На первом этапе необходимо определиться с основными направлениями сайта, выбрать его тип (интернет–магазин, новостной блог, сайт–визитка и пр.), тематику, структуру, целевую аудиторию и необходимость обратной связи с пользователями. Следующим этапом будет создание первичного списка запросов, по которым будет устанавливаться список ключевых слов.
Второй этап наиболее трудоемкий. Все запросы, вводимые пользователями в поисковые системы, можно условно разделить на:
• высокочастотные (ВЧ);
• среднечастотные (СЧ);
• низкочастотные (НЧ).
Запрос относят в ту или иную группу в зависимости от того, как часто пользователи набирают его в поисковых системах. Определенных рамок и границ, отделяющих ВЧ от СЧ, а СЧ от НЧ запросов, не существует. Они сильно зависят от тематики, но обычно считают низкочастотными те запросы, которые набирают до 500-700 раз в месяц; среднечастотными – до 1–2 тысяч раз в месяц; высокочастотными – свыше 2 тысяч раз в месяц [18].
При составлении семантического ядра сайта нельзя использовать только частотность того или иного слова. Необходимо также определить, насколько тяжело будет конкурировать при продвижении по данному запросу. Поэтому стоит ввести еще три группы запросов:
• высококонкурентные (ВК);
• среднеконкурентные (СК);
• низкоконкурентные (НК).
Если определить частотность слов довольно просто, то степень их конкурентности оценить зачастую крайне трудно. Исходя из этого часто считают высокочастотные и высококонкурентными запросами, среднечастотные – среднеконкурентными, а низкочастотные – низкоконкурентными. Однако это не всегда верно, так как в некоторых тематиках даже НЧ запросы бывают сильно востребованы, и бывает обратная ситуация (но намного реже) – по СЧ, по которым очень легко выйти в ТОП. Чаще всего это слова, написанные с ошибками, или очень специфичные запросы, представляющие собой URL–адрес известного ресурса (например, yandex.ru).
При отборе запросов также необходимо учитывать их категорию:
1. Первичные запросы – запросы, характеризующие ресурс «в общем», являющиеся наиболее общими в тематике сайта. Например для блога по seo первичными запросами являются: создание сайта, продвижение сайта, раскрутка сайта, заработок на сайте, заработок в интернете и т.д.;
2. Основные запросы – запросы, которые будут входить в список СЯ, те, по которым целесообразно продвижение. Для предыдущего случая: как раскрутить блог, как создать блог, какой создать сайт для заработка, обмен постовыми и т.д.;
3. Ассоциативные (вспомогательные) запросы – запросы, которые также набирались людьми, вводящими основные запросы. Они чаще всего бывают схожи с основными запросами. Например, для запроса СЕМАНТИЧЕСКОЕ ЯДРО САЙТА ассоциативными будут продвижение сайта в поисковых системах, внутренняя оптимизация, сео.
Запросы источники ключевых слов для создания семантического ядра приведены на рис.3.
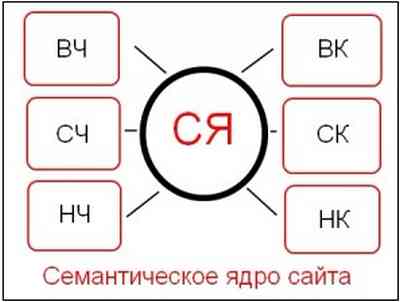
Рисунок 3 – Источники ключевых слов для семантического ядра
Для начала можно ограничиться 100-200 запросами. Далее производится отсев неподходящих слов. Нужно удалить те слова, по которым точно не будет продвигаться сайт. Как правило таких слов больше половины. Также производится отсев высококонкурентных запросов, по которым продвижение нереально. В итоге отсеивается три слова из четырех, если не больше.
На третьем этапе производится распределение списка запросов по страницам сайта. Ключевые слова с наибольшей частотой помещают в метатэги keywords, с меньшей – распределяют по контенту сайта. Более конкурентные запросы лучше оставить на главной странице сайта, а менее конкурентные нужно сгруппировать по смыслу и распределить по другим страницам ресурса. Целесообразно создать документ в Exel, разбить ключевые слова по страницам, подобрать ассоциативные слова. Для блога можно придерживаться схемы: 5–12 среднеконкурентных слов – на главную; 1 СЧ + 2-3 НЧ + 2-3 вспомогательных (ассоциативных) – на внутреннюю.
Общепринятый алгоритм построения семантического ядра приведен на рис. 4.

Рисунок 4 – Традиционный алгоритм создания семантического ядра сайта
(анимация: 7 кадров, 7 циклов повторения, 123 Кб)
6.Алгоритм формирования семантического ядра для сайтов с динамическим контентом
Для сокращения времени разработки и обновления СЯС с динамическим контентом без потери полноты и точности можно использовать анализ связей (link analysis), позволяющий сгенерировать правила количественного описания взаимной связи между двумя и более ключевыми словами, объединенными в одном семантическом запросе. Такие правила в терминах анализа связей называются ассоциативными, а запрос представляет собой некоторое множество событий, происходящих совместно, и образует транзакцию.
Для поиска закономерности между событиями, то есть запросами пользователей используется база поисковых транзакций (БПТ), БПТ представляет собой таблицу, каждая запись которой содержит номер транзакции и список ключевых слов, составивших запрос во время этой транзакции.
Алгоритм автоматизации разработки и обновления СЯ на основе применения анализа связей к базе поисковых транзакций можно представить в виде последовательности следующих шагов:
1. Оценка контента сайта и исследование поисковых тенденций для определения первичного списка поисковых транзакций;
2. С помощью средств статистики поисковых систем формирование списка ассоциированных запросов с указанной частотой ключевых слов;
3. Формирование базы поисковых транзакций (БПТ) заданного вида на основании списка ассоциированных запросов;
4. Поиск популярных наборов в БПТ и формирование базы популярных поисковых транзакций (БППТ);
5. На основе БППТ формирование базы возможных импликаций типа «условие > следствие», расчет их поддержки и достоверности и формирование базы ассоциативных правил;
6. Формирование МЕТА-тэгов (Title, Description, Keywords) и модификация контента сайта.
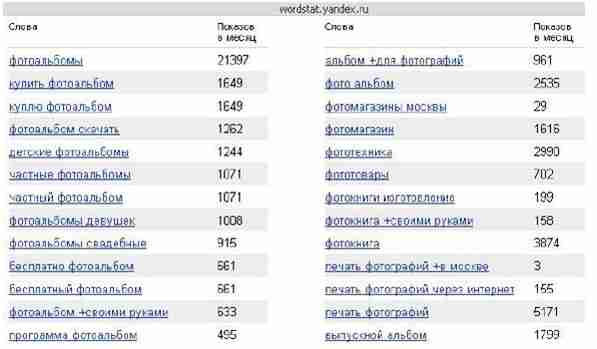
Рисунок 5 – Пример списка ассоциированных запросов с указанной частотой ключевых слов
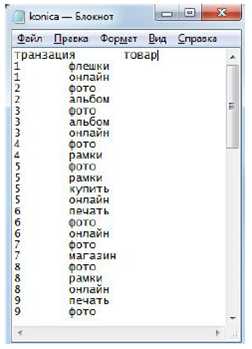
Рисунок 6 – Пример базы поисковых транзакций (БПТ)
7. Направления дальнейших исследований
Для реализации 4 и 5 этапов алгоритма предполагается использовать методы «Data Mining», реализованные в аналитическом приложении Deductor Academic [19].
Выводы
Реализация алгоритма разработки СЯ сайтов с динамическим контентом позволит поднять позиции в выдачах поисковых систем для разных типов запросов за счет автоматизированного формирования атрибута content мета тэгов keywords на основе АП, полученных из транзакционной базы популярных поисковых транзакций. Алгоритм разработки СЯ является достаточно универсальным и может быть применен для эффективного продвижения сайтов с динамическим контентом специалистами по SEO.
Список литературы
1 Паклин Н.Б. Бизнес-аналитика: от данных к знаниям / Н.Б. Паклин, В.И. Орешков. – СПб.: Питер, 2009. – 624 с.
2. Chung D. Suchmaschinen-Optimierung: Der schnell Einstieg / D. Chung, A. Klunder. – Heidelberg: REDLINE/mitp, 2007. – 224 S.
3. Сирович Дж., Дари Кр. Поисковая оптимизация на PHP для профессионалов. Руководство разработчика по SEO. = Professional Search Engine Optimization with PHP: A Developer's Guide to SEO. M.: Диалектика, Вильяме, 2008. - 352 с.
4. Байков В. Д. Интернет. Поиск информации. Продвижение сайтов. — СПб.: БХВ-Петербург, 2000. 288 с.
5. Колисниченко Д. Н. Поисковые системы и продвижение сайтов в Интернете. М.: Диалектика, 2007. - 272 с.
6. Евдокимов Н. В. Раскрутка Web-сайтов. Эффективная Интернет-коммерция. М.: Вильяме, 2007. - 160 с.
7. Евдокимов Н., Лебединский И. Раскрутка веб-сайта. Практическое руководство. М.: Вильяме, 2011. - 288 с.
8. Евдокимов Н.В. Основы контентной оптимизации. Эффективная интернет-коммерция и продвижение сайтов в интернет. М.: Вильяме, 2007. - 160 с.
9. Ашманов И.С., Иванов A.A. Оптимизация и продвижение сайтов в поисковых системах. СПб.: Питер, 2009. - 400 с.
10. Яковлев А. А. Раскрутка и продвижение сайтов: основы, секреты,трюки. СПб.: БХВ-Петербург, 2007. - 336 с.ч
11. Яковлев А., Ткачев В. Раскрутка сайтов. Основы, секреты, трюки. -СПб.: БХВ-Петербург, 2010. 352 с.
12. Agrawal R., Srikant R. Searching with numbers // In Proceedings of the eleventh international conference on World Wide. ACM Press, 2002.
13. Aizawa A. The feature quantity: an information theoretic perspective of tfldf-like measures // In Proceedings of the 23rd annual international ACM SIGIR conference on Research and development in information retrieval.
14. Тероу Ш. Видимость в Интернете. Поисковая оптимизация сайтов. = Search Engine Visibility. Б. м.: Символ-Плюс, 2009. - 288 с.
15. Арсирий Е.А., Игнатенко О.А., А.А. Леус Разработка семантического ядра сайта с динамическим контентом на основе ассоциативных правил // 2012, Том 2, №1
16. Павленко А. И. Ранжирование факторов продвижения интернет-магазина с помощью аппарата мультимножеств// реферат выпускной работы магистра Факультет вычислительной техники и информатики ДонНТУ. 2009.
17. Халыгов А. А. Методы повышения скорости ранжирования сайтов в поисковой системе Google// реферат выпускной работы магистра Факультет вычислительной техники и информатики ДонНТУ. 2013.
18. Как составить семантическое ядро сайта [Электроний-ресурс]. – Режим доступа: great-world.ru
19. Deductor Academic [Электроний-ресурс]. – Режим доступа: basegroup.ru
Важное замечание
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2014 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.