
Моделирование динамических процессов в распределенных базах данных компьютерных информационных систем
Кафедра: АСУ
Руководитель: к.т.н. Лаздынь С.В.
Становление систем управления базами данных совпало по времени со значительными успехами в развитии технологий распределенных вычислений и параллельной обработки. В результате возникли системы управления распределенными базами данных. Именно эти системы становятся доминирующими инструментами для создания приложений интенсивной обработки данных. В среде распределенных СУБД упрощается решение вопросов, связанных с возрастанием объема баз данных или потребностей обработки. При этом редко возникает необходимость в серьезной перестройке системы; расширение возможностей обычно достигается за счет добавления процессорных мощностей или памяти.
В идеале распределенная СУБД обладает свойством линейной расширяемости и линейного ускорения. Под линейной расширяемостью понимается сохранение того же уровня производительности при увеличении размера базы данных и одновременном пропорциональном увеличении процессорной мощности и объема памяти. Линейное ускорение означает, что с наращиванием процессорной мощности и объема памяти при сохранении прежнего размера базы данных пропорционально возрастает производительность. Причем при расширении системы потребуется минимальная реорганизация существующей базы данных.
С учетом соотношения цена/производительность для микропроцессоров и рабочих станций экономически выгоднее оказывается составить систему из нескольких небольших компьютеров, чем реализовать ее на эквивалентной по мощности одной большой машине. Множество коммерческих распределенных СУБД функционируют на мини-компьютерах и рабочих станциях именно по причине более выгодного соотношения цена/производительность. Технологии, основанные на применении рабочих станций, получили столь широкое распространение благодаря тому, что большинство коммерческих СУБД способны работать в рамках локальных сетей, где в основном и используются рабочие станции. Развитие распределенных СУБД, предназначенных для глобальных сетей WAN, может привести к повышению роли мэйнфреймов. С другой стороны, распределенные СУБД будущих поколений, скорее всего, будут поддерживать иерархические сетевые структуры, состоящие из кластеров, в пределах которых компьютеры взаимодействуют на базе локальной сети, а сами кластеры соединяются между собой посредством высокоскоростных магистралей.
Все эти причины привели к бурному развитию технологий распределенных баз данных информационных систем. Однако остаются нерешенными некоторые сложные вопросы связанные с данной темой. Один из этих вопросов - динамические процессы в распределенных базах данных.
Анализ состояния исследуемого вопроса.
Объект и предмет исследования.
Объектом исследования является распределенная база данных компьютерных информационных систем.
Предметом исследования является влияние динамических процессов на функционирование распределенной базы данных.
Распределенная база данных (РБД) -- это совокупность логически взаимосвязанных баз данных, распределенных в компьютерной сети.
Другими словами, системы распределенных баз данных состоят из набора узлов, связанных вместе коммуникационной сетью, в которой:
- 1)
- каждый узел обладает своими собственными системами баз данных;
- 2)
- узлы работают согласованно, поэтому пользователь может получить доступ к данным на любом узле сети, как будто все данные находятся на его собственном узле.

Система управления распределенной базой данных (РСУБД) -- это программная система, которая обеспечивает управление распределенной базой данных таким образом, чтобы ее распределенность была прозрачна для пользователей.
Эти определения можно дополнить, если рассмотреть также различные характеристики РБД и РСУБД. В 1981г К. Дейт опубликовал свои правила для распределенных баз данных1. Ниже приведены эти 12 правил.
- Локальная автономность. Локальные данные должны находиться под локальным владением и управлением, включая функции безопасности, целостности, представления данных в памяти. Исключением может быть ситуация, когда ограничения целостности охватывают данные нескольких узлов или когда управление распределенной транзакцией осуществляется некоторым внешним узлом.
- Никакой конкретный сервис не должен возлагаться на какой-либо специально выделенный центральный узел. Соблюдение этого правила, т.е. принципа децентрализированности функций РСУБД, позволяет избежать узких мест.
- Непрерывность функционирования. Система не должна останавливаться в случае необходимости добавления нового узла или удаления в распределенной среде некоторых данных, изменения определения метаданных и даже (что довольно сложно) осуществления перехода к новой версии СУБД на отдельном узле.
- Независимость от местоположения. Пользователи и приложения не обязаны знать о том, где физически располагаются данные.
- Независимость от фрагментации. Фрагменты (называемые также разделами) данных должны поддерживаться и обрабатываться средствами РСУБД таким образом, чтобы пользователи или приложения могли бы вообще ничего не знать об этом. Более того, РСУБД должна уметь обходить при обработке запросов фрагменты, не имеющие к ним отношения.
- Независимость от тиражирования. Те же принципы независимости и прозрачности относятся и к механизму тиражирования.
- Распределенная обработка запросов. Обработка запросов должна производиться распределенным образом.
- Управление распределенными транзакциями. На распределенные базы данных необходимо распространить механизмы управления транзакциями и управления одновременным доступом. Эта проблема включает выявление и разрешение тупиковых ситуаций, прерывания по истечении временных интервалов, фиксацию и откат распределенных транзакций, а также ряд других вопросов.
- Независимость от оборудования. Одно и то же программное обеспечение РСУБД должно выполняться на различных аппаратных платформах и функционировать в системе в качестве равноправного партнера. На практике достичь этого исключительно сложно, поскольку многие поставщики поддерживают множество платформ. Это ограничение преодолевается с помощью модели много-продуктовых сред.
- Независимость от операционных систем. Эта проблема тесно связана с предыдущей, и она также разрешается аналогичным образом.
- Независимость от сети. Узлы могут быть связаны между собой с помощью множества разнообразных сетевых и коммуникационных средств. Многоуровневая модель, присущая многим современным информационным системам (например, семиуровневая модель OSI, модель TCP/IP, уровни SNA и DECnet), обеспечивает решение этой проблемы не только в среде РБД, но и для информационных систем вообще.
- Независимость от СУБД. Локальные СУБД должны иметь возможность участвовать в функционировании РСУБД.
Анализ технологий организации РБД.
База данных физически распределяется по узлам данных при помощи фрагментации и репликации, или тиражирования, данных.
Фрагментация данных.
Отношения, принадлежащие реляционной базе данных, могут быть фрагментированы на горизонтальные или вертикальные разделы.
Горизонтальная фрагментация реализуется при помощи операции селекции, которая направляет каждый кортеж отношения в один из разделов, руководствуясь предикатом фрагментации. Например, для отношения Employee (Сотрудник) возможна фрагментация в соответствии с территориальным распределением рабочих мест сотрудников.
Тогда запрос ``получить информацию о сотрудниках компании'' может быть сформулирован так:
SELECT * FROM employee@donetsk, employee@kiev
При вертикальной фрагментации отношение делится на разделы при помощи операции проекции. Например, один раздел отношения Employee может содержать поля Номер_сотрудника (emp_id), ФИО_сотрудника (emp_name), Адрес_сотрудника (emp_adress), а другой -- поля Номер_сотрудника (emp_id), Оклад (salary), Руководитель (emp_chief).
Тогда запрос ``получить информацию о заработной плате сотрудников компании'' будет выглядеть следующим образом:
SELECT employee.emp_id, emp_name, salary FROM employee@donetsk, employee@kiev ORDER BY emp_id
За счет фрагментации данные приближаются к месту их наиболее интенсивного использования, что потенциально снижает затраты на пересылки; уменьшаются также размеры отношений, участвующих в пользовательских запросах.
Репликация данных.
Второй способ распределения данных -- репликация. Репликация (или тиражирование) означает создание дубликатов данных. Репликаты -- это множество различных физических копий некоторого объекта базы данных (обычно таблицы), для которых поддерживается синхронизация (идентичность) с некоторой ``главной'' копией. Теоретически значения всех данных в тиражированных объектах должны автоматически и незамедлительно синхронизироваться друг с другом. (На практике это правило обычно несколько ослабляется.) В некоторых системах копии используются исключительно в режиме чтения и обновляются в соответствии с заданным расписанием. В других средах допускается модификация отдельных значений в копиях, и эти изменения распространяются в соответствии с процедурами планирования и координации. На рисунке 4 показаны различные модели тиражирования.
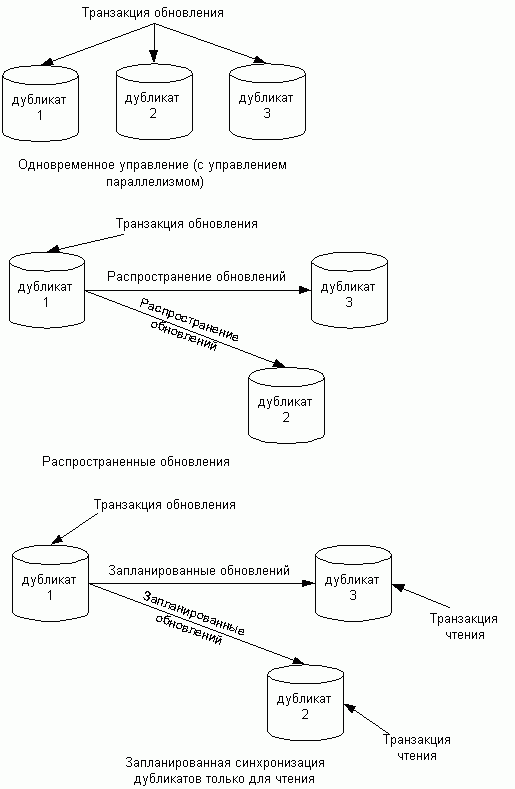
При репликации фрагменты данных тиражируются с учетом спроса на доступ к ним. Это полезно, если доступ к одним и тем же данным нужен из приложений, выполняющихся на разных узлах. В таком случае, с точки зрения экономии затрат, более эффективно будет поддерживать копии данных на всех узлах, чем непрерывно пересылать данные между узлами.
Основной проблемой репликации данных является то, что обновление любого логического объекта должно распространяться на все хранимые копии этого объекта. Трудности возникают из-за того, что некоторый узел, содержащий данный объект, может быть недоступен (например, из-за краха системы или данного узла) именно в момент обновления. В таком случае очевидная стратегия немедленного распространения обновлений на все копии может оказаться неприемлемой, поскольку предполагается, что обновление (а значит и исполнение транзакции) будет провалено, если одна из копий будет недоступна в текущий момент.
Каталог распределенной системы.
Важным компонентом структуры логического уровня РБД является сетевой каталог, который обеспечивает эффективное выполнение основных функций управления РБД и содержит всю информацию, необходимую для обеспечения независимости размещения, фрагментации и репликации. Существует несколько вариантов хранения системного каталога. Ниже перечислены некоторые из этих вариантов.
- Централизированный каталог. Весь каталог храниться в одном месте, т.е. на центральном узле.
- Полностью реплицированный каталог. Весь каталог полностью хранится на каждом узле.
- Секционированный каталог. На каждом узле содержится его собственный каталог для объектов, хранимых на этом узле. Общий каталог является объединением всех разъединенных локальных каталогов.
- Комбинация первого и третьего вариантов. На каждом узле содержится его собственный каталог (как в п.3), кроме того, на одном центральном узле хранится унифицированная копия всех этих локальных каталогов (как в п.1).
Для каждого подхода характерны определенные недостатки и проблемы. В первом подходе, очевидно, не достигается "независимость от центрального узла". Во втором утрачивается автономность функционирования, поскольку при обновлении каждого каталога это обновление придется распространять на каждый узел. В третьем выполнение не локальных операций становится весьма дорогостоящим (для поиска удаленного объекта потребуется в среднем осуществить доступ к половине имеющихся узлов). Четвертый подход более эффективен, чем третий (для поиска удаленного объекта потребуется осуществить доступ только к одному удаленному каталогу), но в нем снова не достигается ``независимость от центрального узла''.
Примеры распределенных систем.
Сегодня практически все крупнейшие производители СУБД предлагают решения в области управления распределенными ресурсами. Однако все эти решения поддерживают ограниченные функции построения неоднородных распределенных систем.
Среди многочисленных прототипов и научно-исследовательских систем следует упомянуть систему SDD-1, созданную в конце 70-х -- начале 80-х годов в научно-исследовательском отделении фирмы Computer Corporation of America; систему R*, которая является распределенной версией системы System R и создана в начале 80-х годов фирмой IBM; а также систему Distributed INGRES, которая является распределенной версией системы INGRES и создана также в начале 80-х годов в Калифорнийском университете в Беркли.
Что касается коммерческих продуктов, то в настоящее время в большинстве реляционных систем предусмотрены разные виды поддержки использования распределенных баз данных с разной степенью функциональности. Среди таких систем наиболее известны система INGRES/STAR отделения Ingres Division фирмы The ASK Group Inc., система ORACLE фирмы Oracle Corporation, а также модуль распределенной работы системы DB2 фирмы IBM.
Анализ методов моделирования РБД.
РБД стали в настоящее время объектом всестороннего исследования. При этом наряду с принципами конструирования и организации, алгоритмами действия большое внимание уделяется методам анализа качества работы РБД, а также исследованию закономерностей их функционирования и взаимосвязи качества работы с особенностями конструктивных и алгоритмических решений.
Однако ввиду исключительной сложности РБД как объекта формального описания и расчета до настоящего времени априорная оценка ожидаемого эффекта от тех или иных конструктивных и алгоритмических решений, а следовательно, и от капиталовложений, необходимых для их реализации, обычно базируется на общих качественных соображениях, не подкрепленных расчетом, когда влияние отдельных факторов оценивается интуитивно, и возможны грубые ошибки. Для практически убедительного суждения о качестве работы РБД с позиции потребителя необходимо оценить пусть с ограниченной, но заранее известной точностью функции распределения вероятностей параметров работы ИС.
Реальные сложные системы можно исследовать с помощью двух типов математических моделей: аналитических и имитационных. В аналитических моделях поведение систем записывается в виде некоторых функциональных соотношений или логических условий. Наиболее полное исследование удается провести в том случае, когда получены явные зависимости, связывающие искомые величины с параметрами исследуемых объектов и начальными условиями его изучения. Однако это удается выполнить только для сравнительно простых систем. Для РБД, которая является сложной системой, нам придется идти на упрощения представления реальных явлений, дающие возможность описать их поведение и представить взаимодействия между компонентами распределенной системы. Для построения аналитических моделей имеется мощный математический аппарат (алгебра, функциональный анализ, разностные уравнения, теория вероятностей, математическая статистика, теория массового обслуживания и т.д.).
Аналитические модели распределенных баз данных предложены в ряде работ изданных в начале 90-х годов. В своей книге [Cegel90] Г. Г. Цегелик рассмотрел несколько моделей РБД. Эти модели различаются разными подходами к их построению и выбранными топологиями. Эти модели позволяют оптимизировать распределение объектов РБД по узлам распределенной системы. Однако они построены при некоторых, очень значительных, упрощениях. Самое существенное из них -- это то, что эти модели статичны. Т.е. они не учитывают влияние динамических процессов в РБД. Это приводит к неточности модели и мы не в состоянии измерить степень этой неточности.
Аналитическую модель также рассматривают А. Г. Мамиконов, В. В. Кульба и др. Для этой модели характерны те же недостатки что и для модели, предложенной Г. Г. Цегеликом.
Основными методами расчета параметров работы ИС, используемыми в настоящее время, являются методы теории массового обслуживания и, имитационного моделирования. Применение их при ряде упрощающих допущений на законы распределения времени возникновения запросов, их объема, структуру системы и т.п. позволяет наряду с оценками времени передачи информации получить значения многих других характеристик РБД -- оценить длины очередей, вероятности отказа в обслуживании и т.п.
Однако методы теории массового обслуживания достаточно сложны и не могут в настоящее время использоваться для расчета временных характеристик в реальных РБД с большим числом узлов и каналов связи. Также при помощи теории массового обслуживания трудно предусмотреть все специфичные моменты работы реальных РБД. Поэтому для исследования предпочтительней использовать имитационное моделирование.
В имитационной модели поведение компонент объекта описывается набором алгоритмов, которые затем реализуют ситуации, возникающие в реальной системе. Моделирующие алгоритмы позволяют по исходным данным, содержащим сведения о начальном состоянии объекта, и фактическим значениям параметров системы отобразить реальные явления в системе и получить сведения о возможном поведении объекта для данной конкретной ситуации.
При всех преимуществах данного подхода автору неизвестны примеры
использования методов имитационного моделирования для расчета параметров
функционирования РБД в компьютерных информационных системах.
Заметки:
- ... данных1
- Эти правила были сформулированы К. Дейтом в его статье "What Is Distributed Database System?", опубликованной в сборнике C. D. Date, Relational Database Writtings 1985-1989. Reading. Mass.: Addison-Wesley (1990). К. Дейт цитирует ключевые моменты этой работы в шестом издании своей знаменитой хрестоматии
Ссылки:
-
Распределенные и параллельные системы баз данных
М. Тамер Оззу, Патрик Валдуриз -
Распределенные информационные системы и базы данных
Глеб Ладыженский -
Параллельные архитектуры серверов баз данных
Г.Г. Барон, СУБД # 2 1995 -
Параллельные системы баз данных: будущее высоко эффективных систем баз данных
Д. Девитт, Д. Грэй, СУБД # 2 1995 -
Объектные технологии построения распределенных информационных систем
Ю.Пуха, СУБД # 3 1997 -
Асинхронное тиражирование данных в гетерогенных средах
Б.О.Калиниченко, СУБД # 3 1996