

|
|
Построение тестов - это сложная проблема со многими взаимодействующими аспектами. Наиболее важными проблемами являются:
Стоимость ГТ зависит от сложности метода построения теста. Произвольный метод генерации теста (ПГТ) представляет собой простой процесс, который включает в себя только порождение произвольных входных векторов. Однако, для того, чтобы построить высококачественный тест, нам понадобится больший набор произвольных входных векторов. Из этого следует, что даже если метод ГТ непосредственно прост, определение его характеристик, например, моделированием неисправности - может быть дорогим процессом. Кроме того, более длинный тест стоит больше, потому что он увеличивает время эксперимента и ужесточает требования к памяти тестера.
ПГТ работает без рассмотрения функции или структуры проверяемой схемы, а детерминированный ГТ строит тесты с учетом логической структуры схемы. По сравнению с ПГТ, детерминированный ГТ более дорог, но он строит короткий и высококачественный тест.
Детерминированный ГТ может быть ориентированным на неисправность или независимым от неисправности. В режиме ориентации на неисправности, тесты генерируются только для конкретных неисправностей. Во втором режиме ГТ рассматривает все неисправности. Конечно, стоимость ГТ также зависит от степени интеграции схемы, которая будет проверена.
На рисунке 1.1 изображен общий вид детерминированной системы ГТ. Тесты сгенерированы на основе модели схемы и рассматриваемой модели неисправности. Сгенерированные тесты включают, также и стимулы, которые нужно подавать на входы исправной схемы для получения ожидаемого результата. Некоторые системы ГТ также производят диагностические данные, которые можно использовать для обнаружения неисправностей.
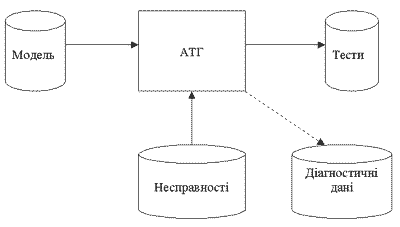
Рисунок 1.1 Детерминированная система генерации тестов
Существуют две фундаментальные ступеньки в производстве теста для неисправности l s-a-v, первая, активизировать неисправность, и, вторая, распространить возникающую в результате ошибку к первичному выходу. Активизация неисправности означает, что первичные входные воздействия (ВВ) устанавливаются такими, при которых линия l имеет значение v. Чтобы следить за распространением ошибки, мы должны наблюдать за выходами исправной схемы N и неисправной схемы Nf с определенной неисправностью f. Для этого мы определяем составные логические значения формы v/vf, где v и vf - значения того же самого сигнала в N и Nf. Составные логические значения, которые представляют ошибки - 1/0 и 0/1 -, обозначены символами D и nD [Roth 1966].
Другие два составных значения 0/0 и 1/1 - обозначены 0 и 1. Между двумя составными значениями может быть выполнена любая логическая операция. Например, D + 0 = 0/1 + 0/0 = 0 + 0/1 + 0 = 0/1 = D. К этим четырем двоичным составным значениям мы добавляем пятое значение (x), чтобы обозначить неопределенное состояние, то есть любое значение в наборе {0,1,D,D}. Логические операции, использующие эти составные значения, описаны в таблицах 1.1, 1.2, 1.3. Очевидно, что D ведет себя в соответствии с правилами булевой алгебры, т.е., D + nD = 1, D & nD = 0, D + D = D & D = D, D & D = D+D = D.
Таблица 1.1 - Составные логические значения
| V/Vf | Значение |
| 0/0 | 0 |
| 1/1 | 1 |
| 1/0 | D |
| 0/1 | nD |
| AND | 0 | 1 | D | nD | X |
| 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 1 | D | nD | X |
| D | 0 | D | D | 0 | X |
| nD | 0 | nD | 0 | nD | X |
| X | 0 | X | X | X | X |
| OR | 0 | 1 | D | D | X |
| 0 | 0 | 1 | D | D | X |
| 1 | 1 | 1 | 1 | 1 | 1 |
| D | D | 1 | D | 1 | X |
| D | D | 1 | 1 | D | X |
| X | X | 1 | X | X | X |
Структура алгоритма построения теста для неисправности l s-a-v изображена ниже. Этот алгоритм инициализирует все переменные значением x, и выполняет активизацию (подпрограмма Justify()) и распространение (подпрограмма Propagate()).
Подпрограмма Propagate(): begin //set all values to x Justify(l. v) If v = 0 then Propagate (I, D) else Propagate (I, D) end Подпрограмма Justify(): Justify (l, val) вegin set l to val if l is a PI(ВВ) then return /* l is a gate (output) */ c = controlling value of l i = inversion of l inval = valЕ i if (inval = c) then for every input j of l Justify (j, inval) else begin select one input (j) of l Justify (j, inval) end end
Как видно из текста программы, активизация пути - это рекурсивный процесс, который продолжается до тех пор, пока все входные воздействия не будут определены. Рассмотрим для примера элемент NAND с k входами изображенный на рисунке 1.2.
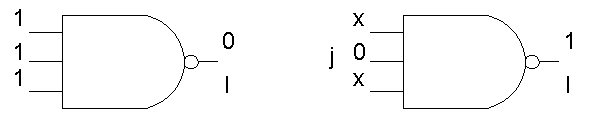
Рисунок 1.2 - Элемент NAND
Ноль, на выходе данного элемента, мы получим только в том случае, если подадим на входы все единицы, а для того чтобы получить 1 на выходе можно подать 2k-1 входных вектора. Самый простой из этих векторов состоит из одного 0 и двух неопределенностей. Это соответствует выбору одного из k примитивных кубов, в котором выход равняется 1.
Чтобы распространить ошибку до выхода схемы, необходимо активизировать путь от ветви l до выхода. Каждый выход элемента, на этом пути, имеет только один вход активизации неисправности. Согласно теореме Лемме 4.1, мы должны установить все другие входы на этом пути в такое состояние, при котором они не будут влиять на выход. Таким образом, мы трансформируем задачу распространения ошибки в набор задач активизации (рисунок 1.3).
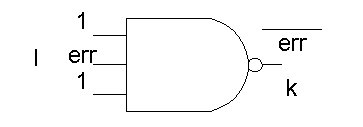
Рисунок 1.3
Важно отметить, что в схеме без разветвлений, каждая задача активизации пути может быть решена независимо от всех других, потому что наборы входных воздействий не пересекаются. В схемах с разветвлениями, возможны различные пути распространения ошибки к выходу схемы. Выбирая один путь для продвижения неисправности к выходу, мы преобразуем задачу распространения ошибки к набору задач активизации пути. Основная трудность, вызванная (повторно сходящимся) разветвлением на выходе схемы состоит в том, что, возникающие в результате задачи активизации больше не независимы. Для примера рассмотрим схему на рисунке 1.4.

Рисунок 1.4
Рассмотрим неисправность h s-a-1. Чтобы активизировать эту неисправность, мы должны установить h = 0 и распространить ее через ветви p и s. Для этого необходимо подать следующие входные воздействия: e = f = 1 и q = r = 1. Значение q = l может быть доопределено через l = 1 или k = 1. Установим l = 1, тогда c = d = 1. Однако данное решение неправильно, так как при е = 1, r быть равно 0, что противоречит входным условиям. Следовательно, необходимо двигаться по ветви k. При k = 1 необходимо чтобы выполнялись следующие условия а = b = 1. Теперь необходимо активизировать ветвь r, но при подаче на входы m и n единицы, даная проблема успешно решается.
Так как такие ситуации возникают в различных схемах очень часто, то для их решения применяются различные методы оптимизации алгоритмов распространения и активизации путей.
Принцип рекурсии заключается в том, что, каждый раз, выбирая путь для активизации или распространения неисправности, мы должны записывать все состояния предшествующие данному шагу. Это необходимо для того, чтобы, при возникновении тупиковой ситуации, была возможность, вернутся, в состояние предшествующее неправильному решению.
Рассмотрим D - алгоритм построения детерминированных тестов. Классический D-алгоритм представлен ниже [Roth 1966, Roth и al. 1967].
D_alg()
begin
if Imply_and_check() = FAILURE then
return FAILURE
if (error not at PO) then
begin
if D-frontier = 0 then
return FAILURE
repeat
begin
select an untried gate (G) from D-frontier
c = controlling value of G
assign c to every input of G with value x
if D-alg() = SUCCESS then
return SUCCESS
end
until all gates from D-frontier have been tried
return FAILURE
end
/* error propagated to a PO */
if J-frontier = 0 then
return SUCCESS
select a gate (G) from the J-frontier
c = controlling value of G
repeat
begin
select an input (j) of G with value x
assign c to j
if D-alg() = SUCCESS then
return SUCCESS
assign c to j
/* reverse decision */
end
until all inputs of G are specified
return FAILURE
end
Характерная особенность D-алгоритма - способность распространить ошибки на отдельных повторно сходящихся путях. Эта особенность D-алгоритма называется активизацией многомерного пути [Schneider 1967].
D-алгоритм позволяет строить детерминированные тесты для любых типов неисправностей, но он характеризуется большим числом переборов. Для уменьшения числа переборов был разработан алгоритм PODEM ( Path - Oriented Decision Making) [Goel 1981]. Рассмотрим данный алгоритм .
Пусть целью процедуры является установка значения V на некоторой линии. Тогда значение внешнего входа определяется четностью числа элементов инвертирующего типа вдоль выбранного пути. В случае прохождения элемента со многими входами выбирается один из них. При этом используются следующие правила выбора. Прежде всего, определяется, имеется ли один или несколько вариантов присвоения значений входов вентиля, при которых на его выходе устанавливаются требуемое значение. В случае нескольких вариантов выбирается вход, ближайший к внешнему входу или имеющий лучший показатель управляемости, т.е. наиболее перспективный путь. Если имеется только один вариант, то выбирается вход, наиболее далекий от внешних входов или имеющий худший показатель управляемости, а остальные входы заносятся в стек этой процедуры. Это делается с целью скорейшего обнаружения противоречивых ситуаций. Блок схема этой процедуры представлена на рисунке 1.5. После того как внешний вход в результате этой процедуры получил определенное значение, выполняется импликация. Если в результате импликации цель достигнута (на "целевой" линии устанавливается требуемое значение D или D), то выполняется следующий шаг D распространения. Иначе выполняется возврат назад.
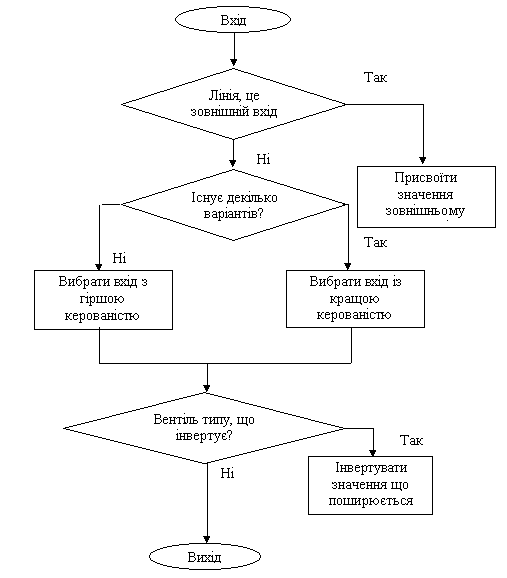
Рисунок 1.5 - Блок схема алгоритма
PODEM
В методе PODEM при построении теста по аналогии с задачами целочисленного программирования используется метод ветвей и границ. Процесс неявного перебора осуществляется на структуре дерева решений, которое представлено на рисунке 1.6.
Рисунок 1.6 - Блок схема неявного
перебора
Структура дерева решений указывает на тот факт, что процесс поиска по алгоритму PODEM основан на прямом неявном переборе всех входных векторов схемы. Как в D-алгоритме, поиск заканчивается, если возникла ситуация ошибки, или в ситуации, когда для неисправности тест не существует. (На практике, время поиска ограничивает сам пользователь при помощи указания ограничениями влияющих на сам процесс поиска решений.)
PODEM отличается от других алгоритмов ГТ лишь в некоторых аспектах. В алгоритме PODEM, значения вычисляются только прямой импликацией входных воздействий. Следовательно, вычисленные значения - всегда согласованы с другими значениями в наборе значений и все значения доопределены. Следовательно, PODEM не нуждается :
Другое важное следствие прямого процесса поиска - то, что это позволяет алгоритму PODEM использовать более простой механизм рекурсивного перебора.
В алгоритмах ГТ восстановление предварительно сохраненных состояний достаточно трудоемкий процесс. В алгоритме PODEM восстановление выполнить проще, так как состояние зависит только от значений первоначальных входов схемы. Таким образом, рекурсивный перебор, выполняемый при моделировании, ускоряет процесс сохранения / восстановления значений.
Из-за этих преимуществ, алгоритм PODEM более простой, чем другие алгоритмы ГТ, и эта простота - главный критерий, способствующий его успеху на практике. Экспериментально было доказано [Goel 1981], что алгоритм PODEM работает гораздо быстрее, чем D - алгоритм, но по-прежнему количество переборов в дереве решений данного алгоритма очень велико, поэтому был разработан алгоритм FAN (Fanout-Oriented TG) [Fujiwara и Shimono 1983].
FAN использует методику алгоритма PODEM, но с небольшими дополнениями:
Внутренние ветви, в которых алгоритм FAN останавливает процедуру обратного прослеживания, определены следующим образом. Ветвь, достигнутая (то есть, непосредственно или косвенно найденная) на последнем шаге является границей. Ветви, которые не связаны с этой границей, являются свободными. Главная ветвь - свободная ветвь, которая непосредственно передает информацию граничной ветви. Например, в схеме рисунка 1.7, A, B, C, E, F, G, H, и J - свободные ветви, K, L, и М - граничные ветви, и H, J - главные ветви. Так как подсхема, передающая главную ветвь l, не разветвляется на выходе, то значение l может быть доопределено без противоречия с любым другим значением, предварительно назначенным в схеме. Таким образом, обратное прослеживание может останавливаться в J, и задача до определения значения l может быть отложена до последней стадии алгоритма ГТ.

Рисунок 1.7
Пример: Для схемы на рисунке 1.7, предположим, что в некоторой точке при выполнении алгоритма PODEM, необходимо установить J = 0. При этом известно, что подача входных воздействий при которых J = 0 приведет к тому, что D-граница, станет пустой, и следовательно, возникнет состояние ошибки. Рисунок 1.8 показывает блок дерева решений алгоритма PODEM, соответствующий этому неудачному поиску.
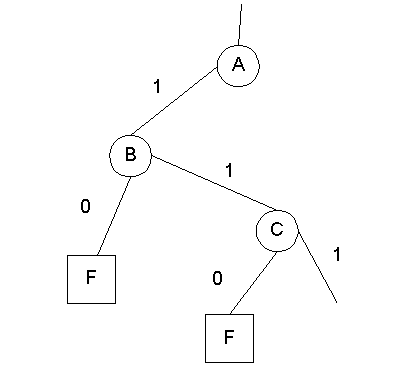
Рисунок 1.8 - Дерево решений алгоритма
PODEM
Алгоритм FAN останавливается на ветви J прежде чем возникнет потребность в до определении и анализирует возможные комбинации. Такой подход ведет к уменьшению дерева решений на рисунке 1.9 .
Рисунок 1.9 - Дерево решений
алгоритма FAN
Повторный вызов задач активизация неисправности и задач распространения ошибки преобразуется в набор задач до определения значений. В алгоритме PODEM для каждой из этих задач запускается процедура обратного до определения, что существенно увеличивает время поиска решения. Для минимизации этого поиска, процедура многомерного возвращения алгоритма FAN (Mbacktrace ) запускается с набором задач (Current_objectives), и предопределенным значением k = vk, которое способствует достижению решения или показывает, что для выбранного подмножества задач единое решение не может быть найдено.
Последняя ситуация может возникнуть только тогда, когда различные задачи - возвращаются к той же самой точке на дереве решений с конфликтным значением (см. рисунок 6.35). Чтобы обнаружить это, Mbacktrace останавливает процедуру обратного прослеживания, когда такая точка достигнута и следит за числом оявлений 0-х и 1-х значений в точке.
Процедура Mbacktrace возвращает каждой конкретной задаче значения до тех пор, пока набора Current_objectives не исчерпается - задачи сгенерированные для главных ветвей схемы сохранены в Head_objectives. Точно так же набор Current_objectives сохраняет установки, достигнутые обратным прослеживанием. После того, как все задачи были оттрасированы, самая сложная точка на дереве решений из списка Stem_objectives проанализирована. Выбор самой сложной точки гарантирует, что все задачи, которые могут зависеть от этой точки на дереве решений, будут доопределены. Если точка k была достигнута с конфликтным значением (и если k невозможно распространять неисправности), то Mbacktrace возвращает (k, vk), где vk - наиболее часто возникающее значение k. Иначе необходимо запустить процедуру обратного прослеживания для k. Если ни одна точка не была достигнута, то Mbacktrace возвращает содержимое списка Head_objectives.
Процедура многомерного прослеживания:
Mbacktrace (Currentobjectives)
begin
repeat
begin
remove one entry (k,Vk) from Current_objectives
if k is ahead line
then add (k,Vh) to Headobjectives
else
if k is a fanout branch then
begin
j = stem(k)
increment number of requests at j for vk
add j to Stem_objectives
endl
else /* continue tracing */
begin
i = inversion of k
c = controlling value of k
if (vk + i = c) then
begin
select an input (j) of k with value x
add (j,c) to Current _ohjectives
end
else
for every input (j) of k with value x
add (j,c ) to Currentobjectives
end
end
until Current objectives == 0
if Stemobjectives =/= 0 then
begin
remove the highest-level stem (k) from Stem_objectives
vk = most requested value of k
if is has contradictory requirements
and k is not reachable from target fault)
then return (k,Vk)
add (k,vk to Current_objectives
return Mbacktrace (Currentobjectives)
end
remove one objective (k,vk) from Headobjectives
return (k,vk)
end
Алгоритм FAN:
FAN()
begin
if Imply_and_check() = FAILURE then return FAILURE
if (error at PO and all bound lines are justified) then
begin
justify all unjustified head lines
return SUCCESS
end
if (error not at PO and D-frontier = 0) then return FAILURE
/* initialize objectives */
add every unjustified bound line to Current_objectives
select one gate (G) from the D-frontier
c = controlling value of G
for every input (j') ofG with value x
add (j,c) to Current_objectives 5
/* multiple backtrace */
(j,vj) = Mbacktrace(Current_objectives)
Assign(i,vi)
if FAN()= SUCCESS then return SUCCESS
Assign(i,Vi) /* reverse decision */
if FAN() = SUCCESS then return SUCCESS
Assign(i,x)
return FAILURE
end
В предыдущих пунктах были рассмотрены уже известные и хорошо апробированные методы построения детерминированных тестов. В данном пункте рассматривается новый метод получения тестовых наборов для логических схем.
Суть метода локальной тестируемости заключается в том, что для каждого элемента логической схемы строится его аналог, Т - модель. Т - элемент выполняет не только те же функции что и исходный элемент, но и ряд дополнительных функций, таких как вычисление тестируемости и наблюдаемости выходов схемы. Для всей логической схемы строится диагностическая оболочка, предназначенная для решения конкретной диагностической задачи. В процессе моделирования этой системы (Т- модели всей логической схемы и диагностической оболочки) на ее выходах появляются и выходные функции логической схемы, и диагностические результаты тестируемой схемы.
Т-элемент строится только один раз, в любой из специализированных САПР, которая позволяет тестировать логические схемы, не прибегая к их сборке. Т - модель всей логической схемы обладает теми же входами Х и выходами У, что и исходный схема, но кроме этих входов Т - модель обладает выходами тестируемости, которые показывают, какие неисправности тестируются на данном входном наборе. В результате подачи разных тестовых наборов на входы логической схемы на ее выходах тестируемости получается список неисправностей, которые обнаруживаются или не обнаруживаются в результате моделирования. Из этого списка, можно сформировать тест минимальной длины, покрывающий максимальное количество неисправностей схемы.
При данном подходе к решению диагностических задач необходимо учитывать связность неисправностей, т.е. необходимо учитывать эквивалентность, подчиненность и совмещаем ость неисправностей, для минимизации входного теста.
Такова основная идея данного метода. Модели исходного и эквивалентного ему Т - элемента изображены на рисунке 1.10.
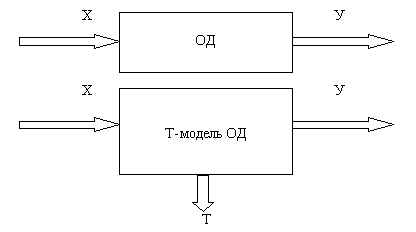
Рисунок 1.10 - Объект диагностики и его Т-модель
|
|