
Abstract
Content
- Introduction
- 1. Relevance of the topic
- 2. Goals and tasks of the research
- 3. Description of the convolutional neural network architecture
- 3.1 Convolution layer
- 3.2 Pooling layer
- 3.3 Fully connected layer
- Conclusion
- References
Introduction
Computer vision is one of the important areas of artificial intelligence. Computer vision is the science of computers and systems software that can recognize and understand images and scenes. Computer vision also consists of various aspects, such as image recognition, object detection, image generation, super–resolution images and more. [1]
Convolutional neural networks (CNNs) dominate the field of object detection today. They are used to recognize images and videos, recommendation systems, image classification, medical image analysis, natural language processing, financial time series, etc. However, to create a successful detection system, it is not enough to take any of the networks and hope for a good result, since all networks differ in different techniques, approaches, architectures, but, most importantly, in their efficiency.
1. Relevance of the topic
Object detection technology is concerned with finding, identifying and tracking objects present in images and videos. This technology has spread rapidly in a variety of industries and today it helps automatic machines safely orientate and navigate the road, detects violent behavior in a crowded place, ensures proper quality control of parts in production, monitors traffic violations and a large variety of other things.
The main criteria for evaluating the efficiency of object detection by a convolutional neural network are accuracy and speed. To achieve good results, scientists come up with various network architectures and improve existing ones, use various techniques to increase speed or accuracy of the model. Moreover, each of the networks can be improved simply by adjusting the parameters of the used methods. Presently there are models that allow you to very accurately determine objects in images, but such models are often slow, compared to models that detect objects in real time but lack accuracy. The field of computer vision and, in particular, object detection is a relevant and actively developing field. Conferences and competitions are held every year where researchers present the results of their models, improvements they have made, or new techniques used to improve detection efficiency.
2. Goals and tasks of the research
The goal of this work is to research and develop intelligent methods for the selection and classification of objects in the image.
To achieve this goal, the following tasks were formulated:
- Analysis of modern methods for detecting objects in images, their basic principles and approaches.
- Selection of the most versatile model capable of detecting objects in images accurately and at high speed, spending the minimum amount of computing power.
- Improving the model by changing the architecture or adjusting training parameters or the parameters of the used methods.
- Analysis of model training results with different parameter settings on one dataset and selection of the model with the best performance.
- Implementation of a software product for interacting with the resulting object detection model with the possibility of user loading images and saving the results.
3. Description of the convolutional neural network architecture
Convolutional Neural Network (CNN) is a special architecture of artificial neural networks proposed by Yann LeCun in 1988 [2] and aimed at efficient pattern recognition. The idea behind convolutional neural networks is to alternate convolutional layers and pooling layers. The structure of the network is feedforward (without feedbacks), fundamentally multilayer. Used for training standard methods, most often the back propagation method [3].
The name convolution
appeared due to the convolution operation, which consists in element–wise multiplication of each image fragment
by the kernel convolutions. The convolution kernel can also be called a matrix or a filter. The resulting image is also called feature map
.
A standard convolutional neural network consists of convolutional, pooling, and fully connected layers. The input image fed to the network
goes through many layers of convolution and pooling. The output of each layer is a feature map
of a reduced size, but with a larger number
of channels. The convolution and pooling layer are the main layers of the convolutional neural network, since they are the ones that extract
the features from the image, at the end of the network usually put several fully connected layers that use the resulting feature maps for
classification.
Figure 3.1 shows the operation of a convolutional neural network.
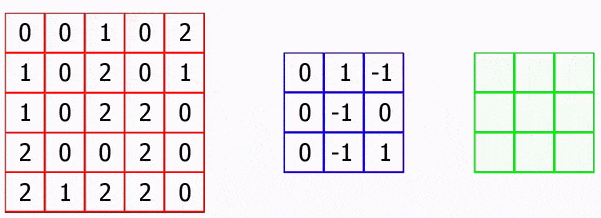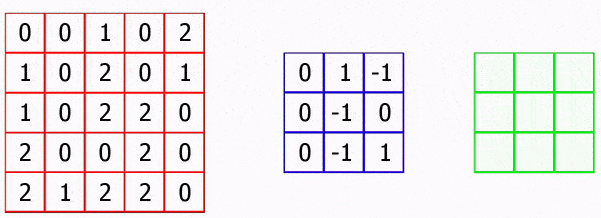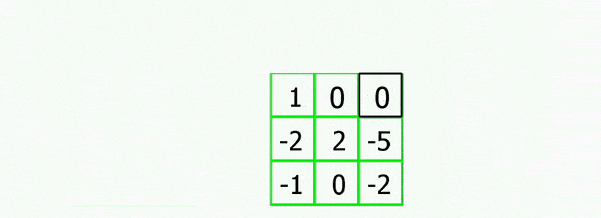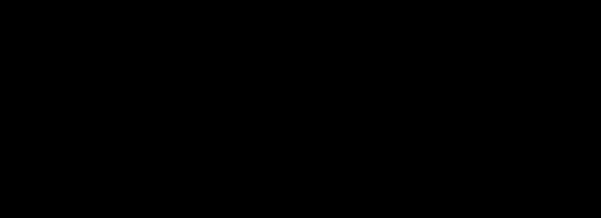
Figure 3.1 – Operation of a convolutional neural network
(animation: 43 frames, 3 repetition cycles, 252 kilobyte)
3.1 Convolution layer
The convolutional layer is the basic layer of any convolutional network (fig. 3.2). Usually, these layers are the largest in comparison with others. A convolutional layer contains a convolution kernel (filter) for each channel, obtained from the feature map of the previous layer.
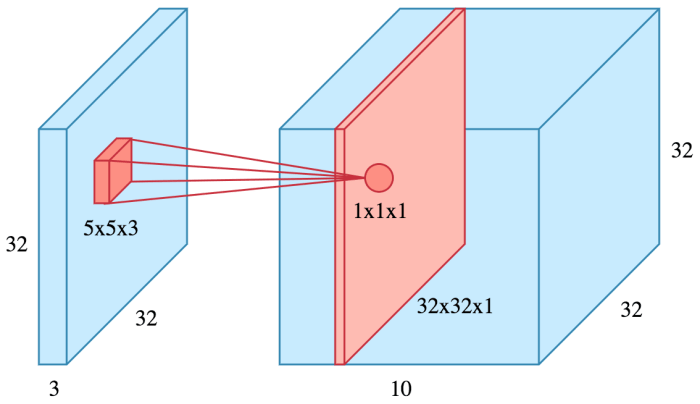
Figure 3.2 – Convolution layer
Usually in a convolutional layer, a weight matrix (convolution kernel) of a small size is used, this matrix is moved
over the entire
feature map (or input image – in the case of the first layer), which results in an activation signal for the neuron of the next layer (feature
map is formed). Such a matrix of weights is understood as encoding a feature, for example, a horizontal line or roundness. Since all CNNs contain
many layers, then there are many weight matrices in them, each of which encodes image elements. However, the encoding is not done by the
developers of the network, it is formed for each matrix independently, as a result of network training.
3.2 Pooling layer
A pooling layer (also called a downsampling or subsampling layer) is used to compress the feature map (fig. 3.3). Compression is performed by passing each group of pixels (usually 2x2) through a nonlinear transformation. As a non–linear transformation can be used: the maximum function (the pixel with the largest value is selected from the group of pixels), the minimum (the pixel with the smallest value is selected) or average value (the values ??of all pixels are summed and divided by the number of pixels in the group), etc. Most often in various CNN architectures the maximum function is used.
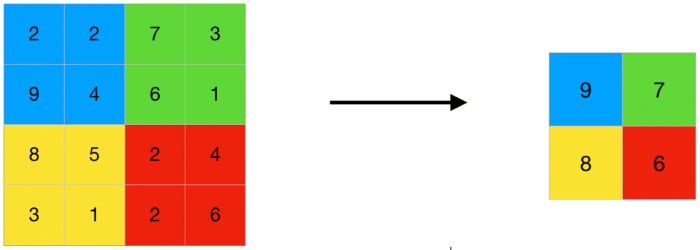
Figure 3.3 – Pooling layer
In typical architectures, the pooling layer is placed between convolutional layers. This layer allows you to reduce the size of the image and is understood as the process of compressing the image to a less detailed one, that is, the features already identified on the previous convolution layer are discarded. Also, besides reducing the image size, pooling reduces network overfitting.
3.3 Fully connected layer
After the input image passes through each convolution and pooling layer, its dimension decreases and the number of channels increases. In the end of the network, an image can consist of one pixel and many channels (in fact, a vector), storing a small amount of data.
This data is transferred to a fully connected layer (fig. 3.4), there can also be several such layers. A fully connected layer is an ordinary neural network in which each neuron is connected to all neurons of the next layer.
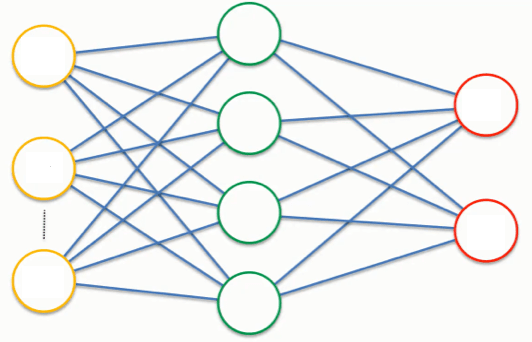
Figure 3.4 – Fully connected layer
The result of a fully connected layer is calculated by the same matrix multiplication as in conventional neural networks. The output of the last fully connected layer is a vector that represents the accuracy (or confidence) of the network for each of the classes in the dataset (vector size is the same length as number of classes).
Conclusion
This work reviewed papers on the development and application of intelligent methods for the selection and detection of objects on image. The modern methods used to solve the problem of object detection were reviewed: R–CNN (Fast R–CNN, Faster R–CNN), YOLO (YOLOv2), SSD, RefineDet. Early models, such as the R–CNN, were able to achieve good detection accuracy, however could not work in real time, since it was required to process a large amount of information, the speed could also decrease due to, for example, using a selective search algorithm, which was also time consuming. Subsequent models (YOLO, SSD, RefineDet) may work in real time, while also showing high detection accuracy. The architecture of a convolutional neural network is reviewed, convolution and pooling layers used to extract and learn features in the image, as well as a fully connected layer required for object classification.
Also, in the work were formulated the tasks necessary to achieve the goal of the master's work. In the future, it is planned to select and improve one of the modern models of object detection and software implementation of the software product using the resulting model.
When writing this essay, the master's work has not yet been completed. Final completion: May 2021. Full text of the work and materials on the topic can be obtained from the author or his manager after the specified date.
References
- Обнаружение объектов с 10 строчками кода [Электронный ресурс]. – Режим доступа: https://medium.com/nuances...
- Lecun Y. Gradient–Based Learning Applied to Document Recognition / Y. Lecun, L. Bottou, Y. Bengio, P. Haffner // Proceedings of the IEEE, Vol. 86, N 11, 1998. – pp. 2278–2324.
- Свёрточная нейронная сеть [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/...