
Abstract
Contents
- Introduction
- 1. Theme urgency
- 2. Goal and tasks of the research
- 3. Overview of researches and developments
- 3.1 Overview of international sources
- 3.2 Overview of local sources
- 4. An approach to the russian text compression using remotely located dictionaries
- Conclusion
- References
Introduction
Over the past three decades, there has been a sharp jump in the development of the Internet and its spread – an increase in the number of computers connected to it. In conjunction with the growing number of users, this has led to a significant increase in the volume of transmitted and stored information.
Due to the continued growth of global networks and the expansion of the range of services they provide, with an exponential growth in the number of network users, as well as successful projects to digitize the contents of huge repositories of information, in particular libraries, exhibition halls and art galleries, it is expected that information stored and transmitted over communication systems will continue to increase at the same or even higher speed [1]. This process poses new tasks that need to be solved – such amounts of information must be stored, processed and transmitted in the most compact form. This raises the problem of compressing information of various types, including text.
1. Theme urgency
Over the decades of computer technology development, the problem of data compression with various degrees of success was solved by various archivers. Different degrees of success are due to the fact that archivers, although developed to solve one common problem (data compression), have obviously different approaches to its solution and accept different types of data as source data. Thus, archivers are both general-purpose (they work with different types of data) and those intended for specific types of data.
General-purpose archivers compress text data, but cope with this task less efficiently than specialized text compressors. However, many text archivers are mainly research, rather than practical, such solutions may require a significant amount of time for compression and decompression of data, which makes their everyday use difficult. In turn, among practical text-based archivers, there are no solutions that use remotely located dictionaries. Therefore, the task of compressing test data and finding new ways to solve it are important and relevant.
2. Goal and tasks of the research
The goal of the work is to develop a proprietary method and algorithms for compressing Russian text using remotely located dictionaries.
To achieve this goal it is planned to solve the following tasks:
- To analyze the existing methods for compressing text data.
- To create frequency dictionaries for the most commonly used words of the Russian language.
- To develop own algorithms for Russian text compression.
- To assess the feasibility of using the developed software for compressing Russian text.
The result of the work is software for compressing Russian text, developed in accordance with the proposed algorithms.
Scientific novelty of the work: for the first time a method of compressing Russian-language text was proposed, featuring the use of remotely located dictionaries, which reduced the volume of the archive containing text data in Russian.
3. Overview of researches and developments
Information compression is a problem that has a rather long history, much longer than the history of the development of computing technology, which usually went along with the history of the development of the problem of encoding and encrypting information [2]. The development of computing technology requires revising the old compression algorithms, developing new ones and adapting them to various technical devices with various computational capabilities and various communication channels. Therefore, the task of research and development of new data compression methods interests specialists all over the world, and they are actively engaged in its solution.
3.1 Overview of international sources
Foreign experts are actively involved in research on the compression of text data. It is worth noting an interesting fact, many of these works relate to the compression of the Arabic text.
In the article [3] Singh M. and Singh N. compare text compression algorithms: Huffman, Shannon-Fano, Arithmetic, LZ, LZW algorithm techniques. There are three types of text that are processed by a multimedia computer and these are: Unformatted text, formatted text and hypertext. Texts are captured from the keyboard and hypertext can be followed by a keyboard, mouse and some other devices when it being run on a computer. The original words in a text file are transformed into codewords having length 2 and 3. The most frequently used words use 2 length codewords and the rest use 3 length codewords for better compression. The codewords are chosen in such way that the spaces between words in the original text file can be removed altogether recovering a substantial amount of space.
In the article [4] Soori H., Platos J., Snasel V. and Abdulla H. note that the Arabic language is the sixth most used language in the world today. It is also used by United Nation. Moreover, the Arabic alphabet is the second most widely used alphabet around the world. Therefore, the computer processing of Arabic language or Arabic alphabet is more and more important task. In the past, several books about analyzing of the Arabic language were published. But the language analysis is only one step in the language processing. Several approaches to the text compression were developed in the field of text compression. The first and most intuitive is character based compression which is suitable for small files. Another approach called word-based compression become very suitable for very long files. The third approach is called syllable-based, it use syllable as basic element. Algorithms for the syllabification of the English, German or other European language are well known, but syllabification algorithms for Arabic and their usage in text compression has not been deeply investigated. This paper describes a new and very simple algorithm for syllabification of Arabic and its usage in text compression.
In the article [5] Abu Jrai E. assesses the effectiveness of LZW and BWT techniques for different categories of Arabic text files of different sizes. Compare these techniques on Arabic and English text files is introduced. Additional to exploiting morphological features of the Arabic language to improve performance of LZW techniques. We found that the enhanced LZW was the best one for all categories of the Arabic texts, then the LZW standard and BWT respectively.
In the article [6] Rathore Y., Pandey R. and Ahirwar M. claim that with the growing demand for text transmission and storage as a result of advent of net technology, text compression has gained its own momentum. Usually text is coded in yank traditional Code for data Interchange format. Huffman secret writing or the other run length secret writing techniques compresses the plain text. They have planned a brand new technique for plain text compression, that is especially inspired by the ideas of Pitman Shorthand. In these technique they propose a stronger coding strategy, which can provide higher compression ratios and higher security towards all possible ways in which of attacks while transmission. The basic idea of compression is to transform text in to some intermediate form, which may be compressed with higher efficiency and more secure encoding, that exploits the natural redundancy of the language in creating this transformation.
3.2 Overview of local sources
The problem of data compression is devoted to the following works of masters of Donetsk National Technical University:
- Kremeshnaya O.
Development of computerized long-time stored data compression system, based on experimental information
[7]; - Kozlenko D.
Research algoritms of compression information and choice the optimal from them for archiving data in environment system of automation laying-out rolled metal in UBM
[8]; - Boiko A.
Projecting of computer subsystem of data copressing by method of genetic programming
[9]; - Kramorenko Y.
Methods and algorithms of data compression for the transmission and storage of sensor data
[10].
It is worth noting that none of them was developing software for compressing Russian text using remotely located dictionaries.
4. An approach to the russian text compression using remotely located dictionaries
Data compression is an algorithmic transformation of information, during which its volume decreases. Compression can be lossless and lossless. The developed software for compressing Russian text using remotely located dictionaries should provide lossless compression, that is, the archiver should restore the compressed Russian text to its original state without any ch
Идея работы разрабатываемого архиватора состоит в замене слов, знаков препинания и специальных символов исходного текста соответствующими им кодами (уникальной последовательностью бит). Чем чаще встречается слово, тем меньшим количеством бит оно кодируется.
Words, symbols and their codes are stored in dictionaries and sorted by decreasing the frequency of occurrence. Dictionaries are stored in a database on the server and each of them is designed to store certain words and symbols. Thus, the following dictionaries are located on the server:
1) a dictionary for proper names;
2) a dictionary for punctuation marks;
3) a dictionary for special terms;
4) a dictionary for prepositions, particles, conjunctions and interjections;
5) a common dictionary for other words.
Distributing words and characters over several dictionaries instead of one has its weighty practical meaning – it will allow to encode words and symbols with the same, shortest bit sequences, which will improve the degree of text compression.
Dictionaries store the following information about a word: the identifier (number) of the word, the word itself, the frequency of occurrence of the word, and the code of the word. To create a database of dictionaries and fill them with the necessary data, it is necessary to develop an auxiliary program - a parser. This program should perform the following actions:
1) determine the frequency of occurrence of words, punctuation marks in the text under consideration (for obtaining optimal information on the frequency of occurrence of words and symbols it is necessary to process with a parser at least 100 tests with a volume above 20,000 words);
2) enter the words and the frequency of their occurrence in the appropriate dictionaries;
3) sort the words by the frequency of their occurrence;
4) based on the frequency of occurrence of a word, determine its code by a Huffman algorithm.
Consider a simple example illustrating the operation of the Huffman algorithm. Let the text in which the word day
occurs 5 times, the word many
occurs 8 times, the word after
occurs 3 times, the word through
occurs 1 time, the word quiet
occurs 4 times and the word also
occurs 6 times. Building a code tree using a Huffman algorithm consists of the following steps:
1) from the available words, two with the lowest values of occurrence are selected;
2) the top of the tree is created and these two words become its parents;
3) the sum of the occurrence of her parents is recorded at the peak;
4) items 1-3 are performed until all words become parents of the tree top;
5) marks the path to each vertex of the tree (to the right – 1, to the left – 0).
The resulting sequences are codes corresponding to each word. The code tree is shown in Fig. 1.
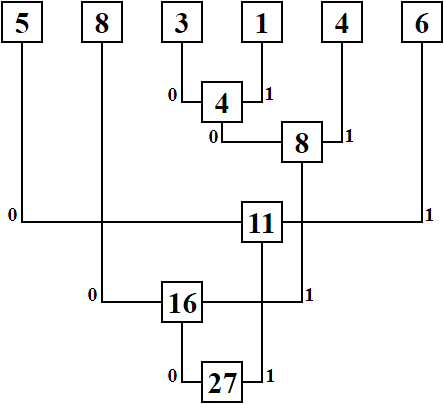
Figure 1 – Huffman code tree
Thus, each word will correspond to a unique code. They are listed in Table 1.
Table 1 – Words and their respective codes
| Word | Frequency of occurrence | Code |
| many | 8 | 00 |
| also | 6 | 11 |
| day | 5 | 10 |
| quiet | 4 | 011 |
| after | 3 | 0100 |
| through | 1 | 0101 |
The developed archiver is a client-server application. The client part breaks the source text into words, punctuation marks and sends them to the server. The server, in turn, finds in the database of dictionaries a code corresponding to a word, a punctuation mark, and returns it to the client along with the identifier of the dictionary from which it was taken. The process of information exchange between the client and server parts of the application is shown in Fig. 2.
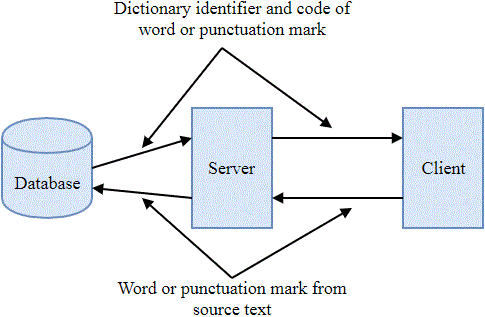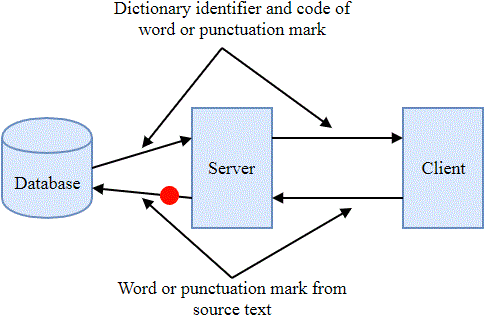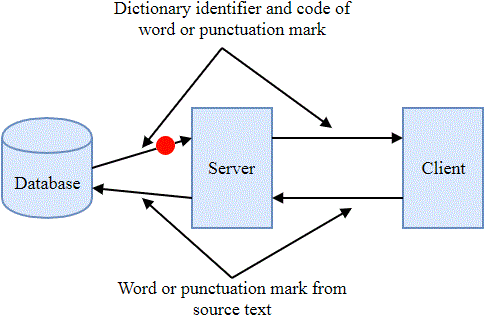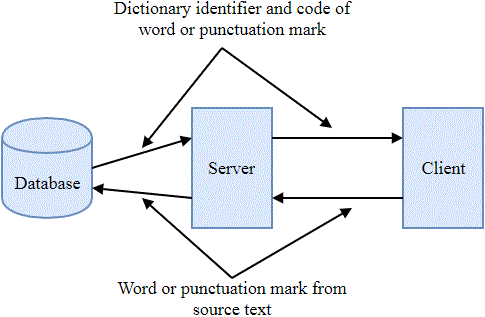
Figure 2 – The process of information exchange between the client and server parts of the application
(animation: 10 frames, 7 cycles of repeating, 46 KB)
The client part of the application archives the data received from the server. Dictionary identifiers have a fixed length of 3 bits, and the codes of words and punctuation marks have, respectively, a dynamic length. Thus, the resulting archive is a sequence of bits, in which the dictionary identifier and the code of a word or punctuation mark are sequentially recorded. Unarchiving occurs in a similar way: a sequence of bits of compressed text is divided into dictionary identifiers and codes of words or punctuation marks, the client sends them to the server. The server returns a word or punctuation mark that corresponds to the code found in the dictionary with the given identifier.
Conclusion
Based on the material studied, it can be concluded that scientists all over the world are interested in the problem of compressing textual information. They conduct research in this area and offer their own solutions to this problem. However, their developments are experimental in nature; they have not been introduced into mass practical use; there is no approach to compressing text that could be considered a standard. Therefore, the search for new solutions make sense and will continue. It also became clear that among the presented works there are no ideas that use remotely placed dictionaries.
As a result of the work done, tasks were identified that need to be solved during the development of software for compressing Russian text using remotely located dictionaries. It is expected that the described approach will allow to achieve a good degree of compression of Russian test data, due to the storage of statistical dictionaries not in the archive with compressed text, but on the server.
At the time of writing this abstract the master's work is not completed yet. Expected completion date: May 2018. The full text of work and materials on the topic can be obtained from the author or his scientific supervisor after the specified date.
References
- Ратушняк О. А. Методы сжатия данных без потерь с помощью сортировки параллельных блоков [Electronic resource]. – URL: http://www.dissercat.com/content/metody-szhatiya-dannykh-bez-poter-s-pomoshchyu-sortirovki-parallelnykh-blokov.
- Обзор методов сжатия данных [Electronic resource]. – URL: http://www.compression.ru/arctest/descript/methods.htm.
- Singh M., Singh N. A study of various standards for text compression techniques [Electronic resource]. – URL: http://www.academia.edu/6671724/a_study_of_various_standards_for_text_compression_techniques.
- Soori H., Platos J., Snasel V., Abdulla H. Simple rules for syllabification of arabic texts [Electronic resource]. – URL: https://link.springer.com/chapter/10.1007/978-3-642-22389-1_9.
- Abu Jrai E. Efficiency lossless data techniques for arabic text compression [Electronic resource]. – URL: https://pdfs.semanticscholar.org/edd3/b182db340980746f8910ec1c35b02cc76521.pdf.
- Rathore Y., Pandey R., Ahirwar M. Digital shorthand based text compression [Electronic resource]. – URL: http://www.academia.edu/11704694/Digital_Shorthand_Based_Text_Compression.
- Кремешная О. А. Разработка компьтеризированной системы сжатия информации, полученной в результате научных экспериментов, для долговременного хранения [Electronic resource]. – URL: http://masters.donntu.ru/2004/kita/kremeshnaya/.
- Козленко Д. А. Исследование алгоритмов сжатия информации и выбор оптимального из них для архивации данных в среде системы автоматизации раскроем проката на НЗС [Electronic resource]. – URL: http://masters.donntu.ru/2005/fvti/kozlenko/.
- Бойко А. В. Проектирование компьютерной подсистемы сжатия данных методом генетического программирования [Electronic resource]. – URL: http://masters.donntu.ru/2005/kita/boiko/index.htm.
- Краморенко Е. Г. Методы и алгоритмы сжатия информации для передачи и хранения сенсорных данных [Electronic resource]. – URL: http://masters.donntu.ru/2013/fknt/kramorenko/index.htm.