1. ВВЕДЕНИЕ
Проблема распознавания номерного знака транспортного средства очень интересна и на протяжении многих лет привлекает множество исследователей и экспертов машинного зрения. Применения такой системы огромны и могут варьироваться от парковки безопасности до управления трафиком. Существуют различные подходы к решению этой проблемы, например, на основе текстур, на основе морфологии, и на основе границ. В работе, представлен подход на основе морфологии для идентификации номерных знаков в образе автомобиля. Процесс распознавания слегка отклоняется от традиционного подхода с использованием оптического распознавания символов (OCR) системы и использует концепцию цветных когерентных векторов [1]. Исследователями были предложены различные решения для задачи идентификации номерных знаков и распознавания изображений. Ученые Вроцлавского университета [2] предложили метод для локализации номерных знаков, который требует подключенного анализа компонентов YUV модели [13] на изображении. Применение преобразования Хафа [3, 4 и 5] также было частично успешным в сокращении времени обработки для сегментации номерных знаков на изображении. Применение усовершенствованных методов детектирования перепада [6, 7] в сочетании с другими, такими как наклон и оценка проекции, является еще одним интересным решением этой проблемы. Для достижения более быстрой обработки в некоторых системах определяется порог размера номерного знака и регионов символов в них. Затем с использованием нечеткой логики и нейронных сетей алгоритмы [8, 9 и 11] сегментируют регионы символов и определяют символы в них. Несколько иной подход к проблеме сегментации представлен в среднем вахтовом методе сегментации [10]. Он определяет несколько регионов кандидатов в исходном изображении и использует такие функции, как прямоугольность, пропорции и плотность края, чтобы определить, является ли идентифицированной область номерного знака или нет. Все перечисленные выше исследовательские работ стремятся поддерживать правильный баланс между точностью алгоритма и его скоростью. Идентификация морфологическим методом весьма точна и метод распознавания цветным когерентным вектором чрезвычайно быстр. Тестовое приложение для экспериментальной оценки предложенного алгоритма было создано при помощи Microsoft Visual C # .NET. Этот алгоритм и его экспериментальные результаты будут проиллюстрированы более подробно в следующих разделах.
2. ОПРЕДЕЛЕНИЕ ОБЛАСТИ НОМЕРНОГО ЗНАКА
Первый этап этого алгоритма заключается в определении области в пределах изображения, где находится номерной знак. Были использованы основные математические морфологические [12] операции дилатации и эрозии. Во-первых, исходное изображение (рис. 1) преобразуется в монохромное с использованием двух различных порогов.

Рисунок 1 – Исходный пример изображения
Результаты применения этой операции на исходном изображении показано на рис. 2 и 3. Каждое из этих изображений используется для дальнейших шагов дилатации и эрозии.

Рисунок 2 – Монохромное изображение с порогом 78 между черным и белым

Рисунок 3 – Монохромное изображение с порогом 158 между черным и белым
Кроме того, изображение, представленное в рис. 3, подвергается операции дилатации с размером маски 9х9 и белый цвет является целевым. В результате этой операции белые области в исходном изображении расширены незначительно, результаты которой показаны на рис. 4.

Рисунок 4 – Дилатационное изображение с размером маски 9 на 9
Соответственно, операция эрозии применяется к изображению на рис. 2 с размером маски 30х105 пикселей. Эта операция уменьшает размер белых областей, и помогает в поддержании более крупных белых регионов и удаляя более мелких. Результаты этой операции показаны на рис. 5.
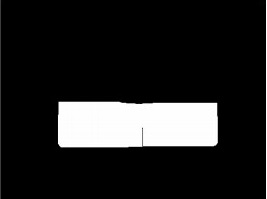
Рисунок 5 – Эродированное изображение с размером маски 30х105
После предварительной обработки набора подготовленного изображения, дилатационное изображение и эродированное изображение используются вместе для поиска областей, которые равны приблизительному размеру требуемого региона номерного знака. Наряду с этим соотношением, содержимое этого региона также рассматривается для определения узора, похожего на набор символов. Сегментированный регион, который лучше всего соответствует такой оценке, затем используется для следующей стадии алгоритма. Предложенный алгоритм идентификации успешно работает, даже если транспортное средство было выровнено камерой под углом 30 градусов по обе стороны. Образец нескольких результатов стадии идентификации изображений с различной ориентацией показан на рис. 6.

Рисунок 6 – Образец результатов стадии идентификации
3. РАСПОЗНАВАНИЕ СЕГМЕНТИРОВАННОГО РЕГИОНА НОМЕРНОГО ЗНАКА
Метод оптического распознавания символов часто используется для идентификации символов в извлеченном изображение номерного знака. Тем не менее, время обработки и точность этого метода сомнительна. Алгоритм, используемый в данной работе, представлен как крайне быстрый и точный метод распознавания номерных знаков. Алгоритм можно назвать неграмотным, в том смысле, что он не извлекает символы внутри изображения, а распознает изображение в целом. Для создания начальной базы данных, изображения необходимых номерных знаков предварительно обрабатываются и их параметры хранятся. В процессе распознавания эти параметры просто сравнению с теми, входного изображения в постоянное время и лучший результат получен. Из-за своей статической сложности это очень быстрый метод распознавания образов, а процесс добычи параметров для изображения номера основан на использовании цветного когерентного вектора [1]. Этот метод делит все полутоновое изображение на сегменты, где каждый сегмент представляет широкий спектр значений серого цвета. Это разделение изображения на сегменты приводит к сегментации символов от остального нежелательного фона. Следовательно, при сравнении этих параметров сегменты, представляющие символы, сравниваются друг с другом и наименьшие отображаются как общая ошибка. Таблица 1 показывает некоторые из успешных и неудачных случаев, возникших в ходе тестирования этого метода.
Таблица 1 – Примеры результата алгоритма распознавания

4. ЭКСПЕРИМЕНТАЛЬНЫЙ АНАЛИЗ
Чтобы проверить точность предложенного алгоритма, с помощью Microsoft Visual C # .NET было создано тестовое приложение. База данных имеет размер выборки из шестидесяти образов и несколько тестов с вариациями выравнивания, освещения и размера протестированных номерных знаков. Сорок семь из шестидесяти случаев были успешными, а тринадцать нет. Большинство неудач в эксперименте связано с неправильным выравниванием транспортного средства камерой или из-за ошибочной сегментации области номерного знака. Во время тестирования, алгоритм распознавания работал постоянно, а процесс выполнения алгоритма идентификации длился от одного до четырех секунд. В целом, результаты испытания показали точность 88 % и среднее время обработки около двух секунд. На рис. 7 представлен скриншот приложения, используемого в эксперименте.
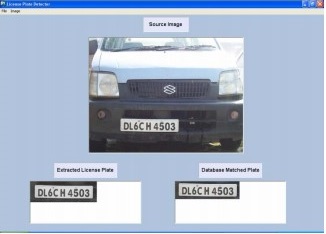
Рисунок 7 – Скриншот приложения
ВЫВОДЫ
Ранее были рассмотрены работы, которые касаются проблемы идентификации номерных знаков и распознавания, но есть необходимость для создания системы, которая уравновешивает точность и скорость. Алгоритм, предложенный в этой работе, использует математические морфологические операции дилатации и эрозии в сегменте региона номерного знака на изображении. Цветной когерентный вектор затем используется для получения ключевых параметров выделенной области. Эти ключевые параметры сравниваются с ранее сохраненной базой данных параметров, и отображается лучшее совпадение. Экспериментальный анализ неграмотного алгоритма распознавания номерных знаков привело к точности 88 % и занимает среднее время обработки двух секунд на изображение. Следовательно, этот алгоритм пытается установить баланс между точностью и скоростью, которыми должна обладать система идентификации и распознавания номерных знаков.
ССЫЛКИ ИСПОЛЬЗУЕМЫХ ИСТОЧНИКОВ
Greg Pass, Ramin Zabih and Justin Miller. Comparing Images Using Color Coherence Vectors. Computer Science Department, Cornell University
Halina Kwasnicka and Bartosz Wawrzyniak. License plate localization and recognition in camera pictures. AI-METH 2002 – Artificial Intelligence Methods
Tran Duc Duan, Duong Anh Duc, Tran Le Hong Du. Combining Hough Transform and Contour Algorithm for detecting Vehicles License-Plates. Proceedings of 2004 International Symposium on Intelligent Multimedia, Video and Speech Processing. October 2004
Remus Brad. License Plate Recognition System. Computer Science Department
Lucian Blaga
University, RomaniaMllig G. He, Alan L. Harvey, Tliurai Vinay. Hough Transform in Car Number Plate Skew Detection. International Symposium on Signal Processing and its Applications, ISSPA. August, 1996
Ming G. He, Alan L. Harvey, Paul Danelutti. Car Number Plate Detection With Edge Image Improvement. Intemational Symposium on Signal Processing and its Applications, ISSPA. August 1996
Vladimir Shapiro, Dimo Dimov,et al. Adaptive License Plate Image Extraction
International Conference on Computer Systems and Technologies – CompSysTech’2003
N. Zimic, J. Ficzko, M. Mraz, J. Virant. The Fuzzy Logic Approach to the Car Numlber Plate Locating Problem. IEEE. 1997
Eun Ryung Lee, Pyeoung Kee Kim, and Hang Joon Kim. Automatic Recognition of a Car License Plate Using Color Image Processing. IEEE. 1994
Wenjing Jia, Huaifeng Zhang and Xiangjian He. Mean Shift for Accurate Number Plate Detection. Proceedings of the Third International Conference on Information Technology and Applications (ICITA’05)
Opas Chutatape, Li Li, and Qian Xiaodong. Automatic License Number Extraction and Its Parallel Implementation. IEEE. 1999
Fernando Martin, Maite Garcia, Jose Luis Alba. New Methods For Automatic Reading of VLP's
YUV Color Model. http://en.wikipedia.org/wiki/YUV