Аннотация
Arthur K. Kordon Гибридные интеллектуальные системы для промышленного анализа данных. Предложен новый подход для промышленного анализа данных на основе интеграции трех ключевых вычислительных подходов для расчётов (генетическое программирование, аналитические нейронные сети и векторные машины поддержки). У разработанных эмпирических моделей есть хорошие возможности обобщения, явные отношения ввода/вывода, возможности самооценки, низкой порог внедрения и стоимость обслуживания. Предложенный подход был осуществлен в нескольких промышленных приложениях в Dow Chemical Company.
ВВЕДЕНИЕ
Гибридные интеллектуальные системы основаны на эффективных совместных действиях среди нескольких подходов ИИ таких, как символические системы с базой знаний, нечеткие системы, нейронные сети и генетические алгоритмы [1]. Хотя у различных подходов есть свои собственные преимущества и определенные прикладные области, часто они недостаточны, чтобы решить реальные промышленные проблемы. Типичный случай — одно из популярных промышленных применений нейронных сетей как мягкие датчики. Мягкий (или логически выведенный) датчики предполагают, что есть эмпирические отношения между некоторыми легко измеряемыми и непрерывно доступными переменными процесса и некоторыми критическими параметрами, связанными с качеством процесса, например молекулярное распределение. С начала 90–х тысячи мягких датчиков были применены в различных областях производства [2]. Однако наряду с преимуществами, которые мягкие датчики показали в различных промышленных условиях, появились несколько текущих и долгосрочных операционных проблем. Большинство проблем связано с некоторыми ограничениями, которые типичны для мягких датчиков на основе нейронных сетей. Из–за их иногда неэффективной, отличающейся структуры и плохой способности обобщения вне диапазона данных тренировки, их работа очень чувствительна к определенному режиму процесса. В результате этой уменьшенной надежности есть необходимость частой переквалификации. Заключительный эффект всех этих проблем — увеличенная стоимость обслуживания и постепенно уменьшаемая производительность и доверие.
Этот пример иллюстрирует негативное воздействие некоторых ограничений, характерных для отобранного подхода, когда сопоставляются разнообразные промышленные проблемы. Это также показывает потребность в эффективной интеграции различных интеллектуальных методов систем, чтобы иметь дело с увеличенной сложностью приложений реального мира.
Первая волна гибридных интеллектуальных систем, разработанных в начале 90–х, основана на ключевых компонентах мягкого вычисления (экспертные системы, нечеткая логика, нейронные сети и генетические алгоритмы). Различный механизм для сплава, преобразования, и интеграции этих методов, а также выгоды гибридных интеллектуальных систем обсужден в [1], [3], и современное состояние дано в [4].
Недавно, несколько новых интеллектуальных системных подходов показали замечательный теоретический рост и потенциал для решения сложных промышленных проблем. Сложные аналитические нейронные сети (внутренне разработанные в Dow Chemical Company) позволяют проводить очень быструю образцовую разработку скупых моделей черного ящика с пределами достоверности. Генетическое программирование (GP) может произвести явные функциональные решения, которые очень удобны для прямого внедрения онлайн в существующей информации о процессе и системах управления [5]. Векторные машины поддержки (SVM) дают огромные возможности для строительства эмпирических моделей с очень хорошей способностью обобщения [6].
Эти подходы - основание второй волны гибридных систем разведки. Новая методология для интеграции сложенных аналитических нейронных сетей, GP и SVM в гибридную интеллектуальную систему предложена в газете. Интегрированная методология усиливает преимущества отдельных методов, значительно уменьшает время разработки и поставляет прочные эмпирические модели со стоимостью низких эксплуатационных расходов. Преимущества предложенной методологии были продемонстрированы в нескольких успешных приложениях в Dow Chemical Company.
ТРЕБОВАНИЯ ДЛЯ УСПЕШНОГО ИНДУСТРИАЛЬНОГО АНАЛИЗА ДАННЫХ
Если цель чисто академического анализа данных может быть упрощенно определена как чтобы перенести данные в знание
, цель промышленного анализа данных состоит в том, чтобы перенести данные в стоимость
. Так как экономика явно включена в объективную функцию, стратегия промышленного анализа данных основана на таких факторах как уменьшение стоимости моделирования и увеличение эффективности анализа данных под широким кругом эксплуатационных условий. Очевидный результат этой стратегии — увеличенные усилия в качественной эмпирической разработке модели, которая встречается очень часто в экономическом оптимуме. Другое следствие экономически–стимулируемого промышленного анализа данных — это тенденция ускорить фундаментальный процесс разработки модели, уменьшая область поиска гипотезы с помощью символьной регрессии или высокоуровневых экспериментов.
Ключевой вопрос состоит в том, что осуществление продуктивной стратегии должно развивать последовательную методологию, которая эффективно объединяет различные подходы моделирования, необходимо поставить высококачественные модели с минимальными усилиями и обслуживанием. Главные требования к успешному промышленному анализу данных могут быть определены следующим образом:
- Робастный, быстрый, и денежно эффективный процесс разработки. Предположение заключается в том, что полученные в результате анализа данных модели должны быть более эффективным, чем дополнительные варианты (дизайн датчика с точки зрения
железа
или фундаментальная разработка модели). Особое значение имеет требование значительно уменьшить время разработки, улучшая последовательность и исполнение поставленных эмпирических моделей. Другой критический фактор должен сделать процесс развития легким в использовании с минимальными настраивающими параметрами и специализированными знаниями. - Низкая чувствительность чтобы обработать изменения. Изменения процесса, которые стимулируют различные операционные режимы, модернизации оборудования или колебания спроса на продукт, являются более правилом, чем исключением. Нереалистично ожидать, что все множество режима процесса будет захвачено данными тренировки и отражено в разработанных эмпирических или фундаментальных моделях. Потенциальное решение находится в моделировании подходов с лучшими возможностями экстраполяции по крайней мере 20% вне обучающего диапазона.
- Способность оценивать собственную производительность. Обычно модели, полученные из промышленного анализа данных, выводят самые критические параметры в производственных процессах, и как таковые требуют оценок с очень высоким уровнем надежности. Необходимо включать элементы самооценки качества прогноза. Предполагаемый подход должен использовать объединенных предсказателей [7] и их статистика как индикатор надежности работы модели.
- Низкая стоимость владения и обслуживания. Опыт от
классических
нейронных чистых мягких датчиков показывает, что львиная доля стоимости обслуживания находится в частой переквалификации и особенно в образцовой модернизации. Ожидание состоит в том, что при помощи моделей нечерного ящика с увеличенной надежностью потребность в переквалификации будет значительно уменьшена. Другим фактором, который способствует сокращению стоимости собственности является непринужденность внедрения в реальном времени. Особенно интересны явные функциональные модели, произведенные GP. Они хорошо поняты инженерами-технологами, непосредственно применимыми в системе управления, и не требуют специализированных знаний для обслуживания.
ИНТЕГРИРОВАННАЯ МЕТОДОЛОГИЯ ДЛЯ РАЗРАБОТКИ ГИБРИДНЫХ ИНТЕЛЛЕКТУАЛЬНЫХ СИСТЕМ
Цели предложенной интегрированной методологии состоят в том, чтобы удовлетворить определенные критерии успешного промышленного анализа данных, т.е. уменьшить время разработки, поставить модель с лучшей способностью обобщения и минимизировать внедрение и стоимость обслуживания. Главные блоки методологии и связанный процесс сжатия данных показаны на рисунке 1.
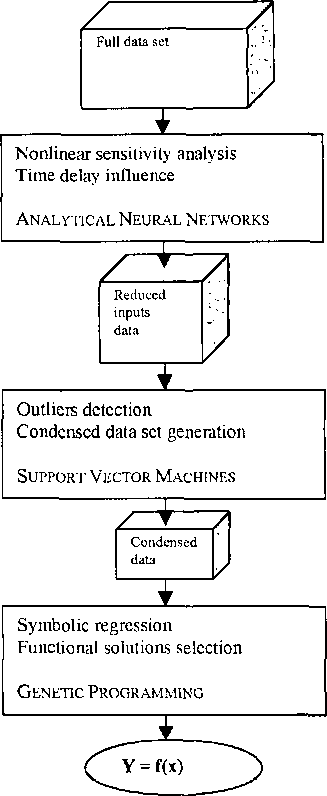
Рисунок 1 — Главные блоки интегрированной методологии для разработки гибридных интеллектуальных систем
Главная цель первого главного блока состоит в том, чтобы сократить количество исходных данных с самой высокой чувствительностью к выводам. Другая цель состоит в том, чтобы проверить через моделирование гипотезу, существует ли некоторая форма нелинейных отношений между отобранными исходными данными и производными. Это — критическая точка в целой методологии, потому что, если нейронная чистая модель не может быть построена, эмпирический образцовый процесс развития останавливается здесь. Заключение в этом случае могло состоять в том, что, если бы универсальный аппроксиматор, такой как нейронная сеть, не может захватить нелинейные отношения, не было бы никакого основания для переменной зависимости и никакой потребности искать другие методы. Анализ чувствительности основан на сложенных аналитических нейронных сетях. Большое преимущество этого типа нейронных сетей — это уменьшенное время разработки. В течение нескольких часов отобраны самые чувствительные исходные данные, исполнение лучших нейронных чистых моделей исследуется, и данные для в вычислительном отношении интенсивного символического регресса (поколение функции GP), шаг подготовлен. Как правило, тридцать сложенных нейронных сетей используются, чтобы улучшить обобщение и оценить нейронную чистую образцовую ошибку согласия. Этот шаг начинается с наиболее сложного строения всех возможных исходных данных. Во время анализа чувствительности, сокращая число исходных данных, постепенно уменьшает начальное сложное строение. Чувствительность каждой структуры — это среднее число расчетных производных в каждых из сложенных нейронных сетей. Процедура выполняет автоматическое устранение наименее значительных исходных данных и производит матрицу входной чувствительности против входного устранения.
Другая важная задача, выполняемая аналитическими нейронными сетями, состоит в том, чтобы иметь дело с временными задержками. Классический подход, чтобы обращаться с временным рядом нейронными сетями, должен добавить дополнительные исходные данные для предыдущих временных шагов [10]. К сожалению, эта техника увеличивает размерность нейронной сети значительно. Это увеличение размерности входных векторов оказывает большое влияние на количество необходимых точек данных для надлежащей образцовой идентификации. Проблема еще больше в случае моделирования GP. Поэтому было бы желательно включать информацию от предыдущих временных шагов, не увеличивая размерность входа к сети. Это может быть достигнуто, выполнив скручивание на входе, используя функцию соответствующей формы. В результате первого блока интегрированной методологии размер полного набора данных уменьшен до количества самых чувствительных исходных данных.
Цель следующего блока, на основе SVM, состоит в том, чтобы далее уменьшить размер набора данных только к тем точкам данных, которые представляют шину существенной информации о нелинейной модели. Обнаружение выбросов является первой задачей в этом процессе. Для обнаружения выбросов мы используем то, что точки данных, содержащие важную информацию, определены методом SVM как векторы поддержки. Когда вес точки данных отличный от нуля, это — вектор поддержки. Ценность фактора веса вектора поддержки указывает, до какой степени соответствующее ограничение нарушено. Отличные от нуля факторы веса, поражающие верхнюю и нижнюю границу, указывают, что их ограничения очень трудные удовлетворить оптимальное решение. Такие точки данных часто так необычны относительно остальной части образцов, что их можно было бы рассмотреть как выбросы. Инструмент обнаружения изолированной части, используя метод SVM, как правило, строит несколько моделей переменной сложности. Точки данных с высокой частотой значений веса на границах, как предполагается, являются выбросами.
Одно из главных преимуществ использования SVM как метод моделирования — то, что пользователь имеет прямой контроль над сложностью модели (i.c., количество векторов поддержки). Сложностью можно управлять неявно или явно. Неявный метод управляет количеством векторов поддержки, управляя приемлемым уровнем шума. Чтобы явно управлять количеством векторов поддержки, можно или управлять отношением векторов поддержки или процентом векторов неподдержки. В обоих случаях сжатый набор данных, который отражает соответствующий уровень сложности, извлечен для эффективного символического регресса.
Дополнительная опция в этом главном блоке состоит в том, чтобы поставить эмпирическую модель на основе SVM. Некоторое недавнее шоу результатов [8], что у моделей SVM на основе смешанных глобальных и местных ядер есть очень хорошие особенности экстраполяции. Если у эмпирической модели, произведенной GP, нет приемлемой работы вне диапазона данных тренировки, основанная на SVM логически выведенная модель — жизнеспособное решение онлайн.
Заключительный блок интегрированной методологии для гибридного интеллектуального развития систем использует подход GP, чтобы искать потенциальные аналитические отношения в сжатом наборе данных самых чувствительных исходных данных. Предыдущие шаги значительно уменьшают область поиска, и эффективность GP значительно улучшена. Конечный результат от символического регресса — список нескольких аналитических функций и подуравнений, которые удовлетворяют лучшее решение согласно определенной объективной функции. Аналитический выбор функции для заключительной эмпирической модели — еще больше искусства, чем хорошо образованная процедура. Очень часто самое скупое решение не приемлемо из–за определенных производственных требований. Предпочтительно поставить несколько гармонических функций с разными уровнями сложности и позволить заключительному пользователю принять решение. Возможности обобщения каждой эмпирической модели проверены для всех возможных наборов данных. Из особого значения работа вне учебного диапазона. Также возможно проектировать образцовый индикатор уверенности типа соглашения на основе сложенных символических предсказателей.
ПРИКЛАДНЫЕ ОБЛАСТИ
Потенциал для создания стоимости от эффективного промышленного анализа данных на основе гибридных интеллектуальных систем огромен. Некоторые ключевые прикладные области, исследованные недавно в Dow Chemical Company, следующие:
- Надежные мягкие датчики. Некоторые критические параметры в химических процессах не измерены онлайн (состав, молекулярное распределение, плотность, вязкость, и т.д.), и их значения берутся или образцами лаборатории или офлайновым анализом. Однако для регулирования технологического процесса и качественного наблюдения время отклика этих измерений с низкой частотой (несколько часов, даже дней) очень медленное. Когда критические параметры не доступны онлайн в ситуациях с аварийными сигналами из-за сложных первопричин, негативное воздействие могло быть значительным и в конечном счете могло привести к закрытию. Одним из подходов, чтобы решить эту проблему являются посредством развития и установки дорогих аппаратных средств онлайн-анализаторов. Другое решение при помощи надежных мягких датчиков, разработанных предложенной методологией [9].
- Автоматизированные операционные дисциплины. Работа с дисциплиной является ключевым фактором для конкурентоспособного производства. Его главная цель состоит в том, чтобы обеспечить последовательный процесс для обработки всех возможных ситуаций на заводе. Это — самое большое хранилище знаний для эксплуатации установки. Однако эта документация статична и отделена от данных в реальном времени процесса. Недостающее звено между динамическим характером операции по процессу и статической природой операционных документов дисциплины традиционно выполнено техническим составом. Однако это заставляет существующую операционную дисциплину обработать очень чувствительный к человеческим ошибкам, компетентности, невниманию или отсутствию времени. Один подход к решению проблем, связанных с операционной дисциплиной и созданием его адаптивного к изменяющейся операционной среде варианта, должен использовать гибридные интеллектуальные системы в реальном времени. Такой тип системы был успешно осуществлен на крупномасштабном химическом заводе в Dow Chemical Company [11], Это основано на знании объединяющихся экспертов с мягкими датчиками и нечеткой логикой. Гибридная система бежит параллельно с процессом; это обнаруживает и признает проблемные ситуации автоматически в режиме реального времени; это обеспечивает легкий в использовании интерфейс так, чтобы операторы могли с готовностью обращаться со сложными сигнальными ситуациями; это предлагает надлежащие корректирующие действия с помощью гиперкниги; и это облегчает эффективную коммуникацию shift–to–shift.
- Ускоренная фундаментальная разработка модели. Символический регресс для ускоренной фундаментальной разработки модели продемонстрирован в тематическом исследовании для отношений собственности структуры [12]. Произведенное символическое решение подобно фундаментальной модели и обеспечено в значительно меньшее количество времени. Дополнительные выгоды включают определяющие ключевые переменные, и преобразовывает, позволяя быстрое тестирование новой физической гипотезы и сокращение количества экспериментов для образцовой проверки. Оптимизируя возможности к получению быстрых и надежных произведенных GP функциональных решений в сочетании с фундаментальным процессом моделирования, реальный прорыв в скорости разработки нового продукта может быть достигнут.
- Эффективный Дизайн Экспериментов (DOE). У интеграции GP с DOE есть потенциал, чтобы улучшить эффективность эмпирической разработки модели, экономя время и ресурсы в ситуациях, где экспериментальные пробеги довольно дорогие или технически невыполнимые из–за чрезвычайных экспериментальных условий. GP был успешно применен к развитию переменных линеаризурующих ответ в статистически разработанных экспериментах для химического процесса в Dow Chemical Company [13].
- Эмпирические эмуляторы. Эмпирические эмуляторы подражают исполнению первых принципиальных моделей при помощи различного управляемого данными моделирования методов. Главная особенность эмпирических эмуляторов то, что данные тренировки для эмпирической разработки модели произведены дизайном экспериментов из первых принципиальных моделей, названных симуляторами. Это позволяет высокую степень свободы для разработки надежных управляемых данными моделей. Самая очевидная схема внедрения эмпирических эмуляторов как акселератор вычислительного времени для фундаментальных моделей (выгода в 103–105 раз быстрее). Другая возможная схема состоит в том, чтобы использовать эмпирический эмулятор в качестве оценщика работы фундаментальной модели. Из особого значения к оптимизации онлайн схема эмпирического эмулятора как интегратор различных типов фундаментальных моделей (динамическое равновесие, динамичное, жидкое, кинетическое, тепловое, и т.д.). Результаты тематического исследования внедрения эмулятора даны в [14].
ВЫВОДЫ
Новая интегрированная методология для промышленного анализа данных была определена и успешно реализована в различных приложениях в Dow Chemical Company. Предложенная гибридная методология основана на использующих различные вычислительные компоненты (сложные аналитические нейронные сети, генетическое программирование и векторные машины поддержки). Движущая сила потребности в интеграции — требование промышленности для эмпирических моделей с увеличенной надежностью и уменьшенное время разработки. Иллюстрированное применение показывает одно из главных преимуществ предложенной методологии — значительное сокращение данных тренировки, установленных нелинейным анализом чувствительности и векторными машинами поддержки. Заключительное решение онлайн, произведенное GP, основано на очень компактной и прочной сложенной эмпирической модели со способность к самооценке, которая требует минимальной переквалификации и стоимости обслуживания. Успех этого применения в сложной промышленной среде, а также подобных внедрений в области автоматизации операционной дисциплины, ускорение фундаментальной разработки модели, эмпирических эмуляторов, и эффективного DO, демонстрирует большой потенциал комплексного подхода для решения трудных промышленных проблем.
Список источников
- L. Medsker, Hybrid Intelligent Systems Boston, MA: Kluwer, 1995.
- R. Neelakantan and J. Guivcr, “Applying Neural Networks”, Hydrocarbon Processing, vol. 9, October 1998, pp. 114–119.
- R. Khosla and T, Dillon, Engineering Intelligent Hybrid Multi-Agent Systems Boston, MA: Kluwer, 1995.
- S. Mitra, S. Pat, and P. Mitra, “Data Mining in Soft Computing Franework: A Survey”, IEEE Trans. Neural Networks, vol. 13, pp. 3–14, 2002.
- J, Koza, Genetic Programming: On the Programming of Computers by Means of Natural Selection, Cambridge, MA: MIT Press, 1992.
- V. Vapnik, Statistical Learning Theory, New York, NY: Wiley, 1998.
- S. Shark!ey (Editor), Combining Artificial Neural Networks, London, UK: Springer, 1999.
- G, Smits and E. Jordaan, “Using Mixtures of Polynomial and RBF Kernels for Support Vector Regression”, In Proceedings ofWCCI’2002, Honolulu, HA: IEEE Press, 2002, pp. 2785–2790.
- A. Kordon and G. Smits, “Soft Sensor Development Using Genetic Programming”, In Proceedings of GECCO'2001, San Francisco, CA: Morgan Kaufmann, 2001, pp, 1346–1351.
- Medsker L, and L. Jain (Editors), Recurrent Neural Networks: Design and Applications, Boca Raton, FL:CRC Press, 2000.
- A. Kordon, A.Kalos , and G.Smits, “Real Time Hybrid Intelligent Systems for Automating Operating Discipline in Manufacturing”, Artificial Intelligence in Manufacturing Workshop Proceedings of the 17th International Joint Conference on Artificial Intelligence IJCA1 — 2001, Seattle, WA, August 2001.
- A. Kordon , H. Pham, C. Bosnyak, M. Kotanchek, and G. Smits, “Symbolic Regression in Fundamental Model Building”, accepted for GECCO’2002.
- F. Castillo, K. Marshall, J. Greens, and A. Kordon, “Symbolic Regression in Design of Experiments: A Case Study with Linearizing Transformations”, accepted for GECCO’2002.
- P. K. Mercure,, G.F. Smits, and A. K. Kordon, “Empirical Emulators for First Principle Mode IT’, Fall 2001 AIChE meeting, Reno, NV, 2001.
- R. Neelakantan and J. Guivcr, “Applying Neural Networks”, Hydrocarbon Processing, vol. 9, October 1998, pp. 114–119.