
Abstract of the final work
Contents
- Introduction
- 1. Relevance of the topic
- 2. The purpose and objectives of the study, the planned results
- 3. Review of research and development
- 3.1 Overview of international sources
- 3.2 Overview of national sources
- 3.3 Overview of local sources
- 4. The structure and functioning of the convolutional neural network
- 5. Functions and parameters of the convolutional layer
- 6. Functions and parameters of the subsample layer
- 7. The structure of the last layer of the convolutional neural network
- Conclusion
- List of sources
Introduction
The task of identifying a person’s face in a natural or artificial setting and subsequent identification has always been among the top priorities for researchers working in the field of machine vision and artificial intelligence. Nevertheless, a lot of research conducted in leading scientific centers around the world for several decades did not lead to the creation of really working computer vision systems capable of detecting and recognizing a person in any conditions. Despite the proximity of the tasks and methods used in the development of alternative systems of biometric identification of a person (fingerprint identification or image of the iris), identification systems based on the image of a person are significantly inferior to the above systems.
1. Relevance of the topic
Pattern recognition is currently found in many applications. The most urgent and difficult is the problem of recognizing a person's face. The need to solve it arises in the design of control systems for people, security systems and many others.
Despite the relevance of computer vision, there is no qualitative solution to the recognition problem. The main difficulties of computer recognition of faces that need to be overcome are to recognize a person by the image of a person, regardless of the change in angle and lighting conditions when shooting, as well as various changes related to age, hairdo, etc.
Recently, great prospects in solving this problem have been associated with the use of deep neural networks. This class includes a multilayer convolutional neural network. In contrast to the well-known classical neural network architectures, this type is built and operates on the principles of the human visual system. Recently, well-known companies have proposed powerful libraries in which models of deep neural networks have been implemented, which allow solving complex recognition problems. However, the use of third-party libraries may have an insufficiently optimized solution or compromise information security with respect to recognizable images.
On this basis, the development of a personal face recognition system based on a convolutional neural network is considered. In this case, the problem arises of building such a program model of a neural network that would allow one to investigate the features of its work in real conditions. The architecture of the convolutional neural network as an object of study is characterized by the presence of a large set of tunable parameters and the complexity of operation.
Convolutional Neural Network or convolutional neural network (SNS) has shown the best results in the field of facial recognition. It is the development of the ideas of such neural network architectures as multilayer networks such as cognitron and neocognitron. The advantages are due to the peculiar architecture of the SNS, which allows to highlight in detail the features of the two-dimensional image topology in contrast to the multilayer perceptron.
The advantages of the SNA can also be attributed to the provision of partial resistance to scale changes, shifts, turns, angle changes and other distortions. Convolutional neural networks combine three architectural ideas:
- - local receptor fields that provide local two-dimensional connectivity of neurons;
- - common synaptic coefficients for detecting certain traits anywhere in the image and reducing the total number of weights;
- - hierarchical organization with spatial subsamples.
At the moment, the convolutional neural network and its modifications are considered the best in terms of the accuracy and speed of recognition of objects in the image.
2. The purpose and objectives of the study, the planned results
The goal of the work is to develop our own face recognition system based on a convolutional neural network.
To accomplish a given goal, you need to solve the following tasks:
- determine the number of layers of the SNS;
- determine the size of the full mesh SNS;
- определить размер фильтров СНС;
- determine the size of the filters SNA;
- prepare a set of input data;
- build a software model SNS.
Thus, as a result of the work, it is planned to obtain a software model of a convolutional neural network, which serves to recognize the faces of people from a video stream in real time.
3. Review of research and development
Today there are a large number of pattern recognition systems, but many of them are far from ideal solutions. Were found several such systems.
3.1 Overview of international sources
During the search, a solution was found from the company Intelligent Security Systems (ISS). Headquartered in Woodbridge, New Jersey, Intelligent Security Systems is the leading developer of security surveillance and control systems for network-based digital video and audio recording, image processing and digital image processing. MKS systems can be integrated with access control systems, fire and rescue safety and can be compatible with almost any third-party security equipment. [10].
Also found the open source library OpenCV. OpenCV (Open Source Computer Vision Library) is released under the BSD license and, therefore, is free for both academic and commercial use. It has C ++, Python and Java interfaces and supports Windows, Linux, Mac OS, iOS and Android. OpenCV was designed for computational efficiency and with great attention to real-time applications. Written in optimized C / C ++, the library can use multi-core processing. Enabled using OpenCL, it can take advantage of the hardware accelerated heterogeneous core computing platform. [11].
3.2 Overview of national sources
During the search, solutions from AxxonSoft were found. AxxonSoft - the leader of the Ukrainian market in the development of intelligent integrated security systems and video surveillance. They view the professional security system as an open information platform, built on the principle of the operating system, with a set of applications for solving a wide variety of tasks. Consider a security system as an infrastructure that integrates all equipment into a single organism and ensures its smooth operation using the latest intelligent information processing algorithms. [12].
3.3 Overview of local sources
During the analysis of the work of students of the Donetsk National Technical University, many works were found related to pattern recognition:
- Umiarov N. H.
Neural network facial recognition system in the picture from the video stream
[3]; - Isaenko А. P.
Using neural networks to solve pattern recognition problems
[4]; - Stadnik А. S.
Identify similar footage using pattern recognition techniques.
[5]; - Lichkanenko I. S.
Исследование методов и поиск эффективного алгоритма для задачи распознавания номерных знаков транспортных средств
[6]; - Sova А. А.
Recognizing human faces using a neocognitron neural network
[7]; - Fedorov А. V.
Investigation of contour segmentation methods for building an optical character recognition system
[8]; - Sheremet N. N.
Research and development of an adaptive method of active contours for the selection of objects in the video stream
[9].
4. The structure and functioning of the convolutional neural network
A convolutional neural network consists of layers of several types, such as convolutional, subsampling, and perceptron layers. In the general architecture of a multilayered neural network, the convolutional layers and the subsample layers alternate among themselves to form an input feature vector for the output layer — the multilayer perceptron (see Fig. 1). The convolution network got its name from the operation with the name “convolution”.
The main reason for the effectiveness of the SNA is the concept of common weights. They have fewer customizable options than a neocognitron. There are SNA options similar to neocognitron. In such networks, there is a partial rejection of the associated weights, but the learning algorithm remains the same and is based on the back propagation of the error. SNS can quickly work on a sequential machine and quickly learn by effectively paralleling the convolution process on each map, as well as reverse convolution when an error is propagated over the network.

Figure 1 - The structure of the convolutional neural network
In recent years, the activation function called rectifier is very often used in the SNS (see Fig. 2). Neurons with this activation function are called ReLU (rectified linear unit). The ReLU has the following formula f (x) = max (0, x) and implements a simple threshold transition at zero.
Positive aspects of such a function:
- Calculating sigmoids and hyperbolic tangent requires demanding operations, such as exponentiation, while ReLU can be implemented using a simple threshold transformation of the activation matrix at zero. In addition, the ReLU function is not saturated;
- The use of ReLU significantly increases the rate of convergence of a stochastic gradient descent compared to a sigmoid and hyperbolic tangent. It is believed that this is due to the linear nature and the lack of saturation of this function.
The negative side of this function is that the ReLU is not always sufficiently reliable with the hardware implementation and can fail during the learning process. For example, a large gradient passing through a ReLU can lead to such an update of the balance that the neuron is never activated again. If this happens, then, from now on, the gradient passing through this neuron will always be zero. Accordingly, this neuron will be irreversibly disabled. For example, if the learning rate is too high, it may turn out that up to 40% of the neurons will become “dead” (that is, never activated). This problem is solved by choosing the appropriate learning speed.
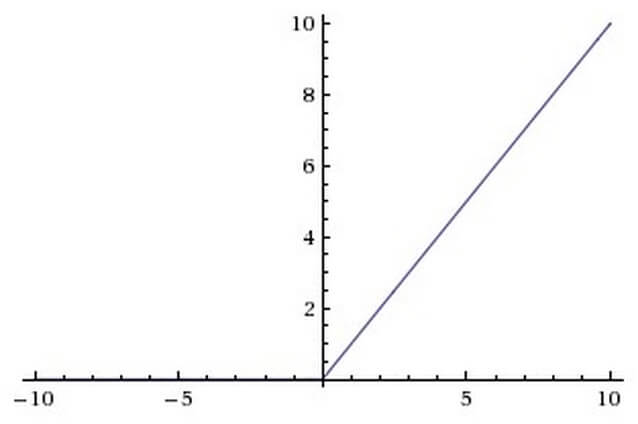
Figure 2 - ReLU activation function
5. Functions and parameters of the convolutional layer
The convolution layer is the main SNS layer, which performs most of the basic calculations. It is a set of matrices (maps), each matrix has a synaptic nucleus (filter).
The number of such matrices is determined by the requirements of the task; if you take a large number of cards, the recognition quality will increase, but the computational complexity will increase. Based on the analysis of scientific articles, it is proposed to take the ratio of one to two, that is, each matrix of the previous layer is associated with two matrices of the convolutional layer.
The sizes of all maps of the convolutional layer are the same and are calculated by the formula:
w = mW – kW + 1,
h = mH – kH + 1,
where w is the new width of the convolutional map; h is the new height of the convolutional map; mW is the width of the previous map; mH - height of the previous map; kW is the width of the core; kH is the height of the core.
The nucleus is a system of shared weights or synapses - this is one of the main features of the convolutional neural network. A normal neural network has a lot of connections between neurons, which slows down the detection process very much. In the convolutional network, on the contrary, the total weights make it possible to reduce the number of connections, as well as to find the same feature throughout the image area.
The core is a matrix of weights, which slides over the entire area of the previous map and finds certain attributes of objects in the image. For example, if the network was trained on many people, then one of the nuclei could give the greatest signal in the area of the eye, mouth, eyebrow or nose in the learning process, another core could detect other signs. Kernel size typically ranges from 3x3 to 7x7 pixels. If the size of the nucleus is small, it will not be able to isolate any signs, if too large, the number of connections between neurons increases.
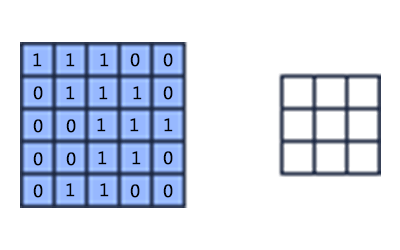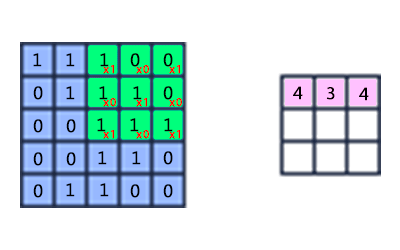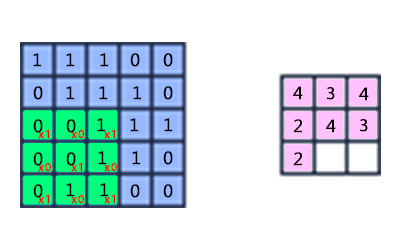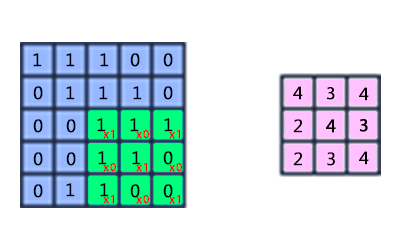
The principle of operation of the convolutional layer
6. Functions and parameters of the subsample layer
The sub-sample layer, like the convolution layer, has matrices and their number coincides with the previous layer. The task of the layer is to reduce the dimension of the maps of the previous layer. If some signs have already been identified using the convolution operation, then such a detailed image is no longer needed for further processing, and it is compacted (according to a certain principle) to a less detailed one (see Fig. 3).
In the process of scanning by the core of the subsample layer of the matrix of the previous layer, the scanning core does not intersect, unlike the convolutional layer. Usually, each card has a core of 2x2, which allows reducing the previous matrices of the convolutional layer by 2 times. The entire attribute map is divided into 2x2 cells, from which the maximum values are selected.
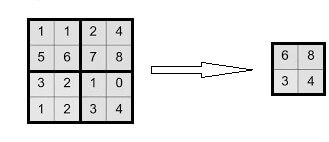
Figure 3 - The subsample process
7. The structure of the last layer of the convolutional neural network
At the output of the SNS, a layer of the usual multilayer perceptron is installed (see Fig. 4). It serves to determine the class to which the recognizable face image belongs. The work of the layer is organized by referring to the output of the previous layer and determining the properties that are most characteristic of a particular class.

Figure 4 - Structure of the full mesh layer
The neural network of this layer is fully connected, i.e. the neurons of each map of the previous subsample layer are associated with one neuron of the hidden layer. Thus, the number of neurons in the hidden layer is equal to the number of matrices of the subsampling layer, but the links may not necessarily be complete. For example, only a part of the neurons of any of the matrices of the subsample layer may be associated with the first neuron of the hidden layer, and the rest with the second, or all the neurons of the first card are connected with the neurons of the first and second hidden layer. The calculation of the values of the neuron is described by the formula:
xlj = f(∑xl-1i * wl-1i,j + bl-1j),
where xlj - feature map j (exit layer l); f() – activation function; bl – shear rate l; wl-1i,j – weight matrix of the first layer
Conclusion
A parametric and functional analysis of the convolutional neural network architecture is carried out. It has been established that it has a number of important advantages: accelerated network training and reduction of the required amount of training data due to the reduced number of trained neurons and due to the large number of abstract layers. Layers provide partial resistance to scale changes, offsets, turns, angle changes and other distortions. The SNA architecture allows for parallelization of computations, and, therefore, it is possible to implement algorithms for working and training the network on graphics processors. But at the same time, the SNS has drawbacks: too many variable network parameters.
Remarks
At the time of writing this essay, the master's work is not yet completed. Estimated completion date: May 2019. Full text of the work, as well as materials on the topic can be obtained from the author or his manager after the specified date.
List of sources
- Convolutional neural network, part 1: structure, topology, activation functions and training set. [Electronic resource]. - Access mode: https://habr.com/post/348000/
- What is a convolutional neural network. [Electronic resource]. - Access mode: https://habr.com/post/309508/
- Umiarov N. H. Нейросетевая система распознавания лица на снимке из видеопотока – Режим доступа: http://masters.donntu.ru/2012/fknt/umiarov/diss/index.htm
- Isaenko А. P. Using neural networks for solving pattern recognition problems - Access Mode: http://masters.donntu.ru/2006/fvti/isaenko/library/index.htm
- Stadnik А. S. Выявления схожего видеоматериала, используя методы распознавания образов – Режим доступа: http://masters.donntu.ru/2011/fknt/stadnik/diss/index.htm
- Lichkanenko I. S. Investigation of methods and the search for an effective algorithm for the vehicle license plate recognition problem - Access Mode: http://masters.donntu.ru/2013/fknt/lichkanenko/diss/index.htm
- Sova А. А. Recognition of human faces using a neocognitron-type neural network - Access Mode: http://masters.donntu.ru/2011/fknt/sova/links/index.htm
- Fedorov А. V. Study of contour segmentation methods for building an optical character recognition system - Access Mode: http://masters.donntu.ru/2010/fknt/fedorov/diss/index.htm
- Sheremet N. N. Research and development of an adaptive method of active contours for the selection of objects in the video stream - Access Mode: http://masters.donntu.ru/2015/fknt/sheremet/diss/index.htm
- Image Recognition System from IIS. [Electronic resource]. - Access mode: https://issivs.com/about-us//
- OpenCV library with many possibilities for computer vision. [Electronic resource]. - Access mode: https://opencv.org/
- Image recognition system from AxxonSoft. [Electronic resource]. - Access mode: https://www.axxonsoft.com/ua/