
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі дослідження
- 3. Очікувана наукова новизна
- 4. Огляд досліджень та розробок по темі
- 4.1 Глобальний рівень
- 4.2 Національний рівень
- 4.3 Локальний рівень
- 5. Аналіз методів розрахування рекомендацій
- 6. Коллаборативна фильтрація
- Висновки
- Список джерел
Вступ
Сучасний Інтернет-простір надає користувачеві величезну кількість різноманітної інформації, у якій стає усе складніше орієнтуватися, тому застосування класичних засобів пошуку й систематизації не може повністю задовольнити потреби користувача: неможливо переглянути всі матеріали, щоб вибрати для себе відповідні. У зв'язку із цим стало з'являтися усе більше так званих систем рекомендацій, які орієнтовані на надання інформації, що найбільше повно задовольняє інтереси користувача, що й найбільше повно відповідає його запиту.
1. Актуальність теми
Системи рекомендацій — це програми, які намагаються передбачити, які об'єкти (книги, фільми, музика, веб-сайти) можуть сподобатися користувачеві, маючи певну інформацію про його профіль.
Такі програми використовуються, як правило, у комерційних цілях (у першу чергу, в Інтернет-магазинах, або на спеціалізованих сайтах "по інтересах" з метою пропозиції товарів). З іншого боку, актуальним завданням є інтелектуалізація самого процесу пошуку в Інтернеті. Багато користувачів Інтернету об'єктивно вважають, що сучасні можливості пошукових систем не дозволять їм знайти необхідні документи або дані. Для такої думки користувачів всесвітньої мережі є наступні передумови:
— вибуховий ріст обсягів доступних суспільству даних взагалі (збільшення числа книг, фільмів, новин, рекламних повідомлень та ін.);
— збільшення обсягу онлайнових даних;
— реальний обсяг інформації, що оточує людину, значно вище того, що він може реально пропустити через себе, щоб виявити необхідну й достатню, а також таку, що сподобалася йому.
Системи рекомендацій актуально використовувати для інтернет-магазинів. Це дозволить користувачеві рекомендувати популярний, якісний товар котрий може його зацікавити, або при відсутності якого-небудь товару на складі порадити йому аналог запитуваної продукції.
2. Мета і задачі дослідження
Ціль роботи полягає в розробці й дослідженні алгоритмічного забезпечення інтелектуальної системи формування рекомендацій на основі методів коллаборативної фільтрації.
Для досягнення поставленої мети необхідно розв'язати наступні завдання:
- розглянути існуючі методи розрахунків рекомендацій і довести вибір методів заснованих на коллаборативній фільтрації;
- проаналізувати заходи близькості (подібності) користувачів;
- удосконалити алгоритм розрахунків рекомендацій.
3. Очікувана наукова новизна
Модифікований алгоритм розрахунків рекомендацій на основі методів коллаборативної фільтрації: матриця оцінок буде не двовимірна, а чотиривимірна. У ній крім об'єктів і користувачів буде ще 2 параметра: час і геолокація. Час буде показувати який проміжок часу користувачі витрачали на перегляд того або іншого об'єкта, а геолокація буде відповідати за доцільно замовлений товар (якщо немає товару на складі у твоєму місті чи варто замовляти його з іншого кінця країни). Запропонований алгоритм може бути впроваджений у будь-який інтернет магазин, для поліпшення його роботи й надання більш точної інформації його відвідувачів.
4. Огляд досліджень та розробок по темі
4.1 Глобальний рівень
На ранніх стадіях еволюції інтернет-магазинів не було як такої системи рекомендацій товарів користувачам. Але конкуренція й бажання стати кращим зробило великий стрибок у сфері систем рекомендацій, це вплинуло на розробку більшого числа рекомендаційних сервісів для сайтів будь-якої спрямованості.
Аналіз клієнтських середовищ: виявлення схованих профілів і оцінювання подібності клієнтів і ресурсів проводилися В.А. Лексиным. У них розглядалися алгоритми схожості користувачів і надання інформації, яка могла б їх зацікавити.
Сфера застосування систем рекомендацій дуже поширена в інтернеті. От кілька відомих прикладів використання таких систем:
На amazon.com і багатьох інших інтернет-магазинах при вибиранні товару можна побачити список товарів, які купували користувачі, які раніше купили обраний вами товар. З його допомогою, покупець може швидко знайти товар, схожий на той, що йому сподобався. Така система добре працює з товарами, що доповнюють один одного, але вона чи навряд зможе запропонувати користувачеві альтернативний вибір.
Last.fm — музичний сайт, який використовує програму Audioscrobbler. Один з моїх улюблених прикладів. Усе, що потрібно від користувача — це встановити програму на свій комп'ютер, і вона буде автоматично аналізувати музику, яку слухає користувач, і давати йому ради. Саме через слово "автоматично" я її й люблю: вона може працювати у фоновому режимі й користувачеві не треба робити ніяких зайвих дій.
Деякі інформаційні ресурси, такі як digg.com (Digg Recommendation Engine) і сам habrahabr.ru використовують систему рекомендацій для визначення того, які статті й новини можуть бути цікаві конкретному користувачеві. Такі системи аналізують безліч непрямих і явних проявів інтересу користувача, такі як перегляд новин, голосування й занесення в "вибране". Важливо, щоб такі системи використовували не тільки явні прояви інтересу, особливо, якщо вони обмежені, але й усі можливі неявні фактори.
4.2 Національний рівень
На національному рівні роботи з дослідження методу коллаборативної фільтрації ведуться в Приазовському державному технічному університеті автором Е.Е. Пятикоп. Автором запропоновані його дослідження над алгоритмом коллаборативної фільтрації на основі подібності елементів.
4.3 Локальний рівень
У Донецькому Національному Технічному Університеті вивченням алгоритмів для підвищення ефективності інтелектуального аналізу web-контенту займається Арбузова Ольга Володимирівна [9].
5. Аналіз методів розрахування рекомендацій
У розглянутих нижче алгоритмах систем рекомендацій використовуються наступні визначення.
Об'єкт — це пісня, фільм, товар, користувач (у випадку рекомендації друзів). Тобто, те, що споживають користувачі системи рекомендацій. Це те, що їм потрібно рекомендувати.
Користувач — це людина, зареєстрована у системі, він може купувати, слухати, дивитися, оцінювати об'єкти й користуватися сервісом рекомендації.
Рекомендація — це об'єкт або кілька об'єктів, які система рекомендації видає користувачеві.
Система рекомендацій дозволяє людині позначити свої смаки й повертає результати, цікаві для нього, базуючись на оцінках інших користувачів і своїх припущеннях [1,3].
На відміну від пошукових систем, для одержання від системи відповіді не потрібно чіткого завдання запиту. Замість цього користувачеві пропонується оцінити деякі об'єкти з колекції, і на підставі цих його оцінок і порівняння їх з оцінками попередніх користувачів будуються припущення про смаки користувача й повертаються найбільше близькі до них результати, формуючи для нього персоналізовану видачу [8].
У якості набору оцінюваних об'єктів можуть, приміром, виступати: каталог посилань на веб-сайти, стрічка новин, товари в електронному магазині, колекція книг у бібліотеці й т.п. У сферу застосування подібних систем входять і ситуації, коли користувач не шукає інформацію з конкретного ключового слова, а, приміром, прагне одержати список сучасних статей, схожих по тематиці на ті, які він переглядав до цього. Залежно від того, які дані використовуються для розрахунків рекомендацій, системи діляться на три великі класи:
— Методи коллаборативної фільтрації
— Методи, що аналізують вміст об'єктів
— Методи, засновані на знаннях
Методи коллаборативної фільтрації кожного користувача системи просять висловити свою думку, виражену в певному чисельному значенні на деякій шкалі градації щодо запропонованого йому ряду об'єктів. Цими об'єктами можуть бути різні споживчі товари, світлини, статті, музичні добутки, кінофільми, телепередачі, комп'ютерні ігри і так далі. У міру того як у базі системи коллаборативної фільтрації набирається усе більше й більше зібраних оцінок, відбуваються наступні важливі речі: — система починає реально розуміти, як виглядають власні переваги кожного окремого користувача цієї системи; — система починає поєднувати користувачів у групи по схожості їх інтересів і ділитися персональним складом груп із самими користувачами, що входять у ці групи; — система стає здатною дати персональну рекомендацію кожному конкретному користувачеві відносно об'єктів, з якими він поки не зустрічався. Це відбувається на підставі логіки виду. Якщо ви оцінюєте це, це й це так-те, так-то й так-те, але не знаєте поки чогось нового, а люди, дуже схожі на вас за своїми оцінками, оцінили це нове от так, то я запропоную вам це нове, тому що я певен, що ви з високим ступенем імовірності оціните це нове для себе так само, як і ті, чиї попередні переваги збігаються з вашими, що інтереси користувачів представлені оцінками, які вони дають об'єктам після перегляду, покупки і т.д. Основна ідея даних методів полягає в порівнянні між собою інтересів різних користувачів або об'єктів на основі цих оцінок. При цьому ніякої додаткової інформації про самих користувачів і об'єктах не використовується [2].
Методи другого класу, навпаки, використовують вміст об'єктів для одержання рекомендацій. Ці методи працюють у тих випадках, коли вміст об'єктів презентовано у вигляді текстів. Вони добре підходять для рекомендації книг. Також їх можна використовувати для порівняння назв, описів і іншої текстової інформації, доступної у фільмах, піснях, товарах і т.і.
Методи, засновані на знаннях, вимагають від користувача описати свої вимоги до потрібних йому об'єктів. А потім шукають із використанням своєї бази знань об'єкти, що задовольняють поставленим вимогам [5].
6. Коллаборативна фильтрація
Для розв'язку завдань поставлених у роботі пропонується використовувати метод коллаборативної фільтрації, тому розглянемо цей метод більш детально.

Рисунок 1 — Принцип дії коллаборативної фільтрації
(анімация: 17 кадрів, 5 ціклів повторення, 260 кілобайт)
Коллаборативна фільтрація (Collaborative filtering) — це метод рекомендації, при якому аналізується тільки реакція користувачів на об'єкти. Користувачі залишають у системі оцінки об'єктів. Причому, оцінки можуть бути як явні (наприклад, оцінка по пятибальній шкалі), так і неявні (наприклад, кількість переглядів одного ролика). Кінцевою метою методу є як можна більш точне передбачення оцінки, яку поставив би поточний користувач системи раніше неоціненим їм об'єктам. Чим більше оцінок збирається, тим точніше виходять рекомендації. Виходить, користувачі допомагають один одному у фільтрації об'єктів. Тому такий метод називається також спільною фільтрацією [4].
Нехай у системі є користувачі й об'єкти. Нехай деякі користувачі оцінили деякі об'єкти. І нехай оцінка — це натуральне число від 1 до 5. Тоді всі оцінки можна зобразити у вигляді матриці. Стовпці в матриці це користувачі, а рядки – об'єкти
Нехай є користувач а. Наше завдання — передбачити, яку оцінку поставив би користувач а об'єкту i. Будемо розглядати тільки користувача а й тих користувачів, які оцінили об'єкт i. Алгоритм містить у собі 3 кроки:
Для кожного користувача u обчислимо, наскільки його інтереси збігаються з інтересами користувача а;
Після цього виберемо безліч користувачів, найбільше близьких до а;
Передбачимо оцінку на основі оцінок об'єкта i "сусідами" з попереднього кроку.
Перший крок. Кожному користувачеві в матриці R відповідає один рядок. Тому будемо обчислювати близькість векторів-рядків користувачів.
Існує безліч способів підрахунку близькості векторів. Один з найпростіших — порахувати косинус між цими векторами:
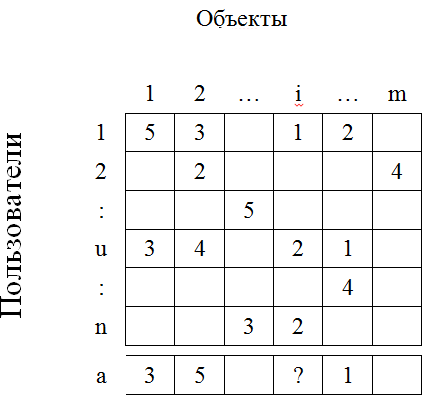
Рисунок 2 – Матриця оцiнок
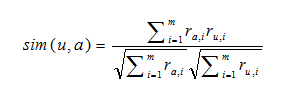
Тут sim (u,a) — захід близькості (подібності) користувачів а й u. r u, i — значення матриці R: u рядок, i стовбець. sim(u,a) ухвалює значення з відрізка [0,1]. Якщо користувач не вказав оцінку для якогось об'єкта значення, що відповідає матриці, рівно 0.
Також часто використовується коефіцієнт кореляції Пирсона, захід близькості Дайса, а також інші заходи близькості.
Другий крок. Тепер потрібно вибрати безліч K найбільш схожих на а користувачів. Є кілька способів вибору. Найчастіше фіксується ціла константа к. Потім усі користувачі сортуються по убуванню заходу близькості. І в безліч K входять перші к користувачів, найбільше близьких до а.
Третій крок. Маючи безліч K близьких користувачів, потрібно обчислити оцінку, яку поставив би користувач а об'єкту i. Нагадаємо, що розглядаються тільки ті користувачі, які оцінили об'єкт i.
Нужная оценка вычисляется по формуле:

p a, i — це оцінка, що передвіщається, користувача а для об'єкта i. Вона являє собою середнє по всіх користувачах з безлічі K. Використовуються ваги: чому ближче користувач u до користувача а (згідно з мірою близькості sim a,u), обчисленої на першому кроці), тем сильніше його внесок у пророкування оцінки [6,7].
Таким чином, описаний алгоритм пророкує оцінки для об'єктів, які поточний користувач ще не оцінив. Для того, щоб зробити рекомендацію для даного користувача, досить передбачити оцінки для всіх неоцінених об'єктів і вибрати об'єкти з найбільшою передвіщеною оцінкою.
Висновки
У даній роботі були коротко викладені основні алгоритми, використовувані в системах рекомендацій. Різні методи використовують різні дані про користувачів і про об'єкти. Кожний підхід має свої гідності й недоліки. Наприклад, метод коллаборативної фільтрації рекомендує об'єкти, не маючи ніякого уявлення про те, що вони собою представляють. Проблему рекомендації нових об'єктів вирішують методи аналізу вмісту. Але для їхньої гарної роботи потрібні текстові дані про об'єкти. Якщо інформації про користувачів, об'єкти й оцінки недостатньо для цих алгоритмів, застосовуються методи, що використовують бази знань. При цьому інтерактивно виявляються вимоги користувача.
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2014 року. Повний текст роботи й матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.
Список джерел
- Jannach D., Zanker M., Felfernig A., Friedrich G. Recommender Systems / An Introduction. New York: Cambridge University Press 32 Avenue of the Americas, — 2011. — 352 p.
- Гомзин А., Коршунов А. Системы рекомендаций: обзор современных подходов // Препринт. Москва: Труды Института системного программирования РАН. 2012. 20 c.
- Melville P., Sindhwani V. Recommender systems. Encyclopedia of Machine Learning. — 2010.
- Su X., MagyhT. Khoshgoftaar Survey of Collaborative Filtering Techniques / Advances in Artificial Intelligence. — 2009.
- Ansari A., Essegaier S., Kohli R., “Internet Recommendations Systems,” / J. Marketing Research, — Aug. 2000. — pp. 363–375.
- Resnick P., Iacovou N., Sushak M., Bergstrom P., Riedl J. "GroupLens: An Open Architecture for Collaborative Filtering of Netnews," / Proceedings of the 1994 Computer Supported Cooperative Work Conference, ACM, — 1994.
- Konstan J., Miller B., Maltz D., Herlocker J., Gordon L., RiedlJ. "GroupLens: Collaborative Filtering for Usenet News," / to appear in Communications of the ACM special issue on collaborative filtering, — March 1997.
- Miller B., Riedl J., Konstan J. "Experiences with GroupLens: Making Usenet Useful Again," / Proceedings of the Usenix 1997 Winter Technical Conference, Anaheim, CA, — January 1997.
- Арбузова О.В. Разработка и исследование алгоритмов для повышения эффективности интеллектуального анализа web-контента // реферат выпускной работы магистра Факультет вычислительной техники и информатики ДонНТУ. 2013.