
Реферат за темою випускної роботи
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: червень 2019 року. Повний текст роботи та матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі дослідження та заплановані результати
- 3. Огляд досліджень та розробок
- 3.1 Огляд міжнародних джерел
- 3.2 Огляд національних джерел
- 3.3 Огляд локальних джерел
- 4. Основні етапи визначення жанру документа
- 4.1 Стемінг як перший етап обробки тексту документа
- 4.2 Представлення документа у векторно-просторовій моделі
- 4.3 Опис прототипу програмної системи визначення приналежності документа до певного жанру
- Висновки
- Перелік посилань
Вступ
Основною проблемою аналізу текстів є велика кількість слів у документі і його неоднорідність. Автоматизований аналіз тексту в початковому вигляді - трудомісткий і тривалий процес, враховуючи те, що не всі слова несуть значущу для користувача інформацію. Крім того, в силу гнучкості природних мов формально різні слова (синоніми і т.п.) насправді означають однакові поняття, велику кількість словоформ одного і того ж слова ускладнюють пошук і систематизацію інформації. Отже, видалення неінформативних слів, а також приведення слів до нормальної формі значно скорочують час аналізу текстів. Усунення описаних проблем є попереднім етапом аналізу і пошуку в документах, визначення їх схожості і жанру.
1. Актуальність теми
Пошук семантичного подібності між текстами є серйозною проблемою для автоматичної обробки тексту. Необхідність пошуку відстані між документами виникає в різних сферах наукової діяльності, таких як виявлення плагіату, визначення авторства документа, пошук інформації, машинний переклад, формування тестів і завдань, автоматична побудова рефератів тощо. Близька до класифікації завдання рубрикацiї тексту - його віднесення до однієї з заздалегідь відомих тематичних рубрик або жанру. Отже, завдання ефективної автоматизованої обробки текстів залишаються актуальними, стабільне збільшення обсягу інформації вимагає постійного вдосконалення алгоритмів і підходів [1].
2. Мета і задачі дослідження та заплановані результати
Мета роботи - проектування та реалізація системи визначення жанру літературного твору на основі технології Text Mining.
Задачи дослідження:
- розглянути методи і алгоритми базової обробки тексту;
- розглянути підходи до представлення документа;
- сформувати програмний апарат обробки документів на основі просторово-векторної моделі;
- розробити алгоритм визначення приналежності літературного твору до певного жанру.
Об'єкт дослідження: літературні твори, що класифікуються за жанрову приналежність.
Предмет дослідження: алгоритми і методи визначення близькості документів.
3. Огляд досліджень та розробок
Досліджувана тема популярна не тільки в міжнародних, але і в національних наукових спільнотах.
3.1 Огляд міжнародних джерел
Серед міжнародних джерел не можна виділити роботи, пов'язані безпосередньо з визначенням жанру літературних творів російською мовою, проте в процесі пошуку матеріалів були виділені роботи, пов'язані з обробкою тексту і загальними підходами визначення подібності або релевантності документа.
Так в статті Г. Солтона і К. Баклі Term-weighting approaches in automatic text retrieval
[ 2 ] узагальнюються дані, отримані при автоматичному зважуванні термінів, і представлені базові моделі з одним індексом, за допомогою яких можна порівнювати інші більш складні процедури аналізу контенту. Також обгрунтований вибір ефективності використання даної вагової системи, її порівняння з іншими, більш складними, і аналіз експериментальних даних, накопичених в процесі попередніх досліджень.
У книзі К. Маннинга, П. Рагхаван, Х. Шютце Введение в информационный поиск
[ 3 ] розглядається веб-пошук, включаючи суміжні завдання класифікації і кластеризації текстів. Крім веб-пошуку, в підручнику розглянуті основні поняття і історія класичного інформаційного пошуку та індексування документів, методи оцінки пошукових систем, а також введення в методи машинного навчання на базі колекцій текстів.
3.2 Огляд національних джерел
Пошук семантичного подібності між текстами є серйозною проблемою для автоматичної обробки тексту. Необхідність пошуку відстані між документами виникає в різних завданнях, таких як виявлення плагіату, визначення авторства документа, пошук інформації, машинний переклад, формування тестів і завдань, автоматична побудова рефератів тощо. Пошуку семантичної схожості текстів було приділено увагу в рамках багатьох міжнародних і російських конференцій такими авторами як Красніков І.А., Керімова С.У., Єрмоленко Т.В., Нікулічев М.М. [4 - 5] .
У статті Яцко В.А. Алгоритмы и программы автоматической обработки текста
[ 6 ] дається огляд найбільш поширених алгоритмів і програм автоматичної обробки тексту. Описуються особливості алгоритмів і програм, що застосовуються на морфологічному, лексичному, синтаксичному та дискурсивної рівнях мовної системи.
Шарнин, М. М., Іщенко, Н. С., Пахмутова Н.Ю., Сюракшіна Ю.В. в своїй статті Использование методов тематического моделирования многоязычных коллекций для прогноза тревожных событий
[7] демонструють результати практичного застосування методів тематичного моделювання в багатомовними середовищах для моніторингу екстремістської активності в Інтернеті та прогнозу тривожних подій. При роботі з двома корпусами текстів, що містять екстремістську ідеологію радикальних мусульман і українських націоналістів, підбираються оптимальні параметри для методу неявних посилань, розраховується міра подібності корпусів тексту, визначається загальна і специфічна характерна термінології двох корпусів текстів. Хоча напрямок магістерської роботи не припускав мультимовності розроблюваної системи або прогнозу, ці відомості дозволяє зробити висновок про широкі можливості і сферах застосування автоматичної обробки тексту.
Автори Большакова Є.І., Клишінскій Е.С., Ланде Д.В., Носков А.А., Пєскова О.В., Ягунова Є.В. у своїй роботіАвтоматическая обработка текстов на естественном языке и компьютерная лингвистика
[8] розглядають базові питання комп'ютерної лінгвістики: від теорії лінгвістичного і математичного моделювання до варіантів технологічних рішень. У статті наведені відомості, необхідні для створення окремих підсистем, що відповідають за аналіз текстів на природній мові, розглянуті питання побудови систем класифікації та кластеризації текстових даних, основи фрактальної теорії текстової інформації.
Дана наукова праця лежить в основі більш предметних досліджень Ягунова Є.В. в роботах Экспериментально- вычислительные исследования художественной прозы Н.В. Гоголя
[9] та Ключевые слова в исследовании текстов Н.В. Гоголя
[10]. У статтях представлені етапи аналізу семантичної та інформаційної структур, де перша в найбільшою мірою співвідноситься зі стилем (характерному для письменника, циклу, твори), а друга - з вмістом твори і / або циклу. Автор демонструє можливості використання формальних ознак (видів розподілу в тексті) і викладає свою методику і підхід до класифікації типів ключових слів твори.
3.3 Огляд локальних джерел
В реферате Леонова А.Д. Методы автоматизированной коррекции специализированных естественно-языковых текстов
[11] розглянуті алгоритми морфологічного і синтаксичного аналіз: стемінг, метод n-грам та інші, виділені області їх застосування та сформульовані загальні висновки по темі.
Стулікова Н.В. в рефераті на тему магістерської роботи [12] розглядає підходи і методи автоматичного реферування, проводить аналіз існуючих систем реферування такі як Intelligent Text Miner, Золотой ключик і TextAnalyst.
4. Основні етапи визначення жанру документа
4.1 Стемінг як перший етап обробки тексту документа
Основне завдання лексичного аналізу - розпізнати лексичні одиниці тексту. Базовим алгоритмом є лексична декомпозиція, яка передбачає розбивку тексту на токени. В даному контексті токенами можуть бути це слова, словоформи, морфеми, словосполучення і розділові знаки, дати, номера телефонів тощо [13].
Лексична сегментація має фундаментальне значення для проведення автоматичного аналізу тексту, оскільки лежить в основі більшості інших алгоритмів. Наступним кроком обробки вихідного твори є стемінг, на вхід якого подається готовий список токенов.
Стемінг - це процес знаходження основи слова для заданого вихідного слова. Основа слова необов'язково збігається з морфологічним коренем слова. Стемінг застосовується в пошукових системах для розширення пошукового запиту, прискорення часу обробки запиту, є частиною процесу нормалізації текстаx [14].
Стеммер прийнято класифікувати на алгоритмічні та словникові. Словникові Стеммер функціонують на основі словників основ слів. У процесі морфологічного аналізу такої Стеммер виконує зіставлення основ слів у вхідному тексті і в відповідному словнику, а аналіз починається з початку слова. Використовуючи словниковий Стеммер, підвищується точність пошуку, проте збільшується час роботи алгоритму і обсяг пам'яті, займаної словниками основ.
Алгоритмічні Стеммер працюють на основі файлів даних, які містять списки афіксів і флексій. У процесі аналізу програма виконує порівняння суфіксів і закінчень слів вхідного тексту зі списком з файлу, аналіз відбувається посимвольний, починаючи з кінця слова. Такі Стеммер забезпечують більшу повноту пошуку, хоча і допускають допускаючи більше помилок, які проявляються в недостатньому або надмірному стеммірованіі. Надмірне стеммірованіе проявляється, якщо по одній основі ототожнюються слова з різною семантикою; при недостатньому стеммірованіі по одній основі не ототожнюються слова з однаковою семантикою.
У російській мові переважає словоформірованіе на основі афіксів, що поєднують відразу кілька граматичних значень. Наприклад, добрий - закінчення ый
вказує одночасно на однина, чоловічий рід і називний відмінок, тому дана мова сприяє використанню алгоритмів стемінг. Однак в силу складної морфологічної змінності слів для мінімізації помилок слід використовувати додаткові засоби [15], наприклад, лематизації. Нижче розглянуті найбільш популярні реалізації стеммерів, що грунтуються на різних принципах і допускають обробку неіснуючих слів для російської мови.
Основна ідея Стеммер Портера полягає в тому, що існує обмежена кількість словообразующих суфіксів, і стемінг слова відбувається без використання будь-яких баз основ: тільки безліч існуючих суфіксів і правила, задані вручну. Алгоритм складається з п'яти кроків, на кожному з яких відсікається словообразующій суфікс і решта перевіряється на відповідність правилам [16]. Наприклад, для російських слів основа повинна містити не менше однієї голосної. Якщо отримане слово задовольняє правилам, відбувається перехід на наступний крок, інакше - алгоритм вибирає інший суфікс для відсікання. На першому кроці відсікається максимальний формоутворювальний суфікс, на другому - буква и
, на третьому - словообразующій суфікс, на четвертому - суфікси чудових форм, ь
і одна з двох н
. Недоліком є те, що часто обрізається більше необхідного, що ускладнює отримання правильної основи слова. Наприклад кровать-крова
при цьому реально незмінна частина - кроват
, але Стеммер вибирає для видалення найбільш довгу морфему [17].
Алгоритм Stemka заснований на ймовірнісної моделі: слова з навчальної тексту розбираються аналізатором на пари останні дві букви основи
+ суфікс
. При цьому, якщо така пара вже є в моделі - її вага збільшується. Отриманий масив даних ранжируется спаданням ваги і малоймовірні моделі відсікаються. Результат - набір потенційних закінчень з умовами на попередні символи - інвертується для зручності сканування словоформ справа наліво
і представляється у вигляді таблиці переходів кінцевого автомата [18].
Алгоритм MyStem є власністю компанії Яндекс. На першому кроці за допомогою дерева суфіксів у вхідному слові визначаються можливі межі між основою і суфіксом, після чого для кожної потенційної основи починаючи з найдовшою бінарним пошуком по дереву основ перевіряється її наявність в словнику або знаходження найбільш близьких до неї основ мірою близькості є довжина загального хвоста
. Якщо слово словникове - алгоритм закінчує роботу, інакше - переходить до наступного розбиття [19].
4.2 Представлення документа у векторно-просторовій моделі
Припустимо, що кожен документ можна охарактеризувати певним набором слів і частотою їх появи. Тоді за умови, що якщо в документі конкретний набір слів вживається з певними частотами, то цей документ відповідає вимогам цього запиту. На підставі цієї інформації будується таблиця слово-документ
, де рядки відповідають термінам, а стовпці - досліджуваним документам. У кожному осередку може зберігатися логічне значення, яке показує наявність хоча б одного входження терміна в документ, частота слова в документі або вага терміна [20, с. 143]. Тепер, для того щоб порівняти документ d і запит q, потрібно визначити міру схожості двох стовпців таблиці.
В рамках цієї моделі кожному терму ti документу dj відповідає певна ненегативна вага wj. Кожному запиту q, який представляє собою безліч термів, не поєднаних між собою ніякими логічними операторами, також відповідає вектор вагових значень wi j.
При цьому вага окремих термів можна обчислювати різними способами. Один з можливих найпростіших підходів - використання нормалізованої частоти появи терма в документі за наступною формулою:
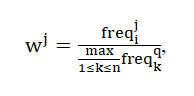
де freqij– кількість вживання терма в документі.
Такий показник ваги терма в документі позначають абревіатурою tfj (Від англійського term frequency - частота терміна). Однак цей підхід не враховує, наскільки часто розглядається терм використовується у всьому масиві документів, іншими словами - дискримінаційну силу терма. Тому в разі, коли доступна статистика використання термів у всьому документальному масиві, більш ефективно правило обчислення ваги з використанням такої формули:
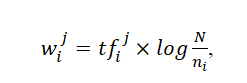
де ni – кількість документів, в яких використовується терм ti,
N - загальна кількість документів в масиві.
Слід зазначити, що підстава логарифма може бути будь-яким, для простоти найчастіше використовують 2 або 10. Наведена вище формула багаторазово уточнювалася з метою найбільш точного відповідності видаваних документів запитам користувачів. У 1988 році Солтона був запропонований такий варіант для обчислення ваги терма tiіз запиту в документі, представлений в наступній формулі [21, с.41]:
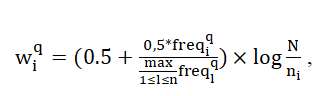
де freqiq – частота терма t i з запиту в тексті цього документа.
Використання такого показника дозволяє посилити відміну терміна, якщо він зустрічається часто в невеликій кількості документів і зменшити значення терміна і релевантність документа, якщо термін зустрічається у багатьох документах або використовується всього кілька разів.
Векторно-просторова модель представлення даних забезпечує системам, побудованим на її основі, такі можливості:
- обробку запитів без обмежень їх довжини;
- простоту реалізації режиму пошуку подібних документів (кожен документ може розглядатися як запит);
- збереження результатів пошуку з можливістю виконання уточнюючого пошуку;
- можливість установки додаткових вагових коефіцієнтів для удосконалення більш узконаправленного пошуку та аналізу подібності документів [22].
Разом з тим в векторно-просторової моделі не передбачено використання логічних операцій в запитах, що певним чином обмежує її застосовність.
4.3 Опис прототипу програмної системи визначення приналежності документа до певного жанру
На поточний момент реалізований базовий алгоритм визначення жанру тексту, заснований на наведених вище підходах. Розглянемо етапи роботи програмної моделі аналізатора документів (див. рис. 1).

Рисунок 1 – Діаграма станів програмної моделі
(анімація: 11 кадрів, 7 циклів повторення, 32 кілобайти))
Для розробки прототипу системи і тестування її роботи, мета якої полягає у визначенні приналежності документа до деякого літературного жанру, були обрані 2 жанру - детектив і любовний роман, підібрано по 5 книг кожного жанру. При натисканні на кнопку в систему завантажується 6 файлів - перший файл є запитом, ще 5 - попередньо відібрані файли одного жанру.
Програмний модуль, що відповідає за лексичний аналіз, запускається в першу чергу і готує дані для наступних етапів аналізу. Основне завдання лексичного аналізу - розпізнати лексичні одиниці тексту, видалити стоп-слова і привести їх до єдиної поданням за допомогою стемінг. Стоп-словами називаються слова, які є допоміжними і несуть мало інформації про зміст документа. Набори стоп-слів можуть бути різними і залежати від цілей і завдань дослідження. В даному випадку використовується список стоп-слів, що складається з частинок, прийменників і деяких займенників. За результатами власних досліджень, видалення стоп-слів відсікає в середньому 30% слів (див. рис. 2), що прискорює подальшу обробку даних і підвищує точність результатів.
Для визначення жанрової приналежності тексту в реалізовувати прототипі програмної системи був розроблений аналізатор близькості завантажується документа до документів, жанрова приналежність яких вже визначена. З цією метою була використана векторно-просторова модель, як найбільш підходяща для вирішення поставленого завдання. Для визначення близькості документів були використані 4 найбільш популярних показника:
- скалярний добуток векторів;
- евклідова відстань;
- манхеттенська відстань;
- метод косинусной міри схожості.
Аналізуючи ці методи, слід звернути увагу, що значення схожості по Евклідовому і Манхеттенського методам насправді є відстанями між векторами. Таким чином, чим відстань менше, тим більше документ схожий із запитом. Методи, які використовують скалярний твір і косинусні показники, в результаті повертають саме схожість, тобто найкращий документ той, який має найбільший показник подібності. Вагомим недоліком методів манхеттенського відстані і евклідової відстані є повний перебір векторів і обчислення відстаней навіть для нульових точок, що несе за собою збільшення вимог до продуктивності.
Одна з причин популярності косинусного подібності полягає в тому, що воно ефективно в якості оціночної заходи, особливо для розріджених векторів, так як необхідно враховувати тільки ненульові вимірювання. На підставі виконаних розрахунків і аналізу описаних методів, заснованих на векторної моделі, найкращим методом для визначення близькості документів було визначено метод косинусного подібності (див. рис. 2).
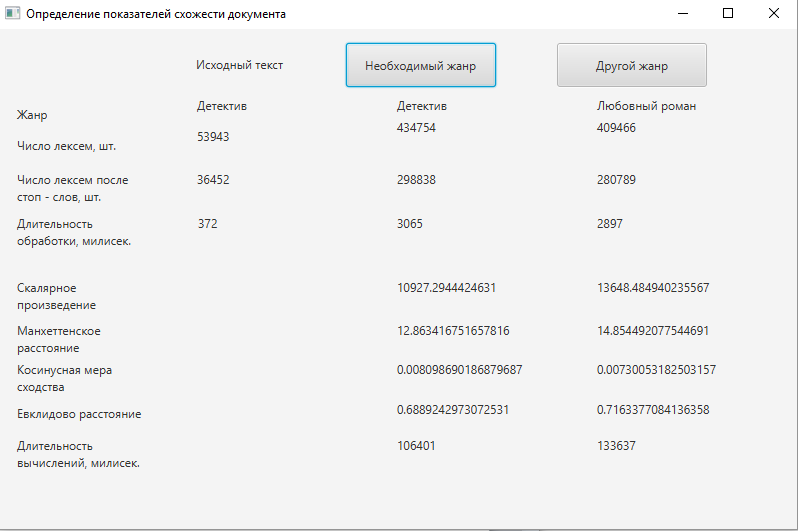
Рисунок 2 – Результати работи програми
Так як показники відстаней між запитом і документами чисельно менше у вибірки детективного жанру, а значення скалярного твори і косинусной міри схожості навпаки, більше, можна зробити висновок, що досліджуваний документ детективного жанру. Однак разючої різниці помітити не вдасться - обрана для подальшого дослідження косинусна міра подібності в загальному випадку належить проміжку [0, 1], тобто, чим ближче значення до одиниці, тим більш імовірно, що жанр визначений вірно.
Отже, показники в 0,0081 і 0,0073 є недостатньо вагомими, щоб з упевненістю класифікувати обраний текст. Для того, щоб вважати документ належить до певного жанру, слід максимально наблизити показник косинусной заходи до одиниці, отже, необхідно доопрацювати систему [23].
На даному етапі розробки були виявлені такі недоліки програмної системи:
- висока тривалість первинної обробки текстів;
- низькі показники схожості документів, релевантність яких визначена на основі експертних оцінок;
- методи манхеттенського і евклідової відстані вимагають більшої тимчасової і обчислювальної складності;
- відсутня можливість донавчання, тобто доповнення навчальної вибірки документами, які в результаті програмного аналізу були визначені як належать до вибраного жанру;
- потрібно виконувати завантаження навчальної вибірки щоразу на початку роботи програми.
У зв'язку з цим слід опрацювати наступні напрямки роботи:
- доопрацювати первинну обробку документів за допомогою видалення особистих імен, назв населених пунктів, інших малозначних конструкцій;
- використовувати розпаралелювання в процесі обробки документів;
- використовувати для визначення схожості документів метод косинусного подібності;
- вважати документом, що належить до вибраного жанру такий, косинусна міра подібності якого буде більш ніж 0.7;
- розробити методологію збереження результатів аналізу для подальшого навчання моделі;
- збільшити число навчальної вибірки мінімум до 100 книг обраного жанру;
- за допомогою експертів виконати аналіз ваг часто вживаних термів в документах певного жанру, підвищити ступінь їх впливу на кінцеве обчислення схожості документів і надалі - на визначення жанру.
Висновки
Аналіз джерел показав, що тема аналізу і обробки текстової інформації актуальна як в міжнародному, національному так і в локальному наукових спільнотах. Однак слід зазначити, що дослідження в автоматизації визначення жанру документа недостатньо популярні або є внутрішніми напрацюваннями пошукових та інших комерційних систем і не перебувають у відкритому доступі.
У рефераті описані особливості стемінг як методу первинної обробки тексту, розглянуті робочі Стеммер. Також були коротко описані напрацювання і дослідження в галузі аналізу схожості документів, проведені на поточний момент, викладені недоліки прототипу програмної системи.
Подальша робота буде спрямована на аналіз ваг часто вживаних термів в документах певного жанру, впровадження результатів в дипломну роботу, а також на розробку програми, що реалізує аналізатор приналежності документа до певного жанру, відповідного висунутим вище вимогам.
Перелік посилань
- Сторожук, Н. О. Анализ методов определения текстовой близости документов / Н. О. Сторожук, И. А. Коломойцева // Материалы студенческой секции IX Международной научно-технической конференции «Информатика, управляющие системы, математическое и компьютерное моделирование» (ИУСМКМ-2018). – Донецк: ДонНТУ, 2018. – С. 43-47.
- Salton G., Buckley C. Term-weighting approaches in automatic text retrieval. Information Processing & Management 1988./ Salton G., Buckley C. Vol. 24, No. 5, pp. 513-523 [Электронный ресурс]. Режим доступа: http://pmcnamee.net/744/papers/SaltonBuckley.pdf. – Загл. с экрана.
- Маннинг, К.Д., Рагхаван П., Шютце Х. Введение в информационный поиск / К. Д. Маннинг, П. Рагхаван, Х. Шютце. – Москва : М.: ООО «И.Д. Вильямс», 2011. – 528 с. [Электронный ресурс]. – Режим доступа: http://mirknig.su/knigi/web/163982-vvedenie-v-informacionnyy-poisk.html. – Загл. с экрана.
- Красников, И.А. Гибридный алгоритм классификации текстовых документов на основе анализа внутренней связности текста [Текст] / И. А. Красников, Н. Н. Никуличев [Электронный ресурс]. – Режим доступа: ivdon.ru/ru/magazine/archive/n3y2013/1773 . – Загл. с экрана.
- Харламов, А. А. Сравнительный анализ организации систем синтаксических парсеров [Текст] / А. А. Харламов, Т. В. Ермоленко, Г. В. Дорохина [Электронный ресурс]. – Режим доступа: ivdon.ru/ru/magazine/archive/n4y2013/2015. – Загл. с экрана.
- Яцко, В.А., Алгоритмы и программы автоматической обработки текста // Вестник иркутского государственного лингвистического университета: Том 1, номер 17. – Иркутск: Евразийский лингвистический институт в г. Иркутске, 2012. – 150-160 с.
- Шарнин, М. М., Ищенко, Н. С., Пахмутова Н.Ю., Сюракшина Ю.В. Использование методов тематического моделирования многоязычных коллекций для прогноза тревожных событий [Текст] / М. М. Шарнин, Н. С.Ищенко, Н.Ю. Пахмутова, Ю.В Сюракшина [Электронный ресурс]. – Режим доступа: http://www.academia.edu/36763506/Использование_методов_тематического_моделирования_в_мультиязыковых_средах_для_прогноза_тревожных_событий _Topic_modeling_methods_in_multi-language_environments_for_troubling_events_prediction. – Загл. с экрана.
- Большакова Е.И., Клышинский Э.С., Ландэ Д.В., Носков А.А., Пескова О.В., Ягунова Е.В. Автоматическая обработка текстов на естественном языке и компьютерная лингвистика [Текст]/ Автоматическая обработка текстов на естественном языке и компьютерная лингвистика: учеб.пособие/Большакова Е.И., Клышинский Э.С., Ландэ Д.В., Носков А.А., Пескова О.В., Ягунова Е.В. — М.: МИЭМ, 2011. — 272 с.
- Ягунова Е.В., Пивоварова Л.М. Экспериментально- вычислительные исследования художественной прозы Н.В. Гоголя [Текст]/ Е.В. Ягунова, Л.М. Пивоварова [Электронный ресурс]. – Режим доступа: http://webground.su/data/lit/pivovarova_yagunova/Experimentalno-vychislitelnyie_issledovaniya_prozy.pdf. – Загл. с экрана.
- Ягунова Е.В. Ключевые слова в исследовании текстов Н.В. Гоголя [Текст]/ Е.В. Ягунова [Электронный ресурс]. – Режим доступа: http://webground.su/data/lit/yagunova/Kliuchevyie_slova_v_issledovanii_textov_N_V_Gogolya.pdf. – Загл. с экрана.
- Леонов А.Д. Методы автоматизированной коррекции специализированных естественно-языковых текстов [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2014/fknt/leonov/diss/index.html. – Загл. с экрана.
- Стуликова Н.В. Разработка и исследование алгоритма автоматического реферирования текстов на основе нечеткой логики [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2014/fknt/stulikova/diss/index.htm. – Загл. с экрана.
- Сторожук, Н. О., Коломойцева И.А. Анализ алгоритмов лексической и морфологической обработки текстов c целью определения жанровой принадлежности / Н. О. Сторожук, И. А. Коломойцева // Материалы V Международной научно-технической конференции «Современные информационные технологии в образовании и научных исследованиях» (СИТОНИ-2017). – Донецк: ДонНТУ, 2017. – С. 191-195.
- Стемминг [Электронный ресурс]. – Режим доступа: https://intellect.ml/stemming-stemmer-portera-6235. – Загл. с экрана.
- Алгоритмы интеллектуальной обработки больших объемов данных [Электронный ресурс]. – Режим доступа: http://www.intuit.ru/studies/courses/3498/740/info . – Загл. с экрана.
- Стеммер Портера для русского языка [Электронный ресурс]. – Режим доступа: https://medium.com/@eigenein/ . – Загл. с экрана.
- Стеммер Портера для русского языка [Электронный ресурс]. – Режим доступа: http://www.algorithmist.ru/2010/12/porter-stemmer-russian.html. – Загл. с экрана.
- Стемминг текстов на естественном языке [Электронный ресурс]. – Режим доступа: http://r.psylab.info/blog/2015/05/26/text-stemming/. – Загл. с экрана.
- Segalovich I., A fast morphological algorithm with unknown word guessing induced by a dictionary for a web search engine [Электронный ресурс] // Yandex-Team – Режим доступа: http://cache-mskdataline03.cdn.yandex.net/download.yandex.ru/company/iseg-las-vegas.pdf. – Загл. с экрана.
- Маннинг, К.Д. Введение в информационный поиск / К. Д. Маннинг, П. Рагхаван, Х. Шютце. – Москва : М.: ООО «И.Д. Вильямс», 2011. – 528 с.
- Salton G., Fox E., Wu H. Extended Boolean information retrieval. Communications of the ACM. 2001./ G.Salton, E,Fox, H.Wu.- Vol. 26. № 4. P. 35–43.
- Компьютерный анализ текста [Электронный ресурс]. – Режим доступа: http://lab314.brsu.by/kmp-lite/CL/CL-Lect/KAT.htm. – Загл. с экрана.
- Сторожук, Н. О., Коломойцева И.А. Реализация прототипа анализатора жанровой принадлежности произведений на основании векторно – пространственной модели представления документов / Н. О. Сторожук, И. А. Коломойцева // Материалы международной научно-практическаой конференции «Программная инженерия: методы и технологии разработки информационновычислительных систем» (ПИИВС-2018) – Донецк: ДонНТУ, 2018. – С. 132-137.