
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования
- 3. Предполагаемая научная новизна и практическая значимость
- 4. Обзор существующих алгоритмов сокращения размера выборок
- 4.1 Способы решения задачи сокращения данных
- 4.2 Алгоритм STOLP
- 4.3 Алгоритм FRiS-STOLP
- 4.4 Алгоритм ДРЭТ
- 4.5 Алгоритм NNDE
- 4.6 Алгоритм LVQ
- 4.7 Алгоритм FOREL
- 5. Метод построения выборки w-объектов
- 5.1 Основные определения
- 5.2 Описание алгоритма построения w-объектов
- Выводы
- Список источников
- Важное замечание
Введение
С задачей распознавания образов живые системы, в том числе и человек, сталкиваются постоянно с момента своего появления. В частности, информация, поступающая из органов чувств, обрабатывается мозгом, который, в свою очередь, сортирует информацию, обеспечивает принятие решения, а далее с помощью электрохимических импульсов передает необходимый сигнал далее, например, органам движения, которые реализуют необходимые действия. Затем происходит изменение окружающей обстановки, и вышеуказанные явления происходят заново. И если разобраться, то каждый этап сопровождается распознаванием.
С развитием вычислительной техники стало возможным решить ряд задач, возникающих в процессе жизнедеятельности, облегчить, ускорить, повысить качество результата. К примеру, работа различных систем жизнеобеспечения, взаимодействие человека с компьютером, появление роботизированных систем и др. Тем не менее, обеспечить удовлетворительный результат в некоторых задачах (распознавание быстродвижущихся подобных объектов, рукописного текста) в настоящее время не удается.
Большинство современных прикладных задач, решаемых путем построения систем распознавания, характеризуется большим объемом исходных данных, что значительно снижает эффективность систем и существенно увеличивает временные затраты на выполнение распознавания. Для сокращения выборок большого объема существует метод построения взвешенной обучающей выборки w-объектов, на основании которого и будут строиться образующие множества.
1. Актуальность темы
В настоящее время основным научным направлением является исследование и разработка алгоритмов и методов построения программных средств интеллектуального анализа данных. Актуальность данной тематики определяется наличием ряда важных прикладных задач, при решении которых требуется анализировать большие объемы данных. Большинство современных прикладных задач, решаемых путем построения систем распознавания, характеризуется возможностью добавления новых данных уже в процессе работы систем. Именно поэтому основными требованиями, предъявляемыми к современным системам распознавания, являются адаптивность (возможность системы в процессе работы изменять свои характеристики, а для обучающихся систем распознавания – корректировать решающие правила классификации, при изменении окружающей среды), работа в реальном времени (возможность формирования решений о классификации за ограниченное время) и высокая эффективность классификации для линейно разделимых и пересекающихся в признаковом пространстве классов [1, 2].
Добавление новых объектов приводит к существенному увеличению размера обучающей выборки, что, в свою очередь, приводит к увеличению времени корректировки решающих правил (особенно, если используемый метод обучения требует построения нового решающего правила, а не его частичной корректировки) и ухудшению качества получаемых решений из-за проблемы переобучения на выборках большого объема [3]. Именно поэтому задача предобработки данных путем сокращения размера выборки является актуальной научно-технической задачей, требующей разработки современных подходов к её решению.
2. Цель и задачи исследования
Объектом исследования является процесс обработки данных в обучающихся системах распознавания.
Предмет исследования – существующие алгоритмы формирования взвешенных выборок в обучающихся системах распознавания.
Целью выпускной работы магистра является разработка метода формирования взвешенных выборок в обучающихся системах распознавания. В процессе работы необходимо решить следующие задачи:
– исследовать существующие алгоритмы формирования взвешенных обучающих выборок;
– исследовать методы применения взвешенных обучающих выборок в адаптивных системах распознавания;
– разработать алгоритм построения взвешенных обучающих выборок в обучающихся системах распознавания;
– разработать программный продукт, реализующий разработанный алгоритм формирования взвешенных выборок в обучающихся системах распознавания;
– выполнить сравнительный анализ результатов работы предложенного алгоритма и известных алгоритмов решения данной задачи.
3. Предполагаемая научная новизна и практическая значимость
Научной новизной данной работы является разработка метода формирования взвешенных обучающих выборок в обучающихся системах распознавания. Так как рост размера обучающей выборки приводит к росту времени и ухудшению качества обучения, предполагается, что на основе взвешенных выборок может быть построен эффективный алгоритм выбора некоторого подмножества объектов выборки и удалении остальных.
Практическая значимость работы заключается в повышении эффективности классификации в обучающихся системах распознавания. Разработанный метод формирования взвешенных выборок может использоваться при программной реализации системы классификации для обработки результатов разнообразных социологических, экономических и статистических исследований, создания электронных библиотек, построения спам-фильтров и т. д.
4. Обзор существующих алгоритмов сокращения размера выборок
4.1 Способы решения задачи сокращения данных
Задачи сжатия и объединения данных при условии неизменяющегося словаря признаков могут быть решены двумя способами. Первый способ заключается в отборе некоторого множества объектов исходной обучающей выборки, каждый из которых отвечает предъявляемым требованиям. Наиболее известными алгоритмами, реализующими такой способ, являются алгоритмы STOLP [4], FRiS-STOLP [5, 6], NNDE (Nearest Neighbor Density Estimate) [7, 10, 11] и MDCA (Multiscale Data Condensation Algorithm) [7]. Второй способ состоит в построении множества новых объектов, каждый из которых строится по информации о некотором подмножестве объектов исходной обучающей выборки и обобщает его. К алгоритмам такого типа можно отнести, например, алгоритм ДРЭТ [4], покрывающий признаковое пространство множеством пересекающихся окружностей, определяя тем самым области, принадлежащие каждому из классов, алгоритмы LVQ (learning vector quantization) [8] и w-GridDC [9].
4.2 Алгоритм STOLP
Алгоритм STOLP – алгоритм отбора эталонных объектов для метрического классификатора. Эталоны – это такое подмножество выборки X L , что все объекты X L (или их большая часть) классифицируются правильно при использовании в качестве обучающей выборки множества эталонов. Эталонами i-го класса при классификации методом ближайшего соседа может служить такое подмножество объектов этого класса, что расстояние от любого принадлежащего ему объекта из выборки X L до ближайшего «своего» эталона меньше, чем до ближайшего «чужого» эталона [4].
Входными данными для алгоритма являются:
– выборка X L;
– допустимая доля ошибок l0;
– порог отсечения выбросов δ;
– алгоритм классификации;
– формула для вычисления величины риска W.
На первом шаге алгоритма необходимо отбросить выбросы, т. е. объекты X L с W>δ. На втором шаге – сформировать начальное приближение μ – из объектов выборки X L выбрать по одному объекту каждого класса, обладающему среди объектов данного класса максимальной или минимальной величиной риска. Потом выполнить наращивание множества эталонов (пока число объектов выборки X L, распознаваемых неправильно, не станет меньше l0):
– классифицировать объекты X L, используя в качестве обучающей выборки μ;
– пересчитать величины риска для всех объектов X L\μ с учетом изменения обучающей выборки;
– среди объектов каждого класса, распознанных неправильно, выбрать объекты с максимальной величиной риска и добавить их к μ.
Результат работы алгоритма – разбиение всего множества объектов X L на эталонные, шумовые (выбросы) и неинформативные объекты.
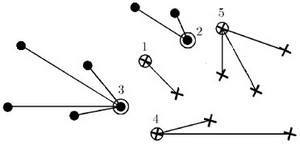
Рисунок 1 – Результат работы алгоритма STOLP
Алгоритм STOLP имеет относительно низкую эффективность (порядка O(l 2), т. к. на каждой итерации для присоединения очередного эталона необходимо заново классифицировать все объекты, еще не ставшие эталонами и считать на них величину риска. Для ускорения работы можно добавлять по несколько далеко отстоящих друг от друга эталонов, не пересчитывая величины риска.
4.3 Алгоритм FRiS-STOLP
Алгоритм FRiS-STOLP – алгоритм отбора эталонных объектов для метрического классификатора на основе FRiS-функции [5]. На вход алгоритм получает обучающую выборку. От классического алгоритма STOLP его отличает использование вспомогательных функций. В качестве вспомогательных функций используют:
– NN(u,U) – возвращает ближайший к u объект из множества U;
– FindEtalon (Хy,μ) – исходя из набора уже имеющихся эталонов μ и набора Хy элементов класса Y, возвращает новый эталон для класса Y.
Функция FindEtalon (Хy,μ) используется в следующем алгоритме:
- Для каждого объекта x ∈ Хy вычисляются две характеристики – «обороноспособность» Dx и «толерантность» Tx (насколько объект в роли эталона одного класса не мешает эталонам других классов) объекта х по формуле 4.1:
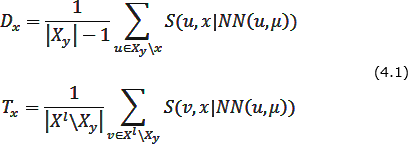
- На основании полученных характеристик вычисляется «эффективность» объекта x по формуле 4.2:

- Функция FindEtalon возвращает объект x ∈ X l с максимальной эффективностью Ex (формула 4.3):

Параметр α ∈ [0,1] количественно задаёт относительную «важность» характеристик объектов («обороноспособности» и «толерантности»). Может быть выбран, исходя из специфики конкретной задачи.
4.4 Алгоритм ДРЭТ
Алгоритм ДРЭТ (метод дробящихся эталонов) основан на покрытии обучающей выборки каждого образа простыми фигурами, которые можно усложнять при необходимости.
Обучающая выборка представляет собой множество объектов, описываемых набором признаков. Каждый объект обучающей выборки может быть представлен в виде точки в пространстве признаков: X = (x1, x2, x3,..., xp), где p – число признаков.
Каждой такой точке соответствует определенное значение Y – априорная информация о принадлежности данной точки какому-либо классу. Таким образом, объект представляет собой следующую совокупность информации: X = (x1, x2, x3,..., xp,Y). Один из вариантов метода «дробящихся эталонов» предусматривает использование в качестве покрывающих фигур набора гиперсфер. Для каждого из k образов строится сфера минимального радиуса, покрывающая все его обучающие реализации. Значения радиусов этих сфер и расстояний между их центрами позволяет определить образы, сферы которых не пересекаются со сферами других образов. Такие сферы считается эталонными, а их центры и радиусы запоминаются в качестве «эталонов первого поколения» [4].
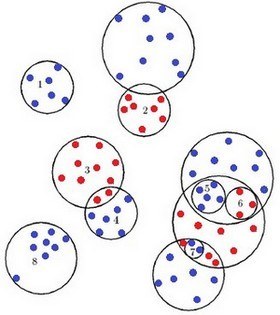
Рисунок 2 – Результат работы алгоритма ДРЭТ
Если два образа пересекаются, но в области пересечения не оказалось ни одной реализации обучающей выборки, такое пересечение считается фиктивным, центры и радиусы этих сфер так же вносятся в список эталонов первого поколения. При этом область пересечения считается принадлежащей сфере с меньшим радиусом (сфера 2). Если в зоне пересечения оказались точки только одного образа, то эта зона считается принадлежащей этому образу (сфера 3). Точка будет считаться относящейся к образу 4, если она попадает в сферу 4 и не попадает в сферу 3. Если же область пересечения содержит точки разных образов, то для этих точек строятся «эталоны второго поколения» (сферы 4,5 и 6). Если и они пересекаются, то для точек из зоны пересечения строятся «эталоны третьего поколения». Процедура дробления эталонов продолжается до получения заданной надежности распознавания обучающей последовательности.
Доказано, что даже в очень сложных случаях для хорошего распознавания обучающей выборки бывает достаточно в среднем не более трех поколений эталонов. При распознавании новых реализаций процесс проверки попадания в ту или иную эталонную сферу начинается со сфер наименьшего диаметра.
4.5 Алгоритм NNDE
Метод ближайших соседей (Nearest Neighbors algorithm) – самый простой алгоритм классификации, основанный на оценивании сходства объектов. Классифицируемый объект относится к тому классу, которому принадлежат ближайшие к нему объекты обучающей выборки [10].
В случае, когда сосед всего один, классифицируемый объект относится к тому классу Yi, к которому принадлежит ближайший объект обучающей выборки xi. Для повышения надёжности классификации используют несколько соседей. Тогда классифицируемый объект относится к тому классу, к которому принадлежит большинство из его соседей – k ближайших к нему объектов обучающей выборки xi.
В задачах с двумя классами число соседей берут нечётным, чтобы не возникало ситуаций неоднозначности, когда одинаковое число соседей принадлежат разным классам. В задачах с числом классов 3 и более нечётность уже не помогает, и ситуации неоднозначности всё равно могут возникать. В этом случае используют метод взвешенных ближайших соседей. Согласно этому методу i-му соседу приписывается вес wi, как правило, убывающий с ростом ранга соседа i. Объект относится к тому классу, который набирает больший суммарный вес среди k ближайших соседей.
4.6 Алгоритм LVQ
Алгоритм сокращения обучающей выборки имеет схожую идею с задачей кластеризации. Он заключается в разбиении исходной выборки на подмножества и их обработку. Применяется преимущественно для кластеризации выборок большого объема и позволяет выделить кластеры сложной формы.
Сеть LVQ имеет два слоя: конкурирующий и линейный. Конкурирующий слой выполняет кластеризацию векторов, а линейный слой соотносит кластеры с целевыми классами, заданными пользователем. Как в конкурирующем, так и в линейном слое приходится один нейрон на кластер или целевой класс [12]. Таким образом, конкурирующий слой способен поддержать количество кластеров, которое может превысить количество целевых классов. Поскольку заранее известно, как кластеры первого слоя соотносятся с целевыми классами второго слоя, то это позволяет заранее задать элементы матрицы весов. Однако чтобы найти правильный кластер для каждого вектора обучающего множества, необходимо выполнить процедуру обучения сети.
4.7 Алгоритм FOREL
Задача таксономии заключается в разделении множества объектов на заданное количество групп (таксонов, кластеров) с заранее неизвестными параметрами по заданному критерию. Разбиение одного и того же множества объектов на таксоны может различаться, поэтому для определения наилучшего разбиения вводится критерий качества таксономии F. Критерий качества основан на гипотезе компактности: в один таксон должны собираться объекты, «похожие» по своим свойствам на некоторый «центральный» объект, то есть объекты близкие по своим характеристикам должны попасть в один таксон.
Пусть Cj – координаты центра j-го таксона, mj – количество объектов в j-ом таксоне, ai, i ∈ [1,mj] – объекты j-го таксона, ρ(Cj, ai) – расстояние между центром и i-м элементом j-го таксона, тогда сумма расстояний от всех элементов до центра j-го таксона определяется по формуле 4.4:

Сумма внутренних расстояний для всех k таксонов определяется по формуле 4.5:

Смысл критерия состоит в том, что нужно найти такое разбиение m объектов на k таксонов, чтобы приведенная выше величина F была минимальной.
В результате работы алгоритма получаются таксоны сферической формы. Количество таксонов зависит от радиуса сфер: чем меньше радиус, тем больше получается таксонов. Вначале признаки объектов нормируются так, чтобы значения всех признаков находились в диапазоне от нуля до единицы. Затем строится гиперсфера минимального радиуса R0, которая охватывает все m точек (все объекты входят в один таксон). Далее радиус сфер постепенно уменьшается. Задаем радиус и помещаем центр сферы в любую из имеющихся точек. Находим точки, расстояние до которых меньше радиуса, и вычисляем координаты центра тяжести этих «внутренних» точек. Переносим центр сферы в этот центр тяжести и снова находим внутренние точки. Сфера как бы плывет в сторону локального сгущения точек. Такая процедура определения внутренних точек и переноса центра сферы продолжается до тех пор, пока сфера не остановится, т. е. пока на очередном шаге не обнаружим, что состав внутренних точек, а, следовательно, и их центр тяжести, не меняется. Это означает, что сфера остановилась в области локального максимума плотности точек в признаковом пространстве.
Точки, оказавшиеся внутри остановившейся сферы, объявляем принадлежащими таксону номер 1 и исключаем их из дальнейшего рассмотрения. Для оставшихся точек описанная выше процедура повторяется до тех пор, пока все точки не окажутся включенными в таксоны [15].
Доказана сходимость алгоритма за конечное число шагов, но легко заметить, что решение может быть не единственным. Если начальную точку менять случайным образом, то может получиться несколько разных вариантов таксономии, и тогда нужно останавливаться на таком варианте, который соответствует минимальному значению величины F.
5. Метод построения выборки w-объектов
В работе [14] предложен метод построения взвешенной обучающей выборки w-объектов для сокращения выборок большого объема.
5.1 Основные определения
Дано некоторое множество объектов М, представленное в виде объединения непересекающихся классов (формула 5.1):

Каждый объект Wi из М описывается системой признаков, т. е. Wi = {wi1, wi2,…,win}, и представляется точкой в линейном пространстве признаков, т. е. Wi ∈ Rn. Имеется конечный набор объектов W = {W1,…,Ws}, называемый обучающей выборкой. О каждом объекте известно, к какому классу он принадлежит. На объектах исходной обучающей выборки W задана некоторая метрика R(Wi,Wj).
Для того чтобы построить взвешенную обучающую выборку в первую очередь необходимо каждый класс объектов исходной обучающей выборки представить с помощью алгоритма преобразования исходной обучающей выборки во взвешенную обучающую выборку в виде покрытия блоками Wf. Эти блоки называются образующими множествами. Далее каждое образующее множество Wf заменяется одним вектором MWf = {wf1,…,wfn,pf}. Значения признаков {wf1,…,wfn} рассчитываются по значениям признаков объектов образующего множества Wf, а pf рассчитывается как его мощность. Получаемый объект MWf называется w-объектом, а элемент pf – весом w-объекта.
5.2 Описание алгоритма построения w-объектов
Основой метода построения взвешенной обучающей выборки w-объектов для сокращения выборок большого объема в системах распознавания является выбор множеств близкорасположенных объектов исходной выборки и их замена одним взвешенным объектом новой выборки. Значения признаков каждого объекта новой выборки являются центрами масс значений признаков объектов исходной выборки, которые он заменяет. Введенный дополнительный параметр – вес определяется как количество объектов исходной выборки, которые были заменены одним объектом новой выборки. Предлагаемый метод ориентирован как на сокращение исходной обучающей выборки, так и на анализ необходимости корректировки выборки и быстрое выполнение такой корректировки при пополнении выборки в процессе работы системы.
Построение w-объекта состоит из трех последовательных этапов:
1) построение образующего множества Wf, содержащее некоторое количество d объектов исходной выборки, принадлежащих одному классу;
2) формирование вектора Xi W = {xi1, xi2,...,xin}, значений признаков w-объекта Xi W и расчет его веса pi;
3) корректировка исходной обучающей выборки – удаление объектов, включенных в образующее множество X = X \Wf.
Построение образующего множества Wf состоит в нахождении начальной точки Xf1 формирования w-объекта, определении конкурирующей точки Xf2 и выборе в образующем множестве Wf таких объектов исходной выборки, расстояние до каждого из которых от начальной точки меньше, чем расстояние от них до конкурирующей точки. В качестве начальной точки Xf1 формирования w-объекта используется объект исходной обучающей выборки, наиболее удаленный от всех объектов других классов. Конкурирующая точка Xf2 выбирается путем нахождения ближайшего к Xf1 объекта, не принадлежащего тому же классу, что и сам Xf1, т.е. yf1 ≠ yf2.
Для случая двух классов выбор объектов {Xf1,Xf2,...,Xd} образующего множества Wf осуществляется по следующему правилу: Xi включается в Wf, если:
– он принадлежит тому же классу, что и начальная точка Xf1;
– расстояние от рассматриваемого объекта до начальной точки Xf1 меньше, чем до конкурирующей точки Xf2;
– расстояние Ri,1 от рассматриваемого объекта до начальной точки меньше расстояния Ri,2 от рассматриваемого объекта до конкурирующей точки и меньше расстояния R1,2 между начальной и конкурирующей точками (для случая, когда классы состоят из нескольких отдельных областей признакового пространства).
Таким образом, образующее множество Wf формируется по правилу (формула 5.2):
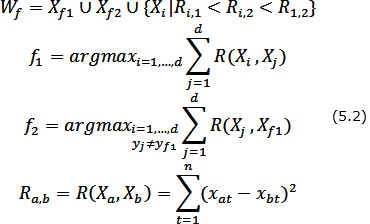
Значения признаков {xi1,xi2,...,xin} нового w-объекта XiW формируются по образующему множеству Wf (формула 5.3) и рассчитываются как координаты центра масс системы из pf = |Wf | материальных точек (примем, что объекты исходной обучающей выборки, являющиеся в признаковом пространстве материальными точками, имеют массу, равную 1), где |Wf | – мощность множества Wf, т.е.

После формирования очередного w-объекта, все объекты образующего его множества удаляются из исходной обучающей выборки, т.е. X=X\Wf. Алгоритм заканчивает свою работу, когда в исходной обучающей выборке не останется ни одного объекта X∈∅.
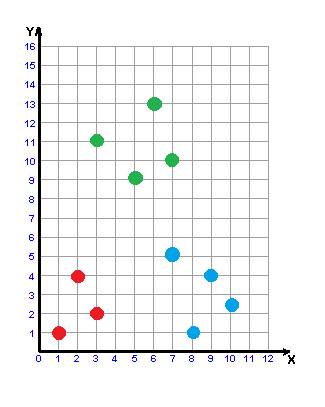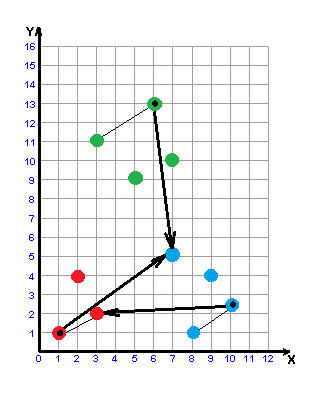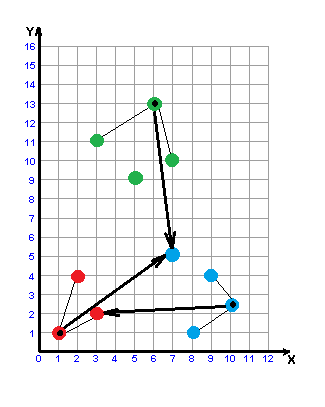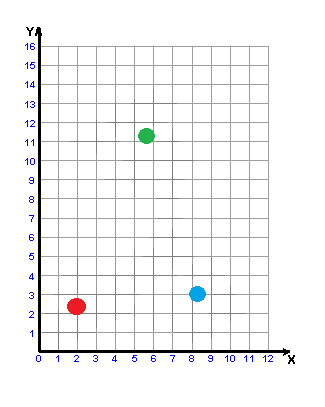
Рисунок 3 – Построение w-объекта
(анимация: 6 кадров, 6 циклов повторения, 32,8 килобайт)
Выводы
В данной работе была рассмотрена актуальная проблема сокращения размера обучающей выборки при обработке данных в обучающихся системах распознавания, были исследованы различные алгоритмы сокращения выборок для систем распознавания. Было выявлено, что такие алгоритмы как STOLP, FRiS-STOLP просты в реализации, но дают большую погрешность при решении задач с большим объемом входных данных, алгоритм NNDE практически не приспособлен для решения таких задач. Был изучен метод построения взвешенной обучающей выборки w-объектов для сокращения выборок большого объема в системах распознавания. Было установлено, что наличие весов в выборках w-объектов позволяет сохранять информацию о количестве заменяемых объектов, а также, позволяет провести характеристику той области, на которой они расположены.
В ходе проведенных исследований было установлено, что формирование выборки w-объектов зависит от образующих множеств, из которых формируются w-объекты. От выбора начальной точки формирования образующего множества зависит количество объектов, которые войдут в образующее множество и само количество w-объектов [16]. Это, в свою очередь, влияет на качество классификации. Поэтому в магистерской работе будет разрабатываться алгоритм формирования образующих множеств, что позволит повысить качество классификации в обучающихся системах распознавания.
Список источников
- Горбань А.Н. Обучение нейронных сетей. / А.Н. Горбань – М.: СП ПараГраф, 1990. – 298 с.
- Pal S.K. Pattern Recognition Algorithms for Data Mining: Scalability, Knowledge Discovery and Soft Granular Computing / S.K. Pal, P. Mitra – Chapman and Hall / CRC, 2004. – 280 p.
- Александров А.Г. Оптимальные и адаптивные системы. / А.Г. Александров – М.: Высшая школа, 1989. – 263 с.
- Загоруйко Н.Г. Методы распознавания и их применение. – М.: Сов. радио, 1972. – 208 с.
- Алгоритм FRiS-STOLP [Электронный ресурс]. – Режим доступа: http://www.machinelearning.ru/...
- Zagoruiko N.G., Borisova I.A., Dyubanov V.V., Kutnenko O.A. Methods of Recognition Based on the Function of Rival Similarity // Pattern Recognition and Image Analysis. – 2008. – Vol. 18. – № 1. – P. 1–6.
- Larose D.T. Discovering knowledge in Data: An Introduction to Data Mining / D.T. Larose – New Jersey, Wiley & Sons, 2005. – 224 p.
- Kohonen T. Self-Organizing Maps. – Springer-Verlag, 1995. – 501 р.
- Волченко Е.В. Сеточный подход к построению взвешенных обучающих выборок w-объектов в адаптивных системах распознавания // Вісник Національного технічного університету «Харківський політехнічний інститут». Збірник наукових праць. Тематичний випуск: Інформатика i моделювання. – Харків: НТУ «ХПІ», 2011. – № 36. – С. 12–22.
- Метод ближайших соседей. Материал из профессионального информационно-аналитического ресурса, посвященного машинному обучению, распознаванию образов и интеллектуальному анализу данных. [Электронный ресурс]. – Режим доступа: http://www.machinelearning.ru/wiki/index.php?title=Метод_ближайших_соседей
- k-nearest neighbors algorithm. Материал из свободной энциклопедии Википедии. [Электронный ресурс]. – Режим доступа: http://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
- Информационно-аналитический ресурс, который посвящен вопросам ИИ – [Нейронные сети Электронный ресурс]. – Режим доступа: http://neural-networks.ru/Arhitektura-LVQ-seti-51.html
- Потапов А.С. Распознавание образов и машинное восприятие. – СПб.: Политехника, 2007. – 548 с.
- Волченко Е.В. Метод построения взвешенных обучающих выборок в открытых системах распознавания // Доклады 14-й Всероссийской конференции «Математические методы распознавания образов (ММРО-14)», Суздаль, 2009. – М.: Макс-Пресс, 2009. – С. 100–104.
- Загоруйко Н.Г. Прикладные методы анализа данных и знаний. – Новосибирск: Издательство Института математики, 1999. – 261 с.
- Семенова А.П., Волченко Е.В. Исследование принципов формирования образующих множеств при построении взвешенной обучающей выборки w-объектов // Інформаційні управляючі системи та комп'ютерний моніторинг (ІУС-2014). Матерiали V мiжнародної науково-технiчної конференцiї студентiв, аспiрантiв та молодих вчених. – Донецьк, ДонНТУ – 2014. – Т. 1 – С. 464–469.
Важное замечание
При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: декабрь 2014 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
