
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования
- 3. Предполагаемая научная новизна
- 4. Обзор исследований и разработок
- 4.1 Обзор международных источников
- 4.2 Обзор национальных источников
- 4.3 Обзор локальных источников
- 5. Анализ методов расчёта рекомендаций
- 6. Коллаборативная фильтрация
- Выводы
- Список источников
Введение
Современное Интернет-пространство предоставляет пользователю огромное количество разнообразной информации, в которой становиться все сложнее ориентироваться, поэтому применение классических средств поиска и систематизации не может полностью удовлетворить потребности пользователя: невозможно просмотреть все материалы, чтобы выбрать для себя подходящие. В связи с этим стало появляться все больше так называемых систем рекомендаций, которые ориентированы на предоставление информации, наиболее полно удовлетворяющую интересы пользователя и наиболее полно отвечающую его запросу.
1. Актуальность темы
Системы рекомендаций — это программы, которые пытаются предсказать, какие объекты (книги, фильмы, музыка, веб-сайты) могут понравиться пользователю, имея определенную информацию о его профиле.
Такие программы используются, как правило, в коммерческих целях (в первую очередь, в Интернет-магазинах, либо на специализированных сайтах «по интересам» с целью предложения товаров). С другой стороны, актуальной задачей является интеллектуализация самого процесса поиска в Интернете. Многие пользователи Интернет объективно полагают, что современные возможности поисковых систем не позволят им найти необходимые документы или данные. Для такого мнения пользователей всемирной сети имеются следующие предпосылки:
— взрывной рост объёмов доступных обществу данных вообще (увеличение числа книг, фильмов, новостей, рекламных сообщений и пр.);
— увеличение объема онлайновых данных;
— реальный объём информации, окружающей человека, значительно выше того, что он может реально пропустить через себя, чтобы обнаружить необходимую и достаточную, а также понравившуюся ему.
Системы рекомендаций актуально использовать для интернет-магазинов. Это позволит пользователю рекомендовать популярный, качественный товар который может его заинтересовать, либо при отсутствии какого либо товара на складе посоветовать ему аналог запрашиваемой продукции.
2. Цель и задачи исследования, планируемые результаты
Цель работы состоит в разработке и исследовании алгоритмического обеспечения интеллектуальной системы формирования рекомендаций на основе методов коллаборативной фильтрации.
Для достижения поставленной цели необходимо решить следующие задачи:
- рассмотреть существующие методы формирования рекомендаций и обосновать целесообразность использования методов основанных на коллаборативной фильтрации;
- обосновать выбор меры близости (похожести) пользователей;
- провести анализ наиболее популярных разработок модифицирования алгоритма коллаборативной фильтрации на основе четырехмерной матрицы оценок.
3. Предполагаемая научная новизна
Модифицированный алгоритм расчёта рекомендаций на основе методов коллаборативной фильтрации: матрица оценок будет не двумерная а четырехмерная. В ней кроме объектов и пользователей будет ещё 2 параметра: время и геолокация. Время будет показывать какой промежуток времени пользователи тратили на просмотр того или иного объекта, а геолокация будет отвечать за целесообразно заказывать товар (если нет товара на складе в твое городе стоит ли заказывать его с другого конца страны). Предлагаемый алгоритм может быть внедрен в любой интернет магазин, для улучшение его работы и предоставления более точной информации его посетителей.
4. Предполагаемая научная новизна
4.1 Обзор международных источников
На ранних стадиях эволюции интернет магазинов не было как таковой системы рекомендаций товаров пользователям. Но конкуренция и желание стать лучшим дало большой скачок в сфере систем рекомендаций, это повлияло на разработку большего числа рекомендательных сервисов для сайтов любой направленности.
Анализ клиентских сред: выявление скрытых профилей и оценивание сходства клиентов и ресурсов проводились В.А. Лексиным. В них рассматривались алгоритмы схожести пользователей и предоставления информации которая могла бы их заинтересовать.
Сфера применения систем рекомендаций очень широкая в интернете. Вот несколько известных примеров использования таких систем:
На amazon.com и многих других интернет магазинах при выборе товара можно увидеть список товаров, которые покупали пользователи, которые ранее купили выбранный вами товар. С его помощью, покупатель может быстро найти товар, похожий на тот, что ему приглянулся. Такая система хорошо работает с дополняющими друг-друга товарами, но она вряд ли сможет предложить пользователю альтернативный выбор.
Last.fm — музыкальный сайт, который использует программу Audioscrobbler. Один из моих любимых примеров. Все, что требуется от пользователя — это установить программу на свой компьютер, и она будет автоматически анализировать музыку, которую слушает пользователи, и давать ему советы. Именно из-за слова «автоматически» я ее и люблю: она может работать в фоновом режиме и пользователю не надо делать никаких лишних действий.
Некоторые информационные ресурсы, такие как digg.com (Digg Recommendation Engine) и сам habrahabr.ru используют систему рекомендаций для определения того, какие статьи и новости могут быть интересны конкретному пользователю. Такие системы анализируют множество косвенных и явных проявлений интереса пользователя, такие как просмотр новостей, голосование и занесение в «избранное». Важно, чтобы такие системы использовали не только явные проявление интереса, особенно, если они ограничены, но и все возможные неявные факторы.
4.2 Обзор национальных источников
На национальном уровне работы по исследованию метода коллаборативной фильтрации ведутся в Приазовском государственном техническом университете автором Е.Е. Пятикоп. Автором предложены его исследований над алгоритмом коллаборативной фильрации на основе сходства элементов.
4.3 Обзор локальных источников
В Донецком Национальном Техническом Университете изучением алгоритмов для повышения эффективности интеллектуального анализа web-контента Арбузова Ольга Владимировна [9].
5. Анализ методов расчёта рекомендаций
В рассмотренных ниже алгоритмах систем рекомендаций используются следующие определения.
Объект — это песня, фильм, товар, пользователь (в случае рекомендации друзей). Т.е. то, что потребляют пользователи системы рекомендаций. Это то, что им нужно рекомендовать.
Пользователь — это человек, зарегистрированный в системе, он может покупать, слушать, смотреть, оценивать объекты и пользоваться сервисом рекомендации.
Рекомендация — это объект или несколько объектов, которые система рекомендации выдает пользователю.
Система рекомендаций позволяет человеку обозначить свои вкусы и возвращает результаты, любопытные для него, базируясь на оценках других пользователей и своих предположениях [1,3].
В отличие от поисковых систем, для получения от системы ответа не требуется четкого задания запроса. Вместо этого пользователю предлагается оценить некоторые объекты из коллекции, и на основании этих его оценок и сравнения их с оценками предыдущих пользователей строятся предположения о вкусах пользователя и возвращаются наиболее близкие к ним результаты, формируя для него персонализированную выдачу [8].
В качестве набора оцениваемых объектов могут, к примеру, выступать: каталог ссылок на веб-сайты, лента новостей, товары в электронном магазине, коллекция книг в библиотеке и т.п. В сферу применения подобных систем входят и ситуации, когда пользователь не ищет информацию по конкретному ключевому слову, а, к примеру, хочет получить список современных статей, похожих по тематике на те, которые он просматривал до этого. В зависимости от того, какие данные используются для расчета рекомендаций, системы делятся на три больших класса:
— Методы коллаборативной фильтрации
— Методы, анализирующие содержимое объектов
— Методы, основанные на знаниях
Методы коллаборативной фильтрации каждого пользователя системы просят высказать свое мнение, выраженное в определенном численном значении на некоторой шкале градации относительно предъявляемого ему ряда объектов. Этими объектами могут быть различные потребительские товары, фотографии, статьи, музыкальные произведения, кинофильмы, телепередачи, компьютерные игры и так далее. По мере того как в базе системы коллаборативной фильтрации набирается все больше и больше собранных оценок, происходят следующие важные вещи: — система начинает реально понимать, как выглядят собственные предпочтения каждого отдельного пользователя этой системы; — система начинает объединять пользователей в группы по схожести их интересов и делится персональным составом групп с самими пользователями, входящими в эти группы; — система становится способной дать персональную рекомендацию каждому конкретному пользователю в отношении объектов, с которыми он пока не сталкивался. Это происходит на основании логики вида Если вы оцениваете это, это и это так-то, так-то и так-то, но не знаете пока чего-то нового, а люди, очень похожие на вас по своим оценкам, оценили это новое вот так, то я предложу вам это новое, потому что я уверен, что вы с высокой степенью вероятности оцените это новое для себя так же, как и те, чьи предыдущие предпочтения совпадают с вашими. что интересы пользователей представлены оценками, которые они дают объектам после просмотра, покупки и т.д. Основная идея данных методов заключается в сравнении между собой интересов различных пользователей или объектов на основе этих оценок. При этом никакой дополнительной информации о самих пользователях и объектах не используется [2].
Методы второго класса, наоборот, используют содержимое объектов для получения рекомендаций. Эти методы работают в тех случаях, когда содержимое объектов представлено в виде текстов. Они хорошо подходят для рекомендации книг. Также их можно использовать для сравнения названий, описаний и другой текстовой информации, доступной у фильмов, песен, товаров и т.д.
Методы, основанные на знаниях, требуют от пользователя описать свои требования к нужным ему объектам. А затем ищут с использованием своей базы знаний объекты, удовлетворяющие поставленным требованиям [5].
6. Коллаборативная фильтрация
Для решения задач поставленных в работе предлагается использовать метод коллаборативной фильтрации, поэтому рассмотрим этот метод более детально.

Рисунок 1 — Принцип действия коллаборативной фильтрации
(анимация: 17 кадров, 5 циклов повторения, 260 килобайт)
Коллаборативная фильтрация (Collaborative filtering) — это метод рекомендации, при котором анализируется только реакция пользователей на объекты. Пользователи оставляют в системе оценки объектов. Причем, оценки могут быть как явные (напри¬мер, оценка по пятибальной шкале), так и неявные (например, количество просмотров одного ролика). Конечной целью метода является как можно более точное предсказание оценки, которую поставил бы текущий пользователь системы ранее неоцененным им объектам. Чем больше оценок собирается, тем точнее получаются рекомендации. Получается, пользователи помогают друг другу в фильтрации объектов. Поэтому такой метод называется также совместной фильтрацией [4].
Пусть в системе есть пользователи и объекты. Пусть некоторые пользователи оце¬нили некоторые объекты. И пусть оценка - это натуральное число от 1 до 5. Тогда все оценки можно изобразить в виде матрицы. Столбцы в матрице это пользователи, а строки — объекты.
Пусть имеется пользователь а. Наша задача — предсказать, какую оценку поставил бы пользователь а объекту i. Будем рассматривать только пользователя а и тех пользователей, которые оценили объект i. Алгоритм включает в себя 3 шага:
Для каждого пользователя u вычислим, насколько его интересы совпадают с ин¬тересами пользователя а;
После этого выберем множество пользователей, наиболее близких к а;
Предскажем оценку на основе оценок объекта i соседями
из предыдущего шага.
Первый шаг. Каждому пользователю в матрице R соответствует одна строка. Поэтому будем вычислять близость векторов-строк пользователей.
Существует множество способов подсчета близости векторов. Один из самых простых — посчитать косинус между этими векторами:
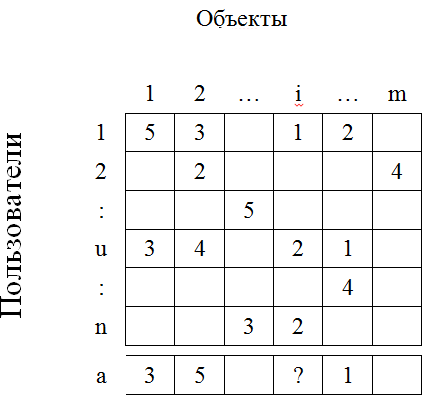
Рисунок 2 – Матрица оценок
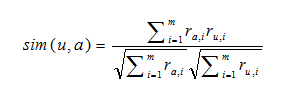
Здесь sim(u,a) — мера близости (похожести) пользователей а и u. ru,i — значение матрицы R: u строка, i столбец. sim(u,a) принимает значения из отрезка [0,1]. Если пользователь не указал оценку для какого-то объекта, соответствующее значение матрицы равно 0.
Также часто используется коэффициент корреляции Пирсона, мера близости Дайса, а также другие меры близости.
Второй шаг. Теперь нужно выбрать множество K наиболее похожих на а пользователей. Есть несколько способов выбора. Чаще всего фиксируется целая константа к. Затем все пользователи сортируются по убыванию меры близости. И во множество K входят первые к пользователей, наиболее близких к а.
Третий шаг. Имея множество K близких пользователей, нужно вычислить оценку, которую поставил бы пользователь а объекту i. Напомним, что рассматриваются только те пользователи, которые оценили объект i.
Нужная оценка вычисляется по формуле:

p a,i — это предсказываемая оценка пользователя а для объекта i. Она представляет собой среднее по всем пользователям из множества K. Используются веса: чем ближе пользователь u к пользователю а (согласно мере близости sim a,u), вычисленной на первом шаге), тем сильнее его вклад в предсказание оценки [6,7].
Таким образом, описанный алгоритм предсказывает оценки для объектов, которые текущий пользователь еще не оценил. Для того, чтобы сделать рекомендацию для дан¬ного пользователя, достаточно предсказать оценки для всех неоцененных объектов и выбрать объекты с наибольшей предсказанной оценкой.
Выводы
В данной работе были кратко изложены основные алгоритмы, используемые в системах рекомендаций. Различные методы используют различные данные о пользователях и об объектах. Каждый подход имеет свои достоинства и недостатки. Например, метод коллаборативной фильтрации рекомендует объекты, не имея никакого представления о том. что они собой представляют. Проблему рекомендации новых объектов решают методы анализа содержимого. Но для их хорошей работы требуются текстовые данные об объектах. Если информации о пользователях, объектах и оценках недостаточно для этих алгоритмов, применяются методы, использующие базы знаний. При этом интерактивно выявляются требования пользователя. Чем больше доступно данных, тем баз ее точную систему рекомендации можно разработать.
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2014 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Список источников
- Jannach D., Zanker M., Felfernig A., Friedrich G. Recommender Systems / An Introduction. New York: Cambridge University Press 32 Avenue of the Americas, — 2011. — 352 p.
- Гомзин А., Коршунов А. Системы рекомендаций: обзор современных подходов // Препринт. Москва: Труды Института системного программирования РАН. 2012. 20 c.
- Melville P., Sindhwani V. Recommender systems. Encyclopedia of Machine Learning. — 2010.
- Su X., MagyhT. Khoshgoftaar Survey of Collaborative Filtering Techniques / Advances in Artificial Intelligence. — 2009.
- Ansari A., Essegaier S., Kohli R., “Internet Recommendations Systems,” / J. Marketing Research, — Aug. 2000. — pp. 363–375.
- Resnick P., Iacovou N., Sushak M., Bergstrom P., Riedl J. "GroupLens: An Open Architecture for Collaborative Filtering of Netnews," / Proceedings of the 1994 Computer Supported Cooperative Work Conference, ACM, — 1994.
- Konstan J., Miller B., Maltz D., Herlocker J., Gordon L., RiedlJ. "GroupLens: Collaborative Filtering for Usenet News," / to appear in Communications of the ACM special issue on collaborative filtering, — March 1997.
- Miller B., Riedl J., Konstan J. "Experiences with GroupLens: Making Usenet Useful Again," / Proceedings of the Usenix 1997 Winter Technical Conference, Anaheim, CA, — January 1997.
- Арбузова О.В. Разработка и исследование алгоритмов для повышения эффективности интеллектуального анализа web-контента // реферат выпускной работы магистра Факультет вычислительной техники и информатики ДонНТУ. 2013.