Источник:
А.А. Букатов, В.Н. Дацюк, А.И. Жегуло. "Программирование многопроцессорных вычислительных систем".
http://rsusu1.rnd.runnet.ru/tutor/method/book.pdf
Часть 1. ВВЕДЕНИЕ В АРХИТЕКТУРЫ И СРЕДСТВА ПРОГРАММИРОВАНИЯ МНОГОПРОЦЕССОРНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Глава 1. ОБЗОР АРХИТЕКТУР МНОГОПРОЦЕССОРНЫХ
ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
В процессе развития суперкомпьютерных технологий идею
повышения производительности вычислительной системы за счет
увеличения числа процессоров использовали неоднократно. Если не
вдаваться в исторический экскурс и обсуждение всех таких попыток, то
можно следующим образом вкратце описать развитие событий.
Экспериментальные разработки по созданию многопроцессорных
вычислительных систем начались в 70-х годах 20 века. Одной из первых
таких систем стала разработанная в Иллинойском университете МВС
ILLIAC IV, которая включала 64 (в проекте до 256) процессорных
элемента (ПЭ), работающих по единой программе, применяемой к
содержимому собственной оперативной памяти каждого ПЭ. Обмен
данными между процессорами осуществлялся через специальную матрицу
коммуникационных каналов. Указанная особенность коммуникационной
системы дала название "матричные суперкомпьютеры" соответствующему
классу МВС. Отметим, что более широкий класс МВС с распределенной
памятью и с произвольной коммуникационной системой получил
впоследствии название "многопроцессорные системы с массовым
параллелизмом", или МВС с MPP-архитектурой (MPP – Massively
Parallel Processing). При этом, как правило, каждый из ПЭ MPP системы
является универсальным процессором, действующим по своей
собственной программе (в отличие от общей программы для всех ПЭ
матричной МВС).
Первые матричные МВС выпускались буквально поштучно, поэтому
их стоимость была фантастически высокой. Серийные же образцы
подобных систем, такие как ICL DAP, включавшие до 8192 ПЭ, появились
значительно позже, однако не получили широкого распространения ввиду
сложности программирования МВС с одним потоком управления (с одной
программой, общей для всех ПЭ ).
Первые промышленные образцы мультипроцессорных систем
появились на базе векторно-конвейерных компьютеров в середине 80-х
годов. Наиболее распространенными МВС такого типа были
суперкомпьютеры фирмы Cray. Однако такие системы были чрезвычайно
дорогими и производились небольшими сериями. Как правило, в подобных
компьютерах объединялось от 2 до 16 процессоров, которые имели
равноправный (симметричный) доступ к общей оперативной памяти. В
связи с этим они получили название симметричные мультипроцессорные
системы (Symmetric Multi-Processing – SMP).
Как альтернатива таким дорогим мультипроцессорным системам на
базе векторно-конвейерных процессоров была предложена идея строить
эквивалентные по мощности многопроцессорные системы из большого
числа дешевых серийно выпускаемых микропроцессоров. Однако очень
скоро обнаружилось, что SMP архитектура обладает весьма
ограниченными возможностями по наращиванию числа процессоров в
системе из-за резкого увеличения числа конфликтов при обращении к
общей шине памяти. В связи с этим оправданной представлялась идея
снабдить каждый процессор собственной оперативной памятью,
превращая компьютер в объединение независимых вычислительных узлов.
Такой подход значительно увеличил степень масштабируемости
многопроцессорных систем, но в свою очередь потребовал разработки
специального способа обмена данными между вычислительными узлами,
реализуемого обычно в виде механизма передачи сообщений (Message
Passing). Компьютеры с такой архитектурой являются наиболее яркими
представителями MPP систем. В настоящее время эти два направления
(или какие-то их комбинации ) являются доминирующими в развитии
суперкомпьютерных технологий.
Нечто среднее между SMP и MPP представляют собой NUMA-архитектуры (Non Uniform Memory Access), в которых память
физически разделена, но логически общедоступна. При этом время доступа
к различным блокам памяти становится неодинаковым. В одной из первых
систем этого типа Cray T3D время доступа к памяти другого процессора
было в 6 раз больше, чем к своей собственной.
В настоящее время развитие суперкомпьютерных технологий идет
по четырем основным направлениям: векторно-конвейерные
суперкомпьютеры, SMP системы, MPP системы и кластерные системы.
Рассмотрим основные особенности перечисленных архитектур.
1.1. Векторно-конвейерные суперкомпьютеры
Первый векторно-конвейерный компьютер Cray-1 появился в 1976
году. Архитектура его оказалась настолько удачной, что он положил
начало целому семейству компьютеров. Название этому семейству
компьютеров дали два принципа, заложенные в архитектуре процессоров:
- конвейерная организация обработки потока команд
- введение в систему команд набора векторных операций, которые
позволяют оперировать с целыми массивами данных [2].
Длина одновременно обрабатываемых векторов в современных
векторных компьютерах составляет, как правило, 128 или 256 элементов.
Очевидно, что векторные процессоры должны иметь гораздо более
сложную структуру и по сути дела содержать множество арифметических
устройств. Основное назначение векторных операций состоит в
распараллеливании выполнения операторов цикла, в которых в основном и
сосредоточена большая часть вычислительной работы. Для этого циклы
подвергаются процедуре векторизации с тем, чтобы они могли
реализовываться с использованием векторных команд. Как правило, это
выполняется автоматически компиляторами при изготовлении ими
исполнимого кода программы. Поэтому векторно-конвейерные
компьютеры не требовали какой-то специальной технологии
программирования, что и явилось решающим фактором в их успехе на
компьютерном рынке. Тем не менее, требовалось соблюдение некоторых
правил при написании циклов с тем, чтобы компилятор мог их эффективно
векторизовать.
Исторически это были первые компьютеры, к которым в полной
мере было применимо понятие суперкомпьютер. Как правило, несколько
векторно-конвейерных процессоров (2-16) работают в режиме с общей
памятью (SMP), образуя вычислительный узел, а несколько таких узлов
объединяются с помощью коммутаторов, образуя либо NUMA, либо MPP
систему. Типичными представителями такой архитектуры являются
компьютеры CRAY J90/T90, CRAY SV1, NEC SX-4/SX-5. Уровень
развития микроэлектронных технологий не позволяет в настоящее время
производить однокристальные векторные процессоры, поэтому эти
системы довольно громоздки и чрезвычайно дороги. В связи с этим,
начиная с середины 90-х годов, когда появились достаточно мощные
суперскалярные микропроцессоры, интерес к этому направлению был в
значительной степени ослаблен. Суперкомпьютеры с векторно-
конвейерной архитектурой стали проигрывать системам с массовым
параллелизмом . Однако в марте 2002 г. корпорация NEC представила
систему Earth Simulator из 5120 векторно-конвейерных процессоров,
которая в 5 раз превысила производительность предыдущего обладателя
рекорда – MPP системы ASCI White из 8192 суперскалярных
микропроцессоров. Это, конечно же, заставило многих по-новому
взглянуть на перспективы векторно-конвейерных систем.
1.2. Симметричные мультипроцессорные системы (SMP)
Характерной чертой многопроцессорных систем SMP архитектуры
является то, что все процессоры имеют прямой и равноправный доступ к
любой точке общей памяти. Первые SMP системы состояли из нескольких
однородных процессоров и массива общей памяти, к которой процессоры
подключались через общую системную шину. Однако очень скоро
обнаружилось, что такая архитектура непригодна для создания сколь либо
масштабных систем. Первая возникшая проблема – большое число
конфликтов при обращении к общей шине. Остроту этой проблемы
удалось частично снять разделением памяти на блоки, подключение к
которым с помощью коммутаторов позволило распараллелить обращения
от различных процессоров. Однако и в таком подходе неприемлемо
большими казались накладные расходы для систем более чем с 32-мя
процессорами.
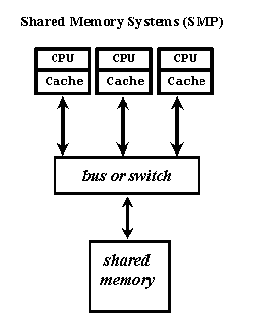
Современные системы SMP архитектуры состоят, как правило, из
нескольких однородных серийно выпускаемых микропроцессоров и
массива общей памяти, подключение к которой производится либо с помощью
общей шины, либо с помощью коммутатора (рис. 1.1).
Рис. 1.1. Архитектура симметричных мультипроцессорных систем.
Наличие общей памяти значительно упрощает организацию взаимодействия процессоров
между собой и упрощает программирование, поскольку параллельная программа
работает в едином адресном пространстве. Однако за этой кажущейся простотой скрываются большие проблемы, рисущие системам этого типа. Все они так или иначе, связаны с оперативной памятью. Дело в том, что в настоящее время даже в
однопроцессорных системах самым узким местом является оперативная
память, скорость работы которой значительно отстала от скорости работы
процессора. Для того чтобы сгладить этот разрыв, современные
процессоры снабжаются скоростной буферной памятью (кэш-памятью),
скорость работы которой значительно выше, чем скорость работы
основной памяти. В качестве примера приведем данные измерения
пропускной способности кэш-памяти и основной памяти для
персонального компьютера на базе процессора Pentium III 1000 Мгц. В
данном процессоре кэш-память имеет два уровня:
- L1 (буферная память команд ) – объем 32 Кб, скорость обмена 9976 Мб /сек;
- L2 (буферная память данных ) – объем 256 Кб, скорость обмена 4446 Мб /сек.
Очевидно, что при проектировании многопроцессорных систем эти
проблемы еще более обостряются. Помимо хорошо известной проблемы конфликтов
при обращении к общей шине памяти возникла и новая
проблема, связанная с иерархической структурой организации памяти
современных компьютеров. В многопроцессорных системах, построенных
на базе микропроцессоров со встроенной кэш-памятью, нарушается
принцип равноправного доступа к любой точке памяти. Данные,
находящиеся в кэш-памяти некоторого процессора, недоступны для других
процессоров. Это означает, что после каждой модификации копии
некоторой переменной, находящейся в кэш-памяти какого-либо
процессора, необходимо производить синхронную модификацию самой
этой переменной, расположенной в основной памяти.
С большим или меньшим успехом эти проблемы решаются в рамках
общепринятой в настоящее время архитектуры ccNUMA (cache coherent Non
Uniform Memory Access). В этой архитектуре память физически
распределена, но логически общедоступна. Это, с одной стороны,
позволяет работать с единым адресным пространством, а, с другой,
увеличивает масштабируемость систем. Когерентность кэш-памяти
поддерживается на аппаратном уровне, что не избавляет, однако, от
накладных расходов на ее поддержание. В отличие от классических SMP
систем память становится трехуровневой:
- кэш-память процессора;
- локальная оперативная память;
- удаленная оперативная память;
Время обращения к различным уровням может отличаться на порядок, что
сильно усложняет написание эффективных программ для таких систем.
Перечисленные обстоятельства значительно ограничивают
возможности по наращиванию производительности ccNUMA систем путем
простого увеличения числа процессоров. Тем не менее эта технология
позволяет в настоящее время создавать системы, содержащие до 256
процессоров с общей производительностью порядка 200 млрд. операций в
секунду. Системы этого типа серийно производятся многими
компьютерными фирмами как многопроцессорные серверы с числом
процессоров от 2 до 128 и прочно удерживают идерство в классе малых
суперкомпьютеров. Типичными представителями данного класса
суперкомпьютеров являются компьютеры SUN StarFire 15K, SGI Origin
3000, HP Superdome. Хорошее иписание одной из наиболее удачных
систем этого типа – компьютера Superdome фирмы Hewlett-Packard -
можно найти в книге [3]. Неприятным свойством SMP систем является то ,
что их стоимость растет быстрее, чем производительность при увеличении
числа процессоров в системе. Кроме того, из-за задержек при обращении к
общей памяти неизбежно взаимное торможение при параллельном
выполнении даже независимых программ.
1.3. Системы с массовым параллелизмом (МРР)
Проблемы, присущие многопроцессорным системам с общей памятью,
простым и естественным образом устраняются в системах с массовым
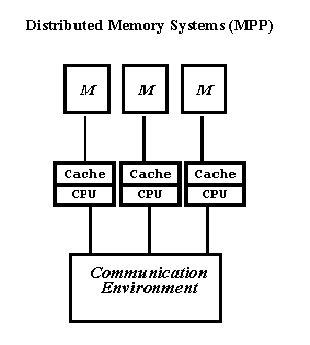
параллелизмом. Компьютеры этого типа представляют собой
многопроцессорные системы с распределенной памятью, в которых с
помощью некоторой коммуникационной среды объединяются однородные
вычислительные узлы (рис. 1.2).
Рис. 1.2. Архитектура систем с распределенной памятью.
Каждый из узлов состоит из одного или нескольких процессоров,
собственной оперативной памяти, коммуникационного оборудования,
подсистемы ввода /вывода, т. е. обладает всем необходимым для
независимого функционирования . При этом на каждом узле может
функционировать либо полноценная операционная система (как в системе
RS/6000 SP2), либо урезанный вариант, поддерживающий только
базовые функции ядра, а полноценная ОС работает на специальном
управляющем компьютере (как в системах Cray T3E, nCUBE2).
Процессоры в таких системах имеют прямой доступ только
к своей локальной памяти. Доступ к памяти других узлов реализуется обычно с
помощью механизма передачи сообщений. Такая архитектура
вычислительной системы устраняет одновременно как проблему
конфликтов при обращении к памяти, так и проблему когерентности кэш-памяти.
Это дает возможность практически неограниченного наращивания
числа процессоров в системе, увеличивая тем самым ее
производительность. Успешно функционируют MPP с сотням и
тысячами процессоров (ASCI White – 8192, Blue Mountain – 6144).
Производительность наиболее мощных систем достигает 10 триллионов
оп /сек (10 Tflops). Важным свойством MPP систем является их высокая
степень масштабируемости. В зависимости от вычислительных
потребностей для достижения необходимой производительности требуется
просто собрать систему с нужным числом узлов.
На практике все, конечно, гораздо сложнее. Устранение одних проблем,
как это обычно бывает, порождает другие. Для MPP систем на
первый план выходит проблема эффективности коммуникационной среды.
Легко сказать: "Давайте соберем систему из 1000 узлов". Но каким
образом соединить в единое целое такое множество узлов? Самым
простым и наиболее эффективным было бы соединение каждого
процессора с каждым. Но тогда на каждом узле было бы 999
коммуникационных каналов, желательно двунаправленных. Очевидно, что
это нереально. Различные производители MPP систем использовали
разные топологии. В компьютерах Intel Paragon процессоры
образовывали прямоугольную двумерную сетку. Для этого в каждом узле
достаточно четырех коммуникационных каналов. В компьютерах Cray
T3D/T3E использовалась топология трехмерного тора. Соответственно, в
узлах этого компьютера было шесть коммуникационных каналов. Фирма
nCUBE использовала в своих компьютерах топологию n-мерного
гиперкуба. Подробнее на э ой топологии мы остановимся в главе 4 при
изучении суперкомпьютера nCUBE2. Каждая из рассмотренных
топологий имеет свои преимущества и недостатки. Отметим, что при
обмене данными между процессорами, не являющимися ближайшими
соседями, происходит трансляция данных через промежуточные узлы.
Очевидно, что в узлах должны быть предусмотрены какие-то аппаратные
средства, которые освобождали бы центральный процессор от участия в
трансляции данных. В последнее время для соединения вычислительных
узлов чаще используется иерархическая система высокоскоростных
коммутаторов, как это впервые было реализовано в компьютерах IBM
SP2. Такая топология дает возможность прямого обмена данными между
любыми узлами, без участия в этом промежуточных узлов.
Системы с распределенной памятью идеально подходят для пареллельного
выполнения независимых программ, поскольку при том
каждая программа выполняется на своем узле и никаким образом не влияет
на выполнение других программ. Однако при разработке параллельных
программ приходится учитывать более сложную, чем в SMP системах,
организацию памяти. Оперативная память в MPP системах имеет 3-х
уровневую структуру:
- кэш-память процессоров;
- локальная оперативная память;
- оперативная память других узлов.
При этом отсутствует возможность прямого доступа к данным, расположенным
в других узлах. Для их использования эти данные должны
быть предварительно переданы в тот узел, который в данный момент в них
нуждается. Это значительно усложняет программирование. Кроме того,
обмены данными между узлами выполняются значительно медленнее, чем
обработка данных в локальной оперативной памяти узлов. Поэтому
написание эффективных параллельных программ для таких компьютеров
представляет собой более сложную задачу, чем для SMP систем.
1.4. Кластерные системы
Кластерные технологии стали логическим продолжением развития
идей, заложенных в архитектуре MPP систем. Если процессорный модуль
в MPP системе представляет собой законченную вычислительную систему,
то следующий шаг напрашивается сам собой: почему бы в качестве таких
вычислительных узлов не использовать обычные серийно выпускаемые
компьютеры. Развитие коммуникационных технологий, а именно,
появление высокоскоростного сетевого оборудования и специального
программного обеспечения, такого как система MPI (см. часть 2),
реализующего механизм передачи сообщений над стандартными сетевыми
протоколами, сделали кластерные технологии общедоступными. Сегодня
не составляет большого труда создать небольшую кластерную систему,
объединив вычислительные мощности компьютеров отдельной
лаборатории или учебного класса.
Привлекательной чертой кластерных технологий является то, что
они позволяют для достижения необходимой производительности
объединять в единые вычислительные системы компьютеры самого
разного типа, начиная от персональных компьютеров и заканчивая
мощными суперкомпьютерами. Широкое распространение кластерные
технологии получили как средство создания систем суперкомпьютерного
класса из составных частей массового производства, что значительно
удешевляет стоимость вычислительной системы. В частности, одним из
первых был реализован проект COCOA [4], в котором на базе 25
двухпроцессорных персональных компьютеров общей стоимостью
порядка $100000 была создана система с производительностью,
эквивалентной 48-процессорному Cray T3D стоимостью несколько
миллионов долларов США.
Конечно, о полной эквивалентности этих систем говорить не
приходится. Как указывалось в предыдущем разделе, производительность
систем с распределенной памятью очень сильно зависит от производительности
коммуникационной среды. Коммуникационную среду можно
достаточно полно охарактеризовать двумя параметрами: латентностью – временем
задержки при посылке сообщения и пропускной
способностью – скоростью передачи информации. Так вот для
компьютера Cray T3D эти параметры составляют соответственно 1 мкс и
480 Мб /сек, а для кластера, в котором в качестве коммуникационной среды
использована сеть Fast Ethernet, 100 мкс и 10 Мб /сек. Это отчасти
объясняет очень высокую стоимость суперкомпьютеров. При таких
параметрах, как у рассматриваемого кластера, найдется не так много задач,
которые могут эффективно решаться на достаточно большом числе
процессоров.
Если говорить кратко, то кластер – это связанный набор
полноценных компьютеров, используемый в качестве единого
вычислительного ресурса. Преимущества кластерной системы перед
набором независимых компьютеров очевидны. Во-первых, разработано
множество диспетчерских систем пакетной обработки заданий,
позволяющих послать задание на обработку кластеру в целом, а не какому-то
отдельному компьютеру. Эти диспетчерские системы автоматически
распределяют задания по свободным вычислительным узлам или
буферизуют их при отсутствии таковых, что позволяет обеспечить более
равномерную и эффективную загрузку компьютеров. Во-вторых,
появляется возможность совместного использования вычислительных
ресурсов нескольких компьютеров для решения одной задачи.
Для создания кластеров обычно используются либо простые
однопроцессорные персональные компьютеры, либо двух- или
четырехпроцессорные SMP-серверы. При этом не накладывается никаких
ограничений на состав и архитектуру узлов. Каждый из узлов может
функционировать под управлением своей собственной операционной
системы. Чаще всего используются стандартные ОС: Linux, FreeBSD,
Solaris, Tru64 Unix, Windows NT. В тех случаях, когда узлы кластера
неоднородны, то говорят о гетерогенных кластерах.
При создании кластеров можно выделить два подхода. Первый
подход применяется при создании небольших кластерных систем. В
кластер объединяются полнофункциональные компьютеры, которые
продолжают работать и как самостоятельные единицы, например,
компьютеры учебного класса или рабочие станции лаборатории. Второй
подход применяется в тех случаях, когда целенаправленно создается
мощный вычислительный ресурс. Тогда системные блоки компьютеров
компактно размещаются в специальных стойках, а для управления
системой и для запуска задач выделяется один или несколько
полнофункциональных компьютеров, называемых хост-компьютерами.
В этом случае нет необходимости снабжать компьютеры вычислительных
узлов графическими картами, мониторами, дисковыми накопителями и
другим периферийным оборудованием, что значительно удешевляет
стоимость системы.
Разработано множество технологий соединения компьютеров в
кластер. Наиболее широко в данное время используется технология Fast
Ethernet. Это обусловлено простотой ее использования и низкой
стоимостью коммуникационного оборудования. Однако за это приходится
расплачиваться заведомо недостаточной скоростью обменов. В самом
деле, это оборудование обеспечивает максимальную скорость обмена
между узлами 10 Мб /сек, тогда как скорость обмена с оперативной
памятью составляет 250 Мб /сек и выше. Разработчики пакета подпрограмм
ScaLAPACK, предназначенного для решения задач линейной алгебры на
многопроцессорных системах, в которых велика доля коммуникационных
операций, формулируют следующим образом требование к
многопроцессорной системе: "Скорость межпроцессорных обменов между
двумя узлами, измеренная в Мб /сек, должна быть не менее 1/10 пиковой
производительности вычислительного узла, измеренной в Mflops" [5].
Таким образом, если в качестве вычислительных узлов использовать
компьютеры класса Pentium III 500 Мгц (пиковая производительность 500
Mflops), то аппаратура Fast Ethernet обеспечивает только 1/5 от
требуемой скорости. Частично это положение может поправить переход на
технологии Gigabit Ethernet.
Ряд фирм предлагают специализированные кластерные решения на
основе более скоростных сетей, таких как SCI фирмы Scali Computer
(~100 Мб /сек) и Mirynet (~120 Мб /сек). Активно включились в поддержку
кластерных технологий и фирмы-производители высокопроизводительных
рабочих станций (SUN, HP, Silicon Graphics).
1.5. Классификация вычислительных систем
Большое разнообразие вычислительных систем породило
естественное желание ввести для них какую-то классификацию. Эта
классификация должна однозначно относить ту или иную вычислительную
систему к некоторому классу, который, в свою очередь, должен достаточно
полно ее характеризовать. Таких попыток предпринималось множество.
Одна из первых классификаций, ссылки на которую наиболее часто
встречаются в литературе, была предложена М. Флинном в конце 60-х
годов прошлого века. Она базируется на понятиях двух потоков: команд и
данных. На основе числа этих потоков выделяется четыре класса
архитектур.
SISD (Single Instruction Single Data) – единственный поток команд и
единственный поток данных. По сути дела это классическая машина
фон Неймана. К этому классу относятся все однопроцессорные
системы.
SIMD (Single Instruction Multiple Data) – единственный поток команд
и множественный поток данных. Типичными представителями
являются матричные компьютеры, в которых все процессорные
элементы выполняют одну и ту же программу, применяемую к своим
(различным для каждого ПЭ) локальным данным. Некоторые авторы
к этому классу относят и векторно-конвейерные компьютеры, если
каждый элемент вектора рассматривать как отдельный элемент
потока данных.
MISD (Multiple Instruction Single Date) – множественный поток
команд и единственный поток данных . М. Флинн не смог привести
ни одного примера реально существующей системы, работающей на
этом принципе. Некоторые авторы в качестве представителей такой
архитектуры называют векторно-конвейерные компьютеры, однако
такая точка зрения не получила широкой поддержки.
MIMD (Multiple Instruction Multiple Date) – множественный поток
команд и множественный поток данных. К этому классу относятся
практически все современные многопроцессорные системы.
Поскольку в этой классификации все современные
многопроцессорные системы принадлежат одному классу, то вряд ли эта
классификация представляет сегодня какую-либо практическую ценность.
Тем не менее, мы привели ее потому, что используемые в ней термины
достаточно часто упоминаются в литературе по параллельным
вычислениям.
|