
Реферат з теми випускної роботи
Зміст
- 1. Мета і завдання
- 2. Актуальність теми
- 3. Передбачувана наукова новизна
- 4. Плановані практичні результати
- 5. Огляд досліджень і розробок
- 5.1 Огляд досліджень і розробок по темі на глобальному рівні
- 5.2 Огляд досліджень і розробок по темі на національному рівні
- 5.3 Огляд досліджень і розробок по темі на локальному рівні
- 6. Проблеми обмеження доступу до веб–ресурсів в освітніх системах
- 7. Інформаційна безпека веб–ресурсів для користувачів інтелектуальних навчальних систем
- 8. Алгорітми визначення інформаційної безпеки веб-ресурсів для користувачів інтелектуальних навчальних систем
- 9. Напрями вдосконалення алгоритмів
- 10. Висновки
- Список джерел
1. Мета і завдання
Метою роботи є розробка алгоритмів підвищення безпеки доступу до зовнішніх інформаційних ресурсів з корпоративних освітніх мереж з урахуванням характерних для них загроз безпеки, а також особливостей контингенту користувачів, політики безпеки, архітектурних рішень, ресурсного забезпечення.
Виходячи з поставленої мети, в роботі вирішуються наступні завдання:
1. Виконати аналіз основних загроз інформаційної безпеки в освітніх мережах.
2. Розробити метод обмеження доступу до небажаних інформаційних ресурсів в освітніх мережах.
3. Розробити алгоритми, що дозволяють здійснювати сканування веб-сторінок, пошук прямих з'єднань і завантаження файлів для подальшого аналізу потенційно шкідливого коду на сайтах.
4. Розробити алгоритм ідентифікації небажаних інформаційних ресурсів на сайтах.
2. Актуальність теми
Сучасні інтелектуальні навчальні системи є Web-орієнтованими і передбачають для своїх користувачів можливість роботи з різними видами локальних і віддалених освітніх ресурсів. Проблема безпечного використання інформаційних ресурсів (ІР), розміщених у мережі Інтернет, постійно набуває все більшої актуальності [1,2]. Одним з методів, використовуваних при вирішенні даної проблеми, є обмеження доступу до небажаних інформаційних ресурсів.
Оператори, що надають доступ в Інтернет освітнім установам, зобов'язані забезпечити обмеження доступу до небажаних ІР. Обмеження здійснюється шляхом фільтрації операторами за списками, регулярно оновлюваних в установленому порядку. Однак, з огляду на призначення і користувача аудиторію освітніх мереж, доцільно використовувати більш гнучку, самообучающуюся систему, яка дозволить динамічно розпізнавати небажані ресурси і захищати від них користувачів.
В цілому доступ до небажаних ресурсів несе наступні загрози: пропаганду протиправних та асоціальних дій, таких, як політичний екстремізм, тероризм, наркоманія, поширення порнографії та інших матеріалів; відволікання учнів від використання комп'ютерних мереж в освітніх цілях; утруднення доступу в Інтернет через перевантаження зовнішніх каналів, що мають обмежену пропускну здатність. Перераховані вище ресурси часто використовуються для впровадження шкідливих програм з супутніми їм погрозами [3,4].
Існуючі системи обмеження доступу до мережевих ресурсів мають можливість перевіряти на відповідність заданим обмеженням не тільки окремі пакети, але і їх вміст-контент, який передається через мережу. В даний час в системах контентної фільтрації застосовуються такі методи фільтрації web-контенту: по імені DNS або конкретному IP-адресою, за ключовими словами всередині web-контенту і за типом файлу. Щоб блокувати доступ до певного web-вузла або групі вузлів, необхідно задати безліч URL, контент яких є небажаним. URL-фільтрація забезпечує ретельний контроль безпеки мережі. Однак не можна передбачити заздалегідь всі можливі неприйнятні URL-адреси. Крім того, деякі web-вузли з сумнівним інформаційним наповненням працюють не з URL, а виключно з IP-адресами.
Один із шляхів вирішення задачі полягає у фільтрації контенту, одержуваного по протоколу HTTP. Недоліком існуючих систем контентної фільтрації є використання списків розмежування доступу, формованих статично. Для їх наповнення розробники комерційних систем контентної фільтрації наймають співробітників, які ділять контент на категорії і складають рейтинг записів у базі даних [5].
Для усунення недоліків існуючих систем фільтрації контенту для освітніх мереж актуальна розробка систем фільтрації web-трафіку з динамічним визначенням категорії web-ресурсу по вмісту його сторінок.
3. Передбачувана наукова новизна
Алгоритм обмеження доступу користувачів інтелектуальних навчальних систем до небажаних ресурсів Інтернет-сайтів, заснований на динамічному формуванні списків доступу до інформаційних ресурсів шляхом їх відкладеної класифікації.
4. Плановані практичні результати
Розроблені алгоритми можуть використовуватися в системах обмеження доступу до нежелетельним ресурсів в інтелектуальних системах комп'ютерного навчання.
5. Огляд досліджень і розробок
5.1 Огляд досліджень і розробок по темі на глобальному рівні
Проблемам забезпечення інформаційної безпеки присвячені роботи таких відомих вчених як: H.H Безруков, П.Д. Зегжда, A.M. Івашко, А.І. Костогриз, В.І. Курбатов К. Лендвер, Д. Маклін, AA Молдовян, H.A. Молдовян, А.А.Малюк, Е.А.Дербін, Р. сандхі, Дж. М. Керрол, та інших. Разом з тим, незважаючи на гнітючий обсяг текстових джерел у корпоративних і відкритих мережах, в області розробки методів і систем захисту інформації в даний час недостатньо представлені дослідження, спрямовані на аналіз загроз безпеки і дослідження обмеження доступу до небажаних ресурсів при комп'ютерному навчанні з можливостями доступу до Web.
5.2 Огляд досліджень і розробок по темі на національному рівні
В Україні провідним дослідником в даній сфері є Домарев В.В. [7]. Захистом інформації в навчальних системах Зайняла Ю.С. [8]
6. Проблеми обмеження доступу до веб-ресурсів в освітніх системах
Розвиток інформаційних технологій в даний час дозволяє говорити про два аспекти опису ресурсів Інтернет-контент та інфраструктура доступу. Під інфраструктурою доступу прийнято розуміти безліч апаратних і програмних засобів, що забезпечують передачу даних у форматі IP-пакетів, а контент визначається як сукупність форми подання (наприклад, у вигляді послідовності символів в певній кодуванні) і контенту (семантики) інформації. Серед характерних властивостей такого опису слід виділити наступні:
1. незалежність контенту від інфраструктури доступу;
2. безперервне якісне і кількісне зміна контенту;
3. поява нових інтерактивних інформаційних ресурсів («живі журнали», соціальні мережі, вільні енциклопедії та ін), в яких користувачі безпосередньо беруть участь у створенні мережевого контенту.
При вирішенні завдань управління доступом до інформаційних ресурсів велике значення мають питання вироблення політики безпеки, які вирішуються по відношенню до характеристик інфраструктури та мережевого контенту. Чим вище рівень опису моделі інформаційної безпеки, тим більшою мірою управління доступом орієнтоване на семантику мережевих ресурсів. Очевидно, що MAC і IP-адреси (канальний і мережевий рівень взаємодії) інтерфейсів мережевих пристроїв неможливо прив'язати до якоїсь категорії даних, так як один і той же адреса може представляти різні сервіси. Номери портів (транспортний рівень), як правило, дають уявлення про тип сервісу, але якісно ніяк не характеризують інформацію, що надається цим сервісом. Наприклад, неможливо віднести певний Web-сайт до однієї з семантичних категорій (ЗМІ, бізнес, розваги і т. д.) тільки на підставі інформації транспортного рівня. Забезпечення інформаційного захисту на прикладному рівні впритул наближається до поняття контентної фільтрації, тобто управління доступом з урахуванням семантики мережевих ресурсів. Отже, чим більше орієнтована на контент система управління доступом, тим більш диференційований підхід стосовно до різних категорій користувачів і інформаційних ресурсів можна реалізувати з її допомогою. Зокрема, семантично орієнтована система управління здатна ефективно обмежити доступ учнів освітніх установ до ресурсів, не сумісним із процесом навчання.
Можливі варіанти процесу отримання веб-ресурсу представлені на рис.1
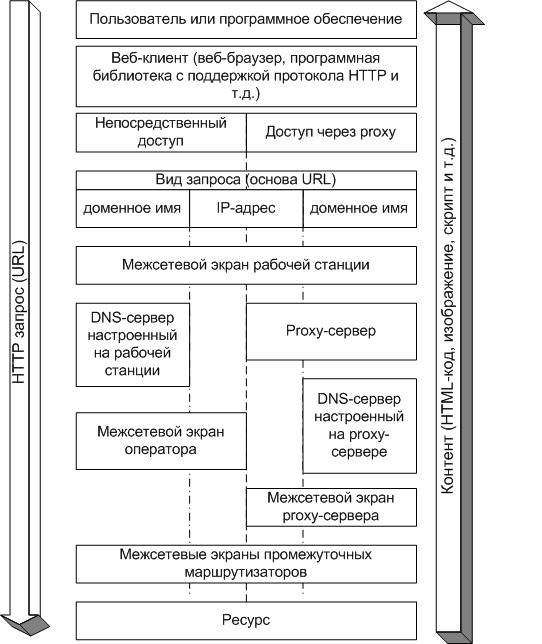
Щоб забезпечити гнучкий контроль використання Інтернет ресурсів, необхідно ввести в компанії-операторі відповідну політику використання
ресурсів освітньою організацією. Ця політика може реалізовуватися як вручну
, так і автоматично. Ручне
реалізація означає,
що в компанії є спеціальний штат співробітників, які в режимі реального часу або по журналах маршрутизаторів, проксі-серверів або міжмережевих
екранів ведуть моніторинг активності користувачів освітньої установи. Такий моніторинг є проблематичним, оскільки вимагає великих трудовитрат.
Щоб забезпечити гнучкий контроль використання Інтернет ресурсів, компанія повинна дати адміністратору інструмент для реалізації політики використання
ресурсів організацією. Цій меті служить контентна фільтрація. Її суть полягає в декомпозиції об'єктів інформаційного обміну на компоненти, аналізі
вмісту цих компонентів, визначенні відповідності їх параметрів прийнятій політиці використання Інтернет-ресурсів та здійсненні певних дій за результатами
такого аналізу. У разі фільтрації веб трафіку під об'єктами інформаційного обміну маються на увазі веб запити, вміст веб сторінок, що передаються по
запиту користувача файли.
Користувачі навчальної організації отримують доступ до мережі Інтернет виключно через proxy-сервер. При кожній спробі отримання доступу до того чи іншого ресурсу proxy-сервер перевіряє – не внесений чи ресурс в спеціальну базу. У разі якщо такий ресурс розміщений в базі заборонених – доступ до нього блокується, а користувачеві видається на екран відповідне повідомлення.
У разі, якщо запитаний ресурс відсутній в базі заборонених ресурсів то доступ до нього надається, проте запис про відвідування даного ресурсу фіксується в спеціальному службовому журналі. Один раз на день (або з іншим періодом) proxy-сервер формує перелік найбільш відвідуваних ресурсів (у вигляді списку URL) і відправляє його експертам. Експерти (адміністратори системи) з використанням відповідної методики перевіряють отриманий перелік ресурсів і визначає їх характер. У разі, якщо ресурс має нецільовий характер, експерт здійснює його класифікацію (порноресурс, ігровий ресурс) і вносить зміну до бази даних. Після внесення всіх необхідних змін оновлена редакція бази даних автоматично пересилається всім proxy-серверам, підключеним до системи. Схема фільтрації нецільових ресурсів на proxy-серверах наведена на рис. 2.
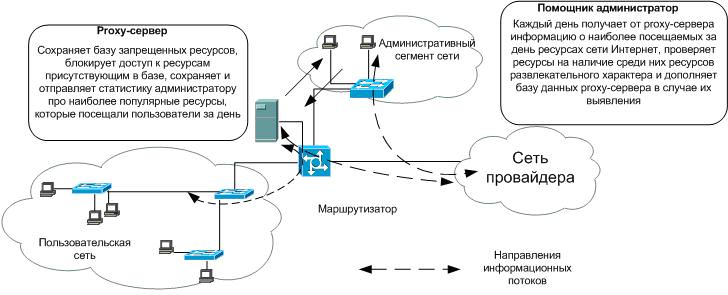
Проблеми фільтрації нецільових ресурсів на proxy-серверах наступні. За централізованої фільтрації необхідна висока продуктивність обладнання центрального вузла, велика пропускна спроможність каналів зв'язку на центральному вузлі, вихід з ладу центрального вузла веде до повного виходу з ладу всієї системи фільтрації.
При децентралізованій фільтрації «на місцях» безпосередньо на робочих станціях або серверах організації велика вартість розгортання і підтримки.
При фільтрації за адресою на
етапі відправлення запиту відсутня превентивна реакція на наявність небажаного контенту, складності при фільтрації маскуються
веб-сайтів.
При фільтрації по контенту необхідна обробка великих обсягів інформації при отриманні кожного ресурсу, складність обробки ресурсів підготовлених з використанням таких засобів як Java, Flash.
7. Інформаційна безпека веб-ресурсів для користувачів інтелектуальних навчальних систем
Розглянемо можливість управління доступом до ІР за допомогою поширеного рішення, заснованого на ієрархічному принципі комплексування засобів управління доступом до ресурсів Інтернет (рис.3). Обмеження доступу до небажаних ІР з ІОС може бути забезпечено шляхом поєднання таких технологій як межсетевое екранування, використання проксі-серверів, аналіз аномальної діяльності з метою виявлення вторгнень, обмеження смуги пропускання, фільтрація на основі аналізу змісту (контенту), фільтрація на підставі списків доступу. При цьому однією з ключових завдань є формування та використання актуальних списків обмеження доступу.
Фільтрація небажаних ресурсів проводиться відповідно до діючих нормативних документів на підставі публікованих у встановленому порядку списків. Обмеження доступу до іншим інформаційним ресурсам проводиться на підставі спеціальних критеріїв, що розробляються оператором освітньої мережі.
Доступ користувачів з частотою, нижче заданої навіть до потенційно небажаного ресурсу, є допустимим. Аналізу і класифікації підлягають тільки затребувані ресурси, тобто ті, для яких число запитів користувачів перевищила задане граничне значення. Сканування і аналіз здійснюються через деякий час після перевищення числа запитів порогового значення (в період мінімального завантаження зовнішніх каналів).
Скануються непоодинокі веб-сторінки, а всі пов'язані з ними ресурси (шляхом аналізу наявних на сторінці посилань). В результаті даний підхід дозволяє в процесі сканування ресурсу визначати наявність посилань на шкідливі програми.

Автоматизована класифікація ресурсів проводиться на корпоративному сервері клієнта – власника системи. Час класифікації визначається використовуваним методом, в основі якого лежить поняття відкладеної класифікації ресурсу. При цьому передбачається, що доступ користувачів з частотою нижче заданої навіть до потенційно небажаного ресурсу є допустимим. Це дозволяє уникнути дорогої класифікації на льоту
. Аналізу та автоматизованої класифікації підлягають тільки затребувані ресурси, тобто ресурси, частота запитів користувачів до яких перевищила задане граничне значення. Сканування і аналіз здійснюються через деякий час після перевищення числа запитів порогового значення (в період мінімального завантаження зовнішніх каналів). Метод реалізує схему динамічного побудови трьох списків: чорного
(ПСП), білого
(БСП) і сірого
(ССП). Ресурси, що знаходяться в чорному
списку заборонені для доступу. Білий
список містить перевірені дозволені ресурси. Сірий
список містить ресурси, які хоча б один раз були затребувані користувачами, але не пройшли класифікацію. Первісне формування і подальша ручна
коректування чорного
списку проводиться на підставі офіційної інформації про адреси заборонених ресурсів, що надаються уповноваженим державним органом. Первісне зміст білого
списку складають рекомендовані для використання ресурси. Будь-який запит ресурсу, що не відноситься до чорного
списку, задовольняється. У тому випадку, якщо цей ресурс не знаходиться в білому
списку, він поміщається в сірий
список, де фіксується кількість запитів до цього ресурсу. Якщо частота запитів перевищує деяке порогове значення, проводиться автоматизована класифікація ресурсу, на підставі чого він потрапляє в чорний
або білий
список.
8. Алгоритми визначення інформаційної безпеки веб-ресурсів для користувачів інтелектуальних навчальних систем
Алгоритм обмеження доступу. Обмеження доступу до небажаних ресурсів Інтернет-сайтів грунтується на наступному визначенні поняття ризику доступу до небажаного ІР в ИОС. Ризиком доступу до небажаного i-му ІР, віднесеному до к-му класу ІР, будемо називати величину, пропорційну експертною оцінкою збитку, що наноситься небажаним ІР даного виду ІОС або особи користувача і числу звернень до даного ресурсу за заданий відрізок часу:

За аналогією з класичним визначенням ризику як твори ймовірності реалізації загрози на вартість завдається шкоди, дане визначення трактує ризик як математичне очікування величини можливого збитку від доступу до небажаного ІР. При цьому величина очікуваного збитку визначається ступенем впливу ІР на особистості користувачів, яка в свою чергу прямо пропорційна числу користувачів, що випробували цей вплив.
У процесі аналізу будь-якого веб-ресурсу, з точки зору бажаності або небажаності доступу до нього, необхідно розглядати наступні основні компоненти кожної його сторінки: контент, тобто текстову та іншу (графічну, фото, відео) інформацію, розміщену на цій сторінці; контент, розміщений на інших сторінках цього ж веб-сайту (отримати внутрішні посилання з вмісту завантажених сторінок можна за регулярними виразами); з'єднання з іншими сайтами (як з точки зору можливого завантаження вірусів і троянських програм), так і з точки зору наявності небажаного контенту. Алгоритм обмеження доступу до небажаних ресурсів з використанням списків наведено на рис. 4.
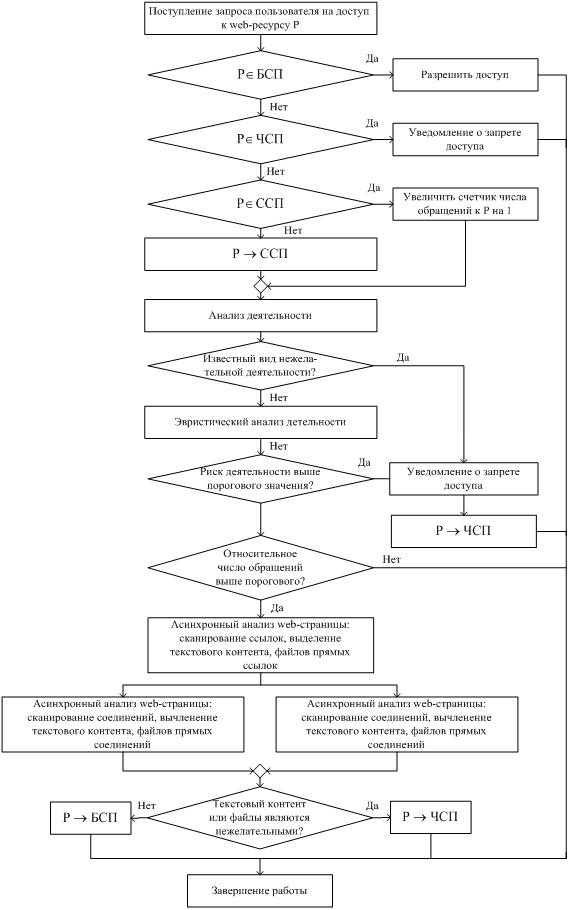
Алгоритм визначення небажаних Web-сторінок. Для класифікації контенту – текстів веб-сторінок – необхідно вирішити наступні завдання: завдання категорій класифікації; витяг з вихідних текстів інформації, піддається автоматичному аналізу; створення колекцій проклассифицировать текстів; побудова та навчання класифікатора, що працює з отриманими наборами даних.
Навчальне безліч проклассифицировать текстів піддають аналізу, виділяючи терми – найбільш часто вживані словоформи в цілому і по кожній категорії класифікації окремо. Кожен вихідний текст представляють у вигляді вектора, компонентами якого є характеристики зустрічальності даного терма в тексті. Для того щоб уникнути розрідженості векторів і зменшити їх розмірність, словоформи доцільно привести до початкової форми методами морфологічного аналізу. Після цього вектор слід нормалізувати, що дозволяє домогтися більш коректного результату класифікації. Для однієї веб-сторінки можна сформувати два вектори: для інформації, яка відображається для користувача, і для тексту, наданого пошукових машин.
Відомі різні підходи до побудови класифікаторів веб-сторінок. Найбільш часто використовуваними є [9–13]: байесовский класифікатор; нейронні мережі; лінійні класифікатори; метод опорних векторів (SVM). Всі вищеназвані методи вимагають навчання на навчальній колекції та перевірки на тестирующей колекції. Для бінарної класифікації можна вибрати наївне байєсівського рішення, що передбачає незалежність один від одного характеристик у векторному просторі. Будемо вважати, що всі ресурси необхідно класифікувати як бажані і небажані. Тоді вся колекція зразків текстів веб-сторінок розділяється на два класи: C = { C1, C2 } причому апріорна ймовірність кожного класу P (Ci), i = 1,2. При досить великій колекції зразків можна вважати, що P (Ci) дорівнює відношенню кількості зразків класу Ci до загальної кількості зразків. Для деякого підлягає класифікації зразка D з умовної ймовірності P (D / Ci), згідно теоремі Байеса, може бути отримана величина P (Ci / D):

причому
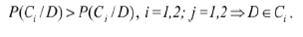
з урахуванням сталості P (D) отримуємо:
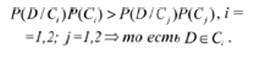
Припускаючи незалежність один від одного термів у векторному просторі, можна отримати наступне співвідношення:

Для того щоб більш точно класифікувати тексти, характеристики яких близькі (наприклад, розрізняти порнографію та художню літературу, в якій описуються еротичні сцени), слід ввести вагові коефіцієнти:
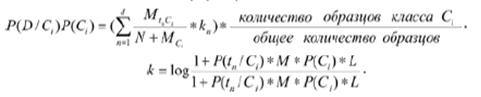
Если kn=k; если kn меньше k, kn.=1/|k|. Тут M – частота всіх термів в базі даних зразків, L – кількість всіх зразків.
9. Напрями вдосконалення алгоритмів
Надалі передбачається розробити алгоритм аналізу посилань з метою виявлення впровадження шкідливого коду в код web-сторінки і порівняти байесовский класифікатор з методом опорних векторів.
10. Висновки
Виконано аналіз проблеми обмеження доступу до веб-ресурсів в освітніх системах. Обрані базові принципи фільтрації нецільових ресурсів на proxy-серверах на основі формування і використання актуальних списків обмеження доступу. Розроблено алгоритм обмеження доступу до небажаних ресурсів з використанням списків, що дозволяє динамічно формувати та оновлювати списки доступу до ІР на основі аналізу їх контенту з урахуванням частоти відвідувань і контингенту користувачів. Для виявлення небажаного контенту розроблений алгоритм на основі наявного байєсівського класифікатора.
Список використаних джерел
- Зима В. М. Безопасность глобальных сетевых технологий / В. Зима, А. Молдовян, Н. Молдовян. – 2–е изд. – СПб.: БХВ–Петербург, 2003. – 362 c.
- Воротницкий Ю. И. Защита от доступа к нежелательным внешним информационным ресурсам в научно-образовательных компьютерных сетях / Ю. И. Воротницкий, Се Цзиньбао // Мат. XIV Межд. конф. «Комплексная защита информации». – Могилев, 2009. – С. 70–71.
- Varatnitsky Y. Web Application Vulnerability Analysis and Risk Control / Y. Varatnitsky, Xie Jinbao // J. of Computer Applications and Software. – 2010, №10. – P. 279–280, 287.
- Varatnitsky Y. Based on source code analysis detection method of web-based malicious code / Y. Varatnitsky, Xie Jinbao //J. of Computer & Information Technology. – 2010, №1–2. – P. 49–53.
- Хилл Б. Решения для фильтрации Web-контента // Открытые системы: [Электронный документ] – (http://www.osp.ru/win2000/2004/05/177073/).
- Домарев В.В."Безопасность информационных технологий. Системный подход" – К.:ООО ТИД «Диасофт», 2004.–992 с
- Химка С. С. Разработка моделей и методов для создания системы информационной безопасности корпоративной сети предприятия с учетом различных критериев // реферат выпускной работы магистра Факультет вычислительной техники и информатики ДонНТУ. 2009.
- Заняла Ю.С.Защита информации в обучающих системах // реферат выпускной работы магистра Факультет вычислительной техники и информатики ДонНТУ. 2007.
- Маслов М. Ю. Автоматическая классификация веб-сайтов / М. Ю. Маслов, А. А. Пяллинг, С. И. Трифонов. – Режим доступа: rcdl.ru/doc/2008/230_235_paper27. pdf. – Дата доступа: 08.11.2011.
- Wu lide. Large Scale Text Process / Wu lide. ShangHai: Fudan University Press, 1997. – 180 p.
- Zhang Yizhong.The automatic classification of web pages based on neural networks / Zhang Yizhong, Zhao Mingsheng, Wu Youshou // Neural Information Processing, ICONIP2001 Proceedings, 2001. – Р. 570–575.
- Hwanjo Yu. Web Page Classification without N Chang // IEEE Transactions on Knowledge and Data Engineering, January, 2004. – Vol. 16, №1. – P. 70–81.
- Воротницкий Ю. И. Принципы обеспечения безопасности образовательных информационных сетей / Ю. И. Воротницкий, Се Цзиньбао // Межд. конф.-форум «Информационные системы и технологии». – Минск, 2009. – Ч. 2.– С.26–29.