СИСТЕМА СЖАТИЯ РЕЧЕВЫХ СИГНАЛОВ С ПОМОЩЬ НЕЙРОСЕТЕВЫХ ТЕХНОЛОГИЙ
Изюмов В.В., группа ТКС-06м
Донецкий национальны технический университет
Cборник научных работ студентов факультета КИТА, выпуск №4, электронное издание
Донецк, 2006 г.
В настоящее время наблюдается активное развитие и внедрение новых средств связи и телекоммуникаций, в частности, современных цифровых телефонных сетей и соответствующего абонентского оборудования, а также развитие компьютерной телефонии и спутниковых средств связи. Использование цифровых методов представления, обработки и передачи приводит к многократному увеличению занимаемой полосы частот и, как следствие этого, к многократному увеличению скорости передачи информационных сообщений. Кроме того, информация в подавляющем большинстве случаев носит частный, конфиденциальный характер, поэтому все чаще к передающей аппаратуре и каналам связи предъявляется требование обеспечения защиты передаваемой информации от несанкционированного доступа.
Решение проблемы лежит в области разработки эффективных методов цифрового преобразования - сжатия (кодирования) различных сообщений, являющихся, как правило, нестационарными случайными процессами. Поскольку речь является наиболее распространенным аналоговым информационным сообщением, вопросы сжатия (цифрового кодирования) речи являются наиболее актуальными и традиционными. На данный момент имеется множество различных решений сжатия речевого сигнала, которые можно разбить на три категории.
К первой категории относятся так называемые кодеры формы. Их принцип основан на точной передачи формы сигнала. Из существующих решений кодеров формы можно выделить адаптивно дифференциальную импульсно кодовую модуляцию, так как АДИКМ позволяет без значительного уменьшения качества речи сократить скорость кода в двое по отношению к ИКМ. Суть АДИКМ заключается в квантовании и предсказании следующего отсчета сигнала с учетом их текущего значения и изменения во времени, то есть адаптивно. Так, если скорость изменения сигнала стала большей, можно увеличить шаг квантования, и, наоборот, если сигнал стал изменяться гораздо медленнее, величину шага квантования можно уменьшить. При этом ошибка предсказания уменьшится и, следовательно, будет кодироваться меньшим числом бит на отсчет. Такой способ кодирования называется адаптивной ДИКМ, или АДИКМ. Использование АДИКМ со скоростью кода 4 бита/отсчет или 32 кбит/с обеспечивает такое же субъективное качество речи, что и 64 кбит/с - ИКМ, но при вдвое меньшей скорости кода.
Ко второй категории относятся вокодеры. Суть которых кодировать не форму сигнала, а сами параметры речевого сигнала. Вокодеры позволяют очень сильно сократить скорость кода. В качестве примера можно привести канальный вокодер предложенный еще в 1939 году. Этот вокодер использует слабую чувствительность слуха человека к незначительным фазовым (временным) сдвигам сигнала, поскольку органы слуха человека не реагируют на фазовые соотношения. Для сегментов речи длиной примерно в 20 - 30 мс с помощью набора узкополосных фильтров определяется амплитудный спектр. Чем больше фильтров, тем лучше оценивается спектр, но тем больше нужно бит для его кодирования и тем больше результирующая скорость кода. Сигналы с выходов фильтров детектируются, пропускаются через ФНЧ, дискретизуются и подвергаются двоичному кодированию. Таким образом определяются медленно изменяющиеся параметры голосообразующего тракта, а также с помощью детекторов основного тона и гласных звуков, период основного тона возбуждения и признак -гласный/негласный звук.
Канальный вокодер может быть реализован как в цифровой, так и в аналоговой форме и обеспечивает достаточно разборчивую речь при скорости кода на его выходе порядка 4,8 кбит/с. Декодер, получив информацию, вырабатываемую кодером, обрабатывает ее в обратном порядке, синтезируя на своем выходе речевой сигнал, в какой-то мере похожий на исходный.
Учитывая простоту модели, трудно ожидать от вокодерного сжатия хорошего качества восстановленной речи. Действительно, канальные вокодеры используются в основном только там, где главным образом необходимы разборчивость и высокая степень сжатия: в военной связи, авиации, космической связи.
К третей категории относятся гомоморфные вокодеры, которые используют принципы кодеров формы и вокодеров.
Кодер Regular Pulse Excited, или RPE-кодек, использует в качестве сигнала возбуждения u(n) фиксированный набор коротких импульсов. Однако в этом кодеке импульсы расположены регулярно на одинаковых расстояниях друг от друга, и кодеру необходимо определить лишь положение первого импульса и амплитуды всех импульсов. Таким образом, декодеру нужно передавать меньше информации о положении импульсов, следовательно, в сигнал возбуждения можно включить их большее количество и тем самым улучшить приближение синтезированного сигнала к оригиналу. К примеру, если при скорости кода 10 кбит/с в МРЕ-кодеке используется четырехимпульсный сигнал возбуждения, то в RPE-кодеке можно использовать уже десятиимпульсный сигнал. При этом существенно повышается качество речи.
Метод регулярного импульсного возбуждения RPE сегодня широко применяется, в том числе в системе сотовой связи GSM.
В настоящее время продолжаются работы по разработке новых алгоритмов или модификации существующих, позволяющих улучшить качество восстанавливаемого сигнала без увеличения битовой скорости, или увеличить степень сжатия информации при сохранении приемлемого качества сигнала.
На основе данного обзора можно сделать вывод о том, что несмотря на существование стандартных алгоритмов кодирования речи, у разработчиков и научных работников есть огромный простор для деятельности, направленной на дальнейшее совершенствование технологии сжатия данных.
Одним из направлением развития технологий сжатия данных может быть применение нейросетевых технологий. Нейронные сети, как метод, обладают рядом преимуществ, такими как:
- Способность к обучению. Могут формировать зависимость между любыми образцами входов и выходов.
- Обобщение. Выделение основной сути зависимости "вход - выход", и делать вывод о зависимостях, которых она не знает.
- Нелинейность. Сеть может нелинейные, непараметрические функции от входа. Это преимущество, так как речь - очень нелинейный процесс.
- Помехоустойчивость. Сеть устойчива к физическим повреждения и зашумленным входам.
- Однородность. Сети предлагают однородную вычислительную парадигму, которая может интегрировать связи от различных типов входов.
- Параллелизм. Сети параллельны по природе. Так что они хорошо решаются с помощь многопроцессорных систем или нейроконтролеров, что в конечном счете позволить очень быстро обрабатывать речь или другие данные.
Идея системы сжатия заключается в том, чтобы из входного сигнала выделять речь и определять ее структуру - фонемы, которые в последствии передавать в канал связи. А на приемной стороне по полученной информации синтезировать речевой сигнал.
Модель кодера создавалась средствами среды MATLAB. Так как реализация кодера с помощью нейронной сети для полного набора фонем представляет некоторую сложность, то было принято упрощение, заключающееся в том, чтобы построить сеть распознающую 6 гласных фонем (а, э, и, ы, у) и 2 "фонемы" обозначающих паузу и неопознанные фонемы. Также нейронная сеть тренируется только на одного диктора.
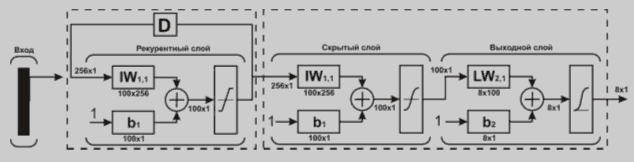
Рисунок 1 - Структур нейронной сети.
Работа модели заключается в том, что поток оцифрованной речи с частотой дискретизации 22050 Гц разбивается на кадры длиной 256 отсчетов и далее подвергается вейвлет преобразованию, получая матрицу 16х16 коэффициентов, которые потом преобразуются во входной вектор сети. Сеть состоит из двух подсетей. Первая - рекуррентная сеть Хопфилда, функция которой заключается в том чтобы входной вектор ассоциировать с запомненными шаблонами, подсеть также обладает свойством подавления помех. Далее двухслойная подсеть классифицирует "очищенный" вектор и вырабатывает выходной вектор, каждый элемент которого соответствует определенной фонеме. То есть элемент выходного вектора ближайший к единице является предполагаемой фонемой содержащийся в кадре.
Сеть обучается стандартным методом градиентного спуска. Примеры шаблонов обучения представлены на рисунке 2
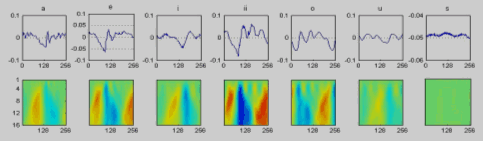
Рисунок 2 - Примеры обучающих образцов (внизу вейвлет коэффициенты подаваемые на вход).
Сеть правильно распознает 58-64 образца из 80 предъявленных, в которые входят 40 обучающих образцов. Сеть точно определяет 40 обучающих образцов и на 18-24 образца дает правильное предположение. То есть сеть дает примерно 75% верных ответов.
Данная структура нейронной сети имеет хорошую верность результата порядка 75-85%, а также проявляет свойства подавления зашумленности в предъявляемых векторах. Для повышения полученных результатов предлагается структуру и параметры системы оптимизировать с помощью метода генетических алгоритмов. С помощь ГА можно оптимизировать параметры вейвлет преобразования (количество коэффициентов и тип вейвлета), параметры рекуррентного слоя (количество шагов восстановления входного вектора), количество нейронов в скрытом слое и тип активационной функции. Также для обучения сети можно применить ГА, но стандартные методы работают быстрее и в некоторых случаях лучше, чем ГА. По этому применение ГА для обучения сети в данном случае не дает выигрыша.
