
Реферат з теми випускної роботи
Зміст
- Вступ
- 1. Актуальність теми
- 2. Мета і задачі дослідження та заплановані результати
- 3. Огляд досліджень та розробок
- 3.1 Огляд основних принципів побудови комп'ютерної морфології
- 3.2 Графематичний аналіз
- 3.3 Морфологічний аналіз із використанням словника
- 4. Морфологічний аналізатор
- 4.1 Загальні вимоги до морфологічного аналізатора
- 4.2 Морфологічний аналіз слова
- 4.3 Базові словники
- Висновки
- Перелік посилань
Вступ
У більшості природних мов спостерігається таке явище, як морфологічна змінність слів. Дане явище дуже виражене в російській та українській мовах, які належать до групи флективних мов зі складною системою флексій.
Інформаційно-пошукова система або будь-яка інша система, що працює з російською або іншою флективною мовою, повинна враховувати цю особливість мови, що реалізується зазвичай за допомогою спеціального модуля системи, що називається модулем морфологічного аналізу.
Мета роботи є дослідження та розробка алгоритмів побудови морфологічного аналізатора на основі словника з формальним описом мови. Основною вирішуваною проблемою при цьому є розробка методів побудови структури морфологічного словника та способів програмування, що дозволяють вирішити поставлене завдання.
1. Актуальність теми
Актуальність проблеми морфологічного аналізу та синтезу словоформ визначається тим, що блок морфологічного аналізу є необхідною частиною більшості працюючих з природно-мовними текстами програм різного рівня та призначення.
На сьогоднішній день розробка алгоритмів побудови морфологічного аналізатора на основі словника - це одне з актуальних завдань у комп'ютерній лінгвістиці. За допомогою вже розроблених алгоритмів буде простіше в майбутньому розробляти складніші алгоритми, які вже включатимуть більший функціонал у цій темі.
2. Мета та завдання дослідження, плановані результати
Мета роботи є дослідження та розробка алгоритмів побудови морфологічного аналізатора на основі словника з формальним описом мови для веб-платформи. Основною вирішуваною проблемою при цьому є розробка методів побудови структури морфологічного словника та способів програмування, що дозволяють вирішити поставлене завдання.
Основні завдання дослідження:
- Провести дослідження алгоритмів формування структури морфологічного словника за умов обмежень, накладених засобами розробки веб-платформ.
- Спроектувати модель бази даних.
- Розробити алгоритми побудови морфологічного аналізатора з урахуванням словника.
- Розробка методу розпізнавання відсутніх у словнику слів.
Предмет дослідження – методи створення сайтів, системи автоматизації продажу (CRM, BI), алгоритми процесу ухвалення управлінських рішень.
Об'єкт дослідження – результат виконання алгоритмів побудови морфологічного аналізатора на основі словника та їх подальша оптимізація.
3. Огляд досліджень та розробок
Морфологічним аналізом називається встановлення по словоформі вихідного слова – лексеми, і навіть морфологічних показників даної словоформи, як-от рід, відмінок, число тощо. Розроблений морфологічний аналізатор повинен буде виконувати морфологічний аналіз, і виявляти іменники-поняття даного тексту
3.1 Огляд основних принципів побудови комп'ютерної морфології
Серед методів морфологічного аналізу, що використовуються в лінгвістичних процесорах, можна виділити методи з декларативною та процедурною орієнтацією. Для методів декларативної орієнтації характерна наявність повного словника всіх можливих словоформ для кожного слова. При цьому кожна словоформа забезпечується повною та однозначною морфологічною інформацією, куди входять як постійні, так і змінні морфологічні параметри. Завдання морфологічного аналізу у разі зводиться до пошуку необхідної словоформи у словнику та копіюванню морфологічної інформації, відповідної знайденої словоформі, в програму[11].
У процедурних методах використовують імовірнісно-статистичні методи та лексикони суфіксів або квазі-суфіксів, основ або квазі-основ, побудованих емпірично. Кожне слово поділяється на основу та афікс, і словник містить лише основи слів разом із посиланнями на відповідні рядки у таблиці можливих афіксів. Основний критерій під час розбиття слова на основу та афікс – основа повинна залишатися незмінною у всіх можливих словоформах цього слова. Оскільки велика кількість слів російської має одні й самі афікси, то сумарний обсяг словника основ і словника афіксів виявляється значно менше, ніж обсяг повного словника всіх словоформ, що у декларативних методах. Однак процедура морфологічного аналізу ускладнюється: тепер із словника основ необхідно по черзі вибирати всі основи, що збігаються з початковими літерами аналізованого слова, і для кожної такої основи перебирати всі можливі для неї афікси. У разі точного збігу чергового варіанту «основа+афікс» з аналізованим словом варіант аналізу вважається успішним, і програму передається морфологічна інформація, відповідна цій основі і даному афіксу. У цьому, зазвичай, постійні морфологічні параметри визначаються основою слова, а змінні – афіксом.
Можливо використовувати комбінований варіант морфологічного аналізу. У цьому використовується як словник словоформ, і словник основ. На першому етапі проводиться пошук за словником словоформ, і у разі успішного пошуку аналіз на цьому завершується. В іншому випадку використовується словник основ і процедурний метод аналізу.
3.2 Графематичний аналіз
Перед тим, як приступати до морфологічного аналізу окремих слів, необхідно провести графематичний аналіз вхідного тексту.
Основна мета графематичного модуля отримати вибірку повних словоформ із масиву текстів БД[5]. Графематичний аналіз працює із зовнішнім представленням тексту та використовує таблицю стоп-слів. У цій таблиці зберігаються цифри, спецсимволи і частотні слова мови, нерелевантні пошуку текстів і які потребують морфологічному аналізі.
Графематичний аналіз виконує три функції:
Одиницею графематичного аналізу є ланцюжок символів, виділений із двох сторін пробілами. Виділений ланцюжок символів піддається послідовній обробці евристичними правилами: відсікти знаки пунктуації, перевірити присутність голосних усередині ланцюжка, чергування верхнього та нижнього регістрів тощо. Залежно від результатів обробки отриманий ланцюжок символів спрямовується в один із трьох потоків даних:
Перші два потоки даних не потребують морфологічного аналізу. Повні словоформи надходять на вхід морфологічного аналізу, мета якого розбити всю множину словоформ на підмножини за ознакою приналежності до тієї чи іншої лексеми (множина словоформ, що відрізняються один від одного тільки словозмінними значеннями), привести всі елементи кожної такої підмножини до унікальної основи, однозначно визначити граматичні Показники лексеми і проіндексувати тексти по основах, що зустрілися в них.
3.3 Морфологічний аналіз із використанням словника
Моделі, які використовують словник, здатні дати повніший аналіз словоформи (тобто оперувати великою кількістю граматичних ознак). Ступінь точності такого аналізу вищий, порівняно з моделями, що не використовують словника. Але на просторі реальних текстів системи, що використовують словник, часто дають збої. Це пов'язано з тим, що немає повних словників. Лексика мови постійно поповнюється – з'являються нові слова. Для кожної предметної області існує своя термінологія, своє підмножина лексики мови, і включити до загального словника всю існуючу термінологію – неможливо. Так само неможливо і перерахувати всі існуючі імена та прізвища, які мають регулярне відмінювання.
Даний метод копіює академічну лінгвістичну модель опису, де виділяються основні парадигматичні класи, що відповідають типу відмінювання та відмінювання, і правила регулярних альтернатив (фонетичних чергувань), а нерегулярні форми, наприклад, сильні дієслова в німецькій та англійській мовах, задаються перерахуванням. Такого типу лексикони для російської мови складаються на базі моделі граматичного словника, наприклад А. Залізняка, А. Лебедєва та ін., розробляючи 8 класів іменного відмінювання та 16 дієслівної дієвідміни, а чергування в основі та дієслівної теми виносяться в окрему множину пост-морфологічних правил альтернатив.
Процеси індексації такі самі, як і методі побудови морфології без словника. Спочатку текст проходить графематичний аналіз – текст розбивається на слова, потім слова подаються на вхід морфологічного аналізатора.
Вхідним параметром є текстове уявлення вихідного слова. Метою та результатом морфологічного аналізу є визначення морфологічних характеристик слова та його основної словоформи. Список всіх морфологічних показників слів і допустимих значень кожної їх залежить від природного мови. Тим не менш, ряд характеристик (наприклад, назва мови) присутні в багатьох мовах. Результати морфологічного аналізу слова неоднозначні, що можна простежити на багатьох прикладах.
Словник А. Залізняка містить основні словоформи слів російської, кожної з яких зазначений певний код[2]. Відома система правил, за допомогою якої можна побудувати всі форми даного слова, відштовхуючись від початкової словоформи та відповідного коду. Крім побудови кожної словоформи, система правил автоматично ставить у відповідність до неї морфологічні характеристики. При проведенні чіткого морфологічного аналізу необхідно мати словник усіх слів та всіх словоформ мови. Цей словник на вході набуває форми слова, але в виході видає його морфологічні характеристики. Даний словник можна побудувати на основі словника А. Залізняка або аналогічного за очевидним алгоритмом: перебрати всі слова зі словника, для кожного з них визначити всі лексеми і занести їх у словник, що формується.
За такого підходу щодо морфологічного аналізу заданого слова необхідно легко знайти їх у словнику, де вже зберігаються точні, остаточно відомі значення всіх його морфологічних характеристик. Для того самого вхідного слова можуть зустрітися відразу кілька варіантів значень його морфологічних характеристик.
На жаль, цей спосіб застосовується не завжди: слова, що надходять на вхід, можуть не входити до словника всіх словоформ. Така ситуація може виникнути через помилки введення вихідного тексту, через наявність у тексті власних назв і т.д. Якщо метод не дає потрібного результату, застосовується нечітка морфологія.
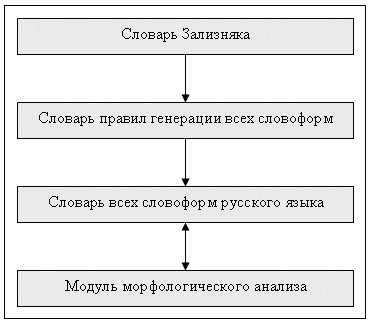
Малюнок 1 – Морфологічний аналіз на основі словника О. Залізняка
Метою морфемного аналізу слова є поділ слова на приставки, коріння, суфікси та закінчення.
У словнику морфем російської вказано поділ кожного слова деякі частини, але з зазначені типи кожної їх – яка їх є приставкою, яка коренем тощо.
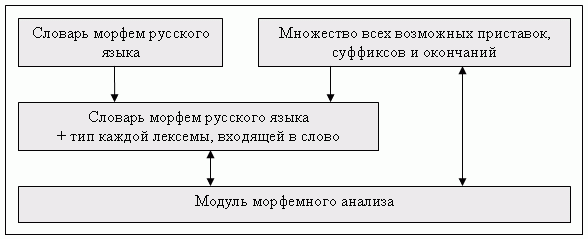
Малюнок 2 – Морфемний аналіз
Безліч всіх коренів слів російської відкрито, але безліч всіх можливих приставок, суфіксів і закінчень обмежена; крім того, відомо, що у будь-якому слові спочатку йдуть приставки, потім коріння, далі суфікси та закінчення. Тому на основі словника морфем російської можна побудувати інший словник, який міститиме не тільки розбиття кожного слова на частини, а й тип кожної з них. У такому разі для проведення морфемного аналізу слова необхідно звернутися до цього словника.
Морфемний аналіз не обмежується зверненнями до словника. У ситуації, коли слово відсутнє у словнику, можливе безпосереднє проведення аналізу на основі стандартної будови слів російської мови (приставка – корінь – суфікс – закінчення) та безлічі всіх приставок, суфіксів та закінчень.
Повернемося до морфологічного аналізу слова у ситуації, коли вдалося визначити характеристики слова з допомогою методів чіткої морфології, але вдалося розчленувати їх у частини. Наявність тих чи інших лексем може визначати морфологічні характеристики слова: можна побудувати систему правил, яка спиратиметься на наявність чи відсутність будь-яких частин і видавати одне чи кілька припущень про морфологічні параметри. Такий набір правил можна побудувати двома способами. Перший грунтується на морфемному аналізі слів, які у словнику всіх словоформ, та його морфологічних характеристик. Розглянемо це завдання формальніше: відомі пари значень, що складаються з морфемної будови слова та його морфологічних характеристик. Це не що інше, як «вхід» і «вихід» системи правил, яка за морфемною будовою слова визначатиме його морфологічні характеристики. Завдання побудови такої системи правил можна вирішити за допомогою системи, що самонавчається. Для її реалізації можуть бути використані дерева рішень, програмування з урахуванням індуктивної логіки (ILP, Inductive Logic Programming) чи інші алгоритми.
4. Морфологічний аналізатор
4.1 Загальні вимоги до морфологічного аналізатора
Основне завдання морфологічного аналізатора полягає у визначенні морфологічних ознак слів тексту та канонічних форм (КФ) слів. Як КФ може виступати або основа (або навіть корінь), або традиційна нормальна форма слова (НФ) - якась початкова форма слова, наприклад, для дієслова - інфінітив, для іменника - однина в називному відмінку.
Для завдання приведення необхідно створення словника, за допомогою якого можна отримати канонічну форму слова та інформацію про морфологічні ознаки слова, його відмінювання. Слід виділити основні компоненти, від яких залежить ефективність використання морфологічного аналізатора.
1. Організація структури словника. Словник має бути простий у реалізації, не повинен містити складних та багатооб'ємних елементів. Необхідно врахувати мінімальне використання додаткових ресурсів та витрачений час доступу до елементів словника.
2. Алгоритм визначення канонічної форми та відмінювання. Елементи словника повинні містити необхідну інформацію для приведення та максимально повну для визначення лексем, що виключає використання додаткових методів перед- та постобробки.
3. Алгоритми визначення морфологічних характеристик слів, які у словнику. Природні мови постійно поповнюються новими словами, тому дуже важливо своєчасно оновлювати словник.
4.2 Морфологічний аналіз слова
Морфологічний аналіз можна розділити на «прямий» та «зворотний». Обидва методи широко застосовуються в пошукових машинах.
Прямий метод полягає у знаходженні із нормальної форми слова всіх його словоформ. Ця операція застосовується під час вибірки документів. Так як відбираються документи, які містять всі форми слова, то в результат пошуку потрапляють не тільки документи зі словом у формі, що збігається з запитом, але й інші документи, що містять різні форми даного слова.
Алгоритм побудови всіх словоформ та визначення його морфологічних характеристик насамперед залежить від структури морфологічного словника, що використовується аналізатором.
Зворотний метод полягає у знаходженні нормальної форми із довільної. Ця операція застосовується під час індексування тексту. Таким чином, досягається зменшення розміру індексу та часу пошуку документів, що задовольняють умові.
Алгоритм перебування нормальної форми по довільної також залежить від структури словника.
4.3 Базові словники
Для побудови морфологічного словника можна скористатися будь-яким граматичних словників, в якому описана формальна модель мови. Для російської можна скористатися такими словниками:
4.3.1 Словник російської А. Лебедєва
У орфографічному словнику А. Лебедєва є два файла: самого словника і афікс-правил. Обсяг словника – 137.2 тисячі слів та понад 1.354 мільйони словоформ. Цей словник розроблявся спеціально для програми перевірки орфографії Ispell. На його основі можна побудувати морфологічний словник для аналізатора.
Перший файл – словник, список слів у НФ, розділених символом "/" від груп ідентифікаторів правил словотворів.
Словоформи для слова «одягнуться» будуються за правилами для групи правил С. Варто особливо звернути увагу на те, що груп може бути кілька (долучитися/BLWR). Це означає, що це правила із зазначених груп (B, L, W, R) застосовні до цього слова. У цілому нині досить гнучкий принцип, в такий спосіб, зменшується надмірність, ряд правил виносяться до окремих груп і застосовується до основний групі.
Файл з афікс-правилами (*.aff) складається з прапорів та правил словотвору.
Це можна прочитати так: у слові «играть» замінюємо закінчення «-ть» на «ю» тільки в тому випадку, якщо слово «играть» задовольняє масці «[АЕ]ть», де маскою є звичайний PERL-сумісний регулярний вираз. Дізнатися, які групи правил можна застосовувати до цього слова, а які не допомагають прапори, вказані біля слова у словнику.
Морфологія, заснована на даному словнику, дуже поступається комерційним розробкам, оскільки словник спочатку призначався для перевірки орфографії. Слова «приодень», «приоденьте» і «приоденьтесь» є абсолютно різними словами, хоча насправді можуть мати одну основу. Також у словнику не можна знайти «нові» слова, які прийшли до нас з інших мов, наприклад, «менчердайзер».
Деякі недоліки можна вирішити, використовуючи словник А. Залізняка, на основі якого були побудовані майже всі сучасні системи, що працюють із морфологією російської мови.
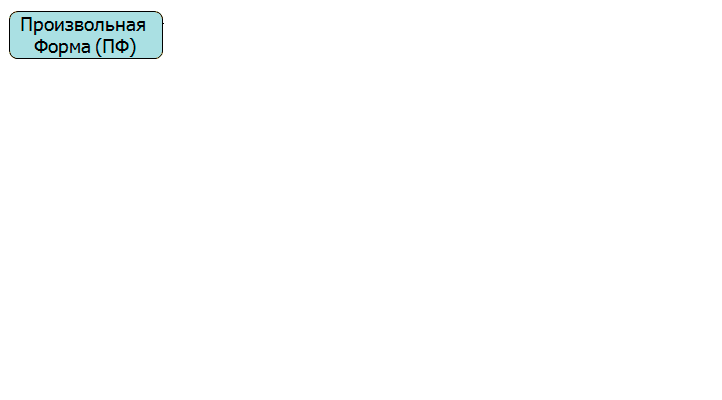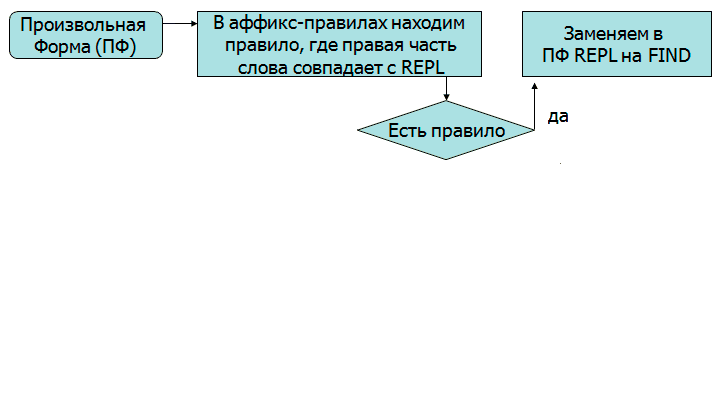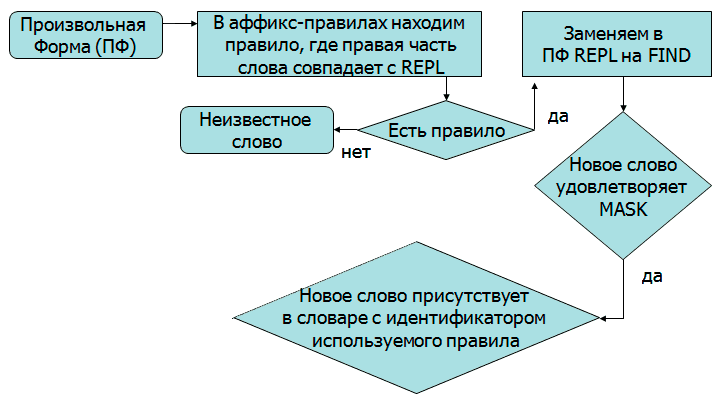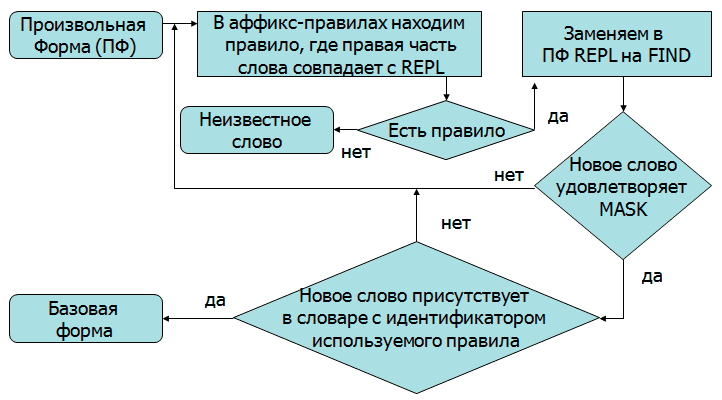
Малюнок 3 - Алгоритм приведення слова до базової форми(Малюнок анімований, кількість повторів 7, тривалість одного становить 9 с, 9 кадрів, 103 КБ.)
4.3.2 Словник російської А. Залізняка
Граматичний словник А. Залізняка на даний момент містить 161 000 слів[2]. Це основна праця з морфології, де вперше було запропоновано системний підхід до опису граматичних парадигм, що включають не лише зміну літерного складу слів, а й наголоси.
Словник уперше було видано 1977 р., відтоді неодноразово перевидавалася. Електронна версія цього словника лягла в основу більшості сучасних комп'ютерних програм, що працюють з російською морфологією (системи перевірки орфографії, автоматичного перекладу, реферування тощо).
Кожне слово представлено у словнику своєю вихідною, або словниковою, формою (яка утворює так зване заголовне слово статті). Для схиляються частин промови це називний відмінок (якщо слово змінюється за числами – од. числа; якщо воно змінюється за родами чоловічого роду), для дієслів – інфінітив, для незмінних частин промови – єдина існуюча форма.
Всі слова (як у вихідній, так і в інших формах) даються у звичайному орфографічному записі, але із зазначенням наголосу.
Будова словникової статті.
Словникова стаття у випадку складається (крім великого слова) з:
1) основного літерного символу,
2) індексу,
3) додаткових послідів і вказівок (в окремих випадках той чи інший з цих елементів може бути відсутнім).
Якщо різним значенням слова відповідають якісь відмінності у освіті форм, словникова стаття розпадається на відповідне число частин («статей»), кожна з яких будується як самостійна стаття (тобто має свій основний літерний символ, свій індекс та свої додаткові посліди) та вказівки). Кожна така стаття починається з нового рядка.
Основне буквене позначення.
Основний буквений символ (у всіх слів, крім іменників та дієслів) – це буквене скорочення, що означає частину мови. У іменників основний літерний символ складається із символів роду та одухотвореності чи неживої (або символу «мн.»), у дієслів – із символів виду та перехідності чи неперехідності; частина мови у випадках не вказується, оскільки вона зрозуміла з основного буквеного символу.
Індекс.
Індекси є лише у змінних частин промови. Елементи, у тому числі складається індекс, такі (обов'язковим є лише перший їх, будь-який з інших елементів може бути відсутній).
1. Цифра (від 0 до 8 у імен, від 1 до 16 у дієслів) – тип відмінювання або відмінювання.
2. Надрядкова зірочка (*) або кружечок (°) при цифрі – символи наявності певних чергувань в основі (у деяких особливих випадках * і ° виступають одночасно).
3. Латинська літера (або дві літери, розділені косою межею) без штрихів або зі штрихами – схема наголосу. Цей елемент індексу відсутній лише після цифри 0.
4. Російська літера або літерна послідовність (між рисочками, у дужках), наприклад, (-д-) при вісті, (-ім-) при розняти, - вказівка (можлива тільки при невеликій частині дієслів), що дозволяє правильно утворити основу теперішнього часу .
5. Одна або кілька цифр у гуртку (від 1 до 9) – символи найбільш поширених відхилень від стандартного відмінювання або відмінювання.
6. Знак «е» – символ наявності основи чергування: е (під наголосом) – е (без наголосу). Варіантом цього знака є знак "про" (можливий тільки у дієслів на-цівати).
Приклади індексів: 1; За/с; 5*b; l*a/b2, е.
У переважній більшості слів індекс складається лише з 1-го та 3-го елементів, тобто з цифри та латинської літери (або літер), наприклад, 1а, 4b, За/с (або навіть лише з однієї цифри 0). Надалі такі індекси називаються простими.
Сукупність 1-го, 2-го та 3-го елементів індексу називається основною частиною індексу.
У деяких іменниках і прикметниках індекс (разом з додатковим символом роду або частини мови) укладено в кутові дужки. Це означає, що слово схиляється так, як зазначено в кутових дужках, хоча саме належить до іншого роду чи іншої частини мови. Приклади:
- Чоловік мо <жо 1а> (тобто це іменник чоловічого роду схиляється за зразком жіночого роду);
- кома ж <п 1b> (тобто це іменник схиляється як прикметник).
Побудова форм безпосередньо за індексом.
Спосіб побудови форм полягає в тому, що кожен елемент індексу має самостійне морфологічне значення. Воно розкривається у «Граматичних відомостях», у розділах, озаглавлених «Значення буквених символів та елементів індексу», словника О. Залізняка. Наприкінці цих розділів вказано і сам спосіб побудови форм безпосередньо за індексом. Якщо Словникова стаття має додаткові посліди або вказівки, при цьому способі, так само, як і за попереднього, у побудованих формах необхідно зробити відповідні поправки.
Висновки
У процесі виконання даної роботи, були вирішені та розглянуті такі завдання:
1. Основні засади побудови комп'ютерної морфології.
2. Основні алгоритми створення експериментальної моделі морфологічного аналізатора на основі словника з формальним описом мови для веб-платформи.
3. Була вирішена проблема розробки методів побудови структури морфологічного словника та способів програмування, що дозволяють мінімальними силами вирішити поставлене завдання стосовно текстів довільної (або майже довільної) складності.
4. Три структури морфологічного словника для запропонованої моделі аналізатора, що відрізняються один від одного складністю побудови, швидкістю та якістю аналізу
5. Було розглянуто та впроваджено у запропоновану модель аналізатора метод визначення морфологічних характеристик слів, відсутніх у словнику.
6. В результаті аналізу було вирішено проблему розробки методів побудови структури морфологічного словника та способів програмування, що дозволяють мінімальними силами вирішити поставлене завдання стосовно текстів довільної (або майже довільної) складності.
7. Для реалізації запропонованої моделі морфологічного аналізатора та аналізу ефективності розроблених структур словника були використані сучасні засоби у галузі веб-програмування, такі як високорівнева мова програмування PHP.
Ця розробка є відкритою – запропоновану модель морфологічного аналізатора можна вбудувати у будь-які комп'ютерні системи для веб-платформи, що обробляють тексти природною мовою.
Перелік посилань
1. Goldsmith J. Unsupervised learning of the morphology of a natural language / J. Goldsmith. // University of Chicago. – 1998. – №1. – с. 1-46.
2. Зализняк А. А. Грамматический словарь русского языка. Словоизменение / А. А. Зализняк. – М. : русский язык, 1977. – 880 с.
3. Аношкина Ж.Г. Морфологический процессор русского языка / Ж.Г. Аношкина. // Альманах «Говор». – 1995. – №6. – с. 17-23.
4. Гершензон Л.М. Синтаксический анализ в системе РМЛ / Л.М. Гершензон, И.М. Ножов, Д.В. Панкратов, А.В. Сокирко [Электронный ресурс]. – режим доступа : http://www.Aot.Ru/docs/synan.html. 2003.
5. Ножов И.М. Процессор автоматизированного морфологического анализа без словаря. Деревья и корреляция. / Ножов И.М. // Диалог’2000. Труды конференции. – Протвино, 2000. – т.2. – с. 284-290.
6. Сокирко А.В. Морфологические модули на сайте / А.В. Сокирко. // диалог-2004. – 2004. – т.1. – с. 3-18.
7. Rabiner L. R. A tutorial on Hidden Markov Models and selected applications in speech recognition / L. R. Rabiner. – proc. Of the ieee, 1989. – 340 с.
8. Ермаков А.Е. Выделение объектов в тексте на основе формальных описаний / А.Е. Ермаков, В.В. Плешко, В.А. Митюнин. // информационные технологии. – 2003. – №12. – с. 1-6.
9. Анисимов А.В. Компьютерная лингвистика для всех. Мифы. Алгоритмы. Язык / А.В.Анисимов. – Киев : Наукова думка, 1991. – 447с.
10. Baeza-yates R. Modern information retrieval / Baeza-Yates R., Ribeiro-Neto B. – ACM Press. 1999. – 580 с.
11. Андреев А.М., Березкин Д.В., Брик А.В. Лингвистический процессор для информационно-поисковой системы. [Электронный ресурс]. - режим доступа: http://www.inteltec.ru/publish/articles/textan/art_21br.shtml