| MASTERS | DONNTU | EN |
| Биография | Автореферат | Ссылки | Отчет о поиске | Библиотека | Индивидуальное задание |
Автореферат магистерской работы.
Студента группы АСУ-00а
Тевелева А. Д
На тему: Разработка автоматизированной системы учета и анализа медико-статистической информации Донецкого региона
Руководитель проекта: Мокрый Г. В
Введение
Традиционные подходы в способах и методах получения и использования информации, существующие в сложившейся инструктивно-нормативной базе по медико-социальному обеспечению населения в настоящее время уже не соответствуют современным требованиям и недостаточно ориентированы на качественные показатели. Противоречие между потребностью в более качественной, оперативной информации и неадекватностью затрат на ее получение приводит к объективной необходимости создания медицинских автоматизированных справочно-информационных систем для оценки состояния здоровья населения. Совершенствование медицины в настоящее время не может эффективно осуществляться без применения современных методов диагностики, лечения и профилактики болезней, компьютерных информационных технологий. В связи с этим одной из основных задач территориального здравоохранения является не только рациональное оснащение лечебно-профилактических учреждений области современными медицинскими приборами и аппаратурой, но и средствами электронно-вычислительной техники и программными продуктами к ним, а также максимально эффективное их использование. Только так может быть обеспечена эффективная деятельность органов и служб городского и областного здравоохранения.
Большую помощь руководителям лечебных учреждений и главным специалистам органов управления при анализе показателей, характеризующих динамику тенденций здоровья населения, планировании распределения ресурсов здравоохранения области, управлении специализированными медицинскими службами, должны оказать автоматизированные информационные системы (АИС). [1]
Первоочередными задачами для автоматизации работы отрасли здравоохранения, являются:
- объединение всех учреждений в единую информационную сеть;
- автоматизация операций документооборота;
- автоматизация сбора и обработки табличной (статистической) информации;
- создание автоматизированных рабочих мест для специалистов учреждений здравоохранения и органов управления с интеграцией их выходных данных через системы автоматизации документооборота и сбора и обработки табличной (статистической) информации в единую базу данных здравоохранения области.
При этом первичные данные с уровня лечебно-профилактических учреждений должны собираться на уровне муниципальных образований и далее передаваться на уровень области, тем самым, замыкая весь цикл обработки первичной учетной медико-статистической, текстовой и прочей документации в единое целое. В результате унифицируются системы информационного обеспечения руководителей областных органов, служб и учреждений здравоохранения, стандартизируются методы работы по поиску оптимальных критериев оценки результатов, повышаются информационная обоснованность и своевременность принимаемых управленческих решений. Разработка комплекса программ ведется на основании заказа Министерства здравоохранения Украины. Внедрение разработанного комплекса способствует уменьшению трудоемкости и времени обработки статистической информации, ее достоверности и качества.
Цель проектируемой системы – автоматизировать процесс сбора, хранения и обработки медикостатистической информации Донецкого Региона, а также автоматизацию анализа накопленных данных. Медицинская статистика Донецкого региона собирает данные с различных лечебно-профилактических учреждений, а также по районам, и населенным пунктам. Данные представляют собой числовые показатели распространенности различных заболеваний, количества больных, смертности и т. п. Данные собираются за определенное время, называемое отчетным периодом. За время функционирования Донецкого УЗО, накоплен достаточно обширный банк данных, поэтому возникает задача рационального хранения, и использования этих данных, получение из них знаний, с целью возможности прогнозирования и принятия решений, способствующих более эффективному функционированию здравоохранения.
Для решения задач анализа накопленных данных можно выделить два класса систем. На первых стадиях информатизации всегда требуется навести порядок именно в процессах повседневной рутинной обработки данных, на что и ориентированы системы обработки данных (СОД). Системы второго класса — системы интелектуального анадиза данных (ИАД) — являются вторичными по отношению к ним.
В качестве технологии системы обработки данных (СОД) предполагается использовать технологию OLAP. В основе концепции оперативной аналитической обработки (OLAP) лежит многомерное представление данных. Cуществует два класса OLAP систем – многомерный OLAP (MOLAP) – данные хранятся в многомерном виде и реляционный OLAP – данные в OLAP систему поступают из плоских таблиц реляционных БД.
Использование реляционных БД в качестве исходных данных в разрабатываемой системе имеет следующие достоинства.
- В случае, когда изменения в структуру измерений приходится вносить достаточно часто, ROLAP системы с динамическим представлением размерности являются оптимальным решением, так как в них такие модификации не требуют физической реорганизации БД.
- Системы ROLAP могут функционировать на гораздо менее мощных клиентских станциях, чем системы MOLAP, поскольку основная вычислительная нагрузка в них ложится на сервер, где выполняются сложные аналитические SQL-запросы, формируемые системой. Соответственно это облегчает внедрение системы в медицинских учреждениях, без необходимости закупки более мощного и дорогостоящего оборудования.
- Реляционные СУБД обеспечивают значительно более высокий уровень защиты данных и разграничения прав доступа.
- Реляционные СУБД хорошо применимы для работы с очень большими базами данных, что является определяюще важным фактором для хранения такого огромного банка данных как данные медицинской статистики области.
Таким образом, при внедрении данной технологии в систему медицинской статистики вариант ROLAP является наиболее приемлемым.
OLAP система дает основу для проведения интеллектуального анализа данных. Можно дать следующее определение: ИАД — это процесс поддержки принятия решений, основанный на поиске в данных скрытых закономерностей. Большинство методов ИАД было первоначально разработано в рамках теории искусственного интеллекта (ИИ) в 70-80-х годах, но получили распространение только в последние годы, когда проблема интеллектуализации обработки больших и быстро растущих объемов данных предприятий потребовала их использования в качестве надстройки над хранилищами данных .
Большинство авторов приводит классификацию задач, решаемых средствами ИАД по типам производимой информации. Следующие пять видов называются всеми без исключений.
1) Классификация. Наиболее распространенная задача ИАД. Она позволяет выявить признаки, характеризующие однотипные группы объектов — классы, — для того чтобы по известным значениям этих характеристик можно было отнести новый объект к тому или иному классу. Ключевым моментом выполнения этой задачи является анализ множества классифицированных объектов. С помощью классификации можно определить например районы с эпидемией вируса, или районы где заболеваемость имеет приемлемый уровень. Также можно определить группы граждан, наиболее подверженных тому или иному заболеванию, и т. д. В качестве методов решения задачи классификации могут использоваться алгоритмы типа Lazy-Learning, в том числе известные алгоритмы ближайшего соседа (Nearest Neighbor) и k-ближайшего соседа (k-Nearest Neighbor), байесовские сети (Bayesian Networks), индукция деревьев решений, индукция символьных правил, нейронные сети.
2) Кластеризация. Логически продолжает идею классификации на более сложный случай, когда сами классы не предопределены. Результатом использования метода, выполняющего кластеризацию, как раз является определение (посредством свободного поиска) присущего исследуемым данным разбиения на группы. В качестве примера используемых методов можно привести обучение "без учителя" особого вида нейронных сетей — сетей Кохонена, а также индукцию правил.
3) Выявление ассоциаций. В отличие от двух предыдущих типов, ассоциация определяется не на основе значений свойств одного объекта или события, а имеет место между двумя или несколькими одновременно наступающими событиями. При этом производимые правила указывают на то, что при наступлении одного события с той или иной степенью вероятности наступает другое. В частности, выявление ассоциаций позволяет определить, как часто события X и Y случаются вместе, в виде доли от общего количества событий X; скажем, рост процента заболеваемости одной болезнью (X) ведет к росту процента заболеваемости другой болезнью (Y).
4) Выявление последовательностей. Подобно ассоциациям, последовательности имеют место между событиями, но наступающими не одновременно, а с некоторым определенным разрывом во времени. Таким образом, ассоциация есть частный случай последовательности с нулевым временным интервалом.
5) Прогнозирование. Это особая форма предсказания, которая на основе особенностей поведения текущих и ранее собранных данных оценивает будущие значения определенных численных показателей. Данный класс задач является очень важным в системе медицинской статистики, и является важнейшей целью автоматизации анализа накопленных данных. В задачах подобного типа наиболее часто используются традиционные методы математической статистики, а также нейронные сети. [2],[10]
Все перечисленные пять задач должны решаться в разрабатываемой системе. Каждая из задач имеет различные методы решения, и реализация каждого из этих методов может осуществляться с помощью различных блоков, с использованием также уже существующих средств ИАД.
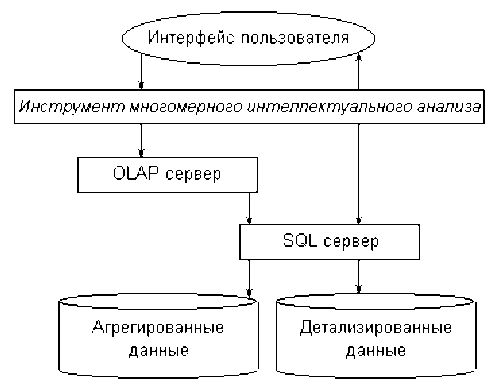
В разрабатываемой системе средства интеллектуального анализа данных будут получать информацию как из детализированных данных (SQL), так и из многомерных данных. Таким образом система объединяет в себе механизмы SQL, OLAP и средства интеллектуального анализа данных. На рисунке представлена общая схема их интеграции.
Таким образом можно выделить 3 основных направления исследований:
1) Построение оптимальной системы хранения и сбора данных на основе технологий OLAP и реляционных баз данных. Основные проблемы, этого направления — обеспечение надежного и достаточно быстрого функционирования системы, при ее специфических особенностях — большие обьемы данных, многопользовательская работа с распределенным хранилищем данных, необходимость оперативного изменения и синхронизации данных на различных уровнях функционирования системы, обеспечение функционирования системы в сети интернет.
2) Решение проблем анализа накопленных данных. Выбор наиболее приемлемых и эффективных методов анализа среди существующих, обеспечение автоматизированного принятия решений на основе собранных данных. Также имеет смысл рассмотреть вопросы принятия решений по оптимизации самого сбора данных, на основе результатов анализа.
3) Интеграция системы сбора и хранения данных с системой анализа данных в единую СППР. Данный вопрос наиболее интересен с точки зрения новизны, так как на сегодняшний день существует немного систем, функционирующих по принципу взаимодействия OLAP — ИАД. Совершенствование технологий в этой области откроет путь к созданию принципиально более мощных систем интеллектуальной обработки данных.
Следует отметить, что на данный момент одним из примеров подобной информационной системы является информационная система здравоохранения Смоленской области РФ. В области действует автоматизированная система по сбору, обработке и анализу различных показателей деятельности учреждений здравоохранения. При построении комплекса автоматизированных информационных систем здравоохранения области придерживались идеологии, при которой первичные учетные данные, вводимые в лечебно-профилактических учреждениях (далее ЛПУ), должны использоваться для анализа показателей на разных уровнях управления (ЛПУ — район (город) — область — Минздрав). Для создания единого информационного пространства внутри учреждений здравоохранения используются локальные вычислительные сети, а для связи между учреждениями — модемная связь по коммутируемым каналам связи. В настоящее время абонентами региональной медицинской сети являются практически все учреждения здравоохранения области (более 70-ти учреждений). Однако данная система концентрируется на автоматизации сбора и отображения данных, не применяя методы ИАД для их анализа.
Применяемые методы
Основная цель анализа медико-статистической информации — получить необходимые данные для принятия решений в области управления здравоохранением. Для комплексного анализа данных возможно применение большого количества методов, направленных на решение трех основных задач — выявления скрытых связей между данными (ассоциация), выявление некоторых признаков, характеризующих группу, к которой принадлежит тот или иной объект, другими словами совокупность данных (задача классификации), а также задача построения математической модели на основе имеющихся данных, позволяющей предсказывать поведение системы в будущем (прогнозирование).
Центр медико-статистической информации донецкого региона работает с 48 формами государственной статической отчетности, каждая из которых имеет собственную предметную область анализа данных. Таким образом, состав и способ применения методов анализа данных будет отличаться для различных форм, однако рассмотрения существующих на сегодняшний день методов позволит выработать общую стратегию их применения для исследования данных медицинской-статистики в целом. На данный момент уже было рассмотрено решение задач классификации для отчетной формы F08 — "Данные о заболеваемости активным туберкулезом". Ниже на рисунке приведен вид основной таблицы этой формы.
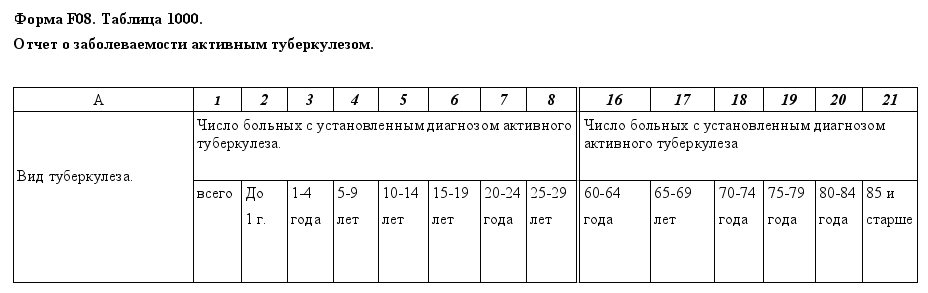
Как видим, данные собираются по различным возрастным категориям, а также по разновидностям туберкулеза. Данные собираются за отчетный год по определенной территории. Система, работающая на уровне области собирает данные по городам а также областным лечебным учреждениям.
Одним из самых простых и в то же время очень эффективных методов, позволяющих решать задачу классификации данных — является метод K-ближайших соседей. Рассмотрим ситуацию с туберкулезом легких в ряде городов Донецкой области за 2002 год. Данные представим на графике, где по оси X будет отложена возрастная категория граждан, по оси Y — показатель заболеваемости для данной категории. На пересечении этих значений будем отмечать знаком "+" пары параметров "возраст"/"количество заболевших", для которых был зарегистрирован опасный уровень заболевания, а знаком "-" — обычный уровень. Приведены данные по следующим населенным пунктам — Макеевка, Константиновка, Мариуполь. Представим эти данные в виде таблицы:
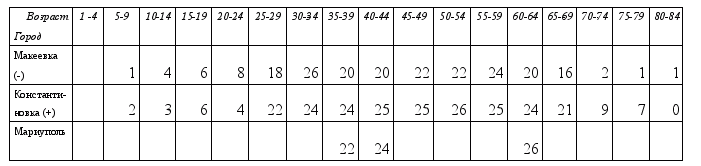
В данном случае классификация проводится с помощью двух заранее известных классов — "Опасный уровень заболеваемости", и "Высокий уровень заболеваемости", которые были заданы вручную, специалистами управления здравоохранения области в 2002 году. Такие данные могут вводится в систему, создавая базу данных классов. Опасный уровень заболевания зарегистрирован был в Константиновке, и для него приведены данные со знаком +. В Макеевке уровень заболеваемости оставался в норме, и для него данные имеют знак минус. Кружками отмечены данные по городу Мариуполь, подлежащие классификации. Взяты только 3 возрастные категории — 35-39, 40-44, 60-64, так как для осуществления классификации достаточно считывать информацию, не во всех, а в некоторых ключевых точках. Видим, что при 1-м 2-х, 3-х или 4-х ближайших соседях знаки распределятся "неопределенность", +, +. При пяти ближайших соседях получаем все три плюса. Такиим образом получили первые результаты при количестве ближайших соседей K=5. По полученным результатам можно сказать, что в 2002 году в городе Мариуполь была опасная ситуация по туберкулезу. Для более детального анализа можно взять дополнительные точки.
Ниже показана графическая демонстрация применения данного метода.
Нажмите чтобы просмотреть анимацию в полном размере.
Выбор параметра K также является ключевым моментом при решении данной задачи. Для оценки этого параметра используется метод кросс-проверки. Основная идея метода заключается в разделении выборки данных на v "складок" (случайным образом выделенные изолированные подвыборки или сегменты). По фиксированному значению К строится К-БС модель для получения предсказаний на v-ом сегменте (при этом остальные сегменты используются как примеры) и оценки ошибки. Для регрессионных задач наиболее часто в качестве оценки ошибки выступает сумма квадратов, а для классификационных задач удобней рассматривать точность (процент корректно классифицированных наблюдений). Далее процесс последовательно повторяется для всех возможных вариантов выбора v. По исчерпании v "складок" (циклов), вычисленные ошибки усредняются и используются в качестве меры устойчивости модели (т.е. меры качества предсказания в точках запроса). Вышеописанные действия повторяются для различных К , и значение соответсвующее наименьшей ошибке (или наибольшей классификационной точности) принимается как оптимальное (оптимальное в смысле метода кросс-проверки). Кросс-проверка вычислительно емкая процедура и следует быть готовым предоставить время для работы алгоритма особенно, если объем образцовой выборки велик. Альтернативный путь — самостоятельно задать значение параметра К. Этот способ приемлем, особенно если распологать обоснованными предположениями относительно возможного значения параметра.[3]
Рассмотрим другой популярный метод классификации — метод дискриминантного анализа. Дискриминантный анализ используется для принятия решения о том, какие переменные различают (дискриминируют) две или более возникающие совокупности (группы).
Зададимся количеством классов K.
Обозначим количество наблюдений в каждом классе ki.
k* — общее число наблюдений по всем классам.
Вычисляется матрица сумм квадратов и попарных произведений T, которая показывает степень различий между объектами. Элементы матрицы T задаются соотношением:
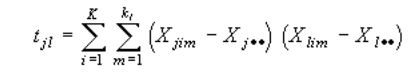
Xjim — это значение переменной j для m-go наблюдения в i-м классе. Очевидно, что для каждого класса набор переменных представляет из себя множество показателей больных туберкулезом по каждой возрастной категории. Xj** — представляет из себя среднее значение переменной j по всем классам. Для определения степени разброса внутри классов, используется матрица W, элементы которой вычисляются по формуле:
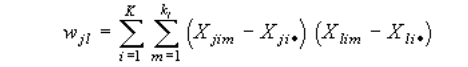
где Xji* — среднее значение переменной j для i-го класса. Введем матрицу разницы этих двух матриц — B=T-W Величины элементов B по отношению к величинам элементов W дают меру различия между группами. Для каждого m-го элемента k-го класса вводится каноническая дискриминантная функция, имеющая вид:
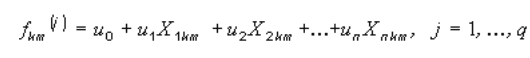
Для этого решается система уравнений:
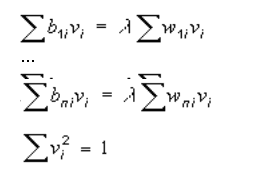
Коэффициенты находятся по формулам:
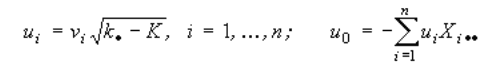
Канонические дискриминантные функции обеспечивают максимальное отличие классов. С их использованием выполняется процедура классификации.
Сначала вычисляются параметры линейной классифицирующей функции и константы сравнения. Для количества классов — 2 (как в предыдущем примере) достаточно вычислять одну классифицирующую функцию, в противном случае вычислется классифицирующая функция для каждого из классов со своим набором коэффициентов. В общем случае набор коэффициентов представляет из себя набор векторов Di для каждого из классов, а также столбец свободных членов Ci.
Вычисления производятся на основе обучающей последовательности {Xi}, то есть набора переменных, принадлежность которых к тому или иному классу известна. В данном случае это данные для городов Макеевка и Константиновка. Для классификации нового вектора X, вычисляются значения классифицирующей функции для каждого из векторов и определяется максимальное из них.
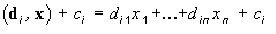
Для правильной классификации методом дискриминантного анализа понадобится весь набор переменных классифицируемого обьекта, в отличие от более гибкого метода K — ближайших соседей, где достаточно задаваться лишь несколькими переменными. Данные методы целесообразно использовать вместе.
Использование нейронных сетей в разрабатываемой системе
Еще один метод классификации, существенно отличающийся от двух предыдущих — метод, использующий нейронные сети. Системы, основанные на нейронных сетях эффективно справляются не только с задачами классификации, но и кластеризации. При решении задачи кластеризации, которая известна также как классификация "без учителя", отсутствует обучающая выборка с метками классов. Алгоритм кластеризации основан на подобии объектов и размещает близкие объекты в один кластер.[5]
В одной из наиболее распространенных архитектур, многослойном перцептроне с обратным распространением ошибки, эмулируется работа нейронов в составе иерархической сети, где каждый нейрон более высокого уровня соединен своими входами с выходами нейронов нижележащего слоя. На нейроны самого нижнего слоя подаются значения входных параметров, на основе которых нужно принимать какие-то решения, прогнозировать развитие ситуации и т. д. Для того чтобы сеть можно было применять в дальнейшем, ее прежде надо "натренировать" на полученных ранее данных, для которых известны и значения входных параметров, и правильные ответы на них. Эта тренировка состоит в подборе весов межнейронных связей, обеспечивающих наибольшую близость ответов сети к известным правильным ответам. С классификацией при заранее известном наборе классов хорошо справляется персептрон Розенблатта [6], с задачами кластеризации — сети Кохонена [7].
На рисунке показана общая схема тренировки нейронной сети в разрабатываемой системе.
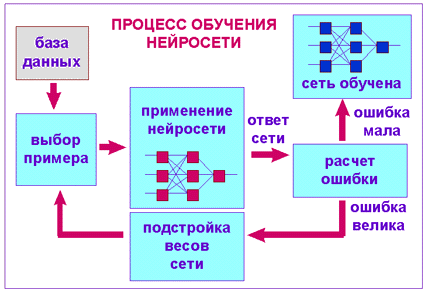
Среди преимуществ использования нейронных сетей в задачах классификации медико-статистических данных — большой объем обучающей информации, накопленной за время функционирования Центра Медико-статистической информации Донецкого УЗО, а также их высокая эффективность, в задачах с большими количествами близко лежащих классов, с которыми не справятся методы математической статистики. Недостаток нейронных сетей — их высокая требовательность к вычислительным ресурсам.
Для успешного решения задач классификации вышеописанные методы необходимо применять в комплексе, от более простых к более сложным.
Заключение
Оперативная аналитическая обработка и интеллектуальный анализ данных — две составные части процесса поддержки принятия решений. Но сегодня большинство систем OLAP заостряет внимание только на обеспечении доступа к многомерным данным, а большинство средств ИАД, работающих в сфере закономерностей, имеют дело с одномерными перспективами данных. Эти два вида анализа должны быть тесно объединены, то есть системы OLAP должны фокусироваться не только на доступе, но и на поиске закономерностей.
K. Parsaye [8] вводит составной термин "OLAP Data Mining" (многомерный интеллектуальный анализ) для обозначения такого объединения. Средство многомерного интеллектуального анализа данных должно находить закономерности как в детализированных, так и в агрегированных с различной степенью обобщения данных. К сожалению, очень немногие производители предоставляют сегодня средства интеллектуального анализа многомерных данных в рамках систем OLAP — по-видимому, только SAS Institute добился в этом некоторого успеха. Идеальной целью построения информационно-аналитической системы является создание СППР замкнутого цикла. Как заметил N. Raden, "многие компании создали ... прекрасные хранилища данных, идеально разложив по полочкам горы неиспользуемой информации, которая сама по себе не обеспечивает ни быстрой, ни достаточно грамотной реакции на рыночные события" [9]. В особенно динамичных сферах, где ситуация меняется ежедневно, своевременное принятие грамотных решений не обеспечивается даже при использовании обычных средств OLAP и ИАД. Они должны быть объединены друг с другом и иметь обратную связь к исходным системам обработки данных, с тем чтобы результаты работы СППР немедленно передавались в виде управляющих воздействий в оперативные системы.
Таким образом на данный момент определена общая структура будущей системы поддержки принятия решений, базирующейся на двух системах — системе обработки данных и системе интеллектуального анализа данных. В качестве системы обработки данных выбран механизм OLAP, проведен обзор существующих OLAP-технологий, проанализированы вопросы, требующие решения при внедрении данного механизма в исследуемом объекте. Проведено подробное изучение существующих на сегодняшний день механизмов интеллектуальной обработки данных и их применение в сфере обработки медико-статистической информации.
Применение методов OLAP и Data Mining в совокупности дает в последствии информацию для принятия решений на основе накопленных данных. Анализ данных дает необходимую информацию для принятия решений не только в медицине но и в области самой медицинской статистики, например позволяя определять обьекты, сбор данных по которым необходим в большей мере чем по другим. Таким образом решается задача самосовершенствования системы управления через обратную связь.
Однако не следует забывать, что конечным звеном системы принятия решений все-равно является человек, инструменты OLAP и Data Mining позволяют лишь облегчить его задачу, выделив важную информацию, способную стать основой для действий в руках специалиста.
Список литературы.
1) Информационная система здравоохранения Смоленской области. Описание. http://admin.smolensk.ru/~zdrav/s_informsys/i_informwords.htm
2) Щавелев Л. В Способы аналитической обработки данных для поддержки принятия решений. СУБД. — 1998. — 4-5.
3) Метод K-Ближайших соседей: Вводный Обзор. http://www.spc-consulting.ru/dms/Machine Learning/MachineLearning/Overviews/KNearestNeighborsIntroductoryOverview.htm
4) Обзор методов принятия решений трейдером на основании статистических методов обработки информации. Попов Роман. (C) Релпресс, 1997
5) Anil K. Jain, Jianchang Mao, K.M. Mohiuddin. Artificial Neural Networks: A Tutorial, Computer, Vol.29, No.3, March/1996, pp. 31-44.
6) Розенблатт Ф. Принципы нейродинамики. Перцептрон и теория механизмов мозга. М.: Мир, 1965. 480 с.
7) Кохонен Т. Ассоциативные запоминающие устройства. — М.: Мир, 1982.
8) Parsaye K. OLAP and Data Mining: Bridging the Gap // Database Programming and Design. — 1997.
9) Моуд Дж. Товары впрок // PC Week/RE. — 1997.
10) Data Mining: The AI Metamorphosis // H.P. Newquist // Database Programming and Design. — 1997. http://www.dbpd.com/vault/newquist.htm