
Abstract
When writing this essay master's work is not yet completed. Final сompletion: June 2019. The full text of the work and materials on the topic can be obtained from the author or his manager after the specified date.
Content
- Introduction
- 1. Theme urgency
- 2. Goal and tasks of the research
- 3. Fundamentals of the genre of the document
- 3.1 Stemming as the first stage of text processing
- 3.2 Representation of a document in a vector-spatial model
- 3.3 Description of the prototype of the software system for determining whether a document belongs to a particular genre
- Conclusion
- References
Introduction
The main problem of text analysis is the large number of words in the document and its heterogeneity. Automated text analysis in its original form is a time consuming and lengthy process, considering that not all words carry meaningful information for the user. In addition, due to the flexibility of natural languages, formally different words (synonyms, etc.) actually mean the same concepts, a large number of word forms of the same word complicate the search and systematization of information. Consequently, the removal of non-informative words, as well as the reduction of words to normal form, significantly reduce the time for analyzing texts. The elimination of the problems described is a preliminary stage of analysis and search in documents, determining their similarity and genre.
1. Theme urgency
The search for semantic similarity between texts is a serious problem for automatic text processing. The need to find the distance between documents arises in various tasks, such as detecting plagiarism, determining authorship of a document, searching for information, machine translation, forming tests and tasks, automatic construction of essays, etc. The task of rubricating text is close to classification: subject headings or genre. Consequently, the tasks of efficient automated text processing remain relevant, a steady increase in the amount of information requires constant improvement of algorithms and approaches [1].
2. Goal and tasks of the research
The goal of the work is to design and implement a system for determining the genre of a literary work based on the Text Mining technology.
Main tasks of the research:
- consider methods and algorithms for basic text processing;
- explore approaches to the presentation of the document;
- create a software document processing apparatus based on the space-vector model;
- develop an algorithm for determining whether a literary work belongs to a particular genre.
Research object: literary works classified by genre.
Research subject: algorithms and methods for determining the proximity of documents.
3. Fundamentals of the genre of the document
3.1 Stemming as the first stage of text processing
The main task of lexical analysis is to recognize lexical units of text. The basic algorithm is a lexical decomposition, which provides for the breakdown of text into tokens. In this context, tokens can be words, word forms, morphemes, phrases and punctuation marks, dates, phone numbers, etc. [2].
Lexical segmentation is fundamental to automated text analysis, as it is the basis of most other algorithms. The next step in processing the original work is stemming, to the input of which a ready list of tokens is supplied.
Stemming is the process of finding the stem of a word for a given source word. The basis of the word does not necessarily coincide with the morphological root of the word. Stemming is used in search engines to expand a search query, speed up query processing time, is part of the text normalization process [3].
Stemmers are usually classified as algorithmic and vocabulary. Vocabulary stemmers operate on the basis of vocabulary word bases. In the process of morphological analysis, such a stemmer performs a comparison of the word bases in the input text and in the corresponding dictionary, and the analysis starts from the beginning of the word. Using the vocabulary stemmer, the search accuracy is improved, however, the time of the algorithm and the amount of memory occupied by the basic dictionaries increases.
Algorithmic stemmers work on the basis of data files that contain lists of affixes and flexions. In the course of the analysis, the program compares suffixes and word endings of the input text with a list from a file, the analysis is performed character-by-character, starting from the end of the word. Such stemmers provide greater completeness of the search, although they allow allowing for more errors, which are manifested in insufficient or excessive stemming. Excessive stemming is manifested if, on a single basis, words with different semantics are identified; with insufficient stemming on a single basis, words with the same semantics are not identified.
In Russian, word formation based on affixes, combining several grammatical meanings, prevails. For example, добрый
- ending ый
indicates simultaneously the singular, masculine and nominative, therefore this language promotes the use of stemming algorithms. However, due to the complex morphological variability of words, additional means should be used to minimize errors [3], for example, lemmatization.
3.2 Representation of a document in a vector-spatial model
Suppose that each document can be characterized by a specific set of words and the frequency of their appearance. Then, provided that if the document uses a specific set of words with certain frequencies, then this document meets the requirements of this query. Based on this information, a “word-document” table is constructed, where the rows correspond to the terms, and the columns represent the examined documents. Each cell can store a Boolean value that indicates the presence of at least one occurrence of a term in a document, the frequency of a word in a document, or the weight of a term [4, с. 143]. Now, in order to compare the document d and the query q, you need to determine the measure of the similarity of the two columns of the table.
Within the framework of this model, each term t i in the document dj corresponds to a certain non-negative weight wj. Each query q, which is a set of terms that are not interconnected by any logical operators, also corresponds to a weight vector w ij .
In this case, the weight of individual terms can be calculated in different ways. In 1988, Solton proposed this option to calculate the weight of a term ti from the query in the document presented in the following formula [5, с.41]:
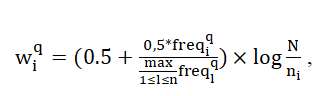
where freqiq – the frequency of the term ti from the query in the text of this document.
Using this indicator allows you to enhance the difference of the term, if it is often found in a small number of documents and reduce the meaning of the term and the relevance of the document, if the term is found in many documents or is used only a few times.
The vector-spatial model of data presentation provides the following possibilities for systems based on it:
- processing requests without limiting their length;
- ease of implementing the search mode for similar documents (each document can be considered as a request);
- saving search results with the ability to perform a refinement search;
- the ability to install additional weights to improve more focused search and analysis of document similarity[6].
However, the vector-spatial model does not provide for the use of logical operations in queries, which in some way limits its applicability.
3.3 Description of the prototype of the software system for determining whether a document belongs to a particular genre
The basic algorithm for determining the genre of text, based on the approaches presented above, is currently implemented. Consider the stages of the program model of the document analyzer (fig. 1).

Figure 1 – State diagram of the software model
(animation: 11 frames, 7 cycles of repetition, 76 kilobytes)
To develop a prototype system and test its work, the purpose of which is to determine whether a document belongs to a certain literary genre, 2 genres were chosen - a detective story and a love novel, 5 books of each genre were selected. By pressing a button, 6 files are loaded into the system - the first file is a request, another 5 are pre-selected files of the same genre.
The software module responsible for the lexical analysis is launched first and prepares the data for the subsequent stages of the analysis. The main task of the lexical analysis is to recognize the lexical units of the text, remove the stop words and bring them to a single representation with the help of stemming. Stop words are words that are auxiliary and carry little information about the content of the document. Sets of stop words can be different and depend on the goals and objectives of the study. In this case, a list of stop words is used, consisting of particles, prepositions, and some pronouns. According to the results of own research, the removal of stop words cuts off an average of 30% of words (fig. 2), which speeds up further data processing and improves the accuracy of the results.
To determine the genre affiliation of the text in the implemented prototype of the software system, an analyzer of the proximity of the loaded document to the documents whose genre affiliation has already been defined was developed. For this purpose, the vector – spatial model was used as the most suitable for solving the problem. To determine the proximity of the documents were used 4 of the most popular indicators:
- scalar product of vectors;
- Euclidean distance;
- Manhattan distance;
- cosine similarity measure method.
Analyzing these methods, one should note that the similarity values ??for the Euclidean and Manhattan methods are actually the distances between vectors. Thus, the smaller the distance, the more the document is similar to the request. Methods using a scalar product and cosine indicators, as a result, they return exactly the similarity, that is, the best document is the one that has the greatest indicator of similarity. A significant disadvantage of the manhattan distance and euclidean distance methods is the complete search of vectors and the calculation of distances even for zero points, which brings with it an increase in performance requirements.
One reason for the popularity of cosine similarity is that it is effective as an estimate measure, especially for sparse vectors, since only non-zero measurements need to be taken into account. Based on the done calculations and analysis of the described methods based on the vector model, the best method for determining the proximity of the documents was determined by the method of cosine similarity (fig. 2).
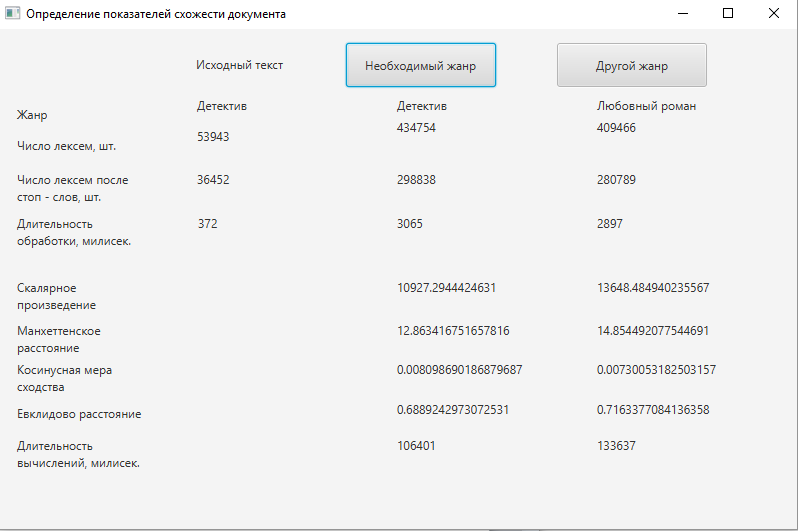
Figure 2 – The results of the program
Since the indices of the distance between the request and the documents are numerically smaller in the sample of the detective genre, and the values of the scalar product and the cosine measure of similarity, on the contrary, are larger, it can be concluded that the document is a detective genre. However, the striking difference cannot be noticed - the cosine measure of similarity chosen for further research generally belongs to the interval [0, 1], that is, the closer the value is to one, the more likely the genre is defined correctly.
Therefore, the indicators at 0.0081 and 0.0073 are not sufficiently weighty to classify the selected text with confidence. In order to consider a document belonging to a particular genre, the cosine measure should be as close as possible to one, therefore, the system should be refined [7].
At this stage of development, the following disadvantages of the software system were identified:
- high duration of preprocessing;
- low rates of similarity of documents, the relevance of which is determined on the basis of expert assessments;
- manhattan and Euclidean distance methods require more time and computational complexity;
- there is no possibility of additional training, that is, additions to the training sample with documents that, as a result of program analysis, were identified as belonging to the selected genre;
- user need to load the training set every time the program starts.
In this regard, the following areas of work should be investigated:
- modify the initial processing of documents by removing personal names, names of settlements, and other minor constructions;
- use parallelization in the processing of documents;
- use the method of cosine similarity to determine the similarity of documents;
- consider a document belonging to the selected genre such, the cosine measure of similarity of which will be more than 0.7;
- develop a methodology for storing analysis results for subsequent training of the model;
- increase the number of the training sample to at least 100 books of the selected genre;
- with the help of experts, perform an analysis of the weights of frequently used terms in documents of a particular genre, increase their influence on the final calculation of the similarity of documents and, subsequently, on the definition of a genre.
Conclusion
The abstract describes the characteristics of stemming as a method of primary text processing. Were also briefly described the developments and research in the field of analyzing the similarity of documents, conducted to date, outlined the shortcomings of the prototype software system.
Further work will be aimed at analyzing the weights of frequently used terms in documents of a particular genre, introducing the results into a thesis, as well as developing an application that implements the analyzer of a document belonging to a specific genre that meets the requirements put forward.
References
- Сторожук, Н. О. Анализ методов определения текстовой близости документов / Н. О. Сторожук, И. А. Коломойцева // Материалы студенческой секции IX Международной научно-технической конференции «Информатика, управляющие системы, математическое и компьютерное моделирование» (ИУСМКМ-2018). – Донецк: ДонНТУ, 2018. – С. 43-47.
- Стемминг [Электронный ресурс]. – Режим доступа: https://intellect.ml/stemming-stemmer-portera-6235. – Загл. с экрана.
- Алгоритмы интеллектуальной обработки больших объемов данных [Электронный ресурс]. – Режим доступа: http://www.intuit.ru/studies/courses/3498/740/info . – Загл. с экрана.
- Маннинг, К.Д. Введение в информационный поиск / К. Д. Маннинг, П. Рагхаван, Х. Шютце. – Москва : М.: ООО «И.Д. Вильямс», 2011. – 528 с.
- Salton G., Fox E., Wu H. Extended Boolean information retrieval. Communications of the ACM. 2001./ G.Salton, E,Fox, H.Wu.- Vol. 26. № 4. P. 35–43.
- Компьютерный анализ текста [Электронный ресурс]. – Режим доступа: http://lab314.brsu.by/kmp-lite/CL/CL-Lect/KAT.htm. – Загл. с экрана.
- Сторожук, Н. О., Коломойцева И.А. Реализация прототипа анализатора жанровой принадлежности произведений на основании векторно – пространственной модели представления документов / Н. О. Сторожук, И. А. Коломойцева // Материалы международной научно-практическаой конференции «Программная инженерия: методы и технологии разработки информационновычислительных систем» (ПИИВС-2018) – Донецк: ДонНТУ, 2018. – С. 132-137.