|
|
|
| На главную страницу | Сайт магистров | Сайт ДонНТУ | Поиск по ДонНТУ |
|---|
Бойко Анна Витальевна (annushka_b@mail.ru)Группа АСУ00аТема работы: "Проектирование компьютерной подсистемы сжатия данных методом генетического программирования"Руководитель - доц. кафедры АСУ Орлов Юрий Константинович |
|---|
| Автобиография |
| Магистерская работа |
| Отчет о поиске |
| Каталог ссылок |
| Библиотека |
| Индивидуальное задание |
Автореферат по теме магистерской работы1. Описание предметной области 1.1 Объект исследования 1.2 Проблема хранения информации 2. Анализ существующих систем сжатия 2.1 Использование сжатых таблиц 2.2 Упаковка битов 2.3 Арифметическое кодирование 3. Выбор метода разработки 3.1 Генетическое программирование как метод сжатия данных 3.2 Обобщение результатов научного поиска и анализа Список использованной литературы ВведениеВопрос экономного кодирования информации в системах управления базами данных был поставлен в первой половине 1970-х годов, но не потерял актуальности до сих пор. Многие современные исследователи отмечают недостаточную теоретическую проработку проблемы и неэффективность поддержки сжатия данных. Интерес к задаче сжатия данных в СУБД изначально был обусловлен стремлением уменьшить физический объем баз данных. Цена подсистемы ввода-вывода составляла основную часть стоимости аппаратуры. Поэтому при надлежащем интегрировании в СУБД методов безущербного сжатия данных достигалась значительная экономия. Небольшое увеличение числа используемых тактов процессора для кодирования-декодирования более чем компенсировалось снижением затрат на подсистему ввода-вывода. Данный результат применения сжатия востребован и в настоящее время. Действительно, падение относительной стоимости устройств хранения информации на несколько порядков сопровождалось соответствующим увеличением размера типичных баз данных. Тем не менее, в настоящее время фокус интереса все больше смещается на увеличение производительности системы управления данными за счет использования сжатия. Использование сжатия данных в СУБД связано с решением множества задач. Любая реализация экономного кодирования в СУБД связана с компромиссом между степенью сжатия, требуемым объемом оперативной памяти, числом обращений к внешней памяти и оперативной памяти, вычислительными затратами. Для применения в СУБД требуются специфические методы и приемы экономного кодирования, поскольку обычные методы не удовлетворяют ряду требований. Практическая ценность реализации достигается только при обеспечении быстрого доступа к произвольной записи или элементу данных. Востребованы так называемые методы сжатия с сохранением упорядоченности, позволяющие выполнять операции сравнения без декодирования данных.
Проблема реализации сжатия в СУБД имеет также такие аспекты, как оптимизация выполнения запросов к сжатым данным, эффективное сжатие результатов выполнения запросов, экономное кодирование метаданных, оценка целесообразности сжатия отдельных элементов, выбор алгоритма сжатия и его параметров с учетом типовых запросов и характера данных.
В связи с прогрессом компьютерных и инженерных разработок поток информации, получаемый из различных областей науки и техники возрос в сотни и тысячи раз. С развитием глобализации и интеграции появились всемирные проекты и организации, которые стремились объединить общие знания в одно целое, а затем и использовать эти данные, максимально сохраняя и оптимально извлекая всю информацию. Таких областей изучения мировых процессов и явлений большое множество. В данной работе рассматривается одна из них, наука о водной оболочке земли - гидрология. Исключительная роль воды в жизни человека и всего живого на Земле обусловливает большое и постоянно возрастающее внимание к изучению гидросферы и режиму водных объектов. Основная работа по организации и осуществлению наблюдений, сбора и обработки информации о состоянии гидросферы выполняется национальными метеорологическими, гидрологическими, геологическими службами и водохозяйственными организациями стран земного шара. Начало создания национальных служб и международного сотрудничества в изучении гидросферы относится к середине XIX века, когда в 1853 году была разработана программа проведения метеорологических наблюдений в океанах с целью повышения безопасности жизни на море. В результате прогресса, достигнутого в различных научных областях, в XX веке были разработаны и быстро усовершенствовались методы наблюдений за компонентами гидросферы в атмосфере, океанах и водных объектах суши. Были приняты меры по обмену данными наблюдений между службами. Разработки в области использования спутников и компьютерной технологии привели к созданию в 1963 году под эгидой Всемирной метеорологической организации (ВМО) комплексной всемирной оперативной системы, названной Всемирной службой погоды, которая включает глобальную систему телесвязи и глобальную систему обработки данных. Создана также глобальная система сбора океанографических данных. В настоящее время на земном шаре действуют около 9 тыс. станций на суше, производящих наблюдения за влажностью воздуха, облачностью, количеством выпадающих атмосферных осадков (из них 350 автоматизированы или частично автоматизированы). Около 700 морских судов производят наблюдения за различными параметрами состояния вод Мирового океана (температура, соленость и минеральный состав вод, направление течений). Эти данные дополняются наблюдениями с коммерческих самолетов (около 10 тыс. сводок в сутки). Передают информацию и 300 заякоренных буев или фиксированных платформ, работающих как автоматические морские станции, и около 600 буев, дрейфующих с океанскими течениями. На сегодняшний момент существует огромное количество институтов и организаций, занимающихся гидрологическими исследованиями. Придумано и осуществлено десятки тысяч международных программ и проектов. В 2003 году Группа ученых из Японии, США и Европы подготовила программу глобального исследования океана. По всему миру распределили около 3 тысяч самопогружающихся датчиков. На протяжении ближайших 3-4 лет они будут собирать подробные данные о течениях, фиксировать колебания температуры, концентрацию соли и прочие параметры, которые, по мнению специалистов, помогут предсказывать изменения климата на планете. Эксперимент получил название "Арго-программа". Оборудованные специальной аппаратурой датчики цилиндрической формы погружаются на глубину 2-х километров и остаются там в течение десяти часов. После этого приборы длиной около метра и диаметром 20 сантиметров автоматически всплывают на поверхность, связываются с помощью антенн со спутниками и передают собранную информацию на наземные станции, а затем вновь уходят под воду. Для хранения и автоматизации обобщения информации создаются специальные банки данных. В странах с небольшой по площади территорией принято создавать единые банки для всех компонентов гидросферы или два-три банка, собирающие информацию по атмосферным компонентам гидросферы, водным объектам суши, Мирового океана (включая окраинные и внутренние моря, морские устья рек). Такой огромный объем информации, который нужно ежедневно обрабатывать (а главная проблема состоит в том, что их нужно хранить в течение нескольков десятков лет для дальнейшего анализа) приводит к необходимости сжатия информации и дальнейшем ее восстановлении с минимальными потерями. Проблема хранения информацииБольшие объемы собираемой информации и требования к сокращению сроков ее предоставления потребителям обусловливают необходимость использования для ее обработки и обобщения современной электронной техники. Для хранения и автоматизации обобщения информации создаются специальные банки данных. В странах с небольшой по площади территорией принято создавать единые банки для всех компонентов гидросферы или два-три банка, собирающие информацию по атмосферным компонентам гидросферы, водным объектам суши, Мирового океана (включая окраинные и внутренние моря, морские устья рек). Эффективное разрешение информационных ресурсов и открытый доступ к пространственно распределенным экспериментальным данным базируются на использовании информационного сервиса глобальных сетей Интернет, т.е. на основе Web-технологий. С этой целью разрабатываются системы обращения со структурами метаданных, обеспечивающие сбор и распределение экспериментальных данных и результатов тематической обработки, при этом архив объединяется с региональными центрами геоэкологического мониторинга глобальной сетью Интернет. Важным элементом является разработка структуры интерфейса, архивации и сетевого обмена данными дистанционного зондирования. Это требует развития поисковых систем и реализации удаленного интерактивного доступа внешних пользователей по сети Интернет к экспериментальным данным и электронным каталогам обработки, предоставление пользователям возможности для интерактивного доступа к ним в режиме on-line. Современной тенденцией развития программ исследования Земли из космоса является создание в ряде стран электронных библиотек космической информации. Эти национальные информационные системы используют потоки спутниковых данных для решения разнообразных задач дистанционного зондирования, определяемых как научным сообществом, так и конкретными отраслями производственной деятельности. Например, в США для информационной поддержки своей национальной системы наблюдения Земли из космоса (EOS) NASA создало EOSDIS - разветвленную инфраструктуру сбора, архивирования и распространения спутниковых данных потребителям. Система EOSDIS сосредоточила огромные массивы геопространственных данных, получаемых со спутников ДЗЗ. Это создает серьезные проблемы при организации хранения и доступа к спутниковым данным, поскольку стандартные пакеты программ баз данных не могут их эффективно перерабатывать. Например, каждый кадр прибора ТМ спутника Ландсат в шести спектральных каналах (разрешение 30 м) и одном тепловом (разрешение 120 м) покрывает площадь 170 х 185 квадратных километров. В результате объем такого кадра спутника Ландсат достигает 400 Мбайт. Ежедневные объемы необработанных спутниковых данных ДДЗ, поступающие в систему EOSDIS, оцениваются в 480-490 Гбайт. Объем обработанных данных ДЗЗ в системе EOSDIS достигает 1600 Гбайт в сутки.
Роль и важность системы хранения определяются постоянно возрастающей ценностью информации в современном обществе, возможность доступа к данным и управления ими является необходимым условием для выполнения бизнес-процессов.
Безвозвратная потеря данных подвергает бизнес серьезной опасности. Утраченные вычислительные ресурсы можно восстановить, а утраченные данные, при отсутствии грамотно спроектированной и внедренной системы резервирования, уже не подлежат восстановлению.
По данным Gartner, среди компаний, пострадавших от катастроф и переживших крупную необратимую потерю корпоративных данных, 43% не смогли продолжить свою деятельность.
В большинстве систем поддержки принятия решений (СППР) обычно используются большие объемы данных, которые хранятся в нескольких очень больших таблицах. При развитии подобных систем требования к дисковому пространству могут быстро расти. Сейчас хранилища данных объемом сотни терабайт встречаются все чаще. При решении проблем с дисковым пространством, появившаяся в Oracle 9i Release 2 возможность сжатия таблицы может существенно сократить объем дискового пространства, используемого таблицами базы данных и, в некоторых случаях, повысить производительность запросов. Возможность сжатия таблиц в Oracle9i Release 2 реализуется путем удаления дублирующихся значений данных из таблиц базы. Сжатие выполняется на уровне блоков базы данных. Когда таблица определена как сжатая, сервер резервирует место в каждом блоке базы данных для хранения одной копии данных, встречающихся в этом блоке в нескольких местах. Это зарезервированное место называют таблицей символов (symbol table). Помеченные для сжатия данные хранятся только в таблице символов, а не в строках данных. При появлении в строке данных, помеченных для сжатия, в строке, вместо самих данных, запоминается указатель на соответствующие данные в таблице символов. Экономия места достигается за счет удаления избыточных копий значений данных в таблице. Сжатие таблицы на пользователя или разработчика приложений никак не влияет. Разработчики обращаются к таблице одинаково, независимо от того, сжата она или нет, поэтому SQL-запросы не придется менять, когда вы решите сжать таблицу. Параметры сжатия таблицы обычно устанавливаются и изменяются администраторами или архитекторами базы данных, и участие в этом процессе разработчиков или пользователей минимально. Основной причиной использования сжатия таблицы является экономия дискового пространства. Таблица в сжатом виде обычно занимает меньше места. Сжатие таблицы в Oracle9i Release 2 позволяет существенно сэкономить дисковое пространство, особенно в базах данных, содержащих большие таблицы только для чтения. Если учитывать дополнительные требования к загрузке и вставке данных, а также правильно выбрать таблицы-кандидаты для сжатия, сжатие таблиц может оказаться потрясающим способом экономии дискового пространства и, в некоторых случаях, повышения производительности запросов.
Но существуют свои недостатки:
Метод упаковки битов (bit packing) заключается в кодировании значения атрибута битовыми последовательностями фиксированной длины. Для каждого сжимаемого столбца требуется хранить соответствующую таблицу перекодировки. Разрядность кодовых последовательностей определяется количеством различных чисел, значения которых реально принимаются атрибутом, или же мощностью области определения атрибута. Очевидно, что требуемая длина кода N равна [ log 2 n], где n - это мощность множества реальных или допустимых значений атрибута. Данный метод рассматривается в одной из самых ранних статей по сжатию баз данных. Метод упоминается наряду с другими приемами под названием "bit compression". Упаковка битов - это простой способ сжатия на уровне значения атрибутов, реализация которого необременительна. Также важно, что при соответствующей реализации сохраняется упорядоченность. Но проблемой при использовании данного метода является обработка появления новых значений атрибута. В этом случае может потребоваться перекодировать все значения столбца, если [ log 2 n] становится больше исходного N . Суть метода: для каждого столбца находится минимальное и максимально значение. Значения, попавшие внутрь этого диапазона, последовательно кодируются. Длина кодового слова постоянна и определяется размером диапазона. Пример: пусть имеется последовательность строк из двух полей = {(100, 21), (98, 24), (103, 29)}. Для первого поля диапазон [98, 103], для второго - [21, 29]. Мощность первого множества значений равна 6, второго - 9. Поэтому будет представлена как: = {(0102, 00002), (0002, 00112), (1012, 10002)}. Очевидно, что если сжатие применяется к полям фиксированной длины, то их новая длина также фиксирована. Для каждого столбца необходимо хранить только границы диапазона и, возможно, длину. Перекодирование требуется лишь в случае выхода значения за границы диапазона. Степень сжатия сильнее всего зависит от распределения значений каждого атрибута для записей, хранящихся в одной странице. Можно кардинально улучшить сжатие за счет перераспределения записей по страницам при обработке на файловом уровне.
Метод упаковки битов не может обеспечить значительной степени сжатия относительно других методов, что, тем не менее, во многих приложениях может компенсировать высокой скоростью обработки данных и сохранением упорядоченности.
Совершенно иное решение предлагает т.н. арифметическое кодирование. Арифметическое кодирование является методом, позволяющим упаковывать символы входного алфавита без потерь при условии, что известно распределение частот этих символов и является наиболее оптимальным, т.к. достигается теоретическая граница степени сжатия. Предполагаемая требуемая последовательность символов, при сжатии методом арифметического кодирования рассматривается как некоторая двоичная дробь из интервала [0, 1). Результат сжатия представляется как последовательность двоичных цифр из записи этой дроби.
Идея метода состоит в следующем: исходный текст рассматривается как запись этой дроби, где каждый входной символ является "цифрой" с весом, пропорциональным вероятности его появления. Этим объясняется интервал, соответствующий минимальной и максимальной вероятностям появления символа в потоке.
Подробнее о методах кодирования можно прочитать на личной странице Семенова ЮА.
Идею генетического программирования (ГП) - впервые предложил Коза в 1992 году, опираясь на концепцию генетических алгоритмов (ГА). Эта идея заключается в том, что в отличие от ГА в ГП все операции производятся не над строками, а над деревьями. При этом используются такие же операторы, как и в ГА: селекция, скрещивание и мутация.
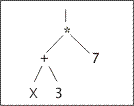
В ГП хромосомами являются программы. Программы представлены как деревья с функциональными (промежуточные) и терминальными (конечные) элементами. Терминальными элементами являются константы, действия и функции без аргументов, функциональными - функции, использующие аргументы.
Для того чтобы применить ГП к какой-либо проблеме, необходимо определить: Первый главный шаг в подготовке использования генетического программирования должен идентифицировать множество терминалов. Набор терминалов, наряду с набором функций, представляет собой компоненты, из которых будет создаваться компьютерная программа для полного или частичного решения проблемы. Второй шаг заключается в определении функционального множества, элементы которого должны использоваться для генерации математических выражений. Каждая компьютерная программа (то есть, анализируемое дерево, математическое выражение) является композицией функций от множества функций F и терминалов из терминального множества T (в случае программ-функций это константы и переменные).
Множество возможных внутренних узлов (не листовых), используемых в деревьях синтаксического анализа, используемых в генетическом программировании, называется функциональным множеством:
Пространством поиска генетического программирования является множество всех возможных рекурсивных композиций функций множества C. В функциональном множестве могут быть применены арифметические, математические, булевы и другие функции. В терминальное множество могут войти переменные, константы или директивные команды. Множества F и T должны обладать свойствами замыкания и достаточности. ЗАМЫКАНИЕ требует, чтобы каждая функция из множества F была способна принять аргументом любые значения и типы данных, которые могут быть возвращены любой функцией из множества C. Это предупреждает ошибки во время выполнения программ, полученных генетическим программированием. Для обеспечения условия замкнутости можно использовать защиту операций - принудительное приведение поступающих данных к диапазону, определяемому конкретной операцией. Например, операцию извлечения корня можно защитить от появления отрицательного аргумента принудительным расчетом модуля от этого аргумента. Альтернативой защите может быть автоматическое исправление ошибок в программе или применение штрафов за ошибки. ДОСТАТОЧНОСТЬ требует, чтобы функции из множества C были способны выразить решение поставленной задачи, то есть, чтобы решение принадлежало множеству всех возможных рекурсивных композиций функций из C. Однако доказать, что выбранное множество C достаточно, возможно лишь в редких случаях. Поэтому, при выборе этого множества, как и при выборе основных операций генетического алгоритма, приходится полагаться лишь на интуицию и экспериментальный опыт.
Обобщенная схема генетического алгоритма: Рис. 2 - Анимация. Генерация хромосом. Для воспроизведения нажмите кнопку на рисунке
Шаги 1-5 выполняются циклически. Обычно после завершения каждого цикла проводят сортировку популяции по приспособленности особей, что облегчает выполнение многих операций. Также, до старта самого алгоритма генерируется начальная популяция - она обычно заполняется случайными решениями (особями). Hа шаге 5, кроме расположения особи в популяции выполняется оператор, определяющий приемлемость новой особи а такжи оператор оценивания новой особи (фитнес-функция).
Цель использования генетического программирования для сжатия данных состоит в том, чтобы для большого набора входящих данных (не имеет значение какого рода, т.е. это могут быть температура, влажность, давление, любые другие коэффициенты и параметры гидрологических исследований) подобрать функции, которые оптимально сворачивают эти данные и позволяют потом при имеющемся типе функции, а также ее коэффициентах получить эти данные для обработки. Если имеется 1000 точек, фиксирующих какие-то параметры, то метод сжатия будет заключаться в подборе 5-6 или более функций, с помощью объединения которых можно будет потом получить весь набор точек. Кроме сжатия данных данная работа предполагает одновременный анализ данных, который может прослеживаться на больших временных отрезках и при этом не обязательно раскодирование. Так например при анализе температуры, видя, что функция температуры имеет приблизительный вид прямой можно сократить измерения на данном участке объекта или сделать их более дискретными. Научность работы заключается в составлении самого алгоритма поиска таких функций, определения интервала, в котором могут лежать предполагаемые коэффициенты функций, а также оценки производительности такого алгоритма в зависимости от разных по объъему наборов.
Таким образом можно выделить следующие задачи и цели магистерской работы:
Полная версия направления разработки магистерской работы находится в научной статье.
|