Анотация: В распределенном масштабе предприятия информация распространяется между разнородными сайтами и всегда обрабатывается отдельно. Поиск через разные сайты может стать сложной задачей из-за различия контекста между узлами распределенной системы. Мы предлагаем в этой статье - уровень доступа высокого уровня с возможностью семантического анализа, семантическое резюме индекса. Этот слой предназначен для оптимизировать потребление полосы пропускания и уменьшить усилия локальных поисковых систем. Этот компонент также улучшает качество результаты поиска с помощью Word Mover Distance для получения семантически близких результатов.
Ключевые слова: распределенный, семантический, поиск, гетерогенный, tf-idf, wmd
1 Введение
В настоящее время объем производимых данных растет в геометрической прогрессии. Таким образом, системы распределенной параллельной обработки широко используются для поиска эффективного решения для поддержания приемлемой производительности вычислений. Кроме того, многие исследования признали критический аспект выполнения поисковых операций. Для распределенных баз данных это все еще трудная задача для поиска и получения результатов с желаемыми требованиями с точки зрения времени отклика и эффективности результатов особенно в гетерогенных средах. Для этого поисковые системы всегда были эффективной системой в чтобы улучшить качество поиска и ускорить доступ.
Поисковые системы обычно работают, индексируя исходный контент в оптимизированной структуре для ускорения поиска и расширенные возможности поиска, такие как расширенное усечение, фонетический поиск, тезаурус, контекст и близость [1]. Люцен высокопроизводительная среда с открытым исходным кодом, полностью написанная на Java, для обеспечения полнофункциональной системы текстового поиска библиотека. Он может работать с любым типом хранилища данных. Таким образом, добавление этого уровня абстракции открывает стандартный интерфейс для клиентов различных репозиториев (пользователей и систем).
Однако применительно к распределенным базам данных в гетерогенных средах Lucene имеет несколько недостатков. Например, он не поддерживает требования к индексации в реальном времени. Кроме того, весь индекс должен быть резидентная память для поддержки времени ответа на запрос с малой задержкой. При обновлении документа необходимо удалить старые документ и переиндексировать новый. Еще одна проблема для аналитики больших данных заключается в том, что сталкиваться с ней непрактично. более длительные задержки между загрузкой данных и запуском операций поиска данных.
В качестве попытки повысить производительность поиска в гетерогенных распределенных базах данных мы предлагаем в этой статье вклад, сочетающий в себе использование индексов Lucene и алгоритмов кластеризации в распределенных средах. Эта статья организована следующим образом. В разделе 2 приведены некоторые недавние работы, посвященные этому варианту использования. Раздел 3 вводит метод семантического резюме индекса. В разделе 4 подробно описаны реализация и результаты тестирования. Раздел 5 резюмирует нашу работу в этом документе и будущую работу, которую необходимо выполнить для адаптации МКС с большими производственная среда.
2 Сопутствующие работы
В этой статье мы изучаем кластеризацию распределенных индексированных данных. Многие работы были связаны с текстовыми данными. индексирование и кластеризация индексов. Кластеризация текстовых документов по-прежнему недоступна поисковой системе. инструменты оптимизации из-за ограничения согласованности поисковых запросов [6]. Представили Scatter / Gather способ улучшить как задержку кластеризации, так и точность поиска. Эмпирическая идея состоит в том, чтобы добавить «оглавление» например, предварительный индекс для ускорения доступа. Авторы утверждают, что новый слой согласовывает индексы поисковых систем с процессом кластеризации [1]. Работали над определением «зернистых кластерных капель», которое выбирает краткое изложение некоторых результаты запроса. Кластер продолжает развиваться за счет новых потоковых данных и запросов пользователей.
Такой подход вполне перспективен для категориальной кластеризации текстовых данных в онлайн-контексте. Основная проблема с кластеризацией текстовых данные - это метод преобразования и его эффективность. Более того, онлайн-ограничение включает другой уровень сложность того, как поддерживать результирующий кластер в актуальном состоянии новыми входящими данными [1]. Решил эту проблему использование потокового источника и постоянное обновление состава кластера. Интересная работа, выполненная [8] и вдохновленный цитатой Алана Тьюринга, касался одного из способов построения этого конкретного типа кластера. На острове модельный генетический алгоритм используется для разделения коллекции документов на кластеры путем создания набора поисковых запросы. Кластер определяется документами, возвращаемыми одним запросом в наборе. Кластер не построен с использованием классический K-Means [14] или любой из его вариантов [13], но с повторным использованием запросов конечных пользователей и ранжирования их результатов поиска.
3. Подход семантического резюме индекса (ISS)
В этом разделе мы описываем наш подход к предоставлению единого интеллектуального и быстрого доступа к разнородной распределенной система. Первый шаг к предоставлению этого резюме - поддержание стандартного интерфейса доступа к исходным данным, поскольку мы имеют дело с неоднородной средой. Индексы поисковых систем - хорошая альтернатива для этой цели. Эти поисковые индексы построены путем создания статистической меры частоты использования терминов, смягчаемой обратным частота. Обычно на него ссылаются TF-IDF [13], сокращенное название для «Term Frequency - Inverse Term Частота» и описывает, насколько важно слово в корпусе. Термин частота f (d, t) - это количество раз слово t встречается в документе d. В данной работе мы предпочитаем логарифмическую шкалу этой меры (1).
Хотя поисковые индексы содержат слишком много важных деталей и оптимизаций, матрица TF-IDF является основным компонентом индексов. Среди информации, хранящейся в этих индексах, есть позиции терминов, исходная и оптимизированная форма термина, фонетическая ценность и некоторая дополнительная информация для поиска. Чтобы отслеживать источник информации, нам нужно сохранить в каждом локальном индексе ссылку на сайт в дополнение к указателю на целевой документ. Эта информация собирается и агрегируется контейнером агрегирования индекса (рис. 1). Этот компонент регулярно запрашивает индекс каждого сайта, чтобы получить обновленный словарь TF-IDF. После сохранения данных в ISS Store компонент реферирования объединяет эти словари в централизованное резюме. Внутренний компонент считывателя TF-IDF считывает и преобразует словарь указателя (термины, позиции и исходные документы) в представление в векторном пространстве, чтобы его можно было обработать с помощью компонента нечеткой кластеризации. Этот компонент нечеткой кластеризации имеет особенность, поскольку он будет полагаться на расстояние перемещения слов [12] для оценки кластера.
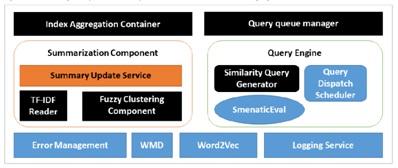
«Механизм запросов» ISS предоставляет интерфейс для управления параллельными запросами, «Диспетчер очереди запросов». «Генератор запросов на подобие» выводит на основе исходного запроса подмножество похожих запросов. Эти альтернативные запросы оцениваются компонентом «Семантическая оценка». Если запрос подтвержден «семантической оценкой», он отправляется в «Планировщик отправки запросов» (QDS). QDS использует обобщенные кластеры, чтобы решить, на какие сайты нацеливаться. Затем запросы отправляются в «Диспетчер очереди запросов» (QQM). Этот компонент будет отвечать за определение порядка выполнения входящих запросов.
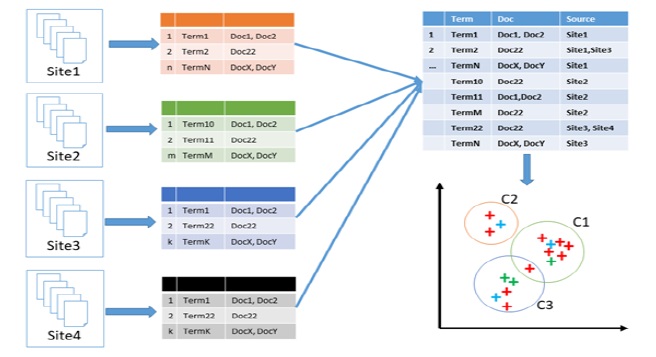
Основная цель кластеризации - предложить общий обзор одного и того же предмета в разных контекстах. Вход в процесс индексации - это индексная таблица распределенных сайтов (рис.2). Для построения МКС наш алгоритм кластеризации использует словарь другого сайта и сохраняет ссылки на источник каждого термина. Поскольку тот же срок может иметь в разных смыслах в контексте разных сайтов, мы применяем реализацию Fuzzy-Kmeans.
Основная цель кластеризации - предложить общий обзор одного и того же предмета в разных контекстах. Вход в процесс индексации - это индексная таблица распределенных сайтов (рис.2). Для построения МКС наш алгоритм кластеризации использует словарь другого сайта и сохраняет ссылки на источник каждого термина. Поскольку тот же срок может иметь в разных смыслах в контексте разных сайтов, мы применяем реализацию Fuzzy-Kmeans.
Чтобы устранить неудобства, связанные с «наивным» измерением расстояния, мы внедряем инструмент word2vec для построения семантически чувствительные кластеры. Word2Vec - это набор инструментов машинного обучения и обработки естественного языка, которые производят слово вложение [3, 8]. Вход word2vec - это корпус, который в нашем случае является глобальным словарем инвертированного индекса, и создает векторное пространство, где слова, использующие один и тот же контекст, вероятно, будут иметь минимальное расстояние в этой модели векторного пространства. Другими словами, два семантически близких слова имеют минимальную евклидову меру расстояния. Таким образом, перед выполнением шага 3 алгоритмов Fuzzy KMeans мы инициализируем word2vec с предварительно обученным набором отношений. Измерение расстояния на шаге 3 будет заменено измерением расстояния word2vec.
Чтобы проиллюстрировать эту идею, мы рассмотрим пример использования международной химической лаборатории, расположенной по всему миру и работающей в различных областях. Одна из лабораторий агрохимии обнаружила, что если они включат асприн в одну из обработок своих культур, скорость роста удвоится. В другой части мира лаборатория красоты и здравоохранения изобрели новое вещество, которое может почти мгновенно удалять перхоть с помощью салициловой кислоты, одного из основных компонентов аспирина. В третьей части мира коммерческая организация, связанная с тем же предприятием, получила множество заявлений о возможной связи между новым диетическим чаем, содержащим один из компонентов аспирина, и выпадением волос. Если лабораторный поисковик будет использовать только свою локальную внутреннюю базу данных, все, что они увидят, это их надежные и конфиденциальные исследования об аспирине. Им придется пройти множество различных тестов, прежде чем они смогут обнаружить возможную связь между аспирином и выпадением волос. Теперь, если бы у них был глобальный обзор своих внутренних и надежных данных по всему миру, коэффициент риска можно было бы отнести к этой конкретной молекуле непосредственно на основе только их поисковой системы. Кластерное представление на верхнем уровне системы - это не только указатель на различные системы, относящиеся к поиску пользователей, но и мощный инструмент для принятия бизнес-решений.
Использование кластеров для распределенного поиска
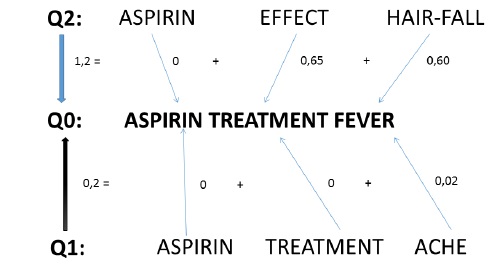
После процесса кластеризации наш распределенный словарь резюмируется в кластерное векторное пространство с семантически чувствительным расстоянием и элементами, связанными с сайтами. Чтобы выполнить поиск по этой сводке верхнего уровня, использование Word Mover Distance (WMD) является правильным выбором, поскольку она высвободит обобщенные знания о кластерах. Одна интересная особенность использования этого ввода для WMD состоит в том, что мы избегаем проблемы производительности WMD, связанной с очень запутанным потоком между похожими словами [2, 11], поскольку мы разделяем потоки с помощью дискриминатора удаленных сайтов и имеем дело с обобщенным корпусом. Фактически, было замечено, что ОМУ плохо масштабируется, особенно с корпусом с высокой вариабельностью (содержащим много разных слов даже после стемминга). Чтобы проиллюстрировать идею, пример, описанный на рис.4, представляет собой пример семантического резюме индекса. Пусть исходный запрос пользователя будет «ASPRIN TREATMENT FEVER». В дополнение к исходному запросу «ASPIRIN TREATMENT ACHE» будет предложено ISS в результате преобразования низкой стоимости ОМУ (0,2 в этом примере) (рис.3). Один из интересных запросов, который также будет предложен ISS - это «ASPIRIN EFFECT HAIR-FALL». Этот запрос будет отправлен на удаленный сайт, который не имеет ничего общего с первой целью поиска, но может выявить скрытую сторону информации. Именно в этом пункте разница между различные подходы к принятию бизнес-решений: чем шире обзор, тем лучше будет решение.
4. Реализация и результаты
Полный подход был реализован с использованием IPython, запущенного на ноутбуке Jupyter. Входной набор данных - это 20 новостей. Группы от Google. Мы смоделировали 20 разных сайтов, разделив новости на отдельные группы. Код был протестировано на 4 отдельных виртуальных машинах, установленных поверх Ubuntu. Код доступен на [https://github.com/hassenfadoua/iss].
Чтобы измерить производительность подхода ISS, мы сначала запускаем 20 запросов, построенных путем конкатенации случайных слов из входной словарь. Затем мы взяли самый медленный запрос в первом тестовом проходе и отправили одни и те же запросы 20 раз. Этот второй тест предназначен для измерения интереса к добавлению кеша для маршрутизации повторяющихся запросов без вызова «Планировщик отправки запросов».
Вторая особенность, которую мы исследовали в этой работе, - это качество результатов поиска. Сгенерированные поисковые запросы должны удовлетворяют, по крайней мере, следующим условиям: 1) Результат исходного запроса должен содержаться в результате сгенерированные запросы. 2) Дополнительные результаты поиска должны соответствовать исходному поиску с настраиваемым коэффициентом неопределенности.
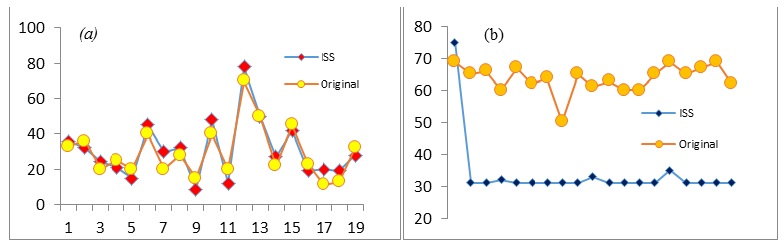
Рисунок 4 (a) и (b) были построены после множества тестовых снимков, чтобы гарантировать, что время прогрева не влияет на общее поведение времени отклика при поиске. Время выполнения случайного запроса, показанное на рис. 4 (а), показывает, что время выполнения почти одинаково как через ISS, так и без него. Однако количество запросов, выполняемых каждый раз, выше при использовании «генератора запросов подобия» ISS. Первоначальный подход отправляет один запрос для каждого поискового запроса клиента, тогда как ISS отправляет по крайней мере один запрос каждый раз, когда стоимость оценки WMD для ближайшего запроса выше, чем тета. В большинстве случаев ISS выдавала более 5 различных запросов для каждого поискового запроса клиента.
С другой стороны, количество запрашиваемых сайтов всегда было меньше, чем исходный запрос пользователя. Первоначальный поисковый запрос должен быть отправлен на все сайты, поскольку интерфейс не знает, где искать эту информацию. В ISS оптимизирован таргетинг на сайты. Эта оптимизация снижает как потребление полосы пропускания, так и работу различных сайтов. Чтобы узнать больше о преимуществах использования ISS, время выполнения повторяющегося запроса всегда было меньше, чем у исходного запроса. Такое поведение, изображенное на рис. 5 (b), можно объяснить ролью планировщика диспетчера запросов, который поддерживает историю расчетов предыдущих целей. После первого запроса ISS знает, куда отправлять запросы напрямую. Эта оптимизация значительно повышает производительность поиска и снижает усилия, необходимые в интенсивном контексте.
5. Заключение и дальнейшая работа
В этой работе мы описали наш подход к оптимизации распределенного поиска путем добавления глобального словаря на высоком уровне. уровень абстракции от поисковых сайтов. Этот словарь был построен с использованием матриц TF-IDF с каждого сайта. Эти «сводные» матрицы были построены путем индексации данных сайта. Чтобы сделать этот глобальный словарь интеллектуальным, мы ввели word2vec инструмент для построения семантических кластеров. Мы дали имя Index Semantic Summary (ISS) результату этот процесс. Чтобы запустить распределенный поиск, мы сначала проходим через ISS, чтобы сгенерировать семантически связанные запросы и направить их на соответствующие сайты. Представленный подход показал приемлемые характеристики по сравнению с плоской подход (отправка запроса на все сайты). ISS показала лучшую производительность на повторяющихся запросах, которые могут быть очень полезно при повторных поисковых запросах. Помимо производительности, качество поиска результаты были значительно улучшены за счет более широкого обзора распределенной системы. Этот подход все еще требует дополнительной работы для улучшения непрерывного процесса приема. Дальнейшая работа должна охватывать другие показатели качества поиска. Собственно, актуальность приписывалась авторами, что является обычной практикой даже в крупнейшие поисковые системы мира. Мы намерены найти математическую модель для описания актуальности следующие выпуски.
Список источников
- Aggarwal, Charu C., and S. Yu Philip. "On clustering massive text and categorical data streams." Knowledge and information systems 24.2 (2010): 171-196..
- Alshahrani, Mohammed, Spyridon Samothrakis, and Maria Fasli. "Word mover's distance for affect detection." the Frontiers and Advances in Data Science (FADS), 2017 International Conference on. IEEE, 2017..
- Al-Maskari, Azzah, Mark Sanderson, and Paul Clough. "The relationship between IR effectiveness measures and user satisfaction." Proceedings of the 30th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 2007.
- Bing, Lidong, et al. "Learning a unified embedding space of web search from large-scale query log." Knowledge-Based Systems (2018).
- Busa-Fekete, Robert, et al. "An apple-to-apple comparison of learning-to-rank algorithms in terms of normalized discounted cumulative gain." 20th European Conference on Artificial Intelligence (ECAI 2012): Preference Learning: Problems and Applications in AI Workshop. Vol. 242. Ios Press, 2012.
- Cutting, Douglass R., et al. "Scatter/gather: A cluster-based approach to browsing large document collections." ACM SIGIR Forum. Vol. 51. No. 2. ACM, 2017.
- Fu, Zhangjie, et al. "Enabling semantic search based on conceptual graphs over encrypted outsourced data." IEEE Transactions on Services Computing (2016). Goldberg, Yoav, and Omer Levy. "word2vec explained: Deriving mikolov et al.'s negative-sampling word-embedding method." arXiv preprint arXiv:1402.3722 (2014).
- Hirsch, Laurence, and Alessandro Di Nuovo. "Document clustering with evolved search queries." Evolutionary Computation (CEC), 2017 IEEE Congress on. IEEE, 2017.
- Huang, Gao, et al. "Supervised word mover's distance." Advances in Neural Information Processing Systems. 2016.
- Ioannakis, George, et al. "RETRIEVAL-An Online Performance Evaluation Tool for Information Retrieval Methods." IEEE Transactions on Multimedia 20.1 (2018): 119-127.
- Kusner, Matt, et al. "From word embeddings to document distances." International Conference on Machine Learning. 2015.
- Turney, Peter D., and Patrick Pantel. "From frequency to meaning: Vector space models of semantics." Journal of artificial intelligence research 37 (2010): 141-188.
- Ramos, Juan. "Using tf-idf to determine word relevance in document queries." Proceedings of the first instructional conference on machine learning. Vol. 242. 2003.
- Wang, Jianfeng, et al. "Optimized cartesian k-means." IEEE Transactions on Knowledge and Data Engineering 27.1 (2015): 180-192.