
Computer modeling and design
In today's rapidly developing information society, the problem of storing and transmitting information is quite acute. Despite the constantly growing cumulative amount of information media, it is sometimes necessary to store a large amount of data in a small repository
Data redundancy is often associated with the quality of information. It improves clarity and perception of information. However, when storing and transferring information using computer hardware, redundancy can lead to increased costs for storing and transferring information. This problem is particularly relevant in the case of processing huge amounts of information with small amounts of data carriers. In this regard, there is always the problem of reducing redundancy or data compression
A compressed (packed) file is called an archive. The process of writing a file to an archive file is called archiving (packing, compressing), and extracting a file from an archive is called unzipping (unpacking). Information archiving is the transformation of information in which the amount of information decreases, and the amount of information remains the same [1].
Today, archivers are used primarily for putting data on the Web. Most of the drivers on the manufacturers' websites are laid out precisely in the archives, and most of the programs on various resources are also archived. By the way, the user himself, before posting any data on the Web (for example, on file-sharing resources), packs the data into the archive [2]
Most digital data is stored in binary files. Pure text files are somewhat rare (probably less than 2% of the data in the world). There are several reasons why binary files are used:
1. Input and output are much faster using binary data. Converting a 32-bit integer to characters takes time. Not a great deal of time, but if a file (such as an image file) contains millions of numbers the accumulated conversion time is significant. Computer games would slow to a crawl if their data were stored in character form.
2. A binary file is usually very much smaller than a text file that contains an equivalent amount of data. For image, video, and audio data this is important. Small files save storage space, can be transmitted faster, and are processed faster. Input/output with smaller files is faster, too, since there are fewer bytes to move.
3. And almost never is a human going to look at the individual data samples, so there is no reason to make it human-readable. For example, humans look at the entire picture of a GIF file, and have little interest in looking at the individual pixels as numbers. Sometimes a programmer or scientist needs to do this, perhaps for debugging or scientific measurements. But these special occasions can use hex dumps or other specialized programs [3].
Therefore, it is the binary data that was chosen to work in the software being developed.
When using a PC, information may be lost for various reasons: due to physical damage to the disk, improper correction or accidental deletion of a file, destruction of information by a virus, etc. Backup tools provided by the operating system and shell programs for storing information require large amounts of external memory. It is more convenient to use special programs for creating archive files that compress information [4].
Compression is a way to encode digital data so that it takes up less memory. For data compression, two types of methods are used - with loss and without data loss. Data loss methods can compress a file, but some data is lost forever. And compression methods without data loss compress information without distorting it and without losing anything during this process. After the restoration, the original document is identical to the original document with bit accuracy [5]. Therefore, when working with binary data, it is necessary to use compression methods without losing data. One of these are image compression algorithms that will be used in this work.
The aim of the work is to develop a method of compressing binary data based on image compression methods.
In the process of work, you must perform the following tasks:
The result of the work is a developed method and software tool for archiving data based on known image compression algorithms.
Due to the growing volumes of processed and stored information, the archiving of data with their compression is of particular importance.
The task of efficient data compression has always been one of the most relevant in computer science, and with the development of computer, digital technology and the Internet, it has become even more important.
Data compression methods have a rather long history of development, which began long before the appearance of the first computer [6]. There are already quite a few standardized compression methods [7], but the need for the emergence of new and improved methods still remains.
In the article [8] Salauddin M. proposed a new compression method for general data based on a logical truth table. The sequence of input data is checked where it is even or odd. If the sequence is odd, then a bit is added, 0 or 1, depending on the last bit, and if it is even, then this step is skipped. If the last bit of the input sequence is 0, then 0 is added, and if it is 1, then 1 is added. Then the binary data is represented by one bit based on the proposed truth table. Thus compressed data is performed.
Satesh R., Mr. R. Mokhan, Mr. P. Partasarati in the article [9], which describes the algorithm of hiding one image in another, are non-standard for compressing information. As a result, the amount of space occupied is reduced by half images
Pavlov I. In his work [10] he presented various variants of algorithms for searching for matching sequences of characters, which is a preliminary procedure for compressing data using the Lempel – Ziv algorithm. The proposed algorithms, in contrast to the known ones, are based on the use of digital search trees, which leads to a low criticality of the time spent on the search to the length of the original sequence of characters. In addition, the proposed algorithms allow you to choose the optimal variant of the search algorithm depending on the available computing resources. The developed modification of the Lempel-Ziv algorithm provides an increase in the degree of compression in comparison with its known variants by 10-40% depending on the data.
The masters of Donetsk National Technical University also considered the topic of data archiving and compression:
The development of software for archiving binary data based on image compression algorithms was not found in the master’s work.
Archiving of binary data must be based on image compression algorithms, so for this to happen, binary files must be presented as raster images before compression. A feature of the bitmap image is that, as a mosaic, it consists of small parts called pixels. It is into such parts that you need to split a binary file. Each pixel is described by a triple of numbers corresponding to the brightness of the basic components in the RGB color representation model.
The color in the RGB model is represented as the sum of three basic colors - red (Red), green (Green) and blue (Blue). The name of the model is composed of the first letters of the English names of these colors. In fig. 1 shows what colors are obtained by adding the three basic ones.
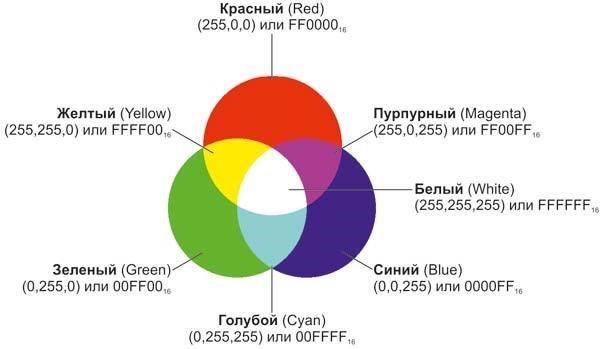
Figure 1 - Combinations of basic colors of the RGB model [14]
Since the brightness of each of the basic color components can take only 256 integer values, each value can be represented by an 8-bit binary number (a sequence of 8 zeros and ones) or, in other words, one byte. Thus, in the RGB model, information about each color requires 3 bytes [14].
Converted from a binary file pixels must be saved in a file that uses the specified format of the bitmap image file and which is given a name with a three-letter extension. Bmp. The specified bitmap file format consists of a bitmapfileheader structure, followed by a bitmapinfoheader structure and an rgbquad array of structures (also called a color table). The color table is accompanied by a second array of indices into the color table (actual bitmap data).
The bitmapfileheader structure identifies the file, specifies the file size in bytes and the offset from the first byte in the header to the first byte of the bitmap data. The bitmapinfoheader structure defines the width and height of the bitmap image in pixels; the color format (the number of color planes and color bits per pixel) of the display device on which the bitmap was created; whether the bitmap data was compressed before storage and the type of compression used; the number of bytes of raster data; the resolution of the display device on which the bitmap was created; and the number of colors represented in the data. The RGBQUAD structures set the luminance RGB values for each of the colors in the device palette [15]
In order to completely convert the pixels converted from a binary file into a bitmap image, it must first be supplemented at the beginning with the filled bitmapfileheader and bitmapinfoheader structures that are necessary to identify the bitmap in .bmp format.
After creating a bitmap in .bmp format, it is converted to the .png format using the Deflate compression method, or to the .pcx format that uses RLE compression.
The process of archiving binary data based on data compression algorithms is shown in fig. 2

Figure 2 - The process of archiving / unarchiving data based on image compression algorithms (animation: 10 frames, 7 cycles, 52 kilobytes)
With a steady rate of increase in the amount of information, the task of archiving and compressing data remains relevant and is interested in it all over the world. Developers offer their new solutions. However, research and development of improved compression methods continues.
In the course of the work, tasks were identified that must be solved for the successful development of an archiving software tool, the implementation of which should provide an improved method of compressing binary data.
At the time of writing this essay the master's work is not yet completed. Final Completion: May 2019. The full text of the work and materials on the topic can be obtained from the author or his manager after the specified date.