
Реферат по теме выпускной работы
Внимание! При написании данного реферата магистерская работа еще не завершена. Окончательное завершение: июнь 2022 года. Полный текст работы и материалы по теме могут быть получены у автора или его руководителя после указанной даты.
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, планируемые результаты
- 3. Обзор исследований и разработок
- 3.1 Обзор международных источников
- 3.2 Обзор национальных источников
- 3.3 Обзор локальных источников
- 4. Этапы анализа тональности текста
- 5. Методы классификации текстов
- 5.1 Наивный Байесовский классификатор
- 5.2 Метод деревьев решений
- 5.3 Метод опорных векторов
- 5.4 Методы на основы искусственных нейронных сетей
- Выводы
- Список источников
Введение
Благодаря современным технологиям пользователи получили возможность делиться информацией друг с другом, в том числе выражать свое мнение насчет всего, что его окружает, будь то книга, фильм, высказывание известного деятеля или жалоба на службу доставки. Объемы текста в Сети с каждой секундой становятся все больше и больше, поэтому обработка их человеком вручную физически невозможна. Так сформировалась потребность в таком направлении, как интеллектуальный анализ текста.
Интеллектуальный анализ текста (с англ. Text Mining) – автоматизация извлечения сведений из текстовых данных. Его особенность (в отличие от анализа других данных) заключается в неформализованности исходной информации: ее не описать простой математической функцией [1].
Различным компаниям и корпорациям для проведения успешных действий важно быстро определять реакцию пользователей, и эта потребность является одной из ключевых для анализа тональности.
Анализ тональности (с англ. Sentiment Analysis) – класс методов анализа содержимого, предназначенный для автоматизированного выявления в текстах эмоционально окрашенной лексики и эмоциональной оценки авторов по отношению к объектам, речь о которых идёт в тексте [2]. Основной целью анализа тональности является нахождение мнений в тексте и выявление их свойств. Какие именно свойства будут исследоваться, зависит уже от поставленной задачи: целью анализа может быть автор, то есть лицо, которому принадлежит мнение.
Задача определения тональности текста является задачей классификации текстов в широком смысле. Классификация документов – одна из задач информационного поиска (раздел машинного обучения), заключающаяся в отнесении документа к одной из нескольких категорий на основании содержания документа [3]. В данном случае классами будут разбитые на подмножества мнения, высказанные пользователями.
1. Актуальность темы
В последние годы возникла потребность в инструментах, позволяющих отслеживать реакцию пользователей интернета на события, товары и даже песни. Положительные и отрицательные мнения сильны, ведь с помощью них можно завоевать доверие покупателя или существенно испортить репутацию среди фанатов. Так, известно, что 40% покупателей формируют мнение о бизнесе после прочтения 1-3 обзоров. Еще можно сказать, что люди гораздо чаще выбирают товар среду прочих других, если его рекомендует человек, которому они доверяют. Процесс отслеживания мнений пользователей можно попытаться автоматизировать, собрав отзывы, упорядочив и обработав их соответствующим образом, и применив методики анализа тональности текстов.
Основной целью анализа тональности является нахождение мнений в тексте и выявление их свойств. Исследуемые свойства зависят от поставленной задачи: кому-то важна реакция сообщества на книгу (в целом положительно/негативно), а для кого-то, скажем, косметической компании, потребуется проводить более детальный анализ: например, определить, к какой целевой аудитории принадлежит автор текста и на чем он акцентировал внимание. В качестве основных инструментальных средств для решения данной задачи используется язык программирования Python, а также различные библиотеки для обработки текста.
Данный язык программирования обычно выбирается за его универсальность, а также наличие множества инструментов (т.е. библиотек), призванных облегчить работу.
2. Цель и задачи исследования, планируемые результаты
Объект исследования – определение тональности текста.
Предмет исследования – методы определения тональности текста.
Целью исследования является изучение подходов к анализу тональности текста, а также разработка инструмента для проведения анализа тональности загруженного корпуса текстов и генерации статистики на их основе.
Основные задачи исследования:
- изучение существующих алгоритмов и методов предобработки текста;
- изучение алгоритмов для определения тональности текста;
- создание собственного корпуса текстов новостей из области культуры;
- разработка собственного алгоритма определения тональности текста на примере созданного корпуса новостных текстов;
- разработка программной модели для определения тональности загруженных текстов и составления статистических данных на их основе для демонстрации отношения общества (в лице авторов загруженных статей) к различным новостям.
Планируется, что разработанная программная модель будет иметь интуитивно понятный пользовательский интерфейс, возможность сохранения результатов анализа, а также их экспорта для дальнейшей работы в других программах.
3. Обзор исследований и разработок
Рассмотрим исследования по данной теме.
3.1 Обзор международных источников
В статье Bing Liu “Sentiment Analysis and Subjectivity” рассматриваются взаимосвязи и отличия фактов и мнений. Мнения обычно представляют собой субъективные выражения, которые описывают чувства, оценки или чувства людей по отношению к объектам, событиям и их свойствам.
В статье Bo Pang, Lillian Lee “A Sentimental Education: Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts” изучается анализ тональности направлен на выявление точки зрения (точек), лежащих в основе диапазона текста. Чтобы определить полярность настроений, предлагается новый метод машинного обучения, который применяет методы категоризации текста только к субъективным частям документа.
3.2 Обзор национальных источников
В статье А.Г. Пазельской, А.Н. Соловьева Метод определения эмоций в текстах на русском языке
рассматриваются методы автоматического определения эмоциональной составляющей (тональности) в тексте и описывается опыт осуществляемой в данный момент практической реализации системы для текстов СМИ на русском языке, в основе которой лежат словари лексической тональности и набор комбинаторных правил объединения отдельных слов и словосочетаний.
В работе предложен метод определения тональности, основанный на предикационных отношениях в пропозиции.
В статье В.В. Осокина, М.В. Шегай Анализ тональности русскоязычного текста
в качестве классификатора используется наивный байесовский классификатор. Используются различные методы для отбора признаков,
производится сравнение полученных результатов с результатами классификации англоязычного текста.
3.3 Обзор локальных источников
В работах магистров не было найдено точно такой же постановки задачи (анализ тональности текста в целях характеристики восприятия обществом новостей),
однако подобная тема уже освещалась в магистерских диссертациях. Так, Прокапович А.А. в своей магистерской диссертации на тему Разработка
алгоритмического обеспечения интеллектуального модуля анализа эмоционального содержания естественно языковых сообщений блогов и форумов
ставил перед собой
цель анализировать эмоциональное содержание сообщений с различных блогов и форумов, разработав при этом соответствующее алгоритмическое обеспечение интеллектуального
модуля анализа; в своей работе он рассмотрел уже имеющиеся алгоритмы, научную новизну данного подхода, а также отметил, что алгоритмы, использующие лингвистический
подход, являются более популярными и точными.
Пилипенко А.С. тоже касался этой темы в своей работе по исследованию методов и алгоритмов определения тональности естественно-языкового текста: он привел сравнение популярных средств, определяющих уникальность текста, а также отметил, что данные средства (сервисы Text.ru, Antiplagiat.ru, Advego Plagiatus, Etxt Антиплагиат), хоть и выделяют некоторые характеристики загруженного текста, но не определяют его тональность в том виде, в котором это предполагается в рамках поставленной задачи.
4. Этапы анализа тональности текста
Прежде чем начать работу над определением тональности того или иного документа, его необходимо обработать. Предварительная обработка текста включает в себя приведение всех слов к нижнему регистру, удаление стоп-слов, токенизацию, лемматизацию или стемматизацию [4]. Все эти шаги служат для уменьшения шума, присущего любому обычному тексту, и повышения точности результатов классификатора: после проделанных действий в качестве признаков будут выступать все значимые слова, встречающиеся в документе.
Токенизация и удаление стоп-слов
Токенизация – это процесс разбиения текста на более мелкие части. Следует обратить внимание, что захваченные токены включают знаки препинания и другие строки, не относящиеся к словам [5]. Стоп-слова – это слова, которые могут иметь важное значение в человеческом общении, но не имеют смысла для машин. Фильтрация текста убирает местоимения и служебные слова: артикли, союзы, предлоги и послелоги [3].
Приведение к нормальной форме: стемминг и лемматизация
В процессе нормализации все формы слова приводятся к единому представлению. Есть два основных подхода: стемминг и лемматизация. Стемминг (с англ. stemming) – процесс нахождения основы слова для заданного исходного слова, дополнив которую можно получить слова-потомки. Например, лесной – лес, походный – поход, столовый – стол [6]. Основа слова может не совпадать с морфологическим корнем слова. Такой подход прост, но и в какой-то мере наивен – стемминг просто обрезает строку, отбрасывая окончание. Лемматизация (с англ. lemmatization) – процесс приведения словоформы к лемме, то есть базовому слову, путем отсечения или преобразования флективных окончаний [7]. В русском языке леммами принято считать:
- имена существительные – в именительном падеже единственного числа;
- имена прилагательные – в именительном падеже единственного числа и мужского рода;
- глаголы, причастия и деепричастия – глаголы в исходной форме (в инфинитиве).
Можно привести такие примеры: игрушек – игрушка, позитивные – позитивный, бегали – бегать. Таким образом, стемминг – это общая операция, а лемматизация – интеллектуальная операция, в которой правильная форма будет выглядеть в словаре. Следовательно, лемматизация помогает в формировании лучших возможностей машинного обучения. Следующим шагом является представление каждого токена способом, понятным машине. Этот процесс называется векторизацией.
Векторизация с помощью Word2Vec и bag-of-words
Word2vec – это методика обработки естественного языка, опубликованная в 2013 году. Word2vec берет на вход большой корпус текстов и создает векторное пространство, обычно состоящее из нескольких сотен измерений, причем каждому уникальному слову в корпусе присваивается соответствующий вектор в этом пространстве. Векторы слов располагаются в векторном пространстве таким образом, что слова, имеющие общие контексты в корпусе, располагаются близко друг к другу в пространстве [8].
Другим рабочим походом является мешок слов (с англ. bag-of-words): для документа формируется вектор размерности словаря, для каждого слова выделяется своя размерность, для документа записывается признак (насколько часто слово встречается в нем), получаем вектор. Наиболее распространенным методом для вычисления признака является TF-IDF [9] и его вариации (TF – частота слова (с англ. term frequency), IDF – обратная частота документа (с англ. inverse document frequency)). Плюсом мешка слов является простая реализация, но стоит помнить, что данный метод теряет часть информации, (например, порядок слов).
5. Методы классификации текстов
Существует несколько групп методов классификации текста. Анализ при помощи методов, основанных на правилах и словарях, заключается в работе с заранее составленными тональными словарями. Процесс составления этих словарей весьма трудоемкий и проблемный, так как одно слово в разных контекстах может обладать различной тональностью (например, слово «сложный» по отношению к системе защиты является положительной характеристикой, но отрицательной – к процедуре регистрации или авторизации пользователя). Для корректного использования в таком случае нужно составить большое количество правил. Существует ряд подходов, позволяющих автоматизировать составление словарей для конкретной предметной области. В методах, основанных на теоретико-графовых моделях, текст изображается в виде графа на основании предположения, что некоторые слова имеют больший вес, а значит, сильнее влияют на тональность текста. Здесь анализ текста начинается с построения графа и ранжирования его вершин. После ранжирования слова классифицируются в соответствии со словарем, где у каждого проанализированного слова появляется характеристика («отрицательный», «нейтральный», «положительный»). Результат определяется как соотношение количества слов с положительной оценкой к количеству слов с отрицательной оценкой: если полученная оценка близка к 1, то текст нейтральный, больше – положительный, меньше – отрицательный. Ключевым моментом в методах на основе машинного обучения с учителем является машинный классификатор, алгоритм работы с которым выглядит следующим образом:
- сбор информации (документов), на основе которой будет происходить обучение;
- разложение каждого документа в виде вектора признаков, по которым будет происходить анализ;
- указание правильного типа тональности для каждого документа;
- выбор алгоритма классификации и метода для обучения классификатора;
- использование полученной модели для определения тональности нового набора информации.
В основе машинного обучения без учителя лежит идея, что термины, которые чаще встречаются в этом тексте и в то же время присутствуют в небольшом количестве текстов всего набора текстов (коллекции), имеют наибольший вес. Вывод о тональности текста основывается на выделении таких терминов и определении их тональности.
5.1 Наивный Байесовский классификатор
Один из методов машинного обучения с учителем – наивный Байесовский классификатор (с англ. Naive Bayes Classifier) [10], который является частным вариантом байесовского классификатора и основан на применении теоремы Байеса с существенным допущением, что изменение одной величины не влияет на изменение другой величины.
Для данной модели теорема Байеса выглядит так:
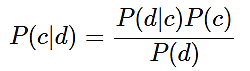 (1)
(1)
где P(c|d) – вероятность, что документ d принадлежит классу c;
P(d|c) – вероятность встретить документ d среди всех документов класса c;
P(c) – безусловная вероятность встретить документ класса c в корпусе документов;
P(d) – безусловная вероятность документа d в корпусе документов.
Знаменатель P(d) в формуле (1) может быть опущен, так как вероятность для одного и того же документа d будет одинаковой.
Для определения наиболее вероятного класса используется оценка апостериорного максимума:
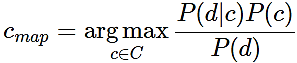 (2)
(2)
Поскольку документ d в модели – это вектор d = {w1, w2, …, wn}, где wi – вес i-ого термина, а n – размер словаря выборки, то условную вероятность P(d|c) можно выразить как P (w1…wn | c) или же P (w1 | c) * (w2 | c) *...* ( wn | c) = Пi P(wi | cj).
Таким образом, для нахождения наиболее вероятного класса c нужно посчитать условные вероятности для каждого возможного класса и выбрать тот, у которого наибольшая вероятность:
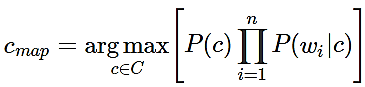 (3)
(3)
Преимущества данного метода:
- высокая скорость работы;
- относительно простая программная реализация алгоритма;
- легкая интерпретируемость результатов работы алгоритма.
Недостатки метода:
- относительно низкое качество классификации;
- неспособность учитывать зависимость результата классификации от сочетания признаков [11].
5.2 Метод деревьев решений
Деревом решений называют ациклический граф, по которому производится классификация объектов (в нашем случае документов), описанных набором признаков. Каждый узел дерева содержит условие ветвления по одному из признаков. У каждого узла столько ветвлений, сколько значений имеет выбранный признак. В процессе классификации осуществляются последовательные переходы от одного узла к другому в соответствии со значениями признаков объекта. Классификация считается завершенной, когда достигнут один из листьев (конечных узлов) дерева. Значение этого листа определит класс, которому принадлежит рассматриваемый объект. На практике обычно используют бинарные деревья решений, в которых принятие решения перехода по ребрам осуществляется простой проверкой наличия признака в документе. Если значение признака меньше определенного значения, выбирается одна ветвь, если больше или равно, другая. Пример дерева решений представлен на рисунке 2 [12].

Рисунок 1 – Пример дерева решений (анимация: 10 кадров, 10 циклов повторения, 66,1 килобайт)
Алгоритм построения дерева решений состоит из следующих шагов:
- создается первый узел дерева, в который входят все документы, представленные всеми имеющимися признаками; размер вектора признаков для каждого документа равен n, так как d = (t1, …, tn);
- для текущего узла дерева выбираются наиболее подходящий признак tk и его наилучшее пограничное значение vk;
- на основе пограничного значения выбранного признака производится разделение обучающей выборки на две части, выбранный признак не включается в описание фрагментов в этих частях;
- образовавшиеся подмножества обрабатываются аналогично до тех пор, пока в каждом из них не останутся документы только одного класса или признаки для различения документов.
Преимущества деревьев решений:
- относительно простая программная реализация алгоритма;
- легкая интерпретируемость результатов работы алгоритма.
Недостатки:
- неустойчивость алгоритма по отношению к выбросам в исходных данных;
- большой объем данных для получения точных результатов.
5.3 Метод опорных векторов
Метод принадлежит к семейству линейных классификаторов. В данном походе каждый объект представляется как вектор (точка) в p-мерном пространстве. Каждая из точек принадлежит одному из двух классов. Задача метода – преобразовать пространство при помощи оператора ядра так, чтобы нашлись такие гиперплоскости, которые разделяют примеры из разных классов обучающей выборки. Если такая гиперплоскость существует, она называется оптимальной разделяющей гиперплоскостью, а соответствующий ей линейный классификатор называется оптимально разделяющим классификатором [13]. На практике структура данных бывает неизвестна и очень редко удается построить разделяющую гиперплоскость, а значит, невозможно гарантировать линейную разделимость выборки. Могут существовать такие документы, которые алгоритм отнесет к одному классу, а в действительности они должны относиться к противоположному. Такие данные называются выбросами. Они создают погрешность метода, поэтому было бы лучше их игнорировать [4]. На рисунке 3 показана графическая интерпретация метода.
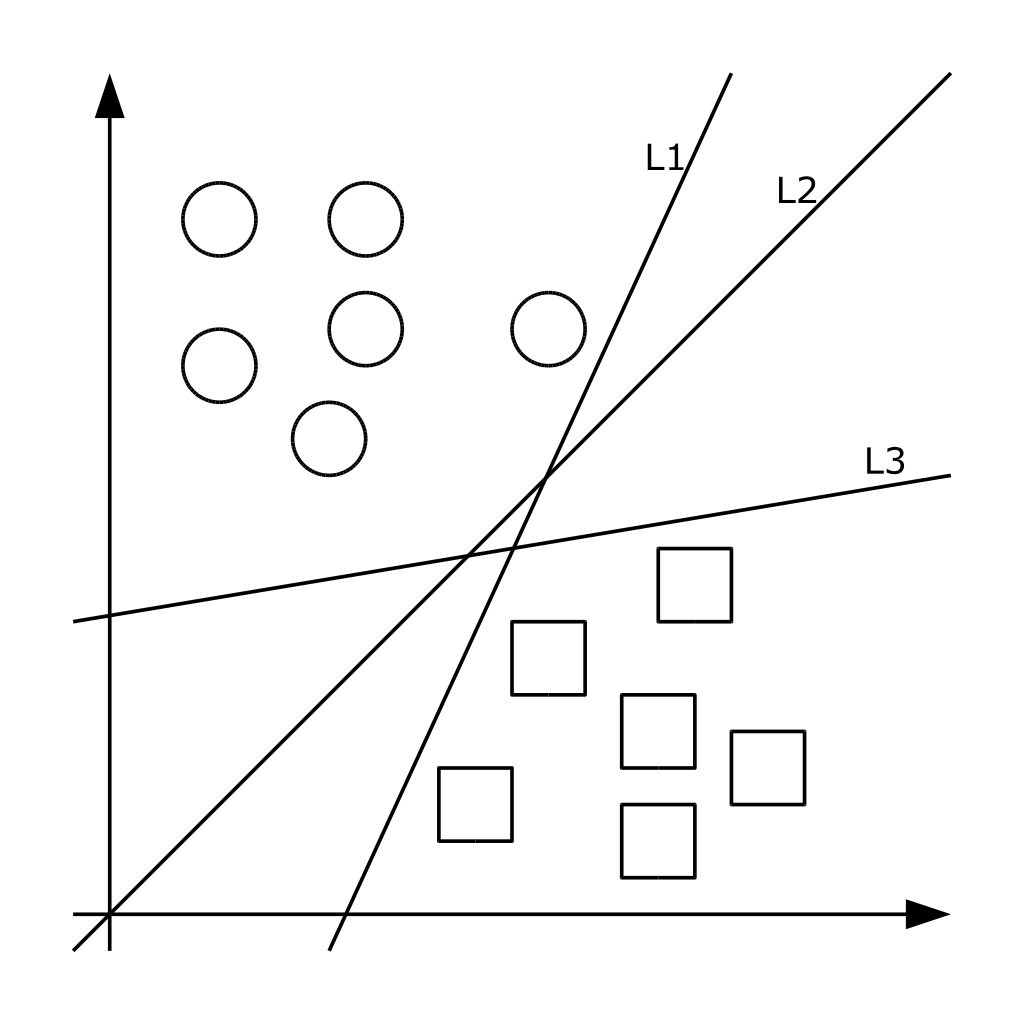
Рисунок 2 – Графическая интерпретация метода опорных векторов
Преимущества метода:
- один из наиболее качественных методов;
- возможность работы с небольшим набором данных для обучения;
- сводимость к задаче выпуклой оптимизации, имеющей единственное решение.
Недостатки метода:
- сложная интерпретируемость параметров алгоритма;
- неустойчивость по отношению к выбросам в исходных данных [4].
5.4 Методы на основы искусственных нейронных сетей
Методов, основанных на нейронных сетях, довольно большое количество. Основными из них являются сети прямого распространения, рекуррентные сети, радиально базисные функции и самоорганизующиеся карты. Настройка весов в методах может быть фиксированной или динамической.
В классических нейронных сетях прямого распространения (Feed Forward Back Propagation, FFBP) присутствуют входной слой, выходной слой и промежуточные слои: сигнал идет последовательно от входного слоя нейронов по промежуточным слоям к выходному. Примером такой структуры является многослойный перцептрон.
Для классификации документа при помощи нейронной сети прямого распространения веса признаков документа подаются на соответствующие входы сети. Активация распространяется по сети; значения, получившиеся на выходах, и есть результат классификации. Стандартный метод обучения такой сети – метод обратного распространения ошибки. Суть его в следующем: если на одном из выходов для одного из обучающих документов получен неправильный ответ, то ошибка распространяется обратно по сети и веса ребер меняются так, чтобы уменьшить ошибку.
Количество промежуточных слоев нейронной сети может быть не задано заранее, такую архитектуру называют динамической. В этом случае слои последовательно динамически генерируются до тех пор, пока не будет достигнут нужный уровень точности.
Сверточная нейронная сеть – однонаправленная многослойная сеть с применением операции свертки, при которой каждый фрагмент входных данных умножается на матрицу (ядро) свертки поэлементно, а результат суммируется и записывается в аналогичную позицию выходных данных. Рекуррентная нейронная сеть получается из многослойного перцептрона введением обратных связей. Одна из широко распространенных разновидностей рекуррентных нейронных сетей – сеть Элмана. В ней обратные связи идут не от выхода сети, а от выходов внутренних нейронов. Это позволяет учесть предысторию наблюдаемых процессов и накопить информацию для выработки правильной стратегии обучения. Главной особенностью рекуррентных нейронных сетей является запоминание последовательностей.
Преимущества метода:
- имеет очень высокое качество алгоритма при удачном подборе параметров;
- является универсальным аппроксиматором непрерывных функций;
- поддерживает инкрементное обучение.
Недостатки метода:
- вероятность возможной расходимости или медленной сходимости, поскольку для настройки сети используются градиентные методы;
- необходимость очень большого объема данных для обучения, чтобы достичь высокой точности;
- низкая скорость обучения;
- сложная интерпретируемость параметров алгоритма [4].
Сверточные нейронные сети
Сверточная нейронная сеть (англ. convolutional neural network, CNN) – специальная архитектура искусственных нейронных сетей, предложенная Яном Лекуном в 1988 году и нацеленная на эффективное распознавание образов, входит в состав технологий глубокого обучения (deep-learning) [14].
Сверточные нейронные сети обеспечивают частичную устойчивость к изменениям масштаба, смещениям, поворотам, смене ракурса и прочим искажениям. Сверточная нейронная сеть и ее модификации считаются лучшими по точности и скорости алгоритмами нахождения объектов на сцене. Именно поэтому их использование наиболее распространено в задачах, связанных с распознаванием изображений.
Преимущества:
- гораздо меньшее количество настраиваемых весов, так как одно ядро весов используется целиком для всего объекта, вместо того, чтобы делать для каждой ее составляющей свои персональные весовые коэффициенты. Это подталкивает нейросеть при обучении к обобщению демонстрируемой информации;
- удобное распараллеливание вычислений, а, следовательно, возможность реализации алгоритмов работы и обучения сети на графических процессорах;
- обучение при помощи классического метода обратного распространения ошибки.
Недостатки метода:
- слишком много варьируемых параметров сети; непонятно, для какой задачи и вычислительной мощности какие нужны настройки.
Входными данными сверточной нейронной сети является матрица с фиксированной высотой n, где каждая строка представляет собой векторное отображение слова в признаковое пространство размерности k [14].
Выводы
Предпочтительными для дальнейшего исследования можно назвать метод опорных векторов (за качественные результаты анализа и возможность обучения небольшого массива данных), наивный байесовский классификатор (за высокую скорость работы и простую интерпретируемость результатов) и методы, связанные с нейронными сетями.
Список источников
- Интеллектуальный анализ текста, или Text Mining [Электронный ресурс]. – Режим доступа: интеллектуальный-анализ-текста-что-это-и-зачем-он-нужен.aspx . – Заглавие с экрана.
- Анализ тональности текста [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Анализ_тональности_текста. – Заглавие с экрана.
- Классификация документов методом опорных векторов [Электронный ресурс]. – Режим доступа: – Режим доступа: https://habr.com/ru/post/130278/. – Заглавие с экрана.
- Батура Т.В. Методы автоматической классификации текстов / Т.В. Батура // Программные продукты и системы. 2017. Т. 30. № 1. С. 85–99; DOI: 10.15827/0236-235X.030.1.085-099.
- Анализ данных и процессов: учеб. пособие / А. А. Барсегян, М. С. Куприянов, И. И. Холод, М. Д. Тесс, С. И. Елизаров. – 3-е изд., перераб. и доп. – СПб.: БХВ-Петербург, 2009. – 512 с.
- Что такое стемминг [Электронный ресурс]. – Режим доступа: https://habr.com/ru/post/130278/ https://textis.ru/stemming/. – Заглавие с экрана.
- Лемматизация [Электронный ресурс]. – Режим доступа: https://cropas.by/seo-slovar/lemmatizatsiya/. – Заглавие с экрана.
- Word2Vec [Электронный ресурс]. – Режим доступа: https://en.wikipedia.org/wiki/Word2vec. – Заглавие с экрана.
- TF-IDF [Электронный ресурс]. – Режим доступа: https://seonomad.net/slovar/tf-idf. – Заглавие с экрана.
- Наивный байесовский классификатор [Электронный ресурс]. – Режим доступа: http://bazhenov.me/blog/2012/06/11/naive-bayes.html. – Заглавие с экрана.
- Классификация текстов и анализ тональности [Электронный ресурс]. – Режим доступа: http://neerc.ifmo.ru/wiki/index.php?title=Классификация_текстов_и_анализ_тональности – Заглавие с экрана.
- Decision Trees – scikit-learn [Электронный ресурс]. – Режим доступа: – Режим доступа: https://scikit-learn.org/stable/modules/tree.html. – Заглавие с экрана.
- Метод опорных векторов [Электронный ресурс]. – Режим доступа: – Режим доступа: https://ru.wikipedia.org/wiki/Метод_опорных_векторов. – Заглавие с экрана.
- Сверточные нейронные сети [Электронный ресурс]. – Режим доступа: https://ru.wikipedia.org/wiki/Свёрточная_нейронная_сеть. – Заглавие с экрана.