
Реферат по теме выпускной работы
Содержание
- 1. Цель и задачи
- 2. Актуальность темы
- 3. Предполагаемая научная новизна
- 4. Планируемые практические результаты
- 5. Обзор исследований и разработок
- 5.1 Обзор исследований и разработок по теме на глобальном уровне
- 5.2 Обзор исследований и разработок по теме на национальном уровне
- 5.3 Обзор исследований и разработок по теме на локальном уровне
- 6. Проблемы ограничения доступа к веб-ресурсам в образовательных системах
- 7. Информационная безопасность веб-ресурсов для пользователей интеллектуальных обучающих систем
- 8. Алгоритмы определения информационной безопасности веб-ресурсов для пользователей интеллектуальных обучающих систем
- 9. Направления совершенствования алгоритмов
- 10. Выводы
1. Цель и задачи
Целью работы является разработка алгоритмов повышения безопасности доступа к внешним информационным ресурсам из корпоративных образовательных сетей с учетом характерных для них угроз безопасности, а также особенностей контингента пользователей, политик безопасности, архитектурных решений, ресурсного обеспечения.
Исходя из поставленной цели, в работе решаются следующие задачи:
1. Выполнить анализ основных угроз информационной безопасности в образовательных сетях.
2. Разработать метод ограничения доступа к нежелательным информационным ресурсам в образовательных сетях.
3. Разработать алгоритмы, позволяющие осуществлять сканирование веб-страниц, поиск прямых соединений и загрузку файлов для дальнейшего анализа потенциально вредоносного кода на сайтах.
4. Разработать алгоритм идентификации нежелательных информационных ресурсов на сайтах.
2. Актуальность темы
Современные интеллектуальные обучающие системы являются Web-ориентированными и предусматривают для своих пользователей возможность работы с различными видами локальных и удаленных образовательных ресурсов. Проблема безопасного использования информационных ресурсов (ИР), размещенных в сети Интернет, постоянно приобретает все большую актуальность [1,2]. Одним из методов, используемых при решении данной проблемы, является ограничение доступа к нежелательным информационным ресурсам.
Операторы, предоставляющие доступ в Интернет образовательным учреждениям, обязаны обеспечить ограничение доступа к нежелательным ИР. Ограничение осуществляется путем фильтрации операторами по спискам, регулярно обновляемым в установленном порядке. Однако, учитывая назначение и пользовательскую аудиторию образовательных сетей, целесообразно использовать более гибкую, самообучающуюся систему, которая позволит динамически распознавать нежелательные ресурсы и ограждать от них пользователей.
В целом доступ к нежелательным ресурсам несет следующие угрозы: пропаганду противоправных и асоциальных действий, таких как: политический экстремизм, терроризм, наркомания, распространение порнографии и других материалов; отвлечение учащихся от использования компьютерных сетей в образовательных целях; затруднение доступа в Интернет из-за перегрузки внешних каналов, имеющих ограниченную пропускную способность. Перечисленные выше ресурсы часто используются для внедрения вредоносных программ с сопутствующими им угрозами [3,4].
Существующие системы ограничения доступа к сетевым ресурсам имеют возможность проверять на соответствие заданным ограничениям не только отдельные пакеты, но и их содержимое – контент, передаваемый через сеть. В настоящее время в системах контентной фильтрации применяются следующие методы фильтрации web-контента: по имени DNS или конкретному IP-адресу, по ключевым словам внутри web-контента и по типу файла. Чтобы блокировать доступ к определенному web-узлу или группе узлов, необходимо задать множество URL, контент которых является нежелательным. URL-фильтрация обеспечивает тщательный контроль безопасности сети. Однако нельзя предугадать заранее все возможные неприемлемые URL-адреса. Кроме того, некоторые web-узлы с сомнительным информационным наполнением работают не с URL, а исключительно с IP-адресами.
Один из путей решения задачи состоит в фильтрации контента, получаемого по протоколу HTTP. Недостатком существующих систем контентной фильтрации является использование списков разграничения доступа, формируемых статически. Для их наполнения разработчики коммерческих систем контентной фильтрации нанимают сотрудников, которые делят контент на категории и составляют рейтинг записей в базе данных [5].
Для устранения недостатков существующих систем фильтрации контента для образовательных сетей актуальна разработка систем фильтрации web-трафика с динамическим определением категории web-ресурса по содержимому его страниц.
3. Предполагаемая научная новизна
Алгоритм ограничения доступа пользователей интеллектуальных обучающих систем к нежелательным ресурсам Интернет-сайтов, основанный на динамическом формировании списков доступа к информационным ресурсам путем их отложенной классификации.
4. Планируемые практические результаты
Разработанные алгоритмы могут использоваться в системах ограничения доступа к нежелетельным ресурсам в интеллектуальных системах компьютерного обучения.
5. Обзор исследований и разработок
5.1 Обзор исследований и разработок по теме на глобальном уровне
Проблемам обеспечения информационной безопасности посвящены работы таких известных ученых как: H.H. Безруков, П.Д. Зегжда, A.M. Ивашко, А.И. Костогрызов, В.И. Курбатов К. Лендвер, Д. Маклин, A.A. Молдовян, H.A. Молдовян, А.А.Малюк, Е.А.Дербин, Р. Сандху, Дж. М. Кэррол, и других. Вместе с тем, несмотря на подавляющий объем текстовых источников в корпоративных и открытых сетях, в области разработки методов и систем защиты информации в настоящее время недостаточно представлены исследования, направленные на анализ угроз безопасности и исследование ограничения доступа к нежелательным ресурсам при компьютерном обучении с возможностями доступа к Web.
5.2 Обзор исследований и разработок по теме на национальном уровне
В Украине ведущим исследователем в данной сфере является Домарев В.В. [6]. Его диссертационные исследования посвящены проблемам создания комплексных систем защиты информации. Автор книг: «Безопасность информационных технологий. Методология создания систем защиты», «Безопасность информационных технологий. Системный подход» и др., автор более 40 научных статей и публикаций.
5.2 Обзор исследований и разработок по теме на национальном уровне
В Донецком национальном техническом университете разработкой моделей и методов для создания системы информационной безопасности корпоративной сети предприятия с учетом различных критериев занималась Химка С.С. [7]. Защитой информации в обучающих системах Заняла Ю.С. [8].
6. Проблемы ограничения доступа к веб-ресурсам в образовательных системах
Развитие информационных технологий в настоящее время позволяет говорить о двух аспектах описания ресурсов Интернет-контент и инфраструктура доступа. Под инфраструктурой доступа принято понимать множество аппаратных и программных средств, обеспечивающих передачу данных в формате IP-пакетов, а контент определяется как совокупность формы представления (например, в виде последовательности символов в определенной кодировке) и контента (семантики) информации. Среди характерных свойств такого описания следует выделить следующие:
1. независимость контента от инфраструктуры доступа;
2. непрерывное качественное и количественное изменение контента;
3. появление новых интерактивных информационных ресурсов («живые журналы», социальные сети, свободные энциклопедии и др.), в которых пользователи непосредственно участвуют в создании сетевого контента.
При решении задач управления доступом к информационным ресурсам большое значение имеют вопросы выработки политики безопасности, которые решаются по отношению к характеристикам инфраструктуры и сетевого контента. Чем выше уровень описания модели информационной безопасности, тем в большей степени управление доступом ориентировано на семантику сетевых ресурсов. Очевидно, что MAC и IP-адреса (канальный и сетевой уровень взаимодействия) интерфейсов сетевых устройств невозможно привязать к какой-либо категории данных, так как один и тот же адрес может представлять различные сервисы. Номера портов (транспортный уровень), как правило, дают представление о типе сервиса, но качественно никак не характеризуют информацию, предоставляемую этим сервисом. Например, невозможно отнести определенный Web-сайт к одной из семантических категорий (СМИ, бизнес, развлечения и т.д.) только на основании информации транспортного уровня. Обеспечение информационной защиты на прикладном уровне вплотную приближается к понятию контентной фильтрации, т.е. управления доступом с учетом семантики сетевых ресурсов. Следовательно, чем более ориентирована на контент система управления доступом, тем более дифференцированный подход по отношению к различным категориям пользователей и информационных ресурсов можно реализовать с ее помощью. В частности, семантически ориентированная система управления способна эффективно ограничить доступ учащихся образовательных учреждений к ресурсам, не совместимым с процессом обучения.
Возможные варианты процесса получения веб-ресурса представлены на рис.1
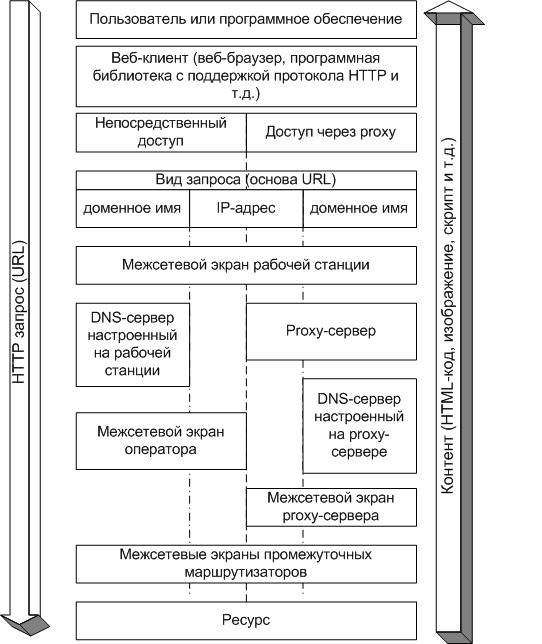
Чтобы обеспечить гибкий контроль использования Интернет-ресурсов, необходимо ввести в компании-операторе соответствующую политику использования ресурсов образовательной организацией. Эта политика может реализовываться как «вручную», так и автоматически. «Ручная» реализация означает, что в компании имеется специальный штат сотрудников, которые в режиме реального времени или по журналам маршрутизаторов, прокси-серверов или межсетевых экранов ведут мониторинг активности пользователей образовательного учреждения. Такой мониторинг является проблематичным, поскольку требует больших трудозатрат. Чтобы обеспечить гибкий контроль использования Интернет ресурсов, компания должна дать администратору инструмент для реализации политики использования ресурсов организацией. Этой цели служит контентная фильтрация. Ее суть заключается в декомпозиции объектов информационного обмена на компоненты, анализе содержимого этих компонентов, определении соответствия их параметров принятой политике использования Интернет-ресурсов и осуществлении определенных действий по результатам такого анализа. В случае фильтрации веб трафика под объектами информационного обмена подразумеваются веб-запросы, содержимое веб страниц, передаваемые по запросу пользователя файлы.
Пользователи учебной организации получают доступ к сети Интернет исключительно через proxy-сервер. При каждой попытке получения доступа к тому либо иному ресурсу proxy-сервер проверяет – не внесен ли ресурс в специальную базу. В случае если такой ресурс размещен в базе запрещенных – доступ к нему блокируется, а пользователю выдается на экран соответствующее сообщение.
В случае, если запрошенный ресурс отсутствует в базе запрещённых ресурсов то доступ к нему предоставляется, однако запись о посещении данного ресурса фиксируется в специальном служебном журнале. Один раз в день (или с другим периодом) proxy-сервер формирует перечень наиболее посещаемых ресурсов (в виде списка URL) и отправляет его экспертам. Эксперты (администраторы системы) с использованием соответствующей методики проверяют полученный перечень ресурсов и определяет их характер. В случае, если ресурс имеет нецелевой характер, эксперт осуществляет его классификацию (порноресурс, игровой ресурс) и вносит изменение в базу данных. После внесения всех необходимых изменений обновлённая редакция базы данных автоматически пересылается всем proxy-серверам, подключённым к системе. Схема фильтрации нецелевых ресурсов на proxy-серверах приведена на рис. 2.
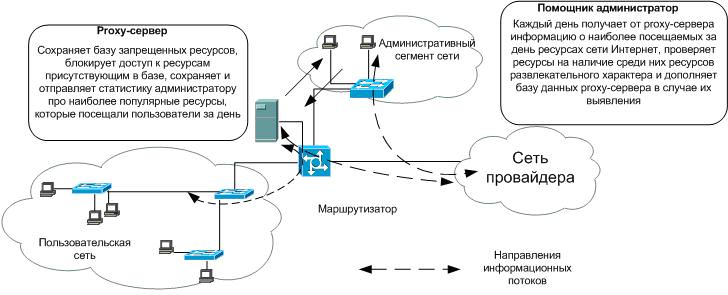
Проблемы фильтрации нецелевых ресурсов на proxy-серверах следующие. При централизованной фильтрации необходима высокая производительность оборудования центрального узла, большая пропускная способность каналов связи на центральном узле, выход из строя центрального узла ведет к полному выходу из строя всей системы фильтрации.
При децентрализованной фильтрации «на местах» непосредственно на рабочих станциях или серверах организации большая стоимость разворачивания и поддержки.
При фильтрации по адресу на этапе отправки запроса отсутствует превентивная реакция на наличие нежелательного контента, сложности при фильтрации «маскирующихся» веб-сайтов.
При фильтрации по контенту необходима обработка больших объёмов информации при получении каждого ресурса, сложность обработки ресурсов подготовленных с использованием таких средств как Java, Flash.
7. Информационная безопасность веб-ресурсов для пользователей интеллектуальных обучающих систем
Рассмотрим возможность управления доступом к ИР при помощи распространенного решения, основанного на иерархическом принципе комплексирования средств управления доступом к ресурсам Интернет (рис.3). Ограничение доступа к нежелательным ИР из ИОС может быть обеспечено путем сочетания таких технологий как межсетевое экранирование, использование прокси-серверов, анализ аномальной деятельности с целью обнаружение вторжений, ограничение полосы пропускания, фильтрация на основе анализа содержания (контента), фильтрация на основании списков доступа. При этом одной из ключевых задач является формирование и использование актуальных списков ограничения доступа.
Фильтрация нежелательных ресурсов проводится в соответствии с действующими нормативными документами на основании публикуемых в установленном порядке списков. Ограничение доступа к иным информационным ресурсам производится на основании специальных критериев, разрабатываемых оператором образовательной сети.
Доступ пользователей с частотой, ниже заданной даже к потенциально нежелательному ресурсу, является допустимым. Анализу и классификации подлежат только востребованные ресурсы, то есть те, для которых число запросов пользователей превысило заданное пороговое значение. Сканирование и анализ осуществляются спустя некоторое время после превышения числа запросов порогового значения (в период минимальной загрузки внешних каналов).
Сканируются не единичные веб-страницы, а все связанные с ними ресурсы (путем анализа имеющихся на странице ссылок). В результате данный подход позволяет в процессе сканирования ресурса определять наличие ссылок на вредоносные программы.

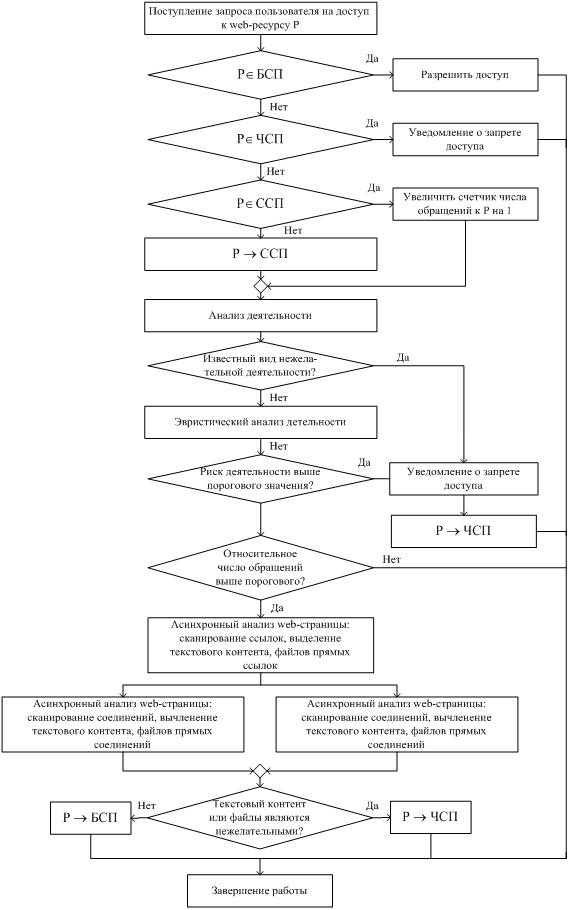
Автоматизированная классификация ресурсов производится на корпоративном сервере клиента – владельца системы. Время классификации определяется используемым методом, в основе которого лежит понятие отложенной классификации ресурса. При этом предполагается, что доступ пользователей с частотой ниже заданной даже к потенциально нежелательному ресурсу является допустимым. Это позволяет избежать дорогостоящей классификации «на лету». Анализу и автоматизированной классификации подлежат только востребованные ресурсы, то есть ресурсы, частота запросов пользователей к которым превысила заданное пороговое значение. Сканирование и анализ осуществляются спустя некоторое время после превышения числа запросов порогового значения (в период минимальной загрузки внешних каналов). Метод реализует схему динамического построения трех списков: «черного»(ЧСП), «белого»(БСП) и «серого»(ССП). Ресурсы, находящиеся в «черном» списке запрещены для доступа. «Белый» список содержит проверенные разрешенные ресурсы. «Серый» список содержит ресурсы, которые хотя бы один раз были востребованы пользователями, но не прошли классификацию. Первоначальное формирование и дальнейшая «ручная» корректировка «черного» списка производится на основании официальной информации об адресах запрещенных ресурсов, предоставляемых уполномоченным государственным органом. Первоначальное содержание «белого» списка составляют рекомендованные для использования ресурсы. Любой запрос ресурса, не относящегося к «черному» списку, удовлетворяется. В том случае, если этот ресурс не находится в «белом» списке, он помещается в «серый» список, где фиксируется количество запросов к этому ресурсу. Если частота запросов превышает некоторое пороговое значение, проводится автоматизированная классификация ресурса, на основании чего он попадает в «черный» или «белый» список.
8. Алгоритмы определения информационной безопасности веб-ресурсов для пользователей интеллектуальных обучающих систем
Алгоритм ограничения доступа. Ограничения доступа к нежелательным ресурсам Интернет-сайтов основывается на следующем определении понятия риска доступа к нежелательному ИР в ИОС. Риском доступа к нежелательному i-му ИР, отнесенному к к-му классу ИР, будем называть величину, пропорциональную экспертной оценке ущерба, наносимого нежелательным ИР данного вида ИОС или личности пользователя и числу обращений к данному ресурсу за заданный отрезок времени:

По аналогии с классическим определением риска как произведения вероятности реализации угрозы на стоимость наносимого ущерба, данное определение трактует риск как математическое ожидание величины возможного ущерба от доступа к нежелательному ИР. При этом величина ожидаемого ущерба определяется степенью воздействия ИР на личности пользователей, которая в свою очередь прямо пропорциональна числу пользователей, испытавших это воздействие.
В процессе анализа любого веб-ресурса, с точки зрения желательности или нежелательности доступа к нему, необходимо рассматривать следующие основные компоненты каждой его страницы: контент, то есть текстовую и иную (графическую, фото, видео) информацию, размещенную на этой странице; контент, размещенный на других страницах этого же веб-сайта (получить внутренние ссылки из содержимого загруженных страниц можно по регулярным выражениям); соединения с другими сайтами (как с точки зрения возможной загрузки вирусов и троянских программ), так и с точки зрения наличия нежелательного контента. Алгоритм ограничения доступа к нежелательным ресурсам с использованием списков приведен на рис. 4.
Алгоритм определения нежелательных Web-страниц. Для классификации контента – текстов веб-страниц – необходимо решить следующие задачи: задание категорий классификации; извлечение из исходных текстов информации, поддающейся автоматическому анализу; создание коллекций проклассифицированных текстов; построение и обучение классификатора, работающего с полученными наборами данных.
Обучающее множество проклассифицированных текстов подвергают анализу, выделяя термы – наиболее часто употребляемые словоформы в целом и по каждой категории классификации в отдельности. Каждый исходный текст представляют в виде вектора, компонентами которого являются характеристики встречаемости данного терма в тексте. Для того чтобы избежать разреженности векторов и уменьшить их размерность, словоформы целесообразно привести к начальной форме методами морфологического анализа. После этого вектор следует нормализовать, что позволяет добиться более корректного результата классификации. Для одной веб-страницы можно сформировать два вектора: для информации, отображаемой для пользователя, и для текста, предоставляемого поисковым машинам.
Известны различные подходы к построению классификаторов веб-страниц. Наиболее часто используемыми являются [9–13]: байесовский классификатор; нейронные сети; линейные классификаторы; метод опорных векторов (SVM). Все вышеназванные методы требуют обучения на обучающей коллекции и проверки на тестирующей коллекции. Для бинарной классификации можно выбрать наивное байесовское решение, предполагающее независимость друг от друга характеристик в векторном пространстве. Будем считать, что все ресурсы необходимо классифицировать как желательные и нежелательные. Тогда вся коллекция образцов текстов веб-страниц разделяется на два класса: C={C1, C2} причем априорная вероятность каждого класса P(Ci), i=1,2. При достаточно большой коллекции образцов можно считать, что P(Ci) равняется отношению количества образцов класса Ci к общему количеству образцов. Для некоторого подлежащего классификации образца D из условной вероятности P(D/Ci), согласно теореме Байеса, может быть получена величина P(Ci /D):

причем
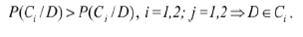
с учетом постоянства P(D) получаем:
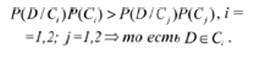
Предполагая независимость друг от друга термов в векторном пространстве, можно получить следующее соотношение:

Для того чтобы более точно классифицировать тексты, характеристики которых близки (например, различать порнографию и художественную литературу, в которой описываются эротические сцены), следует ввести весовые коэффициенты:
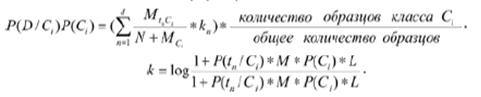
Если kn=k; если kn меньше k, kn.=1/|k|. Здесь M – частота всех термов в базе данных образцов, L – количество всех образцов.
9. Направления совершенствования алгоритмов
В дальнейшем предполагается разработать алгоритм анализа ссылок с целью выявления внедрения вредоносного кода в код web-страницы и сравнить байесовский классификатор с методом опорных векторов.
10. Выводы
Выполнен анализ проблемы ограничения доступа к веб-ресурсам в образовательных системах. Выбраны базовые принципы фильтрации нецелевых ресурсов на proxy-серверах на основе формирования и использование актуальных списков ограничения доступа. Разработан алгоритм ограничения доступа к нежелательным ресурсам с использованием списков, позволяющий динамически формировать и обновлять списки доступа к ИР на основе анализа их контента с учетом частоты посещений и контингента пользователей. Для выявления нежелательного контента разработан алгоритм на основе наивного байесовского классификатора.
Список источников
- Зима В. М. Безопасность глобальных сетевых технологий / В. Зима, А. Молдовян, Н. Молдовян. – 2-е изд. – СПб.: БХВ-Петербург, 2003. – 362 c.
- Воротницкий Ю. И. Защита от доступа к нежелательным внешним информационным ресурсам в научно-образовательных компьютерных сетях / Ю. И. Воротницкий, Се Цзиньбао // Мат. XIV Межд. конф. «Комплексная защита информации». – Могилев, 2009. – С. 70-71.
- Varatnitsky Y. Web Application Vulnerability Analysis and Risk Control / Y. Varatnitsky, Xie Jinbao // J. of Computer Applications and Software. – 2010, №10. – P. 279-280, 287.
- Varatnitsky Y. Based on source code analysis detection method of web-based malicious code / Y. Varatnitsky, Xie Jinbao //J. of Computer & Information Technology. – 2010, №1-2. – P. 49-53.
- Хилл Б. Решения для фильтрации Web-контента // Открытые системы: [Электронный документ] – (http://www.osp.ru/win2000/2004/05/177073/).
- Домарев В.В.«Безопасность информационных технологий. Системный подход» - К.:ООО ТИД «Диасофт», 2004.-992 с
- Химка С. С. Разработка моделей и методов для создания системы информационной безопасности корпоративной сети предприятия с учетом различных критериев // реферат выпускной работы магистра Факультет вычислительной техники и информатики ДонНТУ. 2009.
- Заняла Ю.С.Защита информации в обучающих системах // реферат выпускной работы магистра Факультет вычислительной техники и информатики ДонНТУ. 2007.
- Маслов М. Ю. Автоматическая классификация веб-сайтов / М. Ю. Маслов, А. А. Пяллинг, С. И. Трифонов. – Режим доступа: rcdl.ru/doc/2008/230_235_paper27. pdf. – Дата доступа: 08.11.2011.
- Wu lide. Large Scale Text Process / Wu lide. ShangHai: Fudan University Press, 1997. – 180 p.
- Zhang Yizhong.The automatic classification of web pages based on neural networks / Zhang Yizhong, Zhao Mingsheng, Wu Youshou // Neural Information Processing, ICONIP2001 Proceedings, 2001. – Р. 570-575.
- Hwanjo Yu. Web Page Classification without N Chang // IEEE Transactions on Knowledge and Data Engineering, January, 2004. – Vol. 16, №1. – P. 70-81.
- Воротницкий Ю. И. Принципы обеспечения безопасности образовательных информационных сетей / Ю. И. Воротницкий, Се Цзиньбао // Межд. конф.-форум «Информационные системы и технологии». – Минск, 2009. – Ч. 2.– С.26-29.