
Реферат за темою випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі дослідження та заплановані результати
- 3. Огляд досліджень та розробок
- 3.1 Огляд міжнародних джерел
- 3.2 Огляд національних джерел
- 3.3 Огляд локальних джерел
- 4. Опис архітектури згорткової нейронної мережі
- 4.1 Шар згортки
- 4.2 Шар пулінгу
- 4.3 Повнозв'язний шар
- Висновки
- Перелік посилань
Вступ
Одним з важливих напрямків штучного інтелекту є комп'ютерний зір. Комп'ютерний зір – це наука про комп'ютери та системи програмного забезпечення, які можуть розпізнавати і розуміти зображення і сцени. Комп'ютерний зір також складається з різних аспектів, таких як розпізнавання зображень, виявлення об'єктів, генерація зображень і багато іншого [1].
На сьогоднішній день в області виявлення об'єктів домінують згорткові нейронні мережі (ЗНМ). Вони використовуються для розпізнавання зображень і відео, рекомендаційних системах, класифікації зображень, аналізі медичних зображень, обробці природної мови, фінансових часових рядах та ін. Однак для створення успішної системи виявлення недостатньо взяти будь–яку з мереж і сподіватися на хороший результат, так як всі мережі відрізняються різними техніками, підходами, архітектурами, але, найголовніше, своєю ефективністю.
1. Актуальність теми
Технологія виявлення об'єктів займається знаходженням, ідентифікацією та відстеженням об'єктів, присутніх на зображеннях і відео. Дана технологія набула швидкого поширення в різноманітних галузях і сьогодні вона допомагає машинам з автоматичним управлінням безпечно орієнтуватися і пересуватися по дорозі, виявляє жорстоку поведінку в людному місці, забезпечує належний контроль якості деталей на виробництві, стежить за порушенням правил дорожнього руху і велика безліч інших речей.
Основними критеріями для оцінки ефективності виявлення об'єктів згорткової нейронною мережею є точність і швидкість. Для досягнення хороших результатів вчені вигадують різні архітектури мереж і покращують вже існуючі, використовують різні методики для підвищення швидкості роботи або точності моделі. При цьому кожну з мереж можна поліпшити просто налаштувавши параметри використовуваних методів. На даний момент існують моделі, які дозволяють дуже точно визначати об'єкти на зображеннях, але такі моделі часто працюють повільно, в порівнянні з моделями, які дозволяють виявляти об'єкти в реальному часі, але відстають в точності. Область комп'ютерного зору і, зокрема, виявлення об'єктів є актуальною і активно зростаючою областю. Щороку проводяться конференції та змагання, де дослідники представляють результати роботи їх моделей, поліпшення які вони привнесли або нові використані методики, спрямовані на підвищення ефективності виявлення.
2. Мета і задачі дослідження та заплановані результати
Метою даної роботи є дослідження і розробка інтелектуальних методів виділення і класифікації об'єктів на зображенні.
Для досягнення поставленої мети були сформульовані наступні завдання дослідження:
- Аналіз сучасних методів виявлення об'єктів на зображеннях, їх базових принципів і підходів.
- Відбір найбільш універсальної моделі, здатної точно і з високою швидкістю виявляти об'єкти на зображеннях, витрачаючи мінімальну кількість обчислювальних потужностей.
- Поліпшення моделі шляхом змін в архітектурі або налаштування параметрів навчання і регулюванню параметрів використовуваних методів.
- Аналіз результатів навчання моделі з різними налаштуваннями параметрів на одному наборі даних і відбір моделі з найкращими показниками.
- Реалізація програмного продукту для взаємодії з отриманою моделлю виявлення об'єктів з можливістю користувацького завантаження зображень і збереженням отриманих результатів.
3. Огляд досліджень та розробок
На сьогоднішній день тема виявлення об'єктів є актуальною і активно розвивається в науковому середовищі. По темі написано багато статей з описом різних методів і їх застосуванням для вирішення завдання виявлення об'єктів.
3.1 Огляд міжнародних джерел
У 2014 році в статті Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation
[2] був
представлений алгоритм для виявлення об'єктів на основі згорткової нейронної мережі – R–CNN. Даний метод показав хороші результати в точності
виявлення об'єктів, але зіткнувся з проблемами в швидкості роботи, так як багато часу витрачається на відбір і класифікацію регіонів. Робота
алгоритму складається з 3 основних кроків:
- з вхідного зображення за допомогою алгоритму вибіркового пошуку витягуються приблизно 2000 регіонів;
- для кожного регіону обчислюються ознаки за допомогою великої згорткової нейронної мережі;
- кожен регіон класифікується за допомогою методу опорних векторів.
У статті 2015 року Fast R–CNN
[3] була представлена модифікована версія методу R–CNN під назвою Fast R–CNN. Модифікація
методу полягає в передачі вхідного зображення на створення згорткової карти ознак. На цій карті ознак ідентифікуються регіони і деформуються в
квадрати, а використовуючи шар пулінга регіону інтересів (RoI [4]), регіони перетворюються в фіксований розмір, щоб їх можна
було передавати в повнозв'язний шар. Fast R–CNN швидше, ніж R–CNN, так як немає необхідності кожного разу подавати 2000 регіонів в згорточну
нейронну мережу. Замість цього операція згортання виконується тільки один раз для всього зображення, і вже з нього генерується карта ознак.
Даний метод, в порівнянні з R–CNN, домігся прискорення в 9 разів під час навчання і прискорення в 213 разів під час тестування.
Остання модифікація R–CNN, що отримала назву Faster R–CNN, була представлена в статті Faster R–CNN: Towards Real–Time Object Detection with
Region Proposal Networks
[5] в 2017 році. Головним нововведенням даного методу є заміна алгоритму вибіркового пошуку на
спеціальну мережу, яка прогнозує пропозиції регіонів (Region Proposal Network, RPN). Це дозволило зробити навчаємим етап виділення регіонів і
прискорити роботу всієї мережі завдяки використанню графічного процесора.
У статті 2016 року You Only Look Once: Unified, Real–Time Object Detection
[6] був представлений метод YOLO (You Only
Look Once). Головною особливістю цієї моделі є швидкість, мережа може обробляти 45 кадрів в секунду (також існує зменшена версія базової моделі,
яка досягає 155 кадрів в секунду), тобто може працювати в реальному часі. У порівнянні з мережами R–CNN дана модель демонструє схожу точність і
перевершує їх у швидкості.
Друга версія моделі YOLO – YOLOv2 була представлена в статті YOLO9000: Better, Faster, Stronger
[7]. Автори статті,
за допомогою різних поліпшень минулої мережі змогли підвищити точність і швидкість роботи даної моделі. YOLOv2 перевершує в точності всі моделі
R–CNN, при цьому все ще працюючи значно швидше. Досягаючи точності в більш, ніж 70%, YOLOv2 може обробляти зображення зі швидкістю 67 кадрів в
секунду.
У статті 2016 року SSD: Single Shot MultiBox Detector
[8] була представлена модель SSD. Основною особливістю даної
моделі, на відміну від моделей з пропозиціями регіонів (або об'єктів), є те, що вона складається з однієї глибокої нейронної мережі, що дозволяє
простіше навчати і використовувати дану мережу. Дана модель поєднує в собі швидкість інших одноступінчатих моделей і може працювати в реальному
часі, і точність, порівнянну з іншими точними моделями.
У 2018 році автори статті Single–Shot Refinement Neural Network for Object Detection
[9] представили модель під назвою
RefineDet. У цій моделі вони спробували об'єднати точність двоступеневих моделей і швидкість одноступінчатих. За тестами на різних наборах даних
модель змогла перевершити точність двоступеневих моделей при цьому зберігши порівнянну з одноступінчатими моделями швидкість.
3.2 Огляд національних джерел
У статті Тимчишина Р.М., Волкова О.Є., Мельникова С.В., Коршунова М.В. [10] був проведений огляд сучасних методів виявлення, розпізнавання та ідентифікації динамічних об'єктів, були розглянуті найкращі архітектури і позначені не вирішені на поточний момент проблеми.
У статті авторів Кравець С.А., Легкий В.Н. і Шумейко В.А. [11] описана концепція згорткових нейронних мереж, які передбачається використовувати в ІК системах літальних апаратів.
У статті Друкі Олексія Олексійовича [12] було запропоновано використовувати згорткову нейронну мережу для виділення і розпізнавання автомобільних номерних знаків. У роботі була розроблена згорткова нейронна мережа для класифікації символів і використаний алгоритм, заснований на побудові гістограм середньої інтенсивності пікселів.
Горєлов Антон Ігорович у своїй статті [13] описав процес навчання і використання моделі YOLO для розпізнавання відходів в міському середовищі, а також інструменти, які необхідні для коректної роботи з моделлю. В іншій статті за авторством Чуйкова Р.Ю. і Юдіна Д.А. [14] розглянуто застосування моделі SSD для виявлення транспортних засобів на зображеннях заміських шосе. Автори навчили і порівняли кілька моделей з різними налаштуваннями ваг.
3.3 Огляд локальних джерел
У роботі магістра Мурадіної Д.Г. Дослідження методів класифікації колекцій цифрових зображень
[15] розглянуто
методи класифікації зображень, їх переваги і недоліки, і застосування для розпізнавання образів. У роботі магістра Борискіна Д.В. Дослідження
можливості паралельної реалізації білатеральної фільтрації для вирішення завдань розпізнавання об'єктів на зображеннях і Depth Image Based
Rendering (DIBR)
[16] був виконаний аналіз існуючих засобів розпізнавання об'єктів на зображеннях і був описаний метод
білатеральної фільтрації. Також були розглянуті можливості прискорення і підвищення якості фільтрації за рахунок паралелізації обчислювальних
процесів.
У роботі Сучасне рішення проблеми розпізнавання осіб на основі нейронних мереж
[17] було описано вирішення проблеми
розпізнавання осіб на основі нейронних мереж. Рішення використовує каскадну нейронну мережу для пошуку облич на фото, згорткову нейронну мережу
для генерації векторного ідентифікатора особи і метод опорних векторів для класифікації людини.
Дослідження програмної моделі сверточное нейронної мережі при розпізнаванні осіб на знімках з відеопотоку[18] досліджується використання згорткової нейронної мережі для розпізнавання осіб на знімках з відеопотоку, аналізується архітектура мережі, виявляються переваги і недоліки.
4. Опис архітектури згорткової нейронної мережі
Згорткова нейронна мережа (англ. Convolutional Neural Network, CNN) – спеціальна архітектура штучних нейронних мереж, запропонована Яном Лекуном в 1988 році [19] і націлена на ефективне розпізнавання образів. Ідея згорткових нейронних мереж полягає в чергуванні згорткових шарів і субдискретизуючих шарів. Структура мережі – односпрямована (без зворотних зв'язків), принципово багатошарова. Для навчання використовуються стандартні методи, найчастіше метод зворотного поширення помилки [20].
Назва згорткова
з'явилася через операцію згортки, яка полягає в поелементному множенні кожного фрагмента зображення на ядро згортки.
Ядро згортки також може називатися матрицею або фільтром. Отримане в результаті операції згортки зображення також називається карта ознак
.
Стандартна згорткова нейронна мережа складається з шарів згортки, пулінга і повнозв'язних шарів. Вхідне зображення, що подається в мережу,
проходить безліч шарів згортки і пулінга. Виходом кожного шару є карта ознак
зменшеного розміру, проте з великою кількістю каналів. Шар
згортки і пулінга є основними шарами згорткової нейронної мережі, так як саме вони виділяють ознаки на зображенні, в кінці мережі зазвичай
ставлять кілька повнозв'язних шарів, які використовують отримані карти ознак для класифікації.
На малюнку 4.1 показана робота згорткової нейронної мережі.
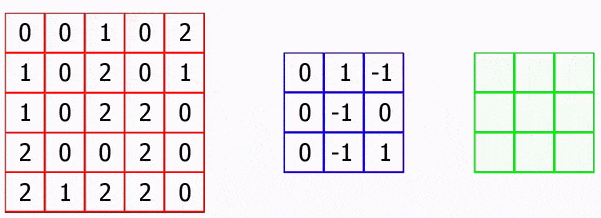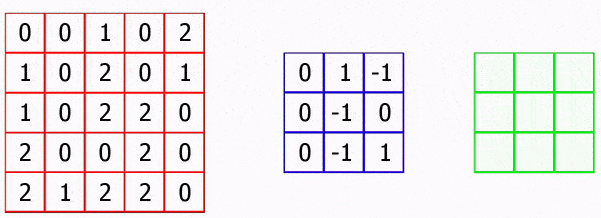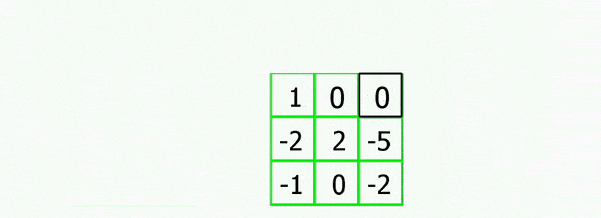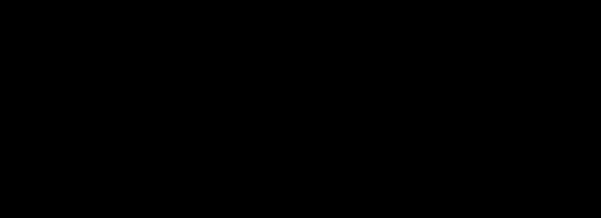
Малюнок 4.1 – Робота згорткової нейронної мережі
(анімація: 43 кадри, 3 циклу повторення, 252 кілобайт)
4.1 Шар згортки
Шар згортки є основним шаром будь–якої згорткової мережі (див. мал. 4.2). Зазвичай саме цих шарів найбільша кількість в порівнянні з іншими. Згортковий шар містить в собі ядро згортки (фільтр) для кожного каналу, отриманого з карти ознак попереднього шару.
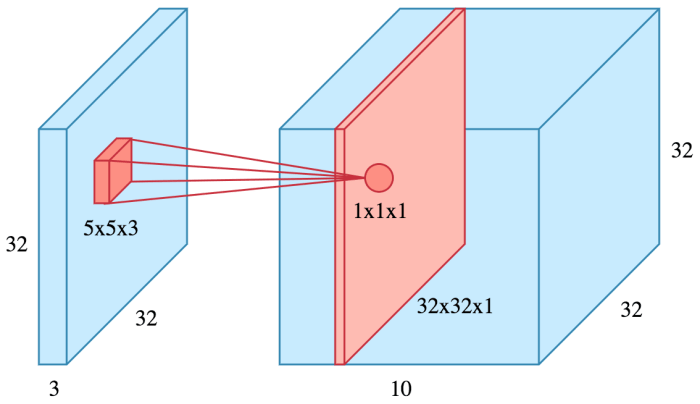
Малюнок 4.2 – Шар згортки
Зазвичай в згортковому шарі використовується матриця ваг (ядро згортки) невеликого розміру, цю матрицю рухають
по всій карті ознак
(або вхідному зображенню – в разі першого шару), результатом чого стає сигнал активації для нейрона наступного шару (формується карта ознак).
Таку матрицю ваг розуміють як кодування ознаки, наприклад, горизонтальної лінії або заокругленості. Так як всі ЗНМ містять безліч шарів, то і
матриць ваг в них багато, кожна з яких кодує елементи зображення. Однак кодування не виконують розробники мережі, вона формується для кожної
матриці самостійно, в результаті навчання мережі.
4.2 Шар пулінгу
Шар пулінгу (також називається шаром субдискретизації або підвибірки) призначений для ущільнення карти ознак (див. мал. 4.3). Ущільнення виконується шляхом пропуску кожної групи пікселів (зазвичай розміром 2х2) через нелінійне перетворення. У якості нелінійного перетворення можуть використовуватися: функція максимуму (з групи пікселів відбирається піксель з найбільшим значенням), мінімуму (відбирається піксель з найменшим значенням) або середнього значення (підсумовуються значення всіх пікселів і діляться на кількість пікселів в групі) і ін. Найчастіше в різних архітектурах ЗНМ зустрічається функція максимуму.
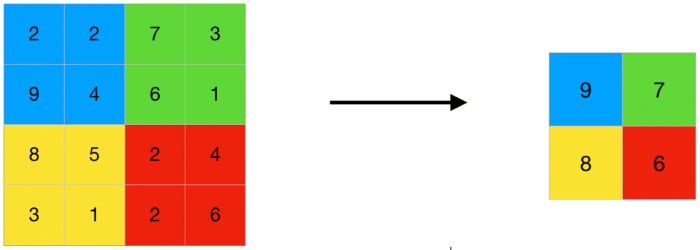
Малюнок 4.3 – Шар пулінгу
У типових архітектурах шар пулінга знаходиться між згортковими шарами. Цей шар дозволяє зменшити розміри зображення і розуміється як процес ущільнення зображення до менш докладного, тобто відкидаються вже виявлені на попередньому шарі згортки ознаки. Також, крім зменшення розміру зображення, пулінг знижує перенавчання мережі.
4.3 Повнозв'язний шар
Після проходження вхідним зображенням кожного шару згортки і пулінга його розмірність зменшується і збільшується кількість каналів. В кінці мережі зображення може складатися з одного пікселя і безлічі каналів (по суті, виходить вектор), що зберігають невелике число даних.
Ці дані передаються в повнозв'язний шар (див. мал. 4.4), таких шарів також може бути кілька. Повнозв'язний шар являє собою звичайну нейронну мережу, в який кожен нейрон пов'язаний з усіма нейронами наступного шару.
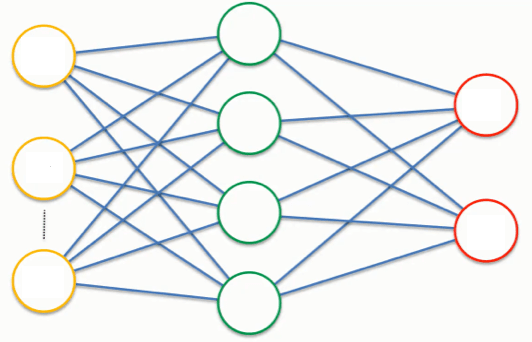
Малюнок 4.4 – Повнозв'язний шар
Результат повнозв'язного шару обчислюється таким же матричним множенням, як і в звичайних нейронних мережах. Виходом останнього повнозв'язного шару є вектор, який представляє точність (або впевненість) мережі по кожному з класів в наборі даних (розмір вектора дорівнює кількості класів).
Висновки
У даній роботі був проведений огляд робіт по темі розробки і застосування інтелектуальних методів виділення і виявлення об'єктів на зображенні. Були розглянуті сучасні методи, що застосовуються для вирішення проблеми виявлення об'єктів: R–CNN (Fast R–CNN, Faster R–CNN), YOLO (YOLOv2), SSD, RefineDet. Одні з перших моделей, такі як R–CNN, змогли досягти хороших результатів в точності виявлення, проте не могли працювати в реальному часі, так як було потрібно обробляти велику кількість інформації, швидкість так само могла знижуватися через, наприклад, використання алгоритму вибіркового пошуку, який так само займав багато часу. Наступні моделі (YOLO, SSD, RefineDet) можуть працювати в реальному часі, при цьому також показують високу точність виявлення. Розглянуто архітектуру згорткової нейронної мережі, шар згортки і пулінгу, що використовуються для виділення і вивчення ознак на зображенні, а також повнозв'язковий шар, необхідний для класифікації об'єктів.
Також в роботі були сформульовані завдання, необхідні для досягнення мети магістерської роботи. Надалі планується вибір і поліпшення однієї з сучасних моделей виявлення об'єктів і програмна реалізація програмного продукту з використанням отриманої моделі.
При написанні даного реферату магістерська робота ще не завершена. Остаточне завершення: травень 2021 року. Повний текст роботи і матеріали по темі можуть бути отримані у автора або його керівника після зазначеної дати.
Перелік посилань
- Обнаружение объектов с 10 строчками кода [Электронный ресурс]. – Режим доступа: https://medium.com/nuances...
- Girshick R. Rich feature hierarchies for accurate object detection and semantic segmentation / R. Girshick, J. Donahue, T. Darrell, J. Malik // 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). – IEEE, 2014. – pp. 580–587.
- Girshick R. Fast R–CNN / R. Girshick // 2015 IEEE International Conference on Computer Vision (ICVV). – IEEE, 2015. – pp. 1440–1448.
- He K. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition / K. He, X. Zhang, S. Ren, J. Sun // IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 37, N 9, 2015. – pp. 1904–1916.
- Ren S. Faster R–CNN: Towards Real–Time Object Detection with Region Proposal Networks / S. Ren, K. He, R. Girshick, J. Sun // IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 39, N 6, 2017. – pp. 1137–1149.
- Redmon J. You Only Look Once: Unified, Real–Time Object Detection / J. Redmon, S. Divvala, R. Girshick, A. Farhadi // 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). – IEEE, 2016. – pp. 779–788.
- Redmon J. YOLO9000: Better, Faster, Stronger / J. Redmon, A. Farhadi // 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). – IEEE, 2017. – pp. 6517–6525.
- Liu W. SSD: Single Shot MultiBox Detector / W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.Y. Fu, A.C. Berg // Computer Vision – ECCV 2016. – Springer, 2016. – pp. 21–37.
- Zhang S. Single–Shot Refinement Neural Network for Object Detection / S. Zhang, L. Wen, X. Bian, Z. Lei, S.Z. Li // 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. – IEEE, 2018. – pp. 4203–4212.
- Тимчишин Р.М. Сучасні системи виявлення, розпізнавання, та ідентифікації динамічних об'єктів, їх переваги і недоліки / Р.М. Тимчишин, О.Є. Волков, С.В, Мельников, М.В. Коршунов // Інформаційні технології в освіті, науці и техніці (ІТОНТ–2018) / Тези доповідей IV Міжнародної науково–практичної конференції. – 2018. – с. 62–63.
- Кравец С.А. Оптоэлектронные системы: вычислительные методы распознавания изображений / С.А. Кравец, В.Н. Легкий, В.А. Шумейко // Интерэкспо Гео–Сибирь / Национальная научная конференция
Наука. Оборона. Безопасность
. – Новосибирск: СГУГиТ, 2017. – с. 177–183. - Друки А.А. Применение сверточных нейронных сетей для выделения и распознавания автомобильных номерных знаков на изображениях со сложным фоном // Известия ТПУ, том 324, №5, 2014. – с. 85–92.
- Горелов А.И. Обучение сети YOLO для распознавания отходов в городской среде // Вестник науки и образования, №9–4 (63), 2019. – с. 23–26.
- Чуйков Р.Ю. Обнаружение транспортных средств на изображениях загородных шоссе на основе метода Single Shot MultiBox Detector / Р.Ю. Чуйков, Д.А. Юдин // Научный результат. Информационные технологии, том 2, №4, 2017. – с. 50–58.
- Мурадина Д.Г. Исследование методов классификации коллекций цифровых изображений [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2014/...
- Борискин Д.В. Исследование возможности параллельной реализации билатеральной фильтрации для решения задач распознования объектов на изображениях и Depth Image Based Rendering(DIBR) [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2019/...
- Чернышов Б.С. Современное решение проблемы распознавания лиц на основе нейронных сетей / Б.С. Чернышов, И.Д. Фоминых, Л.В. Рудак, О.И. Федяев // Программная инженерия: методы и технологии разработки информационно–вычислительных систем (ПИИВС–2018): сборник научных трудов II Международной научно–практической конференции. – Донецк: ДонНТУ, 2018. – с. 180–184.
- Медведев А.С. Исследование программной модели сверточной нейронной сети при распознавании лиц на снимках из видеопотока [Электронный ресурс]. – Режим доступа: http://masters.donntu.ru/2018/...
- Lecun Y. Gradient–Based Learning Applied to Document Recognition / Y. Lecun, L. Bottou, Y. Bengio, P. Haffner // Proceedings of the IEEE, Vol. 86, N 11, 1998. – pp. 2278–2324.
- Свёрточная нейронная сеть [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/...