
Реферат по теме выпускной работы
Содержание
- Введение
- 1. Актуальность темы
- 2. Цель и задачи исследования, планируемые результаты
- 3. Обзор исследований и разработок
- 3.1 Обзор основных принципов построения компьютерной морфологии
- 3.2 Графематический анализ
- 3.3 Морфологический анализ с использованием словаря
- 4. Морфологический анализатор
- 4.1 Общие требования к морфологическому анализатору
- 4.2 Морфологический анализ слова
- 4.3 Базовые словари
- Выводы
- Список источников
Введение
В большинстве естественных языков наблюдается такое явление, как морфологическая изменяемость слов. Данное явление сильно выражено в русском и украинском языках, которые относятся к группе флективных языков со сложной системой флексий.
Информационно-поисковая система или любая другая система, работающая с русским или другим флективным языком, должна учитывать эту особенность языка, что реализуется обычно с помощью специального модуля системы, называемого модулем морфологического анализа.
Цель работы является исследование и разработка алгоритмов построения морфологического анализатора на основе словаря с формальным описанием языка. Основной решаемой проблемой при этом является разработка методов построения структуры морфологического словаря и способов программирования, позволяющих решить поставленную задачу.
1. Актуальность темы
Актуальность проблемы морфологического анализа и синтеза словоформ определяется тем, что блок морфологического анализа является необходимой частью большинства работающих с естественно-языковыми текстами программ самого различного уровня и назначения.
На сегодня разработка алгоритмов построения морфологического анализатора на основе словаря - это одна из актуальных задач в компьютерной лингвистике. С помощью уже разработанных алгоритмов, будет проще в будущем разрабатывать более сложные алгоритмы, которые уже будут включать больший функционал в этой теме.
2. Цель и задачи исследования, планируемые результаты
Цель работы является исследование и разработка алгоритмов построения морфологического анализатора на основе словаря с формальным описанием языка для веб-платформы. Основной решаемой проблемой при этом является разработка методов построения структуры морфологического словаря и способов программирования, позволяющих решить поставленную задачу.
Основные задачи исследования:
- Провести исследование алгоритмов формирования структуры морфологического словаря в условиях ограничений, налагаемых средствами разработки веб-платформ.
- Спроектировать модель базы данных.
- Разработать алгоритмы построения морфологического анализатора на основе словаря.
- Разработка метода распознавания отсутствующих в словаре слов.
Предмет исследования – методы создания сайтов, системы автоматизации продаж (CRM, BI), алгоритмы процесса принятия управленческих решений.
Объект исследования - результат выполнения алгоритмов построения морфологического анализатора на основе словаря и их дальнейшая оптимизация.
3. Обзор исследований и разработок
Морфологическим анализом называется установление по словоформе исходного слова – лексемы, а также морфологических характеристик данной словоформы, таких как род, падеж, число и т.д. Разрабатываемый морфологический анализатор должен будет выполнять морфологический анализ, и выявлять существительные-понятия данного текста
3.1 Обзор основных принципов построения компьютерной морфологии
Среди методов морфологического анализа, использующихся в лингвистических процессорах, можно выделить методы с декларативной и с процедурной ориентацией. Для методов декларативной ориентации характерно наличие полного словаря всех возможных словоформ для каждого слова. При этом каждая словоформа снабжается полной и однозначной морфологической информацией, куда входят как постоянные, так и переменные морфологические параметры. Задача морфологического анализа в этом случае сводится к поиску нужной словоформы в словаре и копированию морфологической информации, соответствующей найденной словоформе, в программу[11].
В процедурных методах используют вероятностно-статистические методы и лексиконы суффиксов или квази-суффиксов, основ или квази-основ, построенных эмпирически. Каждое слово разделяется на основу и аффикс, и словарь содержит только основы слов вместе со ссылками на соответствующие строки в таблице возможных аффиксов. Основной критерий при разбиении слова на основу и аффикс – основа должна оставаться неизменной во всех возможных словоформах данного слова. Поскольку большое количество слов русского языка имеет одни и те же аффиксы, то суммарный объем словаря основ и словаря аффиксов оказывается значительно меньше, чем объем полного словаря всех словоформ, используемого в декларативных методах. Однако процедура морфологического анализа усложняется: теперь из словаря основ необходимо поочередно выбирать все основы, совпадающие с начальными буквами анализируемого слова, и для каждой такой основы перебирать все возможные для нее аффиксы. В случае точного совпадения очередного варианта «основа+аффикс» с анализируемым словом вариант анализа считается успешным, и в программу передается морфологическая информация, соответствующая данной основе и данному аффиксу. При этом, как правило, постоянные морфологические параметры определяются основой слова, а переменные – аффиксом.
Возможно, использовать комбинированный вариант морфологического анализа. При этом используется как словарь словоформ, так и словарь основ. На первом этапе проводится поиск по словарю словоформ, и в случае успешного поиска анализ на этом завершается. В противном случае задействуется словарь основ и процедурный метод анализа.
3.2 Графематический анализ
Прежде, чем приступать к морфологическому анализу отдельных слов, необходимо провести графематический анализ входного текста.
Основная цель графематического модуля получить выборку полных словоформ из массива текстов БД[5]. Графематический анализ работает с внешним представлением текста и использует таблицу стоп-слов. В этой таблице хранятся цифры, спецсимволы и частотные слова языка, нерелевантные для поиска по текстам и не нуждающиеся в морфологическом анализе.
Графематический анализ выполняет три функции:
Единицей графематического анализа является цепочка символов, выделенная с двух сторон пробелами. Выделенная цепочка символов подвергается последовательной обработке эвристическими правилами: отсечь знаки пунктуации, проверить присутствие гласных внутри цепочки, чередование верхнего и нижнего регистров и т.д. В зависимости от результатов обработки полученная цепочка символов направляется в один из трех потоков данных:
Первые два потока данных не нуждаются в морфологическом анализе. Полные словоформы поступают на вход морфологического анализа, цель которого разбить все множество словоформ на подмножества по признаку принадлежности к той или иной лексеме (множество словоформ, отличающихся друг от друга только словоизменительными значениями), привести все элементы каждого такого подмножества к уникальной основе, однозначно определить грамматические характеристики лексемы и проиндексировать тексты по встретившимся в них основам.
3.3 Морфологический анализ с использованием словаря
Модели, которые используют словарь, способны дать более полный анализ словоформы (т.е. оперировать большим числом грамматических признаков). Степень точности такого анализа выше, по сравнению с моделями, которые не используют словаря. Но, на пространстве реальных текстов системы, использующие словарь, часто дают сбои. Это обусловлено тем, что не существует полных словарей. Лексика языка непрерывно пополняется – появляются новые слова. Для каждой предметной области существует своя терминология, свое подмножество лексики языка, и включить в общий словарь всю существующую терминологию – невозможно. Равно как невозможно и перечислить все существующие имена и фамилии, которые имеют регулярное склонение.
Данный метод копирует академическую лингвистическую модель описания, где выделяются основные парадигматические классы, соответствующие типу склонения и спряжения, и правила регулярных альтернаций (фонетических чередований), а нерегулярные формы, например, сильные глаголы в немецком и английском языках, задаются перечислением. Такого типа лексиконы для русского языка составляются на базе модели грамматического словаря, например А. Зализняка, А. Лебедева и др., разрабатывая 8 классов именного склонения и 16 глагольного спряжения, а чередования в основе и глагольной темы выносятся в отдельное множество пост-морфологических правил альтернаций.
Процессы индексации такие же, как и в методе построения морфологии без словаря. С начала текст проходит графематический анализ – текст разбивается на слова, затем слова подаются на вход морфологического анализатора.
Входным параметром является текстовое представление исходного слова. Целью и результатом морфологического анализа является определение морфологических характеристик слова и его основной словоформы. Перечень всех морфологических характеристик слов и допустимых значений каждой из них зависят от естественного языка. Тем не менее, ряд характеристик (например, название части речи) присутствуют во многих языках. Результаты морфологического анализа слова неоднозначны, что можно проследить на множестве примеров.
Словарь А. Зализняка содержит основные словоформы слов русского языка, для каждой из которых указан определенный код[2]. Известна система правил, с помощью которой можно построить все формы данного слова, отталкиваясь от начальной словоформы и соответствующего ей кода. Помимо построения каждой словоформы, система правил автоматически ставит в соответствие ей морфологические характеристики. При проведении четкого морфологического анализа необходимо иметь словарь всех слов и всех словоформ языка. Этот словарь на входе принимает форму слова, а на выходе выдает его морфологические характеристики. Данный словарь можно построить на основе словаря А. Зализняка либо аналогичного по очевидному алгоритму: перебрать все слова из словаря, для каждого из них определить все лексемы и занести их в формирующийся словарь.
При таком подходе для проведения морфологического анализа заданного слова (см. рис. 1) необходимо просто найти его в словаре, где уже хранятся точные, окончательно известные значения всех его морфологических характеристик. Для одного и того же входного слова могут встретиться сразу несколько вариантов значений его морфологических характеристик.
К сожалению, этот способ применим не всегда: слова, поступающие на вход, могут не входить в словарь всех словоформ. Такая ситуация может возникнуть из-за ошибок ввода исходного текста, из-за наличия в тексте имен собственных и т.д. В случае, когда метод не дает нужного результата, применяется нечеткая морфология.
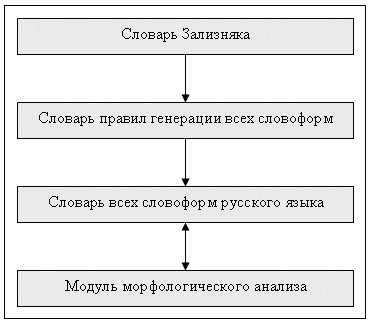
Рисунок 1 – Морфологический анализ на основе словаря А. Зализняка
Целью морфемного анализа слова является разделение слова на приставки, корни, суффиксы и окончания (см. рис.2).
В словаре морфем русского языка указано разделение каждого слова на отдельные части, но не указаны типы каждой из них – какая из них является приставкой, какая корнем и т.д.
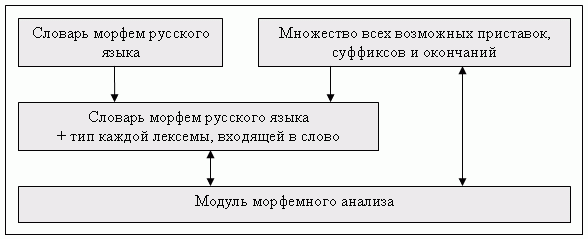
Рисунок 2 – Морфемный анализ
Множество всех корней слов русского языка открыто, но множество всех возможных приставок, суффиксов и окончаний ограничено; кроме того, известно, что в любом слове сначала идут приставки, затем корни, далее суффиксы и окончания. Поэтому на основе словаря морфем русского языка можно построить другой словарь, который будет содержать не только разбиение каждого слова на части, но и тип каждой из них. В таком случае, для проведения морфемного анализа слова необходимо обратиться к этому словарю.
Морфемный анализ не ограничивается обращениями к словарю. В ситуации, когда слово отсутствует в словаре, возможно непосредственное проведение анализа на основе стандартного строения слов русского языка (приставка – корень – суффикс – окончание) и множества всех приставок, суффиксов и окончаний.
Вернемся к морфологическому анализу слова в той ситуации, когда не удалось определить характеристики слова с помощью методов четкой морфологии, но удалось расчленить его на части. Наличие тех или иных лексем может определять морфологические характеристики слова: можно построить систему правил, которая будет опираться на наличие или отсутствие каких-либо частей и выдавать одно или несколько предположений о морфологических параметрах. Такой набор правил можно построить двумя способами. Первый основан на морфемном анализе слов, содержащихся в словаре всех словоформ, и их морфологических характеристик. Рассмотрим эту задачу формальнее: известны пары значений, состоящие из морфемного строения слова и его морфологических характеристик. Это есть не что иное, как «вход» и «выход» системы правил, которая по морфемному строению слова будет определять его морфологические характеристики. Задачу построения такой системы правил можно решить с помощью самообучающейся системы. Для ее реализации могут быть использованы деревья решений, программирование на основе индуктивной логики (ILP, Inductive Logic Programming) или другие алгоритмы.
4. Морфологический анализатор
4.1 Общие требования к морфологическому анализатору
Основная задача морфологического анализатора заключается в определении морфологических признаков слов текста и канонических форм (КФ) слов. В качестве КФ может выступать либо основа (или даже корень), либо традиционная нормальная форма слова (НФ) – некая изначальная форма слова, например, для глагола – инфинитив, для существительного – единственное число в именительном падеже.
Для задачи приведения необходимо создание словаря, с помощью которого можно получить каноническую форму слова и информацию о морфологических признаках слова, его склонении. Следует выделить основные компоненты, от реализации которых зависит эффективность использования морфологического анализатора.
1. Организация структуры словаря. Словарь должен быть прост в реализации, не должен содержать сложных и многообъемных элементов. Необходимо учесть минимальное использование дополнительных ресурсов и затраченное время на доступ к элементам словаря.
2. Алгоритм определения канонической формы и склонения. Элементы словаря должны содержать необходимую информацию для приведения и максимально полную для определения лексем, что исключает использование дополнительных методов пред- и постобработки.
3. Алгоритмы определения морфологических характеристик слов, отсутствующих в словаре. Естественные языки непрерывно пополняются новыми словами, поэтому очень важно своевременно обновлять словарь.
На рисунке 3 приведено схематическое представление морфологического анализатора.
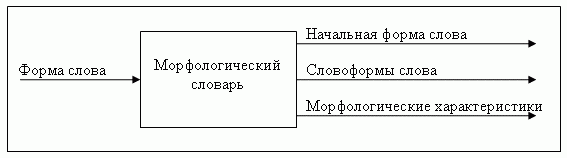
Рисунок 3 – Схематическое представление морфологического анализатора
4.2 Морфологический анализ слова
Морфологический анализ можно разделить на «прямой» и «обратный». Оба метода широко применяются в поисковых машинах.
Прямой метод заключается в нахождении из нормальной формы слова всех его словоформ. Это операция применяется при выборке документов. Так как отбираются документы, которые содержат все формы слова, то в результат поиска попадают не только документы со словом в совпадающей с запросом форме, но и другие документы, содержащие различные формы данного слова.
Алгоритм построения всех словоформ и определения его морфологических характеристик в первую очередь зависит от структуры морфологического словаря, который используется анализатором.
Обратный метод заключается в нахождении нормальной формы из произвольной. Эта операция применяется при индексировании текста. Таким образом, достигается уменьшение размера индекса и времени поиска документов, удовлетворяющих условию.
Алгоритм для нахождения нормальной формы по произвольной также зависит от структуры словаря.
4.3 Базовые словари
Для построения морфологического словаря можно воспользоваться любым из грамматических словарей, в котором описана формальная модель языка. Для русского языка можно воспользоваться следующими словарями:
4.3.1 Словарь русского языка А. Лебедева
Орфографический словарь А. Лебедева представляет собой два файла: самого словаря и аффикс-правил. Объем словаря – 137.2 тысячи слов и более 1.354 миллиона словоформ. Данный словарь разрабатывался специально для программы проверки орфографии Ispell. Но на его базе можно построить морфологический словарь для анализатора.
Первый файл – словарь, список слов в НФ, разделенных символом «/» от групп идентификаторов правил словообразований. Пример словаря представлен на рисунке 4
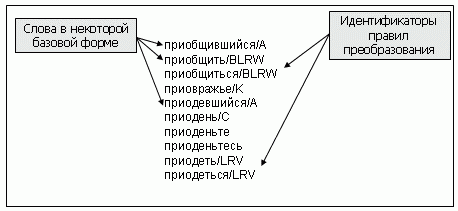
Рисунок 4 – Пример словаря А. Лебедева
Словоформы для слова «приодень» строятся по правилам для группы правил С. Стоит особенно обратить внимание на то, что групп может быть несколько (приобщиться/BLWR). Это значит, что все правила из указанных групп (B, L, W, R) применимы к данному слову. В целом это довольно гибкий принцип, таким образом, уменьшается избыточность, ряд правил выносятся в отдельные группы и применяется к основной группе.
Файл с аффикс-правилами (*.aff) состоит из флагов и правил словообразования. Образец файла аффиксов представлен на рисунке 5.
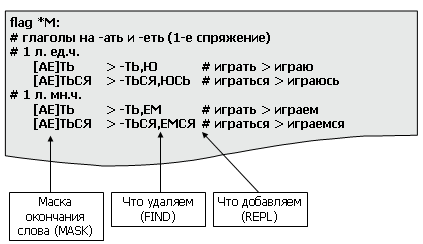
Рисунок 5 – Образец файла аффиксов
Это можно прочитать следующим образом: в слове «играть» заменяем окончание «-ть» на «ю» только в том случае, если слово «играть» удовлетворяет маске «[АЕ]ть», где маской является обычное PERL-совместимое регулярное выражение. Узнать какие группы правил можно применять к данному слову, а какие нельзя помогают флаги, указанные возле слова в словаре.
Морфология, основанная на данном словаре, сильно уступает коммерческим разработкам, так как словарь изначально предназначался для проверки орфографии. Как видно из рисунка 5 слова «приодень», «приоденьте» и «приоденьтесь» являются совершенно разными словами, хотя в действительности могут иметь одну основу. Также в словаре нельзя найти «новые» слова, которые пришли к нам из других языков, например, «менчердайзер».
Некоторые недостатки можно решить, используя словарь А. Зализняка, на базе которого были построены почти все современные системы, работающие с морфологией русского языка.
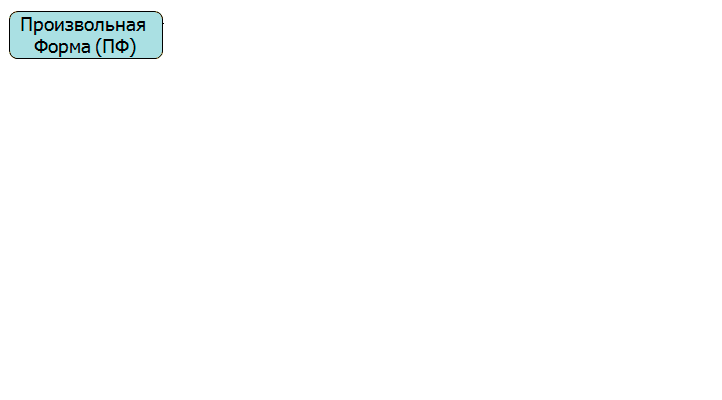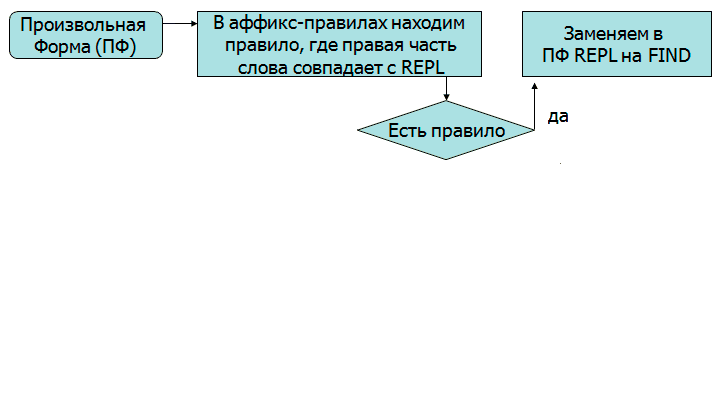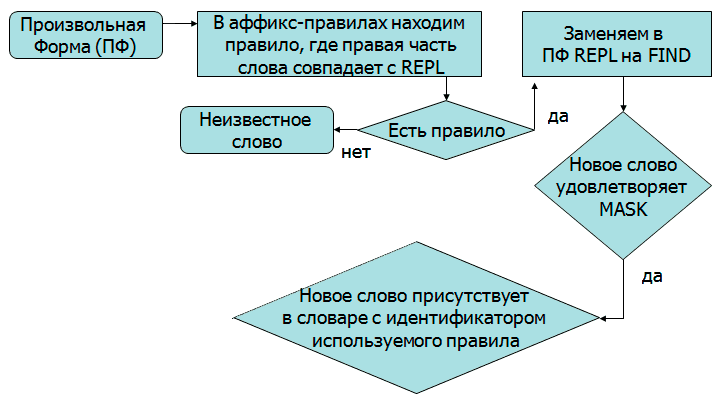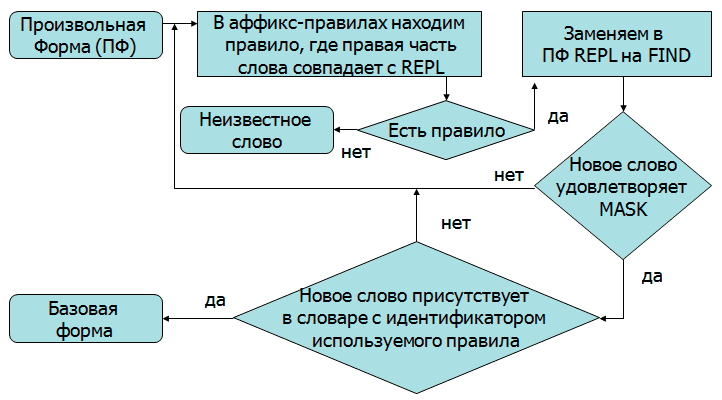
Рисунок 6 - Алгоритм приведения слова к базовой форме(Рисунок анимирован, количество повторов 7, длительность одного составляет 9 с, 9 кадров, 103 КБ.)
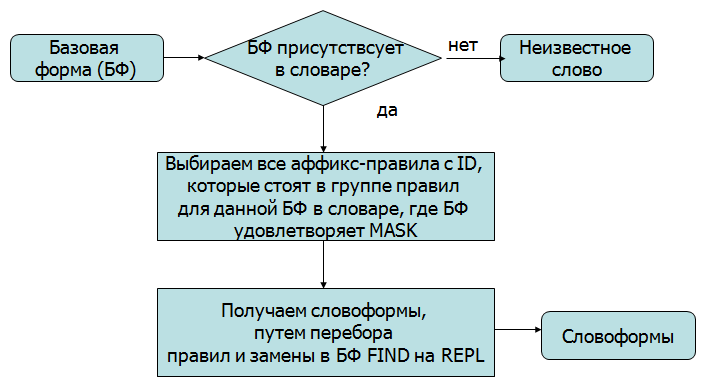
Рисунок 7 - Алгоритм получения всех словоформ от базовой формы
Алгоритм запуска программы представлен в блок-схеме на рисунке 4.
4.3.2 Словарь русского языка А. Зализняка
Грамматический словарь А. Зализняка на данный момент содержит 161 тысячу слов[2]. Это основополагающий труд по морфологии, где впервые был предложен системный подход к описанию грамматических парадигм, включающих не только изменение буквенного состава слов, но и ударения.
Словарь впервые был издан в 1977 г., с тех пор неоднократно переиздавался. Электронная версия этого словаря легла в основу большинства современных компьютерных программ, работающих с русской морфологией (системы проверки орфографии, автоматического перевода, реферирования и т. п.).
Каждое слово представлено в словаре своей исходной, или словарной, формой (которая образует так называемое заглавное слово статьи). Для склоняемых частей речи это именительный падеж (если слово изменяется по числам – ед. числа; если оно изменяется по родам мужского рода), для глаголов – инфинитив, для неизменяемых частей речи – единственная имеющаяся форма.
Все слова (как в исходной, так и в прочих формах) даются в обычной орфографической записи, но с указанием ударения.
Строение словарной статьи.
Словарная статья в общем случае состоит (не считая заглавного слова) из:
1) основного буквенного символа,
2) индекса,
3) дополнительных помет и указаний (в частных случаях тот или иной из этих элементов может отсутствовать).
Если разным значениям слова соответствуют какие-то различия в образовании форм, словарная статья распадается на соответствующее число частей («подстатей»), каждая из которых строится как самостоятельная статья (т. е. имеет свой основной буквенный символ, свой индекс и свои дополнительные пометы и указания). Каждая такая подстатья начинается с новой строки (см. рис. 8).
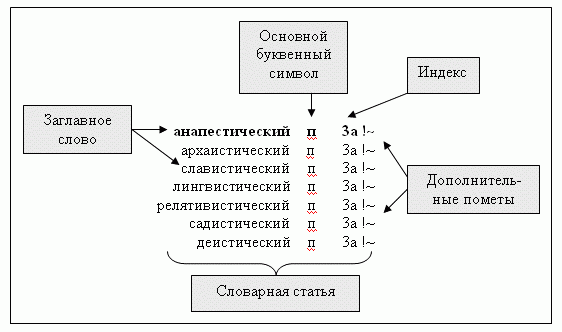
Рисунок 8 - Словарная статья грамматического словаря А. Зализняка
Основной буквенный символ.
Основной буквенный символ (у всех слов, кроме существительных и глаголов) – это буквенное сокращение, обозначающее часть речи. У существительных основной буквенный символ состоит из символов рода и одушевленности или неодушевленности (или символа «мн.»), у глаголов – из символов вида и переходности или непереходности; часть речи в этих случаях не указывается, поскольку она ясна из основного буквенного символа.
Индекс.
Индексы имеются только у изменяемых частей речи. Элементы, из которых складывается индекс, таковы (обязательным является только первый из них, любой из остальных элементов может и отсутствовать).
1. Цифра (от 0 до 8 у имен, от 1 до 16 у глаголов) – тип склонения или спряжения.
2. Надстрочная звездочка (*) или кружочек (°) при цифре – символы наличия определенных чередований в основе (в некоторых особых случаях * и ° выступают одновременно).
3. Латинская буква (или две буквы, разделенные косой чертой) без штрихов или со штрихами – схема ударения. Этот элемент индекса отсутствует только после цифры 0.
4. Русская буква или буквенная последовательность (между черточками, в скобках), например, (-д-) при вести, (-им-) при разнять, – указание (возможное только при небольшой части глаголов), позволяющее правильно образовать основу настоящего времени.
5. Одна или несколько цифр в кружке (от 1 до 9) – символы наиболее распространенных отклонений от стандартного склонения или спряжения.
6. Знак «ё» – символ наличия в основе чередования: ё (под ударением) – е (без ударения). Вариантом этого знака является знак «о» (возможный только у глаголов на -цевать).
Примеры индексов: 1а; За/с; 5*b; l*a/b2, ё.
У подавляющего большинства слов индекс состоит только из 1-го и 3-го элементов, т. е. из цифры и латинской буквы (или букв), например, 1а, 4b, За/с (или даже только из одной цифры 0). В дальнейшем такие индексы называются простыми.Совокупность 1-го, 2-го и 3-го элементов индекса называется основной частью индекса.
У некоторых существительных и прилагательных индекс (вместе с дополнительным символом рода или части речи) заключен в угловые скобки. Это значит, что слово склоняется так, как указано в угловых скобках, хотя само принадлежит к другому роду или другой части речи. Примеры:
– мужчина мо <жо 1а> (т. е. это существительное мужского рода склоняется по образцу женского рода);
– запятая ж <п 1b> (т. е. это существительное склоняется как прилагательное).
Построение форм непосредственно по индексу.
Способ построения форм основан на том, что каждый элемент индекса имеет самостоятельное морфологическое значение. Оно раскрывается в «Грамматических сведениях», в разделах, озаглавленных «Значение буквенных символов и элементов индекса», словаря А. Зализняка. В конце этих разделов указан и сам способ построения форм непосредственно по индексу. Если в Словарной статье имеются дополнительные пометы или указания, при этом способе, так же, как и при предыдущем, в построенных формах необходимо сделать соответствующие поправки.
Выводы
В процессе выполнения данной работы, были решены и рассмотрены такие задачи:
1. Основные принципы построения компьютерной морфологии.
2. Основные алгоритмы для создания экспериментальная модель морфологического анализатора на основе словаря с формальным описанием языка для веб-платформы.
3. Была решена проблема разработки методов построения структуры морфологического словаря и способов программирования, позволяющих минимальными силами решить поставленную задачу применительно к текстам произвольной (или почти произвольной) сложности.
4. Три структуры морфологического словаря для предложенной модели анализатора, отличающиеся друг от друга сложностью построения, скоростью и качеством анализа
5. Был рассмотрен и внедрен в предложенную модель анализатора метод определения морфологических характеристик слов, отсутствующих в словаре.
6. В результате анализа была решена проблема разработки методов построения структуры морфологического словаря и способов программирования, позволяющих минимальными силами решить поставленную задачу применительно к текстам произвольной (или почти произвольной) сложности.
7. Для реализации предложенной модели морфологического анализатора и анализа эффективности разработанных структур словаря были использованы современные средства в области веб-программирования, такие как высокоуровневый язык программирования PHP.
Данная разработка является открытой – предложенную модель морфологического анализатора можно встроить в любые компьютерные системы для веб-платформы, обрабатывающие тексты на естественном языке.
Список источников
1. Goldsmith J. Unsupervised learning of the morphology of a natural language / J. Goldsmith. // University of Chicago. – 1998. – №1. – с. 1-46.
2. Зализняк А. А. Грамматический словарь русского языка. Словоизменение / А. А. Зализняк. – М. : русский язык, 1977. – 880 с.
3. Аношкина Ж.Г. Морфологический процессор русского языка / Ж.Г. Аношкина. // Альманах «Говор». – 1995. – №6. – с. 17-23.
4. Гершензон Л.М. Синтаксический анализ в системе РМЛ / Л.М. Гершензон, И.М. Ножов, Д.В. Панкратов, А.В. Сокирко [Электронный ресурс]. – режим доступа : http://www.Aot.Ru/docs/synan.html. 2003.
5. Ножов И.М. Процессор автоматизированного морфологического анализа без словаря. Деревья и корреляция. / Ножов И.М. // Диалог’2000. Труды конференции. – Протвино, 2000. – т.2. – с. 284-290.
6. Сокирко А.В. Морфологические модули на сайте / А.В. Сокирко. // диалог-2004. – 2004. – т.1. – с. 3-18.
7. Rabiner L. R. A tutorial on Hidden Markov Models and selected applications in speech recognition / L. R. Rabiner. – proc. Of the ieee, 1989. – 340 с.
8. Ермаков А.Е. Выделение объектов в тексте на основе формальных описаний / А.Е. Ермаков, В.В. Плешко, В.А. Митюнин. // информационные технологии. – 2003. – №12. – с. 1-6.
9. Анисимов А.В. Компьютерная лингвистика для всех. Мифы. Алгоритмы. Язык / А.В.Анисимов. – Киев : Наукова думка, 1991. – 447с.
10. Baeza-yates R. Modern information retrieval / Baeza-Yates R., Ribeiro-Neto B. – ACM Press. 1999. – 580 с.
11. Андреев А.М., Березкин Д.В., Брик А.В. Лингвистический процессор для информационно-поисковой системы. [Электронный ресурс]. - режим доступа: http://www.inteltec.ru/publish/articles/textan/art_21br.shtml