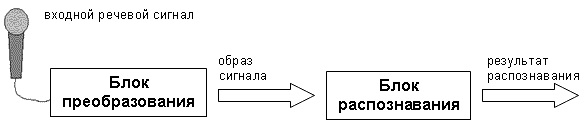
Рисунок 1.1 - Общая схема распознавания речи
Русский | Українська
Email: bond005@yandex.ru
ОГЛАВЛЕНИЕ
Диалог с компьютерами, роботами, автоматизированными системами управления с помощью речевых сообщений открывает большие перспективы:
В связи с увеличением интенсивности обмена информацией в системе «человек-машина» особое значение имеет снижение нагрузки на тактильно-зрительный канал человека. Например, в системах управления востребованной является идея голосового контроля и управления состоянием системы (речевое общение для контроля состояния работы самолета, бескнопочный телефон, речевое управление производственными процессами). Внедрение голосового интерфейса оставит глаза и руки оператора (пилота, водителя, рабочего за станком) свободными от перегрузки, что повысит надёжность и качество управления.
Использование речевого диалога в системах массового обслуживания населения также актуально [Жожикашвили и др., 2003]. Помимо исключительного удобства для населения, такие системы повышают коммерческую выгоду как за счёт привлечения дополнительной клиентуры, так и путём замены человека-оператора компьютерными системами с голосовым интерфейсом.
О всё возрастающей востребованности речевого интерфейса в современных человеко-машинных системах свидетельствует и увеличившееся число коммерческих разработок систем, использующих речевой интерфейс. Так, NaturallySpeaking фирмы Dragon System позволяет редактировать и форматировать текст с помощью собственного текстового процессора без использования клавиатуры и мыши. Компания IBM разработала аналогичную программу, позволяющую осуществлять речевой ввод и форматирование текста в текстовом процессоре MS Word. На практике эти программы показывают недостаточно высокие результаты (при тестировании точность не достигла даже 90% [Лукьянюк, 2006]). Корпорация Microsoft также начала активно заниматься внедрением речевого интерфейса в свои программные продукты. С помощью компонент MS Speech API программист может организовывать речевой интерфейс в любой прикладной программе. Но, несмотря на заявленную в фирменной документации точность распознавания 95% [Буторин, 2005], на практике точность распознавания и, следовательно, надёжность программных систем, использующих речевой интерфейс на основе MS Speech API, невысока.
1 АНАЛИЗ И КЛАССИФИКАЦИЯ ОСНОВНЫХ МЕТОДОВ РАСПОЗНАВАНИЯ РЕЧИ
Реализация речевого диалога основана на решении задачи распознавания речи. Основные этапы распознавания речи приведены на рисунке 1.1.
Рисунок 1.1 - Общая схема распознавания речи
В зависимости от области применения речевого диалога требования к системе распознавания речи будут различными. Например, для систем массового обслуживания населения распознавание должно удовлетворять следующим критериям [Жожикашвили и др., 2003]:
Для систем голосового управления распознавание слитной речи не столь актуально, т.к. управление может осуществляться с помощью ограниченного набора команд (ключевых слов). В случаях ограниченного доступа к системе управления распознавание слов должно быть дикторозависимым (настраиваться на голос одного лица или группы лиц). Но точность распознавания должна быть еще более высокой, поскольку цена ошибки в управлении потенциально опасными устройствами (самолетами, автомобилями и т.д.) слишком высока.
Для создания системы распознавания речи необходимо решить две основные задачи:
Современные устройства распознавания речи не обеспечивают достаточной точности распознавания или распознают малое количество слов, что накладывает большие ограничения на их использование в реальных системах. Это объясняется не самым удачным решением вышеприведенных задач. Поэтому разработка речевых интерфейсов как для различных систем управления, так и для систем массового обслуживания, – это вопрос, остро стоящий на повестке сегодняшнего дня.
Существуют три базовые модели языка:
Наиболее точными с точки зрения распознавания являются системы, основанные на словарной модели, но их область применения ограничена системами управления, имеющими небольшое количество команд. Для распознавания слитной речи в системах массового обслуживания населения более пригодна фонетическая, слоговая или смешанная модель, где используются как фонемы и слоги, так и целые слова (цифры, числа, некоторые команды) [Жожикашвили и др., 2003].
Современные методы распознавания основываются на:
Эталоны формируются путем статистической обработки большого числа шаблонов. Сравнение входного сигнала с эталоном возможно путем нечёткого сопоставления образов [Асаи и др., 1993].
Вторая модель распознавания является более сложной. В ней процесс произношения моделируется с помощью аппарата скрытых марковских цепей или нейронными сетями [Жожикашвили и др., 2003, Иванов и др., 2002]. Использование последних дает большую точность, но требует применения эффективного метода обучения системы (в противном случае обучение может не завершится успехом).
Данная работа посвящена разработке речевого канала управления текстового процессора Microsoft Word, являющегося дополнением к стандартному визуальному интерфейсу. Рациональное сочетание речевого и стандартного визуального способов управления процессом ввода и редактирования текстовой информации позволит снизить нагрузку на тактильно-зрительные каналы человека и тем самым повысить эффективность его работы. Функциональная схема такой системы приведена на рисунке 2.1.
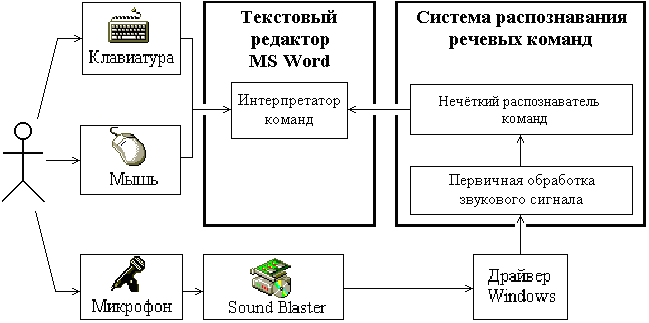
Рисунок 2.1 - Структура речевого канала управления текстовым редактором MS Word
В качестве базовой модели языка используется словарная модель, так как её недостаток – сильная зависимость от словаря – в данном случае является не недостатком, а ограничением предметной области (количество речевых команд и, соответственно, объём словаря известны заранее), а достоинство – наибольшая по сравнению с другими моделями точность – является существенным.
Распознавание речевых команд предлагается осуществлять с помощью подхода, основанного на сопоставлении речевых эталонов. В работе [Асаи и др., 1993] описан метод нечёткого сопоставления образов и приведена высокая оценка его эффективности в распознавании английских, немецких и японских слов. Однако изменения длительности одинаковых речевых образов, обусловленные различной скоростью произношения звуков одних и тех же слов, в указанной работе рассматриваются только как линейные в целях уменьшения объёма вычислений. Но изменение длин речевых образов в общем случае является нелинейным [Винцюк, 1987], поэтому целесообразно оценить учёт этой нелинейности при построении модели временной нормализации.
В данной работе предлагается использовать метод нечёткого DTW-сопоставления [Федяев и др., 2006], в котором нелинейная временная нормализация сравниваемых образов осуществляется на основе метода динамического искажения времени (Dynamic Time Warping, или DTW). Проводится сравнительный анализ эффективности работы системы распознавания, использующей линейную нормализацию, и системы, выравнивающей длины образов по алгоритму DTW.
3 МЕТОДЫ НЕЧЁТКОГО СОПОСТАВЛЕНИЯ И НЕЧЁТКОГО DTW-СОПОСТАВЛЕНИЯ РЕЧЕВЫХ ОБРАЗОВ
3.1 Получение информативных признаков речевого сигнала
Речевой сигнал представляется в виде двумерного спектрального временного образа (СВО), получаемого с помощью краткосрочного преобразования Фурье (рис.3.1а) [Рабинер и др., 1981]. Такой образ отражает изменение по времени амплитуд заданных частотных составляющих речевого сигнала и хорошо выражает особенности речи, что даёт возможность его использовать для автоматического распознавания произносимых слов [Чистович и др., 1976]. СВО позволяет выделить местоположение резонансных частот, т.е. локальных выбросов, что является определяющей особенностью речевого сигнала [Асаи и др., 1993]. На этом основании СВО можно преобразовать к двоичному виду, не теряя указанных информативных признаков речи, с помощью следующей замены: 1 – на месте локального выброса, 0 – в других местах. Полученный образ называют двоичным спектральным временным образом (ДСВО) и используют его как отражение особенностей речевого сигнала (рис. 3.1б).
В качестве единиц речи рассматриваются слова, набор которых определяет словарный состав речевого общения.
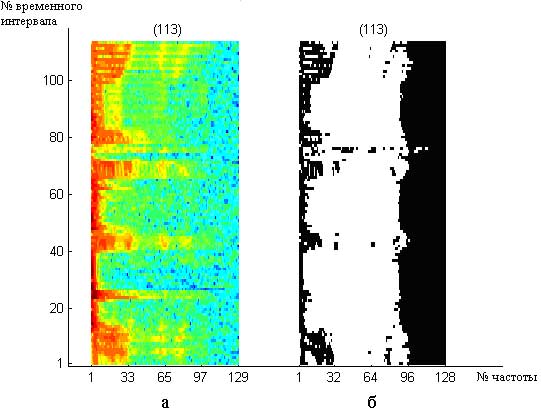
Рисунок 3.1 - Пример спектрально-временного представления слова «автоформат»: а – СВО; б – ДСВО
3.2 Временное выравнивание речевых образов
Различные реализации речевых образов, относящихся к одному и тому же классу, могут значительно отличаться друг от друга по длительности (рис.3.2). Это связано с нестабильностью темпа речи диктора, вызванной влиянием интонации, акцента и т.п. Для корректного сопоставления речевых образов необходимо производить их выравнивание по длине. Выравнивание путём линейного сжатия или растяжения одной реализации слова до величины другой решает задачу лишь частично, так как не учитывается одно важное свойство речевого сигнала – неравномерность его протекания во времени [Винцюк, 1987]. Это свойство речи выражается в неравномерном изменении длительности звуков слова при изменении длительности слова в целом. Поэтому сопоставление целесообразно выполнять с помощью нелинейной временной нормализации [Федяев и др., 2006].
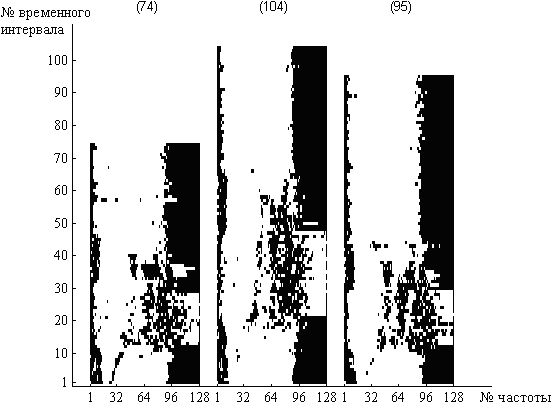
Рисунок 3.2 - ДСВО различных реализаций слова «Курсив»
Для нелинейного выравнивания сопоставляемых образов использовался алгоритм, основанный на определении наилучшего соответствия входных и эталонных речевых образов, известный как метод DTW [Wrigley, 2006]. Суть алгоритма заключается в следующем. Обозначим евклидово расстояние между i-й строкой матрицы входного ДСВО и j-й строкой матрицы эталона как Dij. Для нахождения строк матрицы входного ДСВО, наилучшим образом соответствующих строкам матрицы эталона, определялась матрица C размера (M*N) по следующим формулам:
где M – количество строк матрицы входного ДСВО; N – количество строк матрицы эталона.
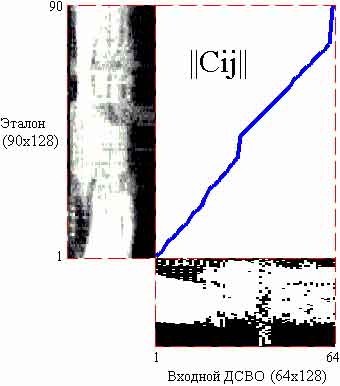
Рисунок 3.3 - Графическое отображение процесса выравнивания входного ДСВО и эталона по алгоритму DTW
На рис. 3.3 ломаной линией соединены элементы матрицы C, отвечающие наиболее соответствующим строкам входного ДСВО и эталона слова «Маркеры». Вертикальному отрезку соответствует случай, когда несколько строк матрицы эталона соответствуют одной строке матрицы входного ДСВО. Горизонтальному отрезку соответствует случай, когда несколько строк матрицы ДСВО соответствуют одной строке матрицы эталона. Таким образом, в отличие от алгоритма линейного приведения длин, данный алгоритм обеспечивает выравнивание только спектрально подобных фрагментов входного ДСВО и эталонного образа.
3.3 Метод нечёткого сопоставления речевых образов
Для распознавания изолированных слов, нормализованных по времени, применялся метод нечёткого сопоставления с эталоном [Асаи и др., 1993]. Эталонные образы для каждого слова словаря формировались как среднее арифметическое ДСВО различных вариантов произношения данного слова. В результате формируется бинарное нечёткое отношение [Кофман, 1982] между множеством F (номеров частот f) и множеством T (номеров временных интервалов t) в виде:
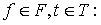 F R T
F R T
где R – нечёткое отношение, которое ставит каждой паре элементов 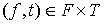 величину функции принадлежности
величину функции принадлежности 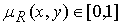 .
.
Обозначим число записанных слов через n, множество слов через I = {i1, i2, ..., in} и множество нечётких отношений, характерных для каждого слова, через R = {r1, r2, ..., rn}. Входной неизвестный образ y рассматривается как обычное (чёткое) отношение между множеством частот и множеством временных интервалов. Для него вычисляются степени сходства Sj с каждым нечётким отношением rj . Результатом распознавания является слово j, такое, что
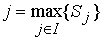
Степень подобия вычисляется по следующей формуле:
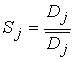 ,
,
где
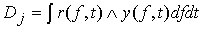 ,
,
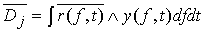 .
.
4 РАЗРАБОТКА МЕТОДИКИ СРАВНИТЕЛЬНОГО АНАЛИЗА МЕТОДОВ РАСПОЗНАВАНИЯ РЕЧЕВЫХ КОМАНД
Были проведены экспериментальные исследования, направленные на определение качества распознавания слов русской речи по методу нечёткого сопоставления при линейном и нелинейном выравнивании образов. Для эксперимента использовалась речевая однодикторная база данных, включавшая в себя звукозаписи 6 речевых команд управления текстовым процессором: «Автоформат», «Жирный», «Курсив», «Маркеры», «Найти», «Нумерация». Каждая речевая команда была представлена 30 реализациями, 15 из которых использовались для обучения системы, а 15 – для тестирования. Таким образом, мощности обучающего и тестового множеств составили 90 различных реализаций вышеперечисленных 6 слов.
Результаты распознавания слов тестового множества по методу нечёткого сопоставления с использованием линейного временного выравнивания представлены в табл. 4.1, а с использованием временного выравнивания по алгоритму DTW – в табл. 4.2.
Таблица 4.1 - Результаты тестирования системы с линейным выравниванием
| Автоформат | Жирный | Курсив | Маркеры | Найти | Нумерация | Итого, % | |
| Автоформат | 15 | 0 | 0 | 0 | 0 | 0 | 100,00 |
| Жирный | 0 | 14 | 0 | 0 | 1 | 0 | 93,22 |
| Курсив | 0 | 0 | 15 | 0 | 0 | 0 | 100,00 |
| Маркеры | 0 | 0 | 0 | 13 | 0 | 2 | 86,67 |
| Найти | 0 | 0 | 0 | 0 | 15 | 0 | 100,00 |
| Нумерация | 0 | 0 | 0 | 0 | 0 | 15 | 100,00 |
| Качество распознавания составило 96,67% | |||||||
Таблица 4.2 - Результаты тестирования системы с DTW-выравниванием
| Автоформат | Жирный | Курсив | Маркеры | Найти | Нумерация | Итого, % | |
| Автоформат | 15 | 0 | 0 | 0 | 0 | 0 | 100,00 |
| Жирный | 0 | 15 | 0 | 0 | 0 | 0 | 100,00 |
| Курсив | 0 | 0 | 15 | 0 | 0 | 0 | 100,00 |
| Маркеры | 0 | 0 | 0 | 15 | 0 | 0 | 100,00 |
| Найти | 0 | 0 | 0 | 0 | 15 | 0 | 100,00 |
| Нумерация | 0 | 0 | 0 | 0 | 0 | 15 | 100,00 |
| Качество распознавания составило 100,00% | |||||||
Для проверки гипотезы о том, что DTW-выравнивание не дало существенного улучшения качества распознавания, то есть гипотезы о равенстве медиан двух выборок (нулевой гипотезе), предлагается использовать знаковый критерий Вилкоксона с уровнем значимости 0,01 [Ермаков и др., 1982]. Знаковый критерий Вилкоксона не требует непротиворечивости распределения генеральной совокупности значений случайной величины нормальному закону [Ермаков и др., 1982], поэтому он может использоваться для проверки интересующей нас гипотезы.
Вычисления выполнялись в системе MATLAB 6.5 [Дьяконов и др., 2001]. В результате нулевая гипотеза была подтверждена, то есть внедрение DTW-сопоставления в процедуру нечёткого сопоставления образов не дало коренных улучшений. Но результаты проведённого теста нельзя считать объективными по двум причинам:
Сейчас завершается формирование речевой базы данных объёмом более чем 12600 реализаций слов, разбитых на 105 классов (речевых команд управления текстовым процессором MS Word). В формировании речевой базы данных принимало участие 43 диктора. Эксперименты на материале этой речевой базы позволит более объективно сравнить метод нечёткого сопоставления образов, использующий линейную временную нормализацию, и предложенную в данной работе его модификацию, основанную на нелинейной временной нормализации.
В результате работы был создан метод нечёткого DTW-сопоставления для распознавания изолированных речевых слов, какими можно считать речевые команды управления текстовым редактором, и разработана методика сравнительного анализа методов распознавания изолированных речевых слов. Применение этой методики для оценки эффективности внедрения DTW-сопоставления в процедуру нечёткого сопоставления образов показало, что DTW-сопоставление не привело к существенному улучшению качества работы метода нечёткого сопоставления образов. Однако необходимы дальнейшие исследования эффективности использования DTW-сопоставления при нечётком сопоставлении образов, потому что результаты проведённого теста нельзя считать объективными по двум причинам:
В дальнейшем планируется проведение экспериментов на материале речевой базы данных объёмом более чем 12600 реализаций слов, разбитых на 105 классов (речевых команд управления текстовым процессором MS Word). В формировании речевой базы данных принимало участие 43 диктора. Эксперименты на материале этой речевой базы позволят более объективно сравнить метод нечёткого сопоставления образов, использующий линейную временную нормализацию, и предложенную в данной работе его модификацию, основанную на нелинейной временной нормализации.
Также в результате тестирования был найден оптимальный баланс по критерию эргономичности между речевой и тактильно-зрительной составляющей интерфейса с текстовым редактором. Через речевой канал интерфейса целесообразно организовывать передачу наиболее употребительных команд, а также макрокоманд (последовательностей простых действий), связанных со сложным редактированием документа. Тактильно-зрительный канал целесообразно использовать для передачи команд, связанных с позиционированием фрагментов документа в пространстве.
На момент написания автореферата (июнь 2006) диссертация не является законченной. Планируемое время окончания работы - октябрь 2006.