Введение
В наше время характерно массовое внедрение информационных технологий в различные области человеческой жизни. Разработка и использование интеллектуальных транспортных систем выполняется для повышения безопасности движения и улучшения дорожной обстановки. Решение задачи распознавания автомобильных номеров можно представить в виде комплекса алгоритмов обработки и анализа изображений, включающего в себя обнаружение области номера на изображении, сегментацию символов и их распознавание.
Стоит добавить, что к технологическим факторам, искажающим качество цифрового изображения, можно отнести ряд внешних факторов, таких как освещение окружающей сцены, движение объектов внутри нее и др. Для получения высокой точности распознавания текстовых символов, находящихся на автомобильном регистрационном знаке, необходим алгоритм, позволяющий решить задачу детектирования и распознавания в присутствии шумов, при низкой резкости и контрастности изображения, ошибочном балансе белого и при прочих помехах, рассматриваемых в рамках области цифровой обработки изображений.
Целью данной статьи является обзор методов и алгоритмов нормализации найденных изображений номерных знаков и сегментации символов на них, а также выявление их достоинств и недостатков.
Методы обработки изображений и распознавания с них образов
Анализ только части границ
Самый очевидный способ выделения номера – поиск прямоугольного контура. Для определения границ выполняется фильтрация изображения, полученного с камеры, затем производится выделение найденных контуров и их анализ. Алгоритм работает в основном только тогда, когда контур изображения легко читаем, ничем не загорожен и имеет высокое разрешение. Более стабилен и практичен алгоритм, где от рамки анализируется только его часть, выделяются контуры, затем выполняется поиск вертикальных прямых. Для любых двух прямых, расположенных недалеко друг от друга, с небольшим сдвигом по оси y, с правильным отношением расстояния между ними к их длине, рассматривается гипотеза того, что номер располагается между ними [1]. Данный алгоритм имеет сходства с упрощенным методом HOG.
Гистограммный анализ регионов
Метод анализа гистограмм изображения основывается на предположении, что частотная характеристика региона с номером отлична от частотной характеристики окрестности. На изображении выделяются границы (выделение высокочастотных пространственных компонент изображения), строится проекция изображения на ось y (иногда и на ось x) [2]. Максимум полученной проекции может совпасть с расположением номера. У такого подхода есть существенный минус – машина по размеру должна быть сопоставима с размером кадра, т. к. фон может содержать надписи или другие детализированные объекты.

Рисунок 1 – Вертикальная проекция изображения а) на ось у
Статистический анализ, классификаторы
Лучшие методы, хотя и недостаточно часто используемые, это методы, опирающиеся на различные классификаторы. Например, хорошо работает обученный каскад Хаара. Такие методы позволяют анализировать область на предмет наличия в ней характерных для номера отношений, точек или градиентов. Такие методы позволяют находить номер в сложных и нетипичных условиях.
Многие методы в реальных алгоритмах прямо или косвенно опираются на наличие границ номера. Даже если границы не используются при детектировании номера, то могут использоваться в дальнейшем анализе.
Для статистических алгоритмов сложным случаем может оказаться даже относительно чистый номер в хромированной (светлой) рамке на белой машине, так как оно встречается куда реже грязных номеров и может не встретиться достаточное количество раз при обучении.
Нормализации символов
Нормализация изображения номерного знака проводится в два этапа. На первом этапе определяется угол поворота номера в плоскости изображения. На втором – выполняется алгоритм получения нормализованного изображения номера с учетом угла его поворота. Для поворота области изображения используется алгоритм, основанный на соответствующем аффинном преобразовании координат. Для уменьшения искажений изображения при повороте, связанных с его дискретным характером, используется метод, основанный на билинейной интерполяции по ближайшим четырем пикселям [3].
На первом этапе выполняется операция подчеркивания границ номера на основе линейного оператора Собеля для горизонтальных границ, имеющего маску свертки:
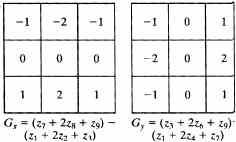
Оператор Собеля более чувствителен к направлениям границ, близким к горизонтальному, в результате чего на полученном изображении хорошо выделяется верхняя и нижняя части номерного знака, как показано на рис. 2.

Рисунок 2 – а) фрагмент исходного изображения с найденным положением номера; б) вырезанное изображение номерного знака с расширением на 40% в вертикальном направлении; в) результат подчеркивания границ
На втором этапе выполняется расчет карты плотностей найденных точек границ в пространстве параметров пространственных координат согласно преобразованию Хафа. Целью второго этапа является определение уравнения прямых, соответствующих верхней и нижней границе номерного знака. Каждая точка карты границ порождает множество проходящих через неё прямых, которые удовлетворяют уравнению:
yi = axi + b,
что в пространстве параметров соответствует:
b = – axi + yi.
Вес прямых v(xi, yi) соответствует значению яркости изображения результата подчеркивания границ (рис. 2в). Таким образом, наделяя весом v прямые и проводя их в пространстве параметров a и b с яркостью, равной весу, получим изображения, подобные приведенному на рис. 3 [4].

Рисунок 3 – Карта результатов преобразования Хафа
Сегментация номерного знака
Сегментацией является процесс разделения ранее детектированного номерного знака на отдельные символы посредством построения разделительных линий между ними на основе наименее важных пикселей и с целью их дальнейшего распознавания.
Для этого наиболее часто используется построение горизонтальной проекции предварительно бинаризованного изображения, как показано на рис. 4. Данные методы требуют довольно малого времени вычисления, однако изменение положения камеры относительно транспортного средства приводит к перспективным искажениям изображения, чьи вертикальная и горизонтальная оси уже не будут параллельны осям номерного знака. Вследствие этого в случаях наклона номера автомобиля проекционные методы приводят к значительным ошибкам.
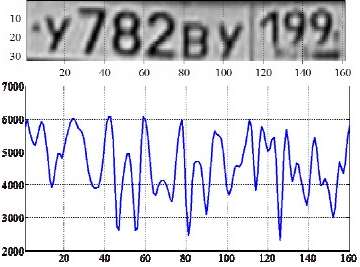
Рисунок 4 – Сегментация номерной пластины методом проекции
Альтернативой таким методам может служить метод поиска разделяющих линий, основанный на минимизации стоимостной функции изображения. Он позволяет производить сегментацию цифрового изображения, учитывая его содержание. В основе алгоритма лежит использование стоимостной функции некоторой условной величины, характеризующей важность данного пикселя в текущем изображении. Разделительные линии между символами проводятся по тем цепочкам пикселей, которые наименее важны в этом изображении.
Распознавание символов
Задача распознавания текста или отдельных символов (optical character recognition, OCR) с одной стороны сложная, а с другой – вполне классическая. Существует множество алгоритмов её решения, некоторые из которых достигли совершенства. В целом, методы распознавания текста можно разбить на два класса: структурные методы, основанные на морфологии и анализе контура, имеющие дело с бинаризованным изображением, и растровые методы, основанные на анализе непосредственного изображения. При этом зачастую используется комбинация структурных и растровых методов.
Очень простым для понимания является метод K-nearest, который, несмотря на свою примитивность, часто может побеждать не самые удачные реализации SVM или нейросетевых методов.
В теории, если записать очень большую базу с примерами символов, снятых под разными углами, освещением, со всеми возможными потертостями, то K-nearest – это все, что нужно. Но тогда нужно очень быстро рассчитывать дистанцию между изображениями, а, значит, бинаризовать его и использовать XOR.
Корреляционный
Часто методы, которые используются в распознавании изображений, построены на эмпирических подходах. Но никто не запрещает использовать математический аппарат теории вероятности, который был просто отполирован в задачах детектирования сигнала в радиолокационных системах. Шрифт на автомобильном номере нам известен, шум фотокамеры или пыль на номере можно с натяжкой назвать гауссовским. Существует некоторая неопределенность по расположению символа и его наклону, но эти параметры можно перебрать. Если мы оставляем изображение не бинаризованным, то нам еще неизвестна и амплитуда сигнала, т. е. яркость символа.
Таким образом, все сводится к операции расчета ковариации входного сигнала с гипотетическим (с учетом заданных смещений и поворотов):
,где X – входной сигнал, Y – гипотеза. Обозначение E – математическое ожидание.
Если нужно выбрать из разных символов, то гипотезы по повороту и смещению строятся для каждого символа. Если известно, что входное изображение содержит символ, то максимум ковариации по всем гипотезам определит символ, его смещение и наклон. Тут, конечно, встает проблема близости изображений различных символов (р
и в
, о
и с
и др.). Самое простое – ввести для каждого символа весовую матрицу коэффициентов.
Иногда такие методы называются «template-matching», что полностью отражает их суть. Задаются образцы – сравнивается входное изображение с образцами. Если есть какая-то неопределенность по параметрам, то, либо перебираются все возможные варианты, либо используются адаптивные подходы.
Достоинства метода:
предсказуемый и хорошо изученный результат, если шум хоть немного соответствует выбранной модели;
если шрифт задан строго, то способен разглядеть сильно пыльный/грязный/потертый символ.
Недостатком метода является то, что он вычислительно затратный.
Заключение
В статье были рассмотрены основные методы обработки изображений и распознавания тестовой информации, содержащейся в автомобильных регистрационных знаках.
Рассмотрены наиболее известные алгоритмы детектирования области автомобильного номера на цифровом изображении. Выявлены основные достоинства и недостатки рассмотренных алгоритмов детектирования номеров.
В дальнейшем планируется применение этих методов для распознавания автомобильных номеров и проверка их на эффективность.
Литература
Saqib Rasheed Automated Number Plate Recognition Using Hough Lines and Template Matching / Saqib Rasheed, Asad Naeem, Omer Ishaq – Proceedings of the World Congress on Engineering and Computer Science Vol I WCECS 2012, 2012 – 5с.
Ondrej Martinsky Algorithmic and mathematical principles of automatic number plate recognition systems / B.SC. Thesis. – Brno University of technology, faculty of information technology, department of intelligent systems, 2007 – 76 с.
Гонсалес Р. Цифровая обработка изображений / Р. Гонсалес, Р. Вудс – М.: Техносфера, 2006 – 1072 с.
Мурыгин К.В. Нормализация изображения автомобильного номера и сегментация символов для последующего распознавания / К.В. Мурыгин –
Штучний інтелект
3, 2010 – 6 с.