
| MASTERS | DONNTU | RU |
| Biography | Abstract | Links | Search report | Library | Personal task |
The abstract for the master project.
Group: ACS-00a
Student: A.D Tevelev
The subject: Working out the automated system for accounting and analysing the medical-statistical information of Donetsk region
Supervisor: G.V. Mokriy
Introduction
Traditional approaches in ways and methods of getting and utilising the information that exists in usual instructive-normative base of medical-social security of the population do not correspond to modern requirements and are insufficiently focused on quality indicators. The contradiction between requirements for better operative information and inadequacy of costs for its getting leads to the real necessity of the medical automated reference systems building, aimed at the estimation of the state of helth of population. The perfection of the medicine today can not be effectively realized without use of the modern diagnostics, treatment and prophylaxis methods based on the information technologies. Given that one of the primary goals of the territorial public health services is not only rational equipment of the regional treatment-and-prophylactic establishments with modern medical devices and outfit, but also with the instruments of the computer techniques and software, as well as their effective use. Only then an effective activity of city and regional public health services can be provided.
The automated information systems (AIS) should render great assistance to the heads of medical establishments and to main experts of controls in the questions of analysis of the parameters that describe dynamics of the health tendences. Also these systems are essential in the planning of distribution of the public health resources and in the management of the specialized medical services. [1]
Priorities for the automatization of public health services are:
- joining all the establishments in unified information network;
- automatization of the document circulation operations;
- automatization of collection and processing of the tabulared (statistical) information;
- crteation of the automatized workplaces for the experts of public health establishements and controls with integration of their target data via the systems of document circulation automatization and statistical data processing in the united regional health security database.
Thus primary data from the treatment-and-prophylactic establishments level should be collected at the level of the municipal consils and be transferred further to the regional level, closing all the operation cycle of the primary statistical, text and other documentation in a single whole. The result is an unification of the dataware systems, being used by the heads of the regional health organs, services and establishments. Also the search methods for the optimum criteria of results' estimation are standardized, and information validity and timeliness of the taken administrative decisions rise. The development of the program complex is carried out according to the order of the Ministry of Health of Ukraine. The application of the complex furthers reduction of laboriousness and time for the statistical information processing and improves its quality and reliability.
The goal of the system is to automate the process of collection, storage and processing of the medical-statistical information of the Donetsk Region, and also to automate the process of the stored data analysis. The medical statistics of Donetsk region collects data from various treatment-and-prophylactic establishments, as well as from regions and settlements. The data represent numerical parameters, showing the prevalence of various diseases, number of patients, mortality, etc. The data is collected for the certain time called "the accounting period". During the functioning of the Donetsk regional Public health Administration, a quite extensive databank is saved up, therefore there is a problem of its rational storage, use and getting knowledge from them, aimed to the opportunity of forecasting and decision-making, promoting more effective functioning of the public health services.
There are basically two classes of the systems, distined to the solving the tasks of the stored data analysis. At the first stages of the automatization there are always the processes of daily routine data treatment that need to be put in order. It's the data processing systems (DPS) that are focused on this question. The second-class systems — those of the intellectual data analysis (IDA) are secondary regarding them.
As a technology of the DPS it's supposed to use the OLAP technology. The basic conception of the operative analytical processing (OLAP) is the multidimensional data presentation. There are two classes of the OLAP systems — multidimensional OLAP (MOLAP) — all the data is stored in a multidimensional state and relational OLAP (ROLAP) — the data comes to the OLAP system from flat tables of a relational DB.
Use of the relational DB as an initial data in the system has the following advantages.
- The ROLAP systems with the dynamic representation of the dimensions are the best decision in case when it's often required to bring changes in the dimensions' structure, as such modifications don't need a physical reorganization of the DB.
- The ROLAP systems can function at much less powerful client stations, than MOLAP systems, as the basic computing load falls to the server, where the complex analytical SQL-queries, formed by the system, are fulfilled. Accordingly, it makes easier the application of the system to the medical establishments, without a necessity of buying the more powerful and expensive equipment.
- The relational DBMS provide much higher level of data protection and delimitation of the access rights.
- The relational DBMS are good for work with very large databases that is the determinant factor for the storage of such a huge databank as the regional medical-statistical data. Thus the variant ROLAP is the most acceptable for the application of the present technology to the medical-statistical system.
The OLAP system gives a base for the intellectual data analysis. It is possible to define the following: IDA is a process of the decision-making support, based on a search of the ulterior rules in the data. The majority of the IDA methods have been originally developed within the limits of the artificial intellect (AI) theory during the 70-80-s years, but have been widely distributed only last years when the problem of an intellectualization of large and quickly growing volumes of the enterprises' data demanded their use as a superstructure on the data warehouses.
Majority of the authors gives the classification of the problems solved by IDA by the types of the output information. The following five methods are refered by all without exception:
1) Classes (sometimes referred to as "classifications"). This information type consists of shared characteristics, such as how many or what percentage of all people over the age of 50 have some disease but haven't undergone any medical treatment. A data mining tool must use pattern recognition to create these classes. Classes are the most common form of data mining.
2) Clusters (or categories). Clusters are a form of class (and thus a subset), but they consist of patterns and relationships that haven't been predefined or were "hidden." These arcane relationships could be valuable once uncovered.
3) Associations. Unlike the previous two information types, associations are event-driven. That is, an association exists between two occurrences in an event such that the completion of one occurrence implies the existence of the next. Data miners tend to use retail analogies for this process.
4) Sequences. Like associations, sequences are events, but they are linked over time and are relevant to a specific instance. That is, an association exists between two occurrences in an event such that the completion of one occurrence implies the existence of the next. Data miners tend to use retail analogies for this process.
5) Forecasts. Just as they sound, forecasts involve predicting the future based on current and ongoing data. Forecasts are applicable to almost any corporate situation, from predicting product sales to ordering inventory, to plans for hiring personnel, to estimating corporate growth. Data mining supports forecasting by extracting all relevant data-including data that might not seem relevant to a human forecaster and applying it, together with relevant fluctuations, to a comprehensive forecast. [2],[10]
These five problems should be solved by the system. Each of the problems has various methods of the decision, and realization of each of these methods can be fulfilled with the help of various blocks, also with already existing IDA tools.
The tools of the IDA in the system will receive the information both from the detailed data (SQL), and from multidimensional data. Thus the system unites the mechanisms SQL, OLAP and the IDA tools. The common scheme of their integration is presented on the picture.
Thus we can allocate 3 basic directions of researches:
1)Construction of an optimal system of data collection and storage using OLAP and relational databases technologies. The basic problems here are — providing the safe and enough fast functioning of the system, considering its specificity – large data levels, the multiuser work with the distributed data warehouse, necessity of operative change and synchronization of the data at various levels of the system functionning, providing the functionning of the system in the Internet.
2)Solving the problems of the stored data analysis. The selection of the most acceptable and effective methods of the analysis among the existing, providing the automated decision-making on the basis of the collected data. Also it makes sense to consider the questions of the decision-making, concerning the optimization of the data gathering, on the basis of the analisys results.
3)Integration of the data collection and storage system with data analisys system in one to decision-making system. This question is the most interesting from the point of the novelty, as there exist a few systems for today that function by the principle of the OLAP – IDA interaction. The perfection of the technologies in this area will open a way to the creation of much more powerful systems of the intellectual data processing.
It is necessary to note, that one of the examples of such information system at present is he information system of the public health services of Smolensk region of the Russian Federation. The automated system of collection, processing and analysis of various parameters of the public health services activity function there. The complex was being constructed following the ideology that the primary registration data entered in treatment-and-prophylactic establishments (TPE further) should be used for the analisys of the parametres on different control levels. (TPE — district (city) – region — Ministry of Health). They use local computer networks for the creation of uniform information space inside of establishments of public health services, and modem communication using commutated channels for the communication between establishments. Now the subscribers of the regional medical network are practically all the establishments of the regional public health services (more then 70 establishments). However the given system concentrates on the automation of collection and display of data, not applying the IDA methods for its analysis.
Used methods.
The basic purpose for the analysis of the medical-statistical information is to obtain the necessary data for the decision-making in the area of the public health services management. For the complex data analysis an application of a plenty of the methods is possible. It is directed on the solving of three primary tasks — revealings of the latent relations in the data (association), revealing of some attributes that describe group to which an object belongs, in other words a data set (a problem of classification). Also there is a problem of construction of a mathematical model on the basis of the available data, allowing to predict the behaviour of the system in the future (forecasting).
The center of the medical-statistical information of Donetsk region works with 48 forms of the statistical reporting, each of them has their own data domain. Thus, the structure and the way of the analysis methods application will differ for various forms, however considering the methods that exist for today we can develop the general strategy of their application for the research of the medical-statistical data at all. At present the decision of the classification problems for the form F08 — "Data on the active tuberculosis disease" has already been considered. The look of the basic table of this form is given on the picture:

As we can see, the data is collected on the different age categories, and also on the tuberculosis kinds. Data is collected for a fiscal year on a certain territory. The system, that works on the regional level collects data on the cities and also on the regional medical establishments.
One of the most simple and at the same time very effective methods, that allows to solve a problem of the data classification is the K-nearest neighbours method. Let's consider a situation with a tuberculosis of lungs in a number of cities of the Donetsk area for the year 2002. Data is present on the plot where the X axis means the age category of the citizens and the Y – the parameter of desease for the given category. On the intersection sign "+" marks those parametres where a dangerous level of the diseas was registered and sign “-” marks those for a usual level. Tha data is given for the next cities: Makeyevka, Konstantinovka, Mariupol. Here is the table:
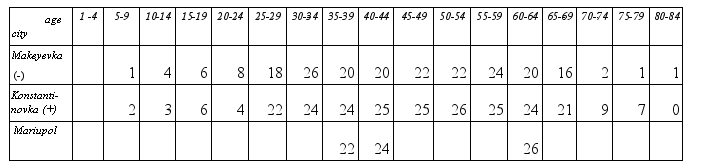
In this case classification is made wit use of two known classes — "Dangerous level of desease", and" and “High level of desease" which have been set manually, by experts of the regional public health services in the 2002. Such data can be typed into the system, creating a database of the classes. The dangerous level of the disease has been registered in Konstantinovka, and for it the data is marked with the sign “+”. The level of the desease remained in norm in the Makeevka, that's why the data have a minus sign for it. Circles note data for the Mariupol, a subject of the classification. Only 3 age categories are given — 35-39, 40-44, 60-64 years old.as for the realization of the classification it is enough to take the information in some key points only. We can see, that with 1-st 2, 3 or 4 nearest neighbours signs will be distributed as "uncertainty", +, +. With five nearest neighbours all three plus are obtained. Thus we received the first results at with 5 nearest neighbours.Given that we can tell, that there was a dangerous situation with the tuberculosis in the Mariupol in 2002. For more detailed analysis some additional points can be taken.
Graphic demonstration of an application of the given method is shown below
Press to view the full-size animation.
Therefore, it is clear that the choice of K is critical, since it represents a trade-off between local and global approximations of the probability measures. In order to support the user in the selection of the optimal K, a cross-validation approach is adopted, where different values of K are considered. The search for the optimal K can be reduced withoud loosing too much accuracy in the approximation. The data set is separated into two sets, called the training set and the testing set. The function approximator fits a function using the training set only. Then the function approximator is asked to predict the output values for the data in the testing set (it has never seen these output values before). The errors it makes are accumulated as before to give the mean absolute test set error, which is used to evaluate the model. The advantage of this method is that it is usually preferable to the residual method and takes no longer to compute. However, its evaluation can have a high variance. The evaluation may depend heavily on which data points end up in the training set and which end up in the test set, and thus the evaluation may be significantly different depending on how the division is made. An alternative way is to select K independently. It's good in case when there are valid predictions for the K-parameter value.[3]
Let's consider another popular method of the classification — a method of the discriminantal analysis. The discriminantal analysis is used to make a decision on what variables distinguish (discriminate) two or more arising sets (groups).
Let's chose a number of classes K.
Let's call the number of the observations in every class as ki.
k* — the general number of observations for all classes.
We shell calculate the matrix of the sums of squares and paired multiplications T which shows a measure of distinctions between the objects. Elements of the matrix T are set by the formula:
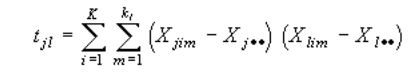
Xjim is a value of the j variable for the m observation in the i class. Evidently, that the set of variables for each class represents the set of parameters of the sick on the tuberculosis for each age category. Xj** is the average value of the j variable from all the classes. For definition of the measure of the disorder inside a class the matrix W is used, which elements are calculated by the formula:
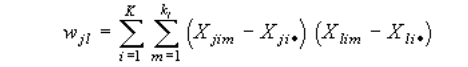
Where Xji* is the average value of the j variable for the i class. We shall enter a matrix of the difference between these two matrixes — B=T-W. The valuses of the elements of B in relation to those of the W elements give us a measure of distinction between groups. For each m-element of k-class the initial discriminantal function is entered. It looks like:
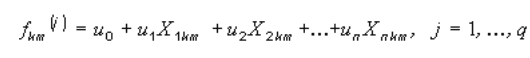
For that the equation system is to be solved:
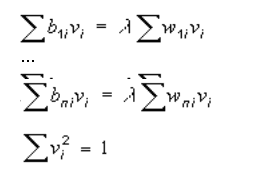
The coefficients are calculated by the formulas:
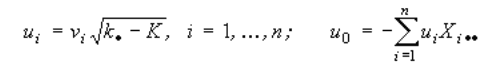
The initial discriminantal functions provide the maximal difference of the classes. With their use the procedure of classification is implimented.
First of all the parameters of the linear classifying function and the constants of comparison are to be calculated. For the number of classes — 2 (as in the previous example) it's enough to calculate one classifying function. In else this function should be calculated with its own set of the factors for each of the classes. Generally the set of factors represents a set of vectors Di for each class, and also a column of free members Ci.
The calculations are made on the basis of training sequence {Xi}, a set of variables which accessories to this or that class is known apriory. In our case it is the data for Makeyevka and Konstantinovka. To classificate a X vector, we should calculate the values of the classifying function for each of the vectors and select the maximal of them.
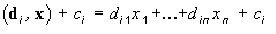
For the correct discriminantal analysis classification we need all the set of variables of the classified object, unlike the more flexible K-nearest neighbours methods where it's enough enough to chose only several variables. The given methods are expedient for using together.
Using neuronets in the system
Another method of classification that is different from the two previous id the neuronet method. The systems based on the neuronets are able effectively deal not only with the problems of classification, but also with those of clusterization. While solving a problem of the clusterization which is known also as a classification "without teacher", there is no training sample with class labels. The algorithm of the clusterization is based on the similarity of objects and places close objects into one cluster.[5]
One of the most widespread architectures — multilayered perceptron with return distribution of the mistake, emulates the work of neurons in the hierarchical network where everyone neuron of a higher level is connected to the outputs of underlaying neurons. The values of input parameters on the basis of which any decisions should be made are sended to the neurons of the lowermost level. For applying the network in future, it should be “trained" before using the data, received before. For this data the values of the input parameters and right answers for them are already known. This training consists in the selection of weights of the interneural communications providing the greatest affinity of the network answers to known right answers. With classification at in advance known set of classes well consults The Rozenblatt's [6] perceptron is good in dealing with classification taks and for the clusterization they often use Kohonen's [7] networks.
The picture shows common scheme of the neuronet training in the system.

Advantages of using neuronets for solving problems of the classification of medical-statistical data are big vollume of the training information which have been saved up during functioning of the Center of medical-statistical information, and also their high efficiency, in the tasks with lots of close laying classes which the mathematical statistics methods will not cope with. A disadvantage of the neural networks is their high requirements to computing resources.
To solve the problems of the classification successfully, the described methods are worth applying together.
Conclusion
Operative analytical processing and intellectual data analysis are the two components for decision-making process. But today the majority of OLAP systems pay attention only to providing access to multidimensional data, and the majority of IDA tools, working in the area of regularities, deal with one-dimensional data perspectives. These two kinds of the analysis should be closely incorporated, that the OLAP systems should be focused not only on the access, but also on the search of the regularities.
K. Parsaye [8] proposes a complex term "OLAP Data Mining" (the multidimentional intellectual analysis) for marking such association. Tools for multidimentional intellectual data analysis should find regularities both in detailed and aggregated data with a various degree of its generalization. Unfortunately, very few manufacturers give today tools for the intellectual analysis of multidimensional data within the limits of OLAP systems — apparently, only SAS Institute has achieved in it. The ideal purpose of an information-analytical system construction is creation of a decision-making system of the closed cycle. As N. Raden has noticed , "many companies have created... Fine data warehouses, having classified ideally mountains of not used information, which doesn't provide itself fast and competent enough reaction to market events" [9]. In the especially dynamical areas where the situation cahanges every day, duly decision-making is not provided even by use of usual OLAP and IDA tools. They should be incorporated with each other and have a feedback to initial systems of data processing so that the results of the the decision-making system functioning be immediately transferred as operating influences to the operative systems.
Thus for now the general structure of the future decision-making system is determined. This structure is based on two systems – the system of data processing and the system of intellectual data analysis. The OLAP mechanism was chosen as a data processing system. Also a review of existing OLAP-technologies is done, and the questions of the application of the given mechanism in the research object are analysed. The existing mechanisms of the intellectual data processing and their application for processing the medical-statistical information are learned in detail.
The application of the OLAP and Data Mining methods together gives an information needed for decision-making using the stored data. The data analysis gives us all the necessary information for decision-making not only in medicine but also in an area of the medical statistics itself, for example allowing to define objects, which data gathering is more necessary than another's. Thus the problem of self-improvement of the control system through a feedback is solved.
However it should be remembered that the final part of a decision-making system is still the human. The OLAP and Data Mining tools allow only to facilitate his task, by allocating an important information that can become a guide to action in an expert's hands.
References:
1) Information system of the public health of the Smolensk region. Description. http://admin.smolensk.ru/~zdrav/s_informsys/i_informwords.htm
2) Shyavelev L. W The ways of the analitical data processing for decision-making support. DBMS. — 1998. — 4-5.
3) K-nearest neighbours method: Introduction. http://www.spc-consulting.ru/dms/Machine Learning/MachineLearning/Overviews/KNearestNeighborsIntroductoryOverview.htm
4)The review of the trader's decision-making methods on the basis of statistical methods of data processing. Roman Popov. (C) Relpress, 1997
5) Anil K. Jain, Jianchang Mao, K.M. Mohiuddin. Artificial Neural Networks: A Tutorial, Computer, Vol.29, No.3, March/1996, pp. 31-44.
6) Rozenblatt F. Neurodynamics principles. The perceptron and the theory of brain mechanisms. M.: Mir, 1965. 480 с.
7) Kohonen T. Associative storage devices. — M.: Mir, 1982.
8) Parsaye K. OLAP and Data Mining: Bridging the Gap // Database Programming and Design. — 1997.
9) Mode J. Goods for use // PC Week/RE. — 1997.
10) Data Mining: The AI Metamorphosis // H.P. Newquist // Database Programming and Design. — 1997. http://www.dbpd.com/vault/newquist.htm