
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета та задачі дослідження
- 3. Передбачувана наукова новизна та практичне значення
- 4. Огляд існуючих алгоритмів скорочення розміру вибірок
- 4.1 Способи розв'язання задачі скорочення даних
- 4.2 Алгоритм STOLP
- 4.3 Алгоритм FRiS-STOLP
- 4.4 Алгоритм ДРЕТ
- 4.5 Алгоритм NNDE
- 4.6 Алгоритм LVQ
- 4.7 Алгоритм FOREL
- 5. Метод побудови вибірки w-об'єктів
- 5.1 Основні поняття
- 5.2 Опис алгоритму побудови w-об'єктів
- Висновки
- Перелік посилань
- Важливе зауваження
Вступ
З задачою розпізнавання образів живі системи, у тому числі й людина, постійно зустрічається з моменту своєї появи. Зокрема, інформація, що надходить з органів почуттів, обробляється мозком, який, у свою чергу, впорядковує інформацію, забезпечує прийняття рішення, а далі з допомогою електрохімічних імпульсів передає необхідний сигнал далі, наприклад, до органів руху, які реалізують необхідні дії. Потім відбувається зміна навколишнього оточення, і вищевказані явища відбуваються знову. І якщо розібратися, то кожен етап супроводжується розпізнаванням.
З розвитком обчислювальної техніки стало можливим вирішити низку завдань, що виникають у процесі життєдіяльності, полегшити, прискорити, підвищити якість результату. Наприклад, робота різних систем життєзабезпечення, взаємодія людини з комп'ютером, поява роботизованих систем та ін. Тим не менш, забезпечити задовільний результат у деяких задачах (розпізнавання подібних об'єктів, які швидко рухаються або рукописного тексту) сьогодні ще не вдається.
Більшість сучасних прикладних задач, які розв'язуються шляхом побудови систем розпізнавання, характеризуються великим обсягом вихідних даних, що значно знижує ефективність систем і суттєво збільшує часові витрати на виконання розпізнавання. Для скорочення вибірок великого обсягу існує метод побудови зваженої навчальної вибірки w-об'єктів, на підставі якого й будуть будуватися утворюючі множини.
1. Актуальність теми
В даний час основним науковим напрямком є дослідження і розробка алгоритмів і методів побудови програмних засобів інтелектуального аналізу даних. Актуальність даної тематики визначається наявністю ряду важливих прикладних задач, при вирішенні яких потрібно аналізувати великі обсяги даних. Більшість сучасних прикладних задач, які розв'язуються шляхом побудови систем розпізнавання, характеризується можливістю додавання нових даних в процесі роботи систем. Саме тому основними вимогами, що пред'являються до сучасних систем розпізнавання, є адаптивність (можливість системи в процесі роботи змінювати свої характеристики, а для систем розпізнавання, що навчаються – коригувати вирішальні правила класифікації, при зміні навколишнього середовища), робота в реальному часі (можливість формування рішень про класифікацію за обмежений час) і висока ефективність класифікації для лінійно раздільних і пересічних в просторі ознак класів [1, 2].
Додавання нових об'єктів призводить до суттєвого збільшення розміру навчальної вибірки, що, в свою чергу, призводить до збільшення часу коригування вирішальних правил (особливо, якщо використовуємий метод навчання вимагає побудови нового вирішального правила, а не його часткового коригування) та погіршення якості одержуваних рішень через проблеми перенавчання на вибірках великого обсягу [3]. Саме тому задача попередньої обробки даних шляхом скорочення розміру вибірки є актуальною науково-технічною задачею, що вимагає розробки сучасних підходів для її розв'язання.
2. Мета та задачі дослідження
Об'єктом дослідження є процес обробки даних в системах розпізнавання, що навчаються.
Предмет дослідження – існуючі алгоритми формування зважених вибірок в системах розпізнавання, що навчаються.
Метою випускної роботи магістра є розробка методу формування зважених вибірок в системах розпізнавання, що навчаються. В процесі роботи необхідно вирішити наступні задачі:
– дослідити існуючі алгоритми формування зважених навчальних вибірок;
– дослідити методи застосування зважених навчальних вибірок в адаптивних системах розпізнавання;
– розробити алгоритм побудови зважених навчальних вибірок в системах розпізнавання, що навчаються;
– розробити програмний продукт, що реалізує розроблений алгоритм формування зважених вибірок в системах розпізнавання, що навчаються;
– виконати порівняльний аналіз результатів роботи запропонованого алгоритму та відомих алгоритмів розв'язання даної задачі.
3. Передбачувана наукова новизна та практичне значення
Науковою новизною цієї роботи є розробка методу формування зважених навчальних вибірок в системах розпізнавання, що навчаються. Так як зростання розміру навчальної вибірки призводить до зростання часу та погіршення якості навчання, передбачається, що на основі зважених вибірок може бути побудовано ефективний алгоритм вибору підмножини об'єктів вибірки та вилучення інших.
Практичне значення роботи полягає в підвищенні ефективності класифікації в системах розпізнавання, що навчаються. Розроблений метод формування зважених вибірок може використовуватися для програмної реалізації системи класифікації для обробки результатів різноманітних соціологічних, економічних і статистичних досліджень, створення електронних бібліотек, побудови спам-фільтрів і т. д.
4. Огляд існуючих алгоритмів скорочення розміру вибірок
4.1 Способи розв'язання задачі скорочення даних
Завдання стиснення й об'єднання даних за умови незмінного словника ознак можуть бути вирішені двома способами. Перший спосіб полягає у відборі деякої множини об'єктів вихідної навчальної вибірки, кожен з яких відповідає висунутим вимогам. Найбільш відомими алгоритмами, що реалізують такий спосіб, є алгоритми STOLP [4], FRiS-STOLP [5, 6], NNDE (Nearest Neighbor Density Estimate) [7, 10, 11] і MDCA (Multiscale Data Condensation Algorithm) [7]. Другий спосіб полягає в побудові безлічі нових об'єктів, кожен з яких будується на основі інформації про деяку підмножину об'єктів вихідної навчальної вибірки й узагальнює його. До алгоритмів такого типу можна віднести, наприклад, алгоритм ДРЕТ [4], який покриває простір ознак безліччю пересічних кіл, визначаючи тим самим області, що належать кожному з класів, алгоритми LVQ (learning vector quantization) [8] і w-GridDC [9].
4.2 Алгоритм STOLP
Алгоритм STOLP – алгоритм відбору еталонних об'єктів для метричного класифікатора. Еталони – це така підмножина вибірки X L , що всі об'єкти X L (або їх більша частина) класифікуються вірно при використанні в якості навчальної вибірки безлічі еталонів. Еталонами i-го класу при класифікації методом найближчого сусіда може слугувати така підмножина об'єктів цього класу, що відстань від будь-якого належного йому об'єкта з вибірки X L до найближчого «свого» еталону менша, ніж до найближчого «чужого» еталону [4].
Вхідні дані алгоритма:
– вибірка X L;
– допустима частка помилок l0;
– поріг відсікання викидів δ;
– алгоритм класифікації;
– формула для знаходження величини ризику W.
На першому кроці алгоритму необхідно відкинути викиди, тобто об'єкти X L с W>δ. На другому кроці – сформувати початкове наближення μ – з об'єктів вибірки X L вибрати по одному об'єкту кожного класу, що володіє серед об'єктів даного класу максимальною або мінімальною величиною ризику. Потім виконати нарощєння множини еталонів (поки число об'єктів вибірки X L, розпізнаних невірно, не стане менше l0):
– класифікувати об'єкти X L, використовуючи в якості навчальної вибірки μ;
– перерахувати величини ризику для всіх об'єктів X L\μ з урахуванням зміни навчальної вибірки;
– серед об'єктів кожного класу, розпізнаних невірно, вибрати об'єкти з максимальною величиною ризику і додати їх до μ.
Результат роботи алгоритму – класифікація всієї множини об'єктів X L на еталонні, шумові (викиди) та неінформативні об'єкти.
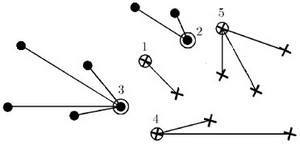
Рисунок 1 – Результат роботи алгоритму STOLP
Алгоритм STOLP має відносно низьку ефективність (порядку O(l 2), так як на кожній ітерації для приєднання чергового еталону необхідно заново класифікувати всі об'єкти, які ще не стали еталонами й рахувати для них величину ризику. Для прискорення роботи можна додавати кілька далеко віддалених один від одного еталонів, не перераховуючи величини ризику.
4.3 Алгоритм FRiS-STOLP
Алгоритм FRiS-STOLP – алгоритм відбору еталонних об'єктів для метричного класифікатора на основі FRiS-функції [5]. На вхід алгоритм отримує навчальну вибірку. Від класичного алгоритму STOLP його відрізняє використання допоміжних функцій. В якості допоміжних функцій використовують:
– NN(u,U) – повертає найближчий до u об'єкт з множини U;
– FindEtalon (Хy,μ) – виходячи з набору вже наявних еталонів μ і набору Хy елементів класу Y, повертає новий еталон для класу Y.
Функція FindEtalon (Хy,μ) використовується у наступному алгоритмі:
- Для кожного об'єкта x ∈ Хy рахують дві характеристики – «обороноздатність» Dx «толерантність» Tx (наскільки об'єкт в ролі еталону одного класу не заважає еталонам інших класів) об'єкта х за формулою 4.1:
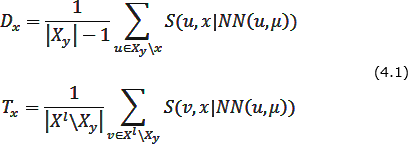
- На основі отриманих характеристик рахуємо «ефективність» об'єкта x за формулою 4.2:

- Функція FindEtalon повертає об'єкт x ∈ X l з максимальною ефективністю Ex (формула 4.3):

Параметр α ∈ [0,1] кількісно визначає відносну «важливість» характеристик об'єктів («обороноздатності» і «толерантності»). Може бути обраним, виходячи із специфіки конкретної задачі.
4.4 Алгоритм ДРЕТ
Алгоритм ДРЕТ (метод роздріблених еталонів) заснований на покритті навчальної вибірки кожного образу простими фігурами, які можна ускладнювати при необхідності.
Навчальна вибірка представляє собою множину об'єктів, що описуються набором ознак. Кожен об'єкт навчальної вибірки може бути представлений у вигляді точки в просторі ознак: X = (x1, x2, x3,..., xp), де p – кількість ознак.
Кожній такій точці відповідає певне значення Y – апріорна інформація про належність даної точки якому-небудь класу. Таким чином, об'єкт представляє собою таку сукупність інформації: X = (x1, x2, x3,..., xp,Y). Один з варіантів методу «роздріблених еталонів» передбачає використання в якості фігури для покріття набір гиперсфер. Для кожного з k образів будується сфера мінімального радіусу, що покриває всі його навчальні реалізації. Значення радіусів цих сфер і відстаней між їх центрами дозволяє визначити образи, сфери яких не перетинаються зі сферами інших образів. Такі сфери вважаються еталонними, а їх центри і радіуси запам'ятовують як «еталони першого покоління» [4].
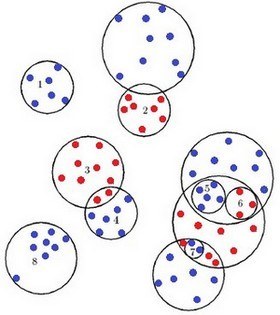
Рисунок 2 – Результат роботи алгоритму ДРЕТ
Якщо два образи перетинаються, але в області перетину не виявилося жодної реалізації навчальної вибірки, такий перетин вважається фіктивним, центри і радіуси цих сфер так само заносять до списку еталонів першого покоління. При цьому область перетину відносять до сфери з меншим радіусом (сфера 2). Якщо в зоні перетину виявилися точки тільки одного образу, то ця зона належить тільки цьому образу (сфера 3). Точка буде належати образу 4, якщо вона потрапляє у сферу 4 та не потрапляє у сферу 3. Якщо ж область перетину містить точки різних образів, то для цих точок будуються «еталони другого покоління» (сфери 4, 5 і 6). Якщо і вони перетинаються, то для точок в зоні перетину будуються «еталони третього покоління». Процедура подріблення еталонів триває до отримання заданої надійності розпізнавання навчальної вибірки.
Доведено, що навіть у дуже складних випадках для задовільного розпізнавання навчальної вибірки може бути достатньо в середньому не більше трьох поколінь еталонів. При розпізнаванні нових реалізацій процес перевірки попадання в ту або іншу еталонну сферу починається зі сфер найменшого діаметра.
4.5 Алгоритм NNDE
Метод найближчих сусідів (Nearest Сусідів algorithm) – найпростіший алгоритм класифікації, заснований на оцінюванні подібності об'єктів. Об'єкт, що класифікується, відноситься до того класу, якому належать найближчі до нього об'єкти навчальної вибірки [10].
У разі, коли сусід всього один, об'єкт, що класифікується, відноситься до того класу Yі, до якого належить найближчий об'єкт навчальної вибірки xі. Для підвищення надійності класифікації використовують кілька сусідів. Тоді об'єкт, що класифікується, відноситься до того класу, до якого належить більшість з його сусідів – k найближчих до нього об'єктів навчальної вибірки xi.
У задачах з двома класами кількість сусідів беруть непарним, щоб не виникало ситуацій неоднозначності, коли однакова кількість сусідів належать різним класам. У задачах з кількістю класів 3 і більше непарність вже не допомагає, і неоднозначні ситуації все одно можуть виникати. У цьому разі використовують метод зважених найближчих сусідів. Згідно з цим методом i-му сусіду приписується вага wі, як правило, регресивний із зростанням рангу сусіда i. Об'єкт відноситься до того класу, який набирає більшу сумарну вагу серед k найближчих сусідів.
4.6 Алгоритм LVQ
Алгоритм скорочення навчальної вибірки має схожу ідею з задачею кластеризації. Він полягає в розбитті вихідної вибірки на підмножини і їх обробку. Застосовується переважно для кластеризації вибірок великого обсягу і дозволяє виділити кластери складної форми.
Мережа LVQ має два шари: конкуруючий і лінійний. Конкуруючий шар виконує кластеризацію векторів, а лінійний шар співвідносить кластери з цільовими класами, заданими користувачем. Як в конкуруючому, так і в лінійному шарі один нейрон припадає на кластер або цільової клас [12]. Таким чином, конкуруючий шар здатний підтримати кількість кластерів, що може перевищити кількість цільових класів. Оскільки заздалегідь відомо, як кластери першого шару співвідносяться з цільовими класами другого шару, то це дозволяє заздалегідь задати елементи матриці вагів. Однак щоб знайти правильний кластер для кожного вектора навчальної множини, необхідно виконати процедуру навчання мережі.
4.7 Алгоритм FOREL
Завдання таксономії полягає в поділі множини об'єктів на задану кількість груп (таксонів, кластерів) із заздалегідь невідомими параметрами за заданим критерієм. Розбиття однакової кількості об'єктів на таксони може відрізнятися, тому для визначення найкращого розбиття вводиться критерій якості таксономії F. Критерій якості заснований на гіпотезі компактності: до одного таксону повинні входити об'єкти, властивості яких «схожі» на деякий «центральний» об'єкт, тобто об'єкти близькі за своїми характеристиками повинні потрапити в один таксон.
Нехай Cj – координати центру j-го таксону, mj – кількість об'єктів у j-му таксоні, ai, i ∈ [1,mj] – об'єкти j-го таксону, ρ(Cj, ai) – відстань між центром й i-м елементом j-го таксону, тоді сума відстаней від усіх елементів до центру j-го таксону можна визначити за формулою 4.4:

Сума внутрішніх відстаней для усіх k таксонів знаходиться за формулою 4.5:

Сенс критерію полягає в тому, що потрібно знайти таке розбиття m об'єктів на k таксонів, щоб наведена вище величина F була мінімальною.
В результаті роботи алгоритму отримуємо таксони сферичної форми. Кількість таксонів залежить від радіусу сфер: чим менше радіус, тим більше таксонів. Спочатку характеристики об'єктів нормуються так, щоб значення всіх характеристик знаходилися в діапазоні від нуля до одиниці. Потім будується гіперсфера мінімального радіусу R0, яка охоплює всі m точок (всі об'єкти входять до одного таксону). Далі радіус сфер поступово зменшується. Задаємо радіус і вибираємо центром сфери будь-яку з наявних точок. Знаходимо точки, відстань до яких менше радіуса, і обчислюємо координати центру ваги цих «внутрішніх» точок. Переносимо центр сфери до центру ваги і знову знаходимо внутрішні точки. Сфера переміщюється в бік локального згущення точок. Така процедура визначення внутрішніх точок і перенесення центру сфери продовжується до тих пір, поки сфера не зупиниться, тобто поки на черговому кроці виявимо, що склад внутрішніх точок, а, отже, і їх центр тяжіння, не змінюється. Це означає, що сфера зупинилася в області локального максимуму щільності точок у просторі ознак.
Точки, що опинилися всередині сфери, що зупинилася, відносимо до таксону номер 1 і виключаємо їх з подальшого розгляду. Для решти точок описана вище процедура повторюється до тих пір, поки всі точки не опиняться у складі таксонів [15].
Доведено збіжність алгоритму за кінцеве число кроків, але легко помітити, що рішення може бути не єдиним. Якщо початкову точку міняти випадковим чином, то може вийти кілька різних варіантів таксономії, і тоді потрібно зупинятися на такому варіанті, який відповідає мінімальному значенню величини F.
5. Метод побудови вибірки w-об'єктів
В роботі [14] запропоновано метод побудови зваженої навчальної вибірки w-объектів для скорочення вибірок великого обсягу.
5.1 Основні поняття
Дано деяка безліч об'єктів М, представлена у вигляді об'єднання непересічних класів (формула 5.1):

Кожен об'єкт Wі з М описується системою ознак, тобто Wі = {wi1, wi2,...,win}, і представляється точкою в лінійному просторі ознак, тобто Wі ∈ Rn. Є кінцевий набір об'єктів W = {W1,...,Ws}, названий навчальною вибіркою. Про кожний об'єкт відомо, до якого класу він належить. На об'єктах вихідної навчальної вибірки W задана деяка метрика R(Wі,Wj).
Для того, щоб побудувати зважену навчальну вибірку в першу чергу необхідно кожний клас об'єктів вихідної навчальної вибірки представити за допомогою алгоритму перетворення вихідної навчальної вибірки у зважену навчальну вибірку у вигляді покриття блоками Wf. Ці блоки називаються утворюючими множинами. Далі кожна утворююча множина Wf замінюється одним вектором MWf = {w1,...,wfn,pf}. Значення ознак {w1,...,wfn} розраховуються за значеннями ознак об'єктів утворюючих множин Wf, pf розраховується як його потужність. Отриманий об'єкт MWf називається w-об'єктом, а елемент pf – вагою w-об'єкта.
5.2 Опис алгоритму побудови w-об'єктів
Основою методу побудови зваженої навчальної вибірки w-об'єктів для скорочення вибірок великого обсягу в системах розпізнавання є вибір множин близькорозташованих об'єктів вихідної вибірки і їх заміна одним зваженим об'єктом нової вибірки. Значення ознак кожного об'єкта нової вибірки є центрами мас значень ознак об'єктів вихідної вибірки, які він замінює. Введений додатковий параметр – вага визначається як кількість об'єктів вихідної вибірки, які були замінені одним об'єктом нової вибірки. Запропонований метод орієнтований як на скорочення вихідної навчальної вибірки, так і на аналіз необхідності корегування вибірки та швидке виконання такого корегування при поповненні вибірки в процесі роботи системи.
Побудова w-об'єкта складається з трьох послідовних етапів:
1) побудова утворюючої множини Wf, що містить деяку кількість d об'єктів вихідної вибірки, що належать одному класу;
2) формування вектора Xі W = {xi1, xi2,...,xin}, значень ознак w-об'єкта Xі W і розрахунок його ваги pі;
3) корегування вихідної навчальної вибірки – видалення об'єктів, включених до утворюючої множини X = X \Wf.
Побудова утворюючої множини Wf полягає в знаходженні початкової точки X1 формування w-об'єкта, визначенні конкуруючої точки Xf2 і виборі в утворюючій множині Wf таких об'єктів вихідної вибірки, відстань до кожного з яких від початкової точки менше, ніж відстань від них до конкуруючої точки. В якості початкової точки X1 формування w-об'єкту використовується об'єкт вихідної навчальної вибірки, найбільш віддалений від усіх об'єктів інших класів. Конкуруюча точка Xf2 вибирається шляхом знаходження найближчого до X1 об'єкта, який не належить до того ж класу, що і сам X1, тобто y1 ≠ yf2.
Для двох класів вибір об'єктів {X1,Xf2,...,Xd} утворюючої множини Wf здійснюється за наступним правилом: Xі включається в Wf, якщо:
– він належить до того ж классу, що й початкова точка Xf1;
– відстань від розглянутого об'єкта до початкової точки X1 менше, ніж до конкуруючої точки Xf2;
– відстань Ri,1 від розглянутого об'єкта до початкової точки менше відстані Ri,2 від розглянутого об'єкта до конкуруючої точки і менше відстані R1,2 між початковою і конкуруючої точками (для випадку, коли класи складаються з декількох окремих областей простору ознак).
Таким чином, утворююча множина Wf формується за правилом (формула 5.2):
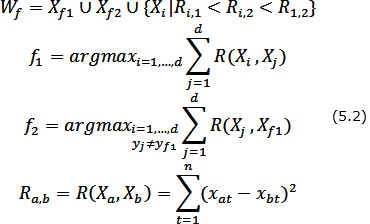
Значення ознак {xi1,xi2,...,xin} нового w-об'єкта XіW формуються згідно з утворюючою множиною Wf (формула 5.3) і розраховуються як координати центру мас системи з pf = |Wf | матеріальних точок (приймемо, що об'єкти вихідної навчальної вибірки, що є матеріальними точками в просторі ознак, мають масу, рівну 1), де |Wf | – потужність множини Wf, тобто

Після формування чергового w-об'єкта, всі об'єкти утворюючої його множини видаляються з вихідної навчальної вибірки, тобто X=X\Wf. Алгоритм закінчує свою роботу, коли у вихідній навчальної вибірці не залишиться жодного об'єкта X∈∅.
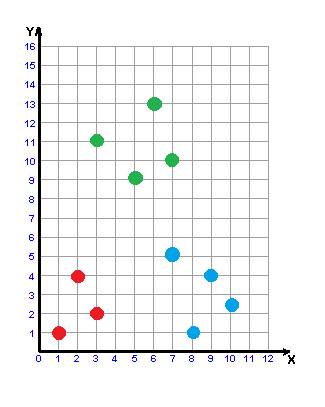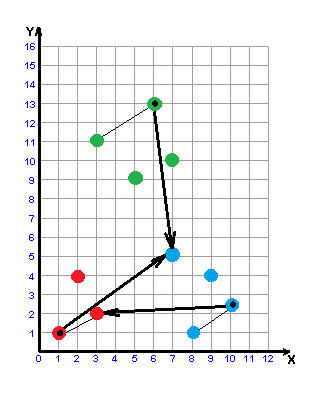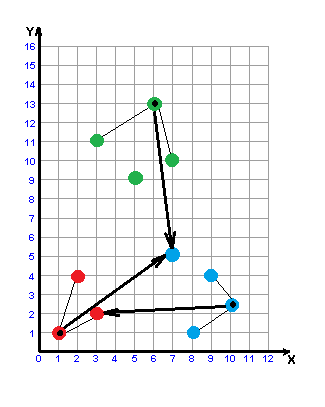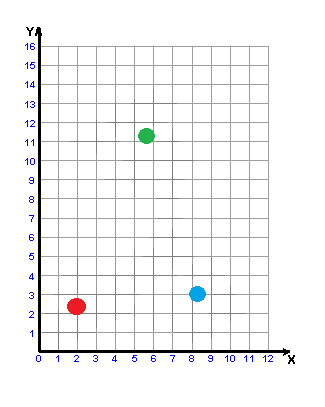
Рисунок 3 – Побудова w-об'єкта
(анімація: 6 кадрів, 6 циклів повторення, 32,8 кілобайт)
Висновки
У даній роботі була розглянута актуальна проблема скорочення навчальної вибірки при обробці даних в системах розпізнавання, що навчаютьтся, були досліджені різні алгоритми скорочення вибірок для систем розпізнавання. Було виявлено, що такі алгоритми як STOLP, FRiS-STOLP прості в реалізації, але дають велику похибку при вирішенні задач з великим обсягом вхідних даних, алгоритм NNDE практично не пристосований для вирішення таких завдань. Був вивчений метод побудови зваженої навчальної вибірки w-об'єктів для скорочення вибірок великого обсягу в системах розпізнавання. Було встановлено, що наявність вагів у вибірках w-об'єктів дозволяє зберігати інформацію про кількість замінених об'єктів, а також, дозволяє провести характеристику тієї області, на якій вони розташовані.
У ході проведених досліджень було встановлено, що формування вибірки w-об'єктів залежить від утворюючих множин, з яких формуються w-об'єкти. Від вибору початкової точки формування утворюючої множини залежить кількість об'єктів, які увійдуть до утворюючої множини і сама кількість w-об'єктів [16]. Це, в свою чергу, впливає на якість класифікації. Тому в магістерській роботі буде розроблятися алгоритм формування утворюючих множин, що дозволить підвищити якість класифікації в системах розпізнавання, що навчаються.
Перелік посилань
- Горбань А.Н. Обучение нейронных сетей. / А.Н. Горбань – М.: СП ПараГраф, 1990. – 298 с.
- Pal S.K. Pattern Recognition Algorithms for Data Mining: Scalability, Knowledge Discovery and Soft Granular Computing / S.K. Pal, P. Mitra – Chapman and Hall / CRC, 2004. – 280 p.
- Александров А.Г. Оптимальные и адаптивные системы. / А.Г. Александров – М.: Высшая школа, 1989. – 263 с.
- Загоруйко Н.Г. Методы распознавания и их применение. – М.: Сов. радио, 1972. – 208 с.
- Алгоритм FRiS-STOLP [Электронный ресурс]. – Режим доступа: http://www.machinelearning.ru/...
- Zagoruiko N.G., Borisova I.A., Dyubanov V.V., Kutnenko O.A. Methods of Recognition Based on the Function of Rival Similarity // Pattern Recognition and Image Analysis. – 2008. – Vol. 18. – № 1. – P. 1–6.
- Larose D.T. Discovering knowledge in Data: An Introduction to Data Mining / D.T. Larose – New Jersey, Wiley & Sons, 2005. – 224 p.
- Kohonen T. Self-Organizing Maps. – Springer-Verlag, 1995. – 501 р.
- Волченко Е.В. Сеточный подход к построению взвешенных обучающих выборок w-объектов в адаптивных системах распознавания // Вісник Національного технічного університету «Харківський політехнічний інститут». Збірник наукових праць. Тематичний випуск: Інформатика i моделювання. – Харків: НТУ «ХПІ», 2011. – № 36. – С. 12–22.
- Метод ближайших соседей. Материал из профессионального информационно-аналитического ресурса, посвященного машинному обучению, распознаванию образов и интеллектуальному анализу данных. [Электронный ресурс]. – Режим доступа: http://www.machinelearning.ru/wiki/index.php?title=Метод_ближайших_соседей
- k-nearest neighbors algorithm. Материал из свободной энциклопедии Википедии. [Электронный ресурс]. – Режим доступа: http://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
- Информационно-аналитический ресурс, который посвящен вопросам ИИ – [Нейронные сети Электронный ресурс]. – Режим доступа: http://neural-networks.ru/Arhitektura-LVQ-seti-51.html
- Потапов А.С. Распознавание образов и машинное восприятие. – СПб.: Политехника, 2007. – 548 с.
- Волченко Е.В. Метод построения взвешенных обучающих выборок в открытых системах распознавания // Доклады 14-й Всероссийской конференции «Математические методы распознавания образов (ММРО-14)», Суздаль, 2009. – М.: Макс-Пресс, 2009. – С. 100–104.
- Загоруйко Н.Г. Прикладные методы анализа данных и знаний. – Новосибирск: Издательство Института математики, 1999. – 261 с.
- Семенова А.П., Волченко Е.В. Исследование принципов формирования образующих множеств при построении взвешенной обучающей выборки w-объектов // Інформаційні управляючі системи та комп'ютерний моніторинг (ІУС-2014). Матерiали V мiжнародної науково-технiчної конференцiї студентiв, аспiрантiв та молодих вчених. – Донецьк, ДонНТУ – 2014. – Т. 1 – С. 464–469.
Важливе зауваження
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: грудень 2014 року. Повний текст роботи і матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.
