Нейронные сети
-
Основные положения.
-
Алгоритм обратного распространения.
-
Обучение без учителя.
-
Нейронные сети Хопфилда и Хэмминга.
Основные положения.
В статье рассмотрены основы теории нейронных сетей, позволяющие в дальнейшем обратиться к конкретным структурам, алгоритмам и идеологии практического применения сетей в компьютерных приложениях.
В последние десятилетия в мире бурно развивается новая прикладная область математики, специализирующаяся на искусственных нейронных сетях (НС). Актуальность исследований в этом направлении подтверждается массой различных применений НС. Это автоматизация процессов распознавания образов, адаптивное управление, аппроксимация функционалов, прогнозирование, создание экспертных систем, организация ассоциативной памяти и многие другие приложения. С помощью НС можно, например, предсказывать показатели биржевого рынка, выполнять распознавание оптических или звуковых сигналов, создавать самообучающиеся системы, способные управлять автомашиной при парковке или синтезировать речь по тексту. В то время как на западе применение НС уже достаточно обширно, у нас это еще в некоторой степени экзотика – российские фирмы, использующие НС в практических целях, наперечет [1].
Широкий круг задач, решаемый НС, не позволяет в настоящее время создавать универсальные, мощные сети, вынуждая разрабатывать специализированные НС, функционирующие по различным алгоритмам.
Модели НС могут быть программного и аппаратного исполнения. В дальнейшем речь пойдет в основном о первом типе.
Несмотря на существенные различия, отдельные типы НС обладают несколькими общими чертами.
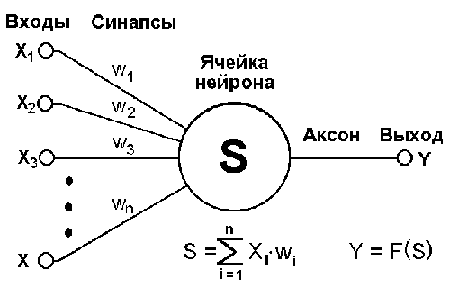
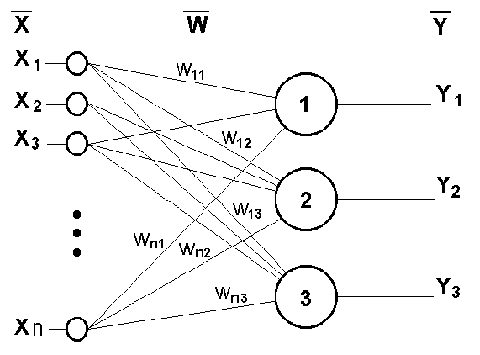
Во-первых, основу каждой НС составляют относительно простые, в большинстве случаев – однотипные, элементы (ячейки), имитирующие работу нейронов мозга. Далее под нейроном будет подразумеваться искусственный нейрон, то есть ячейка НС. Каждый нейрон характеризуется своим текущим состоянием по аналогии с нервными клетками головного мозга, которые могут быть возбуждены или заторможены. Он обладает группой синапсов – однонаправленных входных связей, соединенных с выходами других нейронов, а также имеет аксон – выходную связь данного нейрона, с которой сигнал (возбуждения или торможения) поступает на синапсы следующих нейронов. Общий вид нейрона приведен на рисунке 1. Каждый синапс характеризуется величиной синаптической связи или ее весом wi, который по физическому смыслу эквивалентен электрической проводимости.
Текущее состояние нейрона определяется, как взвешенная сумма его входов:
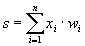 (1)
(1)
Выход нейрона есть функция его состояния:
y = f(s) (2)
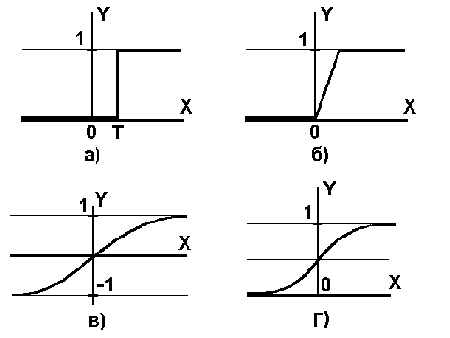
Нелинейная функция f называется активационной и может иметь различный вид, как показано на рисунке 2. Одной из наиболее распространеных является нелинейная функция с насыщением, так называемая логистическая функция или сигмоид (т.е. функция S-образного вида)[2]:
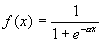 (3)
(3)
При уменьшении a сигмоид становится более пологим, в пределе при a =0 вырождаясь в горизонтальную линию на уровне 0.5, при увеличении a сигмоид приближается по внешнему виду к функции единичного скачка с порогом T в точке x=0. Из выражения для сигмоида очевидно, что выходное значение нейрона лежит в диапазоне [0,1]. Одно из ценных свойств сигмоидной функции – простое выражение для ее производной, применение которого будет рассмотрено в дальнейшем.
![]() (4)
(4)
Следует отметить, что сигмоидная функция дифференцируема на всей оси абсцисс, что используется в некоторых алгоритмах обучения. Кроме того она обладает свойством усиливать слабые сигналы лучше, чем большие, и предотвращает насыщение от больших сигналов, так как они соответствуют областям аргументов, где сигмоид имеет пологий наклон.
Возвращаясь к общим чертам, присущим всем НС, отметим, во-вторых, принцип параллельной обработки сигналов, который достигается путем объединения большого числа нейронов в так называемые слои и соединения определенным образом нейронов различных слоев, а также, в некоторых конфигурациях, и нейронов одного слоя между собой, причем обработка взаимодействия всех нейронов ведется послойно.
В качестве примера простейшей НС рассмотрим трехнейронный перцептрон (рис.3), то есть такую сеть, нейроны которой имеют активационную функцию в виде единичного скачка* . На n входов поступают некие сигналы, проходящие по синапсам на 3 нейрона, образующие единственный слой этой НС и выдающие три выходных сигнала:
 , j=1...3 (5)
, j=1...3 (5)
Очевидно, что все весовые коэффициенты синапсов одного слоя нейронов можно свести в матрицу W, в которой каждый элемент wij задает величину i-ой синаптической связи j-ого нейрона. Таким образом, процесс, происходящий в НС, может быть записан в матричной форме:
Y=F(XW) (6)
где X и Y – соответственно входной и выходной сигнальные векторы, F( V) – активационная функция, применяемая поэлементно к компонентам вектора V.
Теоретически число слоев и число нейронов в каждом слое может быть произвольным, однако фактически оно ограничено ресурсами компьютера или специализированной микросхемы, на которых обычно реализуется НС. Чем сложнее НС, тем масштабнее задачи, подвластные ей.
Выбор структуры НС осуществляется в соответствии с особенностями и сложностью задачи. Для решения некоторых отдельных типов задач уже существуют оптимальные, на сегодняшний день, конфигурации, описанные, например, в [2],[3],[4] и других изданиях, перечисленных в конце статьи. Если же задача не может быть сведена ни к одному из известных типов, разработчику приходится решать сложную проблему синтеза новой конфигурации. При этом он руководствуется несколькими основополагающими принципами: возможности сети возрастают с увеличением числа ячеек сети, плотности связей между ними и числом выделенных слоев (влияние числа слоев на способность сети выполнять классификацию плоских образов показано на рис.4 из [5]); введение обратных связей наряду с увеличением возможностей сети поднимает вопрос о динамической устойчивости сети; сложность алгоритмов функционирования сети (в том числе, например, введение нескольких типов синапсов – возбуждающих, тромозящих и др.) также способствует усилению мощи НС. Вопрос о необходимых и достаточных свойствах сети для решения того или иного рода задач представляет собой целое направление нейрокомпьютерной науки. Так как проблема синтеза НС сильно зависит от решаемой задачи, дать общие подробные рекомендации затруднительно. В большинстве случаев оптимальный вариант получается на основе интуитивного подбора.
Очевидно, что процесс функционирования НС, то есть сущность действий, которые она способна выполнять, зависит от величин синаптических связей, поэтому, задавшись определенной структурой НС, отвечающей какой-либо задаче, разработчик сети должен найти оптимальные значения всех переменных весовых коэффициентов (некоторые синаптические связи могут быть постоянными).
Этот этап называется обучением НС, и от того, насколько качественно он будет выполнен, зависит способность сети решать поставленные перед ней проблемы во время эксплуатации. На этапе обучения кроме параметра качества подбора весов важную роль играет время обучения. Как правило, эти два параметра связаны обратной зависимостью и их приходится выбирать на основе компромисса.
Обучение НС может вестись с учителем или без него. В первом случае сети предъявляются значения как входных, так и желательных выходных сигналов, и она по некоторому внутреннему алгоритму подстраивает веса своих синаптических связей. Во втором случае выходы НС формируются самостоятельно, а веса изменяются по алгоритму, учитывающему только входные и производные от них сигналы.
Существует великое множество различных алгоритмов обучения, которые однако делятся на два больших класса: детерминистские и стохастические. В первом из них подстройка весов представляет собой жесткую последовательность действий, во втором – она производится на основе действий, подчиняющихся некоторому случайному процессу.
Развивая дальше вопрос о возможной классификации НС, важно отметить существование бинарных и аналоговых сетей. Первые из них оперируют с двоичными сигналами, и выход каждого нейрона может принимать только два значения: логический ноль ("заторможенное" состояние) и логическая единица ("возбужденное" состояние). К этому классу сетей относится и рассмотренный выше перцептрон, так как выходы его нейронов, формируемые функцией единичного скачка, равны либо 0, либо 1. В аналоговых сетях выходные значения нейронов способны принимать непрерывные значения, что могло бы иметь место после замены активационной функции нейронов перцептрона на сигмоид.
Еще одна классификация делит НС на синхронные и асинхронные[3]. В первом случае в каждый момент времени свое состояние меняет лишь один нейрон. Во втором – состояние меняется сразу у целой группы нейронов, как правило, у всего слоя. Алгоритмически ход времени в НС задается итерационным выполнением однотипных действий над нейронами. Далее будут рассматриваться только синхронные НС.

Сети также можно классифицировать по числу слоев. На рисунке 4 представлен двухслойный перцептрон, полученный из перцептрона с рисунка 3 путем добавления второго слоя, состоящего из двух нейронов. Здесь уместно отметить важную роль нелинейности активационной функции, так как, если бы она не обладала данным свойством или не входила в алгоритм работы каждого нейрона, результат функционирования любой p-слойной НС с весовыми матрицами W(i), i=1,2,...p для каждого слоя i сводился бы к перемножению входного вектора сигналов X на матрицу
W(S )=W(1)× W(2) × ...× W(p) (7)
то есть фактически такая p-слойная НС эквивалентна однослойной НС с весовой матрицей единственного слоя W(S ):
Y=XW(S ) (8)
Продолжая разговор о нелинейности, можно отметить, что она иногда вводится и в синаптические связи. Большинство известных на сегодняшний день НС используют для нахождения взвешенной суммы входов нейрона формулу (1), однако в некоторых приложениях НС полезно ввести другую запись, например:
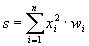 (9)
(9)
или даже
 (10)
(10)
Вопрос в том, чтобы разработчик НС четко понимал, для чего он это делает, какими ценными свойствами он тем самым дополнительно наделяет нейрон, и каких лишает. Введение такого рода нелинейности, вообще говоря, увеличивает вычислительную мощь сети, то есть позволяет из меньшего числа нейронов с "нелинейными" синапсами сконструировать НС, выполняющую работу обычной НС с большим числом стандартных нейронов и более сложной конфигурации[4].
Многообразие существующих структур НС позволяет отыскать и другие критерии для их классификации, но они выходят за рамки данной статьи.
Теперь рассмотрим один нюанс, преднамеренно опущенный ранее. Из рисунка функции единичного скачка видно, что пороговое значение T, в общем случае, может принимать произвольное значение. Более того, оно должно принимать некое произвольное, неизвестное заранее значение, которое подбирается на стадии обучения вместе с весовыми коэффициентами. То же самое относится и к центральной точке сигмоидной зависимости, которая может сдвигаться вправо или влево по оси X, а также и ко всем другим активационным функциям. Это, однако, не отражено в формуле (1), которая должна была бы выглядеть так:
 (11)
(11)
Дело в том, что такое смещение обычно вводится путем добавления к слою нейронов еще одного входа, возбуждающего дополнительный синапс каждого из нейронов, значение которого всегда равняется 1. Присвоим этому входу номер 0. Тогда
 (12)
(12)
где w0 = –T, x0 = 1.
Очевидно, что различие формул (1) и (12) состоит лишь в способе нумерации входов.
Из всех активационных функций, изображенных на рисунке 2, одна выделяется особо. Это гиперболический тангенс, зависимость которого симметрична относительно оси X и лежит в диапазоне [-1,1]. Забегая вперед, скажем, что выбор области возможных значений выходов нейронов во многом зависит от конкретного типа НС и является вопросом реализации, так как манипуляции с ней влияют на различные показатели эффективности сети, зачастую не изменяя общую логику ее работы. Пример, иллюстрирующий данный аспект, будет представлен после перехода от общего описания к конкретным типам НС.
Какие задачи может решать НС? Грубо говоря, работа всех сетей сводится к классификации (обобщению) входных сигналов, принадлежащих n-мерному гиперпространству, по некоторому числу классов. С математической точки зрения это происходит путем разбиения гиперпространства гиперплоскостями (запись для случая однослойного перцептрона)
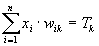 , k=1...m (13)
, k=1...m (13)
|
x1 x2 |
0 |
1 |
|
0 |
A |
B |
|
1 |
B |
A |
Каждая полученная область является областью определения отдельного класса. Число таких классов для одной НС перцептронного типа не превышает 2m, где m – число выходов сети. Однако не все из них могут быть разделимы данной НС.
Например, однослойный перцептрон, состоящий из одного нейрона с двумя входами, представленный на рисунке 5, не способен разделить плоскость (двумерное гиперпространоство) на две полуплоскости так, чтобы осуществить классификацию входных сигналов по классам A и B (см. таблицу 1).
Уравнение сети для этого случая
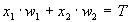 (14)
(14)
является уравнением прямой (одномерной гиперплоскости), которая ни при каких условиях не может разделить плоскость так, чтобы точки из множества входных сигналов, принадлежащие разным классам, оказались по разные стороны от прямой (см. рисунок 6).
Если присмотреться к таблице 1, можно заметить, что данное разбиение на классы реализует логическую функцию исключающего ИЛИ для входных сигналов. Невозможность реализации однослойным перцептроном этой функции получила название проблемы исключающего ИЛИ.

Функции, которые не реализуются однослойной сетью, называются линейно неразделимыми[2]. Решение задач, подпадающих под это ограничение, заключается в применении 2-х и более слойных сетей или сетей с нелинейными синапсами, однако и тогда существует вероятность, что корректное разделение некоторых входных сигналов на классы невозможно.
Наконец, мы можем более подробно рассмотреть вопрос обучения НС, для начала – на примере перцептрона с рисунка 3.
Рассмотрим алгоритм обучения с учителем[2][4].
1. Проинициализировать элементы весовой матрицы (обычно небольшими случайными значениями).
2. Подать на входы один из входных векторов, которые сеть должна научиться различать, и вычислить ее выход.
3. Если выход правильный, перейти на шаг 4.
Иначе вычислить разницу между идеальным и полученным значениями выхода:
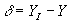
Модифицировать веса в соответствии с формулой:
![]()
где t и t+1 – номера соответственно текущей и следующей итераций; n – коэффициент скорости обучения, 0<n Ј1; i – номер входа; j – номер нейрона в слое.
Очевидно, что если YI > Y весовые коэффициенты будут увеличены и тем самым уменьшат ошибку. В противном случае они будут уменьшены, и Y тоже уменьшится, приближаясь к YI.
4. Цикл с шага 2, пока сеть не перестанет ошибаться.
На втором шаге на разных итерациях поочередно в случайном порядке предъявляются все возможные входные вектора. К сожалению, нельзя заранее определить число итераций, которые потребуется выполнить, а в некоторых случаях и гарантировать полный успех. Этот вопрос будет косвенно затронут в дальнейшем.
В завершении данной вводной статьи хотелось бы отметить, что дальнейшее рассмотрение НС будет в основном тяготеть к таким применениям, как распознавание образов, их классификация и, в незначительной степени, сжатие информации. Более подробно об этих и других применениях и реализующих их структурах НС можно прочитать в журналах Neural Computation, Neural Computing and Applications, Neural Networks, IEEE Transactions on Neural Networks, IEEE Transactions on System, Man, and Cybernetics и других.
Литература
- Е. Монахова, "Нейрохирурги" с Ордынки, PC Week/RE, №9, 1995.
- Ф.Уоссермен, Нейрокомпьютерная техника, М.,Мир, 1992.
- Итоги науки и техники: физические и математические модели нейронных сетей, том 1, М., изд. ВИНИТИ, 1990.
- Artificial Neural Networks: Concepts and Theory, IEEE Computer Society Press, 1992.
- Richard P. Lippmann, An Introduction to Computing withNeural Nets, IEEE Acoustics, Speech, and Signal ProcessingMagazine, April 1987.
Алгоритм обратного распространения.
В статье рассмотрен алгоритм обучения нейронной сети с помощью процедуры обратного распространения, описана библиотека классов для С++.
Среди различных структур нейронных сетей (НС) одной из наиболее известных является многослойная структура, в которой каждый нейрон произвольного слоя связан со всеми аксонами нейронов предыдущего слоя или, в случае первого слоя, со всеми входами НС. Такие НС называются полносвязными. Когда в сети только один слой, алгоритм ее обучения с учителем довольно очевиден, так как правильные выходные состояния нейронов единственного слоя заведомо известны, и подстройка синаптических связей идет в направлении, минимизирующем ошибку на выходе сети. По этому принципу строится, например, алгоритм обучения однослойного перцептрона[1]. В многослойных же сетях оптимальные выходные значения нейронов всех слоев, кроме последнего, как правило, не известны, и двух или более слойный перцептрон уже невозможно обучить, руководствуясь только величинами ошибок на выходах НС. Один из вариантов решения этой проблемы – разработка наборов выходных сигналов, соответствующих входным, для каждого слоя НС, что, конечно, является очень трудоемкой операцией и не всегда осуществимо. Второй вариант – динамическая подстройка весовых коэффициентов синапсов, в ходе которой выбираются, как правило, наиболее слабые связи и изменяются на малую величину в ту или иную сторону, а сохраняются только те изменения, которые повлекли уменьшение ошибки на выходе всей сети. Очевидно, что данный метод "тыка", несмотря на свою кажущуюся простоту, требует громоздких рутинных вычислений. И, наконец, третий, более приемлемый вариант – распространение сигналов ошибки от выходов НС к ее входам, в направлении, обратном прямому распространению сигналов в обычном режиме работы. Этот алгоритм обучения НС получил название процедуры обратного распространения. Именно он будет рассмотрен в дальнейшем.
Согласно методу наименьших квадратов, минимизируемой целевой функцией ошибки НС является величина:
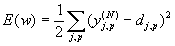 (1)
(1)
где 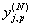 – реальное выходное состояние нейрона j выходного слоя N нейронной сети при
подаче на ее входы p-го образа; djp
– идеальное (желаемое) выходное состояние этого нейрона.
– реальное выходное состояние нейрона j выходного слоя N нейронной сети при
подаче на ее входы p-го образа; djp
– идеальное (желаемое) выходное состояние этого нейрона.
Суммирование ведется по всем нейронам выходного слоя и по всем обрабатываемым сетью образам. Минимизация ведется методом градиентного спуска, что означает подстройку весовых коэффициентов следующим образом:
 (2)
(2)
Здесь wij – весовой коэффициент синаптической связи, соединяющей i-ый нейрон слоя n-1 с j-ым нейроном слоя n, h – коэффициент скорости обучения, 0<h <1.
Как показано в [2],
 (3)
(3)
Здесь под yj, как и раньше, подразумевается выход нейрона j, а под sj – взвешенная сумма его входных сигналов, то есть аргумент активационной функции. Так как множитель dyj/dsj является производной этой функции по ее аргументу, из этого следует, что производная активационной функция должна быть определена на всей оси абсцисс. В связи с этим функция единичного скачка и прочие активационные функции с неоднородностями не подходят для рассматриваемых НС. В них применяются такие гладкие функции, как гиперболический тангенс или классический сигмоид с экспонентой. В случае гиперболического тангенса
 (4)
(4)
Третий множитель ¶ sj/¶ wij, очевидно, равен выходу нейрона предыдущего слоя yi(n-1).
Что касается первого множителя в (3), он легко раскладывается следующим образом[2]:
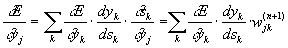 (5)
(5)
Здесь суммирование по k выполняется среди нейронов слоя n+1.
Введя новую переменную
 (6)
(6)
мы получим рекурсивную формулу для расчетов величин d j(n) слоя n из величин d k(n+1) более старшего слоя n+1.
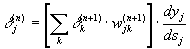 (7)
(7)
Для выходного же слоя
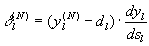 (8)
(8)
Теперь мы можем записать (2) в раскрытом виде:
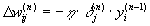 (9)
(9)
Иногда для придания процессу коррекции весов некоторой инерционности, сглаживающей резкие скачки при перемещении по поверхности целевой функции, (9) дополняется значением изменения веса на предыдущей итерации
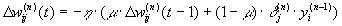 (10)
(10)
где m – коэффициент инерционности, t – номер текущей итерации.
Таким образом, полный алгоритм обучения НС с помощью процедуры обратного распространения строится так:
1. Подать на входы сети один из возможных образов и в режиме обычного функционирования НС, когда сигналы распространяются от входов к выходам, рассчитать значения последних. Напомним, что
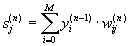 (11)
(11)
где M – число нейронов в слое n-1 с учетом нейрона с постоянным выходным состоянием +1, задающего смещение; yi(n-1)=xij(n) – i-ый вход нейрона j слоя n.
yj(n) = f(sj(n) ), где f() – сигмоид (12)
yq(0)=Iq, (13)
где Iq – q-ая компонента вектора входного образа.
2. Рассчитать d (N) для выходного слоя по формуле (8).
Рассчитать по формуле (9) или (10) изменения весов D w(N) слоя N.
3. Рассчитать по формулам (7) и (9) (или (7) и (10)) соответственно d (n) и D w(n) для всех остальных слоев, n=N-1,...1.
4. Скорректировать все веса в НС
 (14)
(14)
5. Если ошибка сети существенна, перейти на шаг 1. В противном случае – конец.

Сети на шаге 1 попеременно в случайном порядке предъявляются все тренировочные образы, чтобы сеть, образно говоря, не забывала одни по мере запоминания других. Алгоритм иллюстрируется рисунком 1.
Из выражения (9) следует, что когда выходное значение yi(n-1) стремится к нулю, эффективность обучения заметно снижается. При двоичных входных векторах в среднем половина весовых коэффициентов не будет корректироваться[3], поэтому область возможных значений выходов нейронов [0,1] желательно сдвинуть в пределы [-0.5,+0.5], что достигается простыми модификациями логистических функций. Например, сигмоид с экспонентой преобразуется к виду
 (15)
(15)
Теперь коснемся вопроса емкости НС, то есть числа образов, предъявляемых на ее входы, которые она способна научиться распознавать. Для сетей с числом слоев больше двух, он остается открытым. Как показано в [4], для НС с двумя слоями, то есть выходным и одним скрытым слоем, детерминистская емкость сети Cd оценивается так:
Nw/Ny<Cd<Nw/Ny× log(Nw/Ny) (16)
где Nw – число подстраиваемых весов, Ny – число нейронов в выходном слое.
Следует отметить, что данное выражение получено с учетом некоторых ограничений. Во-первых, число входов Nx и нейронов в скрытом слое Nh должно удовлетворять неравенству Nx+Nh>Ny. Во-вторых, Nw/Ny>1000. Однако вышеприведенная оценка выполнялась для сетей с активационными функциями нейронов в виде порога, а емкость сетей с гладкими активационными функциями, например – (15), обычно больше[4]. Кроме того, фигурирующее в названии емкости прилагательное "детерминистский" означает, что полученная оценка емкости подходит абсолютно для всех возможных входных образов, которые могут быть представлены Nx входами. В действительности распределение входных образов, как правило, обладает некоторой регулярностью, что позволяет НС проводить обобщение и, таким образом, увеличивать реальную емкость. Так как распределение образов, в общем случае, заранее не известно, мы можем говорить о такой емкости только предположительно, но обычно она раза в два превышает емкость детерминистскую.
В продолжение разговора о емкости НС логично затронуть вопрос о требуемой мощности выходного слоя сети, выполняющего окончательную классификацию образов. Дело в том, что для разделения множества входных образов, например, по двум классам достаточно всего одного выхода. При этом каждый логический уровень – "1" и "0" – будет обозначать отдельный класс. На двух выходах можно закодировать уже 4 класса и так далее. Однако результаты работы сети, организованной таким образом, можно сказать – "под завязку", – не очень надежны. Для повышения достоверности классификации желательно ввести избыточность путем выделения каждому классу одного нейрона в выходном слое или, что еще лучше, нескольких, каждый из которых обучается определять принадлежность образа к классу со своей степенью достоверности, например: высокой, средней и низкой. Такие НС позволяют проводить классификацию входных образов, объединенных в нечеткие (размытые или пересекающиеся) множества. Это свойство приближает подобные НС к условиям реальной жизни.
Рассматриваемая НС имеет несколько "узких мест". Во-первых, в процессе обучения может возникнуть ситуация, когда большие положительные или отрицательные значения весовых коэффициентов сместят рабочую точку на сигмоидах многих нейронов в область насыщения. Малые величины производной от логистической функции приведут в соответствие с (7) и (8) к остановке обучения, что парализует НС. Во-вторых, применение метода градиентного спуска не гарантирует, что будет найден глобальный, а не локальный минимум целевой функции. Эта проблема связана еще с одной, а именно – с выбором величины скорости обучения. Доказательство сходимости обучения в процессе обратного распространения основано на производных, то есть приращения весов и, следовательно, скорость обучения должны быть бесконечно малыми, однако в этом случае обучение будет происходить неприемлемо медленно. С другой стороны, слишком большие коррекции весов могут привести к постоянной неустойчивости процесса обучения. Поэтому в качестве h обычно выбирается число меньше 1, но не очень маленькое, например, 0.1, и оно, вообще говоря, может постепенно уменьшаться в процессе обучения. Кроме того, для исключения случайных попаданий в локальные минимумы иногда, после того как значения весовых коэффициентов застабилизируются, h кратковременно сильно увеличивают, чтобы начать градиентный спуск из новой точки. Если повторение этой процедуры несколько раз приведет алгоритм в одно и то же состояние НС, можно более или менее уверенно сказать, что найден глобальный максимум, а не какой-то другой.
Существует и иной метод исключения локальных минимумов, а заодно и паралича НС, заключающийся в применении стохастических НС, но о них лучше поговорить отдельно.
Теперь мы можем обратиться непосредственно к программированию НС. Следует отметить, что число зарубежных публикаций, рассматривающих программную реализацию сетей, ничтожно мало по сравнению с общим числом работ на тему нейронных сетей, и это при том, что многие авторы опробывают свои теоретические выкладки именно программным способом, а не с помощью нейрокомпьютеров и нейроплат, в первую очередь из-за их дороговизны. Возможно, это вызвано тем, что к программированию на западе относятся как к ремеслу, а не науке. Однако в результате такой дискриминации остаются неразобранными довольно важные вопросы.
Как видно из формул, описывающих алгоритм функционирования и обучения НС, весь этот процесс может быть записан и затем запрограммирован в терминах и с применением операций матричной алгебры, что сделано, например, в [5]. Судя по всему, такой подход обеспечит более быструю и компактную реализацию НС, нежели ее воплощение на базе концепций объектно-ориентированного (ОО) программирования. Однако в последнее время преобладает именно ОО подход, причем зачастую разрабатываются специальные ОО языки для программирования НС[6], хотя, с моей точки зрения, универсальные ОО языки, например C++ и Pascal, были созданы как раз для того, чтобы исключить необходимость разработки каких-либо других ОО языков, в какой бы области их не собирались применять.
И все же программирование НС с применением ОО подхода имеет свои плюсы. Во-первых, оно позволяет создать гибкую, легко перестраиваемую иерархию моделей НС. Во-вторых, такая реализация наиболее прозрачна для программиста, и позволяет конструировать НС даже непрограммистам. В-третьих, уровень абстрактности программирования, присущий ОО языкам, в будущем будет, по-видимому, расти, и реализация НС с ОО подходом позволит расширить их возможности. Исходя из вышеизложенных соображений, приведенная в листингах библиотека классов и программ, реализующая полносвязные НС с обучением по алгоритму обратного распространения, использует ОО подход. Вот основные моменты, требующие пояснений.
Прежде всего необходимо отметить, что библиотека была составлена и использовалась в целях распознавания изображений, однако применима и в других приложениях. В файле neuro.h в листинге 1 приведены описания двух базовых и пяти производных (рабочих) классов: Neuron, SomeNet и NeuronFF, NeuronBP, LayerFF, LayerBP, NetBP, а также описания нескольких общих функций вспомогательного назначения, содержащихся в файле subfun.cpp (см.листинг 4). Методы пяти вышеупомянутых рабочих классов внесены в файлы neuro_ff.cpp и neuro_bp.cpp, представленные в листингах 2 и 3. Такое, на первый взгляд искусственное, разбиение объясняется тем, что классы с суффиксом _ff, описывающие прямопоточные нейронные сети (feedforward), входят в состав не только сетей с обратным распространением – _bp (backpropagation), но и других, например таких, как с обучением без учителя, которые будут рассмотрены в дальнейшем. Иерархия классов приведенной библиотеки приведена на рисунке 2.
В ущерб принципам ОО программирования, шесть основных параметров, характеризующих работу сети, вынесены на глобальный уровень, что облегчает операции с ними. Параметр SigmoidType определяет вид активационной функции. В методе NeuronFF::Sigmoid перечислены некоторые его значения, макроопределения которых сделаны в заголовочном файле. Пункты HARDLIMIT и THRESHOLD даны для общности, но не могут быть использованы в алгоритме обратного распространения, так как соответствующие им активационные функции имеют производные с особыми точками. Это отражено в методе расчета производной NeuronFF::D_Sigmoid, из которого эти два случая исключены. Переменная SigmoidAlfa задает крутизну a сигмоида ORIGINAL из (15). MiuParm и NiuParm – соответственно значения параметров m и h из формулы (10). Величина Limit используется в методах IsConverged для определения момента, когда сеть обучится или попадет в паралич. В этих случаях изменения весов становятся меньше малой величины Limit. Параметр dSigma эмулирует плотность шума, добавляемого к образам во время обучения НС. Это позволяет из конечного набора "чистых" входных образов генерировать практически неограниченное число "зашумленных" образов. Дело в том, что для нахождения оптимальных значений весовых коэффициентов число степеней свободы НС – Nw должно быть намного меньше числа накладываемых ограничений – Ny× Np, где Np – число образов, предъявляемых НС во время обучения. Фактически, параметр dSigma равен числу входов, которые будут инвертированы в случае двоичного образа. Если dSigma = 0, помеха не вводится.
Методы Randomize позволяют перед началом обучения установить весовые коэффициенты в случайные значения в диапазоне [-range,+range]. Методы Propagate выполняют вычисления по формулам (11) и (12). Метод NetBP::CalculateError на основе передаваемого в качестве аргумента массива верных (желаемых) выходных значений НС вычисляет величины d . Метод NetBP::Learn рассчитывает изменения весов по формуле (10), методы Update обновляют весовые коэффициенты. Метод NetBP::Cycle объединяет в себе все процедуры одного цикла обучения, включая установку входных сигналов NetBP::SetNetInputs. Различные методы PrintXXX и LayerBP::Show позволяют контролировать течение процессов в НС, но их реализация не имеет принципиального значения, и простые процедуры из приведенной библиотеки могут быть при желании переписаны, например, для графического режима. Это оправдано и тем, что в алфавитно-цифровом режиме уместить на экране информацию о сравнительно большой НС уже не удается.
Сети могут конструироваться посредством NetBP(unsigned), после чего их нужно заполнять сконструированными ранее слоями с помощью метода NetBP::SetLayer, либо посредством NetBP(unsigned, unsigned,...). В последнем случае конструкторы слоев вызываются автоматически. Для установления синаптических связей между слоями вызывается метод NetBP::FullConnect.
После того как сеть обучится, ее текущее состояние можно записать в файл (метод NetBP::SaveToFile), а затем восстановить с помощью метода NetBP::LoadFromFile, который применим лишь к только что сконструированной по NetBP(void) сети.
Для ввода в сеть входных образов, а на стадии обучения – и для задания выходных, написаны три метода: SomeNet::OpenPatternFile, SomeNet::ClosePatternFile и NetBP::LoadNextPattern. Если у файлов образов произвольное расширение, то входные и выходные вектора записываются чередуясь: строка с входным вектором, строка с соответствующим ему выходным вектором и т.д. Каждый вектор есть последовательность действительных чисел в диапазоне [-0.5,+0.5], разделенных произвольным числом пробелов (см. листинг 7). Если файл имеет расширение IMG, входной вектор представляется в виде матрицы символов размером dy*dx (величины dx и dy должны быть заблаговременно установлены с помощью LayerFF::SetShowDim для нулевого слоя), причем символ 'x' соответствует уровню 0.5, а точка – уровню -0.5, то есть файлы IMG, по крайней мере – в приведенной версии библиотеки, бинарны (см. листинг 8). Когда сеть работает в нормальном режиме, а не обучается, строки с выходными векторами могут быть пустыми. Метод SomeNet::SetLearnCycle задает число проходов по файлу образов, что в сочетании с добавлением шума позволяет получить набор из нескольких десятков и даже сотен тысяч различных образов.
В листингах 5 и 6 приведены программы, конструирующие и обучающие НС, а также использующие ее в рабочем режиме распознавания изображений.
Особо следует отметить тот нюанс, что в рассматриваемой библиотеке классов НС отсутствует реализация подстраиваемого порога для каждого нейрона. Сеть, вообще говоря, может работать и без него, однако процесс обучения от этого замедляется[3]. Простой, хотя и не самый эффективный способ ввести для нейронов каждого слоя регулируемое смещение заключается в добавлении в класс NeuronFF метода Saturate, который принудительно устанавливал бы выход нейрона в состояние насыщения axon=0.5, с вызовом этого метода для какого-нибудь одного, например, последнего нейрона слоя в конце функции LayerFF::Propagate. Очевидно, что при этом на стадии конструирования в каждый слой НС, кроме выходного необходимо добавить один дополнительный нейрон. Он, в принципе, может не иметь ни синапсов, ни массива изменений их весов и не вызывать метод Propagate внутри LayerFF::Propagate.
Рассмотренный выше и реализованный в программе алгоритм является, можно сказать, классическим вариантом процедуры обратного распространения, однако известны многие его модификации. Изменения касаются как методов расчетов [7][8], так и конфигурации сети [9][5]. В частности в [5] послойная организация сети заменена на магистральную, когда все нейроны имеют сквозной номер и каждый связан со всеми предыдущими.
Сеть, сконструированная в качестве примера в программе, приведенной на листинге 5, была обучена распознавать десять букв, схематично заданных матрицами 6*5 точек за несколько сотен циклов обучения, которые выполнились на компьютере 386DX40 за время меньше минуты. Обученная сеть успешно распознавала изображения, зашумленные более сильно, чем образы, на которых она обучалась.
Программа компилировалась с помощью Borland C++ 3.1 в моделях Large и Small.
Предложенная библиотека классов позволит создавать сети, способные решать широкий спектр задач, таких как построение экспертных систем, сжатие информации и многих других, исходные условия которых могут быть приведены к множеству парных, входных и выходных, наборов данных.
Литература
- Sankar K. Pal, Sushmita Mitra, Multilayer Perceptron, Fuzzy Sets, and Classification //IEEE Transactions on Neural Networks, Vol.3, N5,1992, pp.683-696.
- Ф.Уоссермен, Нейрокомпьютерная техника, М., Мир, 1992.
- Bernard Widrow, Michael A. Lehr, 30 Years of Adaptive NeuralNetworks: Perceptron, Madaline, and Backpropagation //Artificial Neural Networks: Concepts and Theory, IEEE Computer Society Press, 1992, pp.327-354.
- Paul J. Werbos, Backpropagation Through Time: What It Does and How to Do It //Artificial Neural Networks: Concepts and Theory, IEEE Computer Society Press, 1992, pp.309-319.
- Gael de La Croix Vaubois, Catherine Moulinoux, Benolt Derot, The N Programming Language //Neurocomputing, NATO ASI series, vol.F68, pp.89-92.
- H.A.Malki, A.Moghaddamjoo, Using the Karhunen-Loe`ve Transformation in the Back-Propagation Training Algorithm //IEEE Transactions on Neural Networks, Vol.2, N1, 1991, pp.162-165.
- Harris Drucker, Yann Le Cun, Improving Generalization Performance Using Backpropagation //IEEE Transactions on Neural Networks, Vol.3, N5, 1992, pp.991-997.
- Alain Petrowski, Gerard Dreyfus, Claude Girault, Performance Analysis of a Pipelined Backpropagation Parallel Algorithm //IEEE Transactions on Neural Networks, Vol.4, N6, 1993, pp.970-981.
Обучение без учителя.
В статье рассмотрены алгоритмы обучения искусственных нейронных сетей без учителя. Приведена библиотека классов на C++ и тестовый пример.
Рассмотренный в [1] алгоритм обучения нейронной сети с помощью процедуры обратного распространения подразумевает наличие некоего внешнего звена, предоставляющего сети кроме входных так же и целевые выходные образы. Алгоритмы, пользующиеся подобной концепцией, называются алгоритмами обучения с учителем. Для их успешного функционирования необходимо наличие экспертов, создающих на предварительном этапе для каждого входного образа эталонный выходной. Так как создание искусственного интеллекта движется по пути копирования природных прообразов, ученые не прекращают спор на тему, можно ли считать алгоритмы обучения с учителем натуральными или же они полностью искусственны. Например, обучение человеческого мозга, на первый взгляд, происходит без учителя: на зрительные, слуховые, тактильные и прочие рецепторы поступает информация извне, и внутри нервной системы происходит некая самоорганизация. Однако, нельзя отрицать и того, что в жизни человека не мало учителей – и в буквальном, и в переносном смысле, – которые координируют внешние воздействия. Вместе в тем, чем бы ни закончился спор приверженцев этих двух концепций обучения, они обе имеют право на существование.
Главная черта, делающая обучение без учителя привлекательным, – это его "самостоятельность". Процесс обучения, как и в случае обучения с учителем, заключается в подстраивании весов синапсов. Некоторые алгоритмы, правда, изменяют и структуру сети, то есть количество нейронов и их взаимосвязи, но такие преобразования правильнее назвать более широким термином – самоорганизацией, и в рамках данной статьи они рассматриваться не будут. Очевидно, что подстройка синапсов может проводиться только на основании информации, доступной в нейроне, то есть его состояния и уже имеющихся весовых коэффициентов. Исходя из этого соображения и, что более важно, по аналогии с известными принципами самоорганизации нервных клеток[2], построены алгоритмы обучения Хебба.
Сигнальный метод обучения Хебба заключается в изменении весов по следующему правилу:
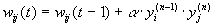 (1)
(1)
где yi(n-1) – выходное значение нейрона i слоя (n-1), yj(n) – выходное значение нейрона j слоя n; wij(t) и wij(t-1) – весовой коэффициент синапса, соединяющего эти нейроны, на итерациях t и t-1 соответственно; a – коэффициент скорости обучения. Здесь и далее, для общности, под n подразумевается произвольный слой сети. При обучении по данному методу усиливаются связи между возбужденными нейронами.
Существует также и дифференциальный метод обучения Хебба.
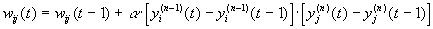 (2)
(2)
Здесь yi(n-1)(t) и yi(n-1)(t-1) – выходное значение нейрона i слоя n-1 соответственно на итерациях t и t-1; yj(n)(t) и yj(n)(t-1) – то же самое для нейрона j слоя n. Как видно из формулы (2), сильнее всего обучаются синапсы, соединяющие те нейроны, выходы которых наиболее динамично изменились в сторону увеличения.
Полный алгоритм обучения с применением вышеприведенных формул будет выглядеть так:
1. На стадии инициализации всем весовым коэффициентам присваиваются небольшие случайные значения.
2. На входы сети подается входной образ, и сигналы возбуждения распространяются по всем слоям согласно принципам классических прямопоточных (feedforward) сетей[1], то есть для каждого нейрона рассчитывается взвешенная сумма его входов, к которой затем применяется активационная (передаточная) функция нейрона, в результате чего получается его выходное значение yi(n), i=0...Mi-1, где M<i – число нейронов в слое i; n=0...N-1, а N – число слоев в сети.
3. На основании полученных выходных значений нейронов по формуле (1) или (2) производится изменение весовых коэффициентов.
4. Цикл с шага 2, пока выходные значения сети не застабилизируются с заданной точностью. Применение этого нового способа определения завершения обучения, отличного от использовавшегося для сети обратного распространения, обусловлено тем, что подстраиваемые значения синапсов фактически не ограничены.
На втором шаге цикла попеременно предъявляются все образы из входного набора.
Следует отметить, что вид откликов на каждый класс входных образов не известен заранее и будет представлять собой произвольное сочетание состояний нейронов выходного слоя, обусловленное случайным распределением весов на стадии инициализации. Вместе с тем, сеть способна обобщать схожие образы, относя их к одному классу. Тестирование обученной сети позволяет определить топологию классов в выходном слое. Для приведения откликов обученной сети к удобному представлению можно дополнить сеть одним слоем, который, например, по алгоритму обучения однослойного перцептрона необходимо заставить отображать выходные реакции сети в требуемые образы.
Другой алгоритм обучения без учителя – алгоритм Кохонена – предусматривает подстройку синапсов на основании их значений от предыдущей итерации.
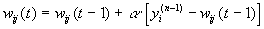 (3)
(3)
Из вышеприведенной формулы видно, что обучение сводится к минимизации разницы между входными сигналами нейрона, поступающими с выходов нейронов предыдущего слоя yi(n-1), и весовыми коэффициентами его синапсов.
Полный алгоритм обучения имеет примерно такую же структуру, как в методах Хебба, но на шаге 3 из всего слоя выбирается нейрон, значения синапсов которого максимально походят на входной образ, и подстройка весов по формуле (3) проводится только для него. Эта, так называемая, аккредитация может сопровождаться затормаживанием всех остальных нейронов слоя и введением выбранного нейрона в насыщение. Выбор такого нейрона может осуществляться, например, расчетом скалярного произведения вектора весовых коэффициентов с вектором входных значений. Максимальное произведение дает выигравший нейрон.
Другой вариант – расчет расстояния между этими векторами в p-мерном пространстве, где p – размер векторов.
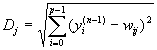 ,
(4)
,
(4)
где j – индекс нейрона в слое n, i – индекс суммирования по нейронам слоя (n-1), wij – вес синапса, соединяющего нейроны; выходы нейронов слоя (n-1) являются входными значениями для слоя n. Корень в формуле (4) брать не обязательно, так как важна лишь относительная оценка различных Dj.
В данном случае, "побеждает" нейрон с наименьшим расстоянием. Иногда слишком часто получающие аккредитацию нейроны принудительно исключаются из рассмотрения, чтобы "уравнять права" всех нейронов слоя. Простейший вариант такого алгоритма заключается в торможении только что выигравшего нейрона.
При использовании обучения по алгоритму Кохонена существует практика нормализации входных образов, а так же – на стадии инициализации – и нормализации начальных значений весовых коэффициентов.
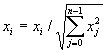 ,
(5)
,
(5)
где xi – i-ая компонента вектора входного образа или вектора весовых коэффициентов, а n – его размерность. Это позволяет сократить длительность процесса обучения.
Инициализация весовых коэффициентов случайными значениями может привести к тому, что различные классы, которым соответствуют плотно распределенные входные образы, сольются или, наоборот, раздробятся на дополнительные подклассы в случае близких образов одного и того же класса. Для избежания такой ситуации используется метод выпуклой комбинации[3]. Суть его сводится к тому, что входные нормализованные образы подвергаются преобразованию:
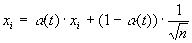 ,
(6)
,
(6)
где xi – i-ая компонента входного образа, n – общее число его компонент, a (t) – коэффициент, изменяющийся в процессе обучения от нуля до единицы, в результате чего вначале на входы сети подаются практически одинаковые образы, а с течением времени они все больше сходятся к исходным. Весовые коэффициенты устанавливаются на шаге инициализации равными величине
 ,
(7)
,
(7)
где n – размерность вектора весов для нейронов инициализируемого слоя.
На основе рассмотренного выше метода строятся нейронные сети особого типа – так называемые самоорганизующиеся структуры – self-organizing feature maps (этот устоявшийся перевод с английского, на мой взгляд, не очень удачен, так как, речь идет не об изменении структуры сети, а только о подстройке синапсов). Для них после выбора из слоя n нейрона j с минимальным расстоянием Dj (4) обучается по формуле (3) не только этот нейрон, но и его соседи, расположенные в окрестности R. Величина R на первых итерациях очень большая, так что обучаются все нейроны, но с течением времени она уменьшается до нуля. Таким образом, чем ближе конец обучения, тем точнее определяется группа нейронов, отвечающих каждому классу образов. В приведенной ниже программе используется именно этот метод обучения.
Развивая объектно-ориентированный подход в моделировании нейронных сетей, рассмотренный в [1], для программной реализации сетей, использующих алгоритм обучения без учителя, были разработаны отдельные классы объектов типа нейрон, слой и сеть, названия которых снабжены суффиксом UL. Они наследуют основные свойства от соответствующих объектов прямопоточной сети, описанной в [1]. Фрагмент заголовочного файла с описаниями классов и функций для таких сетей представлен на листинге 1.
Как видно из него, в классе NeuronUL в отличие от NeuronBP отсутствуют обратные связи и инструменты их поддержания, а по сравнению с NeuronFF здесь появилось лишь две новых переменных – delta и inhibitory. Первая из них хранит расстояние, рассчитываемое по формуле (4), а вторая – величину заторможенности нейрона. В классе NeuronUL существует два конструктора – один, используемый по умолчанию, – не имеет параметров, и к созданным с помощью него нейронам необходимо затем применять метод _allocateNeuron класса NeuronFF. Другой сам вызывает эту функцию через соответствующий конструктор NeuronFF. Метод Propagate является почти полным аналогом одноименного метода из NeuronFF, за исключением вычисления величин delta и inhibitory. Методы Normalize и Equalize выполняют соответственно нормализацию значений весовых коэффициентов по формуле (5) и их установку согласно (7). Метод CountDistance вычисляет расстояние (4). Следует особо отметить, что в классе отсутствует метод IsConverged, что, объясняется, как говорилось выше, различными способами определения факта завершения обучения. Хотя в принципе написать такую функцию не сложно, в данной программной реализации завершение обучения определяется по "телеметрической" информации, выводимой на экран, самим пользователем. В представленном же вместе со статьей тесте число итераций, выполняющих обучение, вообще говоря, эмпирически задано равным 3000.
В состав класса LayerUL входит массив нейронов neurons и переменная с размерностью массивов синапсов – neuronrang. Метод распределения нейронов – внешний или внутренний – определяется тем, как создавался слой. Этот признак хранится в переменной allocation. Конструктор LayerUL(unsigned, unsigned) сам распределяет память под нейроны, что соответствует внутренней инициализации; конструктор LayerUL(NeuronUL _FAR *, unsigned, unsigned) создает слой из уже готового, внешнего массива нейронов. Все методы этого класса аналогичны соответствующим методам класса LayerFF и, в большинстве своем, используют одноименные методы класса NeuronUL.
В классе NetUL также особое внимание необходимо уделить конструкторам. Один из них – NetUL(unsigned n) создает сеть из n пустых слоев, которые затем необходимо заполнить с помощью метода SetLayer. Конструктор NetUL(unsigned n, unsigned n1, ...) не только создает сеть из n слоев, но и распределяет для них соответствующее число нейронов с синапсами, обеспечивающими полносвязность сети. После создания сети необходимо связать все нейроны с помощью метода FullConnect. Как и в случае сети обратного распространения, сеть можно сохранять и загружать в/из файла с помощью методов SaveToFile, LoadFromFile. Из всех остальных методов класса новыми по сути являются лишь NormalizeNetInputs и ConvexCombination. Первый из них нормализует входные вектора, а второй реализует преобразование выпуклой комбинации (6).
В конце заголовочного файла описаны глобальные функции. SetSigmoidTypeUL, SetSigmoidAlfaUL и SetDSigmaUL аналогичны одноименным функциям для сети обратного распространения. Функция SetAccreditationUL устанавливает режим, при котором эффективность обучения нейронов, попавших в окружение наиболее возбужденного на данной итерации нейрона, пропорциональна функции Гаусса от расстояния до центра области обучения. Если этот режим не включен, то все нейроны попавшие в область с текущим радиусом обучения одинаково быстро подстраивают свои синапсы, причем область является квадратом со стороной, равной радиусу обучения. Функция SetLearnRateUL устанавливает коэффициент скорости обучения, а SetMaxDistanceUL – радиус обучения. Когда он равен 0 – обучается только один нейрон. Функции SetInhibitionUL и SetInhibitionFresholdUL устанавливают соответственно длительность торможения и величину возбуждения, его вызывающего.
Тексты функций помещены в файле neuro_mm.cpp, представленном в листинге 2. Кроме него в проект тестовой программы входят также модули neuron_ff.cpp и subfun.cpp, описанные в [1]. Главный модуль, neuman7.cpp приведен в листинге 3. Программа компилировалась с помощью компилятора Borland C++ 3.1 в модели LARGE.
Тестовая программа демонстрирует христоматийный пример обучения самонастраивающейся сети следующей конфигурации. Входной слой состоит из двух нейронов, значения аксонов которых генерируются вспомогательной функцией на основе генератора случайных чисел. Выходной слой имеет размер 10 на 10 нейронов. В процессе обучения он приобретает свойства упорядоченной структуры, в которой величины синапсов нейронов плавно меняются вдоль двух измерений, имитируя двумерную сетку координат. Благодаря новой функции DigiShow и выводу индексов X и Y выигравшего нейрона, пользователь имеет возможность убедиться, что значения на входе сети достаточно точно определяют позицию точки максимального возбуждения на ее выходе.
Необходимо отметить, что обучение без учителя гораздо более чувствительно к выбору оптимальных параметров, нежели обучение с учителем. Во-первых, его качество сильно зависит от начальных величин синапсов. Во-вторых, обучение критично к выбору радиуса обучения и скорости его изменения. И наконец, разумеется, очень важен характер изменения собственно коэффициента обучения. В связи с этим пользователю, скорее всего, потребуется провести предварительную работу по подбору оптимальных параметров обучения сети.
Несмотря на некоторые сложности реализации, алгоритмы обучения без учителя находят обширное и успешное применение. Например, в [4] описана многослойная нейронная сеть, которая по алгоритму самоорганизующейся структуры обучается распознавать рукописные символы. Возникающее после обучения разбиение на классы может в случае необходимости уточняться с помощью обучения с учителем. По сути дела, по алгоритму обучения без учителя функционируют и наиболее сложные из известных на сегодняшний день искусственные нейронные сети – когнитрон и неокогнитрон, – максимально приблизившиеся в своем воплощении к структуре мозга. Однако они, конечно, существенно отличаются от рассмотренных выше сетей и намного более сложны. Тем не менее, на основе вышеизложенного материала можно создать реально действующие системы для распознавания образов, сжатия информации, автоматизированного управления, экспертных оценок и много другого.
Литература
- Ф.Блум, А.Лейзерсон, Л.Хофстедтер, Мозг, разум и поведение, М., Мир, 1988.
- Ф.Уоссермен, Нейрокомпьютерная техника, М., Мир, 1992.
- Keun-Rong Hsieh and Wen-Tsuen Chen, A Neural Network Model which Combines Unsupervised and Supervised Learning, IEEE Trans. on Neural Networks, vol.4, No.2, march 1993.
Нейронные сети Хопфилда и Хэмминга.
Среди различных конфигураций искуственных нейронных сетей (НС) встречаются такие, при классификации которых по принципу обучения, строго говоря, не подходят ни обучение с учителем [1], ни обучение без учителя [2]. В таких сетях весовые коэффициенты синапсов рассчитываются только однажды перед началом функционирования сети на основе информации об обрабатываемых данных, и все обучение сети сводится именно к этому расчету. С одной стороны, предъявление априорной информации можно расценивать, как помощь учителя, но с другой – сеть фактически просто запоминает образцы до того, как на ее вход поступают реальные данные, и не может изменять свое поведение, поэтому говорить о звене обратной связи с "миром" (учителем) не приходится. Из сетей с подобной логикой работы наиболее известны сеть Хопфилда и сеть Хэмминга, которые обычно используются для организации ассоциативной памяти. Далее речь пойдет именно о них.
Структурная схема сети Хопфилда приведена на рис.1. Она состоит из единственного слоя нейронов, число которых является одновременно числом входов и выходов сети. Каждый нейрон связан синапсами со всеми остальными нейронами, а также имеет один входной синапс, через который осуществляется ввод сигнала. Выходные сигналы, как обычно, образуются на аксонах.
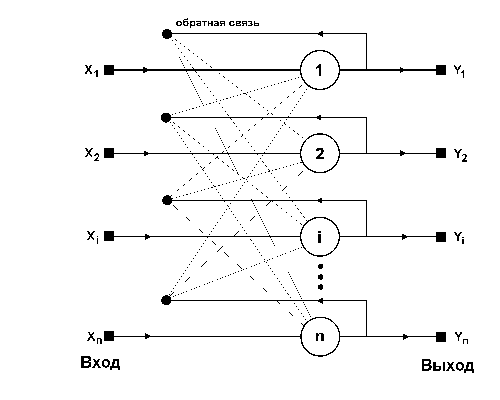
Рис.1 Структурная схема сети Хопфилда
Задача, решаемая данной сетью в качестве ассоциативной памяти, как правило, формулируется следующим образом. Известен некоторый набор двоичных сигналов (изображений, звуковых оцифровок, прочих данных, описывающих некие объекты или характеристики процессов), которые считаются образцовыми. Сеть должна уметь из произвольного неидеального сигнала, поданного на ее вход, выделить ("вспомнить" по частичной информации) соответствующий образец (если такой есть) или "дать заключение" о том, что входные данные не соответствуют ни одному из образцов. В общем случае, любой сигнал может быть описан вектором X = { xi: i=0...n-1}, n – число нейронов в сети и размерность входных и выходных векторов. Каждый элемент xi равен либо +1, либо -1. Обозначим вектор, описывающий k-ый образец, через Xk, а его компоненты, соответственно, – xik, k=0...m-1, m – число образцов. Когда сеть распознaет (или "вспомнит") какой-либо образец на основе предъявленных ей данных, ее выходы будут содержать именно его, то есть Y = Xk, где Y – вектор выходных значений сети: Y = { yi: i=0,...n-1}. В противном случае, выходной вектор не совпадет ни с одним образцовым.
Если, например, сигналы представляют собой некие изображения, то, отобразив в графическом виде данные с выхода сети, можно будет увидеть картинку, полностью совпадающую с одной из образцовых (в случае успеха) или же "вольную импровизацию" сети (в случае неудачи).
На стадии инициализации сети весовые коэффициенты синапсов устанавливаются следующим образом [3][4]:
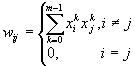 (1)
(1)
Здесь i и j – индексы, соответственно, предсинаптического и постсинаптического нейронов; xik, xjk – i-ый и j-ый элементы вектора k-ого образца.
Алгоритм функционирования сети следующий (p – номер итерации):
1. На входы сети подается неизвестный сигнал. Фактически его ввод осуществляется непосредственной установкой значений аксонов:
yi(0) = xi , i = 0...n-1, (2)
поэтому обозначение на схеме сети входных синапсов в явном виде носит чисто условный характер. Ноль в скобке справа от yi означает нулевую итерацию в цикле работы сети.
2. Рассчитывается новое состояние нейронов
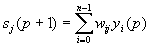 ,
j=0...n-1 (3)
,
j=0...n-1 (3)
и новые значения аксонов
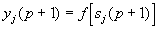 (4)
(4)
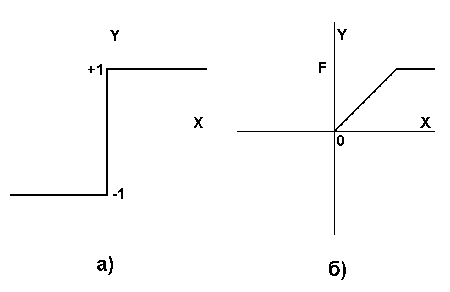
где f – активационная функция в виде скачка, приведенная на рис.2а.
3. Проверка, изменились ли выходные значения аксонов за последнюю итерацию. Если да – переход к пункту 2, иначе (если выходы застабилизировались) – конец. При этом выходной вектор представляет собой образец, наилучшим образом сочетающийся с входными данными.
Как говорилось выше, иногда сеть не может провести распознавание и выдает на выходе несуществующий образ. Это связано с проблемой ограниченности возможностей сети. Для сети Хопфилда число запоминаемых образов m не должно превышать величины, примерно равной 0.15• n. Кроме того, если два образа А и Б сильно похожи, они, возможно, будут вызывать у сети перекрестные ассоциации, то есть предъявление на входы сети вектора А приведет к появлению на ее выходах вектора Б и наоборот.

Рис.3 Структурная схема сети Хэмминга
Когда нет необходимости, чтобы сеть в явном виде выдавала образец, то есть достаточно, скажем, получать номер образца, ассоциативную память успешно реализует сеть Хэмминга. Данная сеть характеризуется, по сравнению с сетью Хопфилда, меньшими затратами на память и объемом вычислений, что становится очевидным из ее структуры (рис. 3).
Сеть состоит из двух слоев. Первый и второй слои имеют по m нейронов, где m – число образцов. Нейроны первого слоя имеют по n синапсов, соединенных со входами сети (образующими фиктивный нулевой слой). Нейроны второго слоя связаны между собой ингибиторными (отрицательными обратными) синаптическими связями. Единственный синапс с положительной обратной связью для каждого нейрона соединен с его же аксоном.
Идея работы сети состоит в нахождении расстояния Хэмминга от тестируемого образа до всех образцов. Расстоянием Хэмминга называется число отличающихся битов в двух бинарных векторах. Сеть должна выбрать образец с минимальным расстоянием Хэмминга до неизвестного входного сигнала, в результате чего будет активизирован только один выход сети, соответствующий этому образцу.
На стадии инициализации весовым коэффициентам первого слоя и порогу активационной функции присваиваются следующие значения:
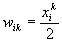 ,
i=0...n-1, k=0...m-1 (5)
,
i=0...n-1, k=0...m-1 (5)
T k = n / 2, k = 0...m-1 (6)
Здесь xik – i-ый элемент k-ого образца.
Весовые коэффициенты тормозящих синапсов во втором слое берут равными некоторой величине 0 < e < 1/m. Синапс нейрона, связанный с его же аксоном имеет вес +1.
Алгоритм функционирования сети Хэмминга следующий:
1. На входы сети подается неизвестный вектор X = {xi:i=0...n-1}, исходя из которого рассчитываются состояния нейронов первого слоя (верхний индекс в скобках указывает номер слоя):
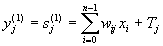 ,
j=0...m-1 (7)
,
j=0...m-1 (7)
После этого полученными значениями инициализируются значения аксонов второго слоя:
yj(2) = yj(1) , j = 0...m-1 (8)
2. Вычислить новые состояния нейронов второго слоя:
 (9)
(9)
и значения их аксонов:
 (10)
(10)
Активационная функция f имеет вид порога (рис. 2б), причем величина F должна быть достаточно большой, чтобы любые возможные значения аргумента не приводили к насыщению.
3. Проверить, изменились ли выходы нейронов второго слоя за последнюю итерацию. Если да – перейди к шагу 2. Иначе – конец.
Из оценки алгоритма видно, что роль первого слоя весьма условна: воспользовавшись один раз на шаге 1 значениями его весовых коэффициентов, сеть больше не обращается к нему, поэтому первый слой может быть вообще исключен из сети (заменен на матрицу весовых коэффициентов), что и было сделано в ее конкретной реализации, описанной ниже.
Программная модель сети Хэмминга строится на основе набора специальных классов NeuronHN, LayerHN и NetHN – производных от классов, рассмотренных в предыдущих статьях цикла [1][2]. Описания классов приведены в листинге 1. Релизации всех функций находятся в файле NEURO_HN (листинг 2). Классы NeuronHN и LayerHN наследуют большинство методов от базовых классов.
В классе NetHN определены следующие элементы:
Nin и Nout – соответственно размерность входного вектора с данными и число образцов;
dx и dy – размеры входного образа по двум координатам (для случая трехмерных образов необходимо добавить переменную dz), dx*dy должно быть равно Nin, эти переменные используются функцией загрузки данных из файла LoadNextPattern;
DX и DY – размеры выходного слоя (влияют только на отображение выходого слоя с помощью функции Show); обе пары размеров устанавливаются функцией SetDxDy;
Class – массив с данными об образцах, заполняется функцией SetClasses, эта функция выполняет общую инициализацию сети, сводящуюся к запоминанию образцовых данных.
Метод Initialize проводит дополнительную инициализацию на уровне тестируемых данных (шаг 1 алгоритма). Метод Cycle реализует шаг 2, а метод IsConverged проверят, застабилизировались ли состояния нейронов (шаг 3).
Из глобальных функций – SetSigmoidAlfaHN позволяет установить параметр F активационной функции, а SetLimitHN задает коэффициент, лежащий в пределах от нуля до единицы и определяющий долю величины 1/m, образующую e .
На листинге 3 приведена тестовая программа для проверки сети. Здесь конструируется сеть со вторым слоем из пяти нейронов, выполняющая распознавание пяти входных образов, которые представляют собой схематичные изображения букв размером 5 на 6 точек (см.рис.4а). Обучение сети фактически сводится к загрузке и запоминанию идеальных изображений, записанных в файле "charh.img", приведенном на листинге 4. Затем на ее вход поочередно подаются зашумленные на 8/30 образы (см.рис.4б) из файла "charhh.img" с листинга 5, которые она успешно различает.

Рис. 4 Образцовые и тестовые образы
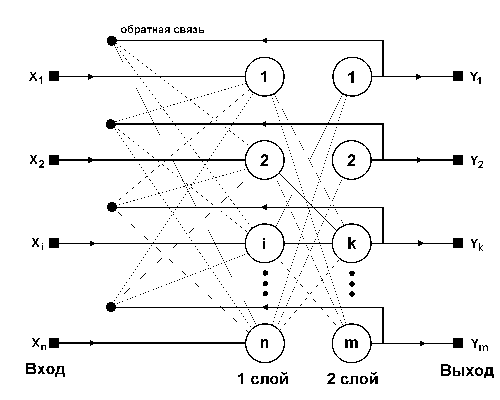
Рис.5 Структурная схема ДАП
В проект кроме файлов NEURO_HN и NEUROHAM входят также SUBFUN и NEURO_FF, описанные в [1]. Программа тестировалась в среде Borland C++ 3.1.
Предложенные классы позволяют моделировать и более крупные сети Хэмминга. Увеличение числа и сложности распознаваемых образов ограничивается фактически только объемом ОЗУ. Следует отметить, что обучение сети Хэмминга представляет самый простой алгоритм из всех рассмотренных до настоящего времени алгоритмов в этом цикле статей.
Обсуждение сетей, реализующих ассоциативную память, было бы неполным без хотя бы краткого упоминания о двунаправленной ассоциативной памяти (ДАП). Она является логичным развитием парадигмы сети Хопфилда, к которой для этого достаточно добавить второй слой. Структура ДАП представлена на рис.5. Сеть способна запоминать пары ассоциированных друг с другом образов. Пусть пары образов записываются в виде векторов Xk = {xik:i=0...n-1} и Yk = {yjk: j=0...m-1}, k=0...r-1, где r – число пар. Подача на вход первого слоя некоторого вектора P = {pi:i=0...n-1} вызывает образование на входе второго слоя некоего другого вектора Q = {qj:j=0...m-1}, который затем снова поступает на вход первого слоя. При каждом таком цикле вектора на выходах обоих слоев приближаются к паре образцовых векторов, первый из которых – X> – наиболее походит на P, который был подан на вход сети в самом начале, а второй – Y – ассоциирован с ним. Ассоциации между векторами кодируются в весовой матрице W(1) первого слоя. Весовая матрица второго слоя W(2) равна транспонированной первой (W(1))T. Процесс обучения, также как и в случае сети Хопфилда, заключается в предварительном расчете элементов матрицы >W (и соответственно WT) по формуле:
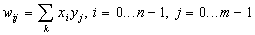 (11)
(11)
Эта формула является развернутой записью матричного уравнения
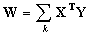 (12)
(12)
для частного случая, когда образы записаны в виде векторов, при этом произведение двух матриц размером соответственно [n*1] и [1*m] приводит к (11).
В заключении можно сделать следующее обобщение. Сети Хопфилда, Хэмминга и ДАП позволяют просто и эффективно разрешить задачу воссоздания образов по неполной и искаженной информации. Невысокая емкость сетей (число запоминаемых образов) объясняется тем, что, сети не просто запоминают образы, а позволяют проводить их обощение, например, с помощью сети Хэмминга возможна классификация по критерию максимального правдоподобия [3]. Вместе с тем, легкость построения программных и аппаратных моделей делают эти сети привлекательными для многих применений.
Литература
- Artificial Neural Networks: Concepts and Theory, IEEE Computer Society Press, 1992.
- Ф.Уоссермен, Нейрокомпьютерная техника, М.,Мир, 1992.