Нейронная сеть использующая акустическую подструктуру слова для беспрерывного распознания слова
Ha-Jin Yu, Yung-Hwan Oh
Dept. of Computer Science, KAIST
(Korea Advanced Institute of Science and Technology)
373-1, Kusong-dong, Yusong-gu, Taejon Korea
Перевод с английскогo Изюмов В.В.
Источник http://wagstaff.asel.udel.edu/icslp
Резюме
Предложена нейросетевая модель для распознания слитной речи основанная на подструктуре слова. Система состоит из трех модулей, и каждый модуль составлен из простых нейронных сетей. В первом модуле речевой ввод сегментирован нейронной сетью на элементы разной длины. Неравные элементы являются возможными моделями вариации фонем, такие как различные фонемы и переходы между слов. Второй модуль распознает элементы. Сегмент имеет постоянную и переходную часть, и сеть разделена согласно этим двум частям. Последний модуль определяет слова, путем моделирования их временного представления. Так же описаны результаты дикторонезависимого распознания 520 слов.
1. Введение
Хотя скрытая Марковская модель (HMM) была расценена как самая мощная модель для распознавания речи, нейронные сети - все еще на рассмотрении из-за их достоинств по другим моделям типа более высокого параллелизма и устойчивости в аппаратных ошибках. Большинство нейросетевых моделей расценивают модули речи как гомогенные статические образцы, и они не представляют внутреннюю структуру сегментов. Например, в моделях типа TDNN, рекуррентной сети, и SOFM [1], входная речь разделена на сегменты равной длины, и фонемы, или слова представлены рядом сегмент. Так как фонемы или слова не имеют однородной акустической структуры, сеть была бы более эффективна, если могла бы моделировать акустическую структуру модулей.
В этом исследовании, речевой ввод сначала разделен на неравные акустические сегменты подслова [2], которые могут быть разделены на стационарные и переходные части. Структура сети разработана, чтобы справиться со структурой сегмента. В слитной речи, эффект слития нескольких фонем или слов, приводит к тому, что некоторых фонемы имеет тенденцию быть пропущенными или ослаблеными. Например, в TIMIT речевых данных, запись слова "утро"("morning") - /m ao1 r n ix ng/, но в реальной речи, одно из произношений вручную сегментировано как /m ao en/. В этом случае, последние четыре фонемы сокращены к одной фонеме /en/. Используя неравномерные сегменты в распознавании речи, мы можем успешно моделировать такие вариации фонем.
Концепция неравных элементов введено в синтезаторе речи Sagisaka [3]. Так же концепция используется для распознавания речи в работах [4] [5]. В [5], кандидаты длинных элементов выбираются, используя текстовые данные, вычисляя частоту всех комбинаций соседних фонем, и фонема добавляется и переобучается в HMM. В нашем подходе [4], элементы выбираются, используя речевые данные. Речевые сегменты выбираются, и вырезаются в середине относительно стационарной части, где значения спектральной переходной меры [6] находиться в локальном минимуме. Так как сегментация является прямой, требуется намного меньше времени, чтобы классифицировать сегмент, и устройство распознавания может быть просто реализовано. В этом исследовании, устройство распознавания было сформировано, используя простые структуры нейронных сетей.
Наша система состоит из трех модулей. Входная речь сегментирована первым модулем, и классифицирована вторым. В предыдущей работе [2], мы реализовали первые два модуля, и сообщили, что система может классифицировать элементы подслова. В этом исследовании, добавлен модуль, чтобы обнаруживать слова по результатам распознания модуля подслова. Модули обучены по результатам обнаружения слова, а не результатам распознания сегментов непосредственно.
2. СТРУКТУРА СИСТЕМЫ
Система составлена из трех модулей: модуль сегментации, модуль распознания элемента, и модули распознания слова, как показано на рисунке 1. Модуль сегментации сегментирует входной поток в акустические элементы подслова, и модуль распознания элемента классифицирует сегментированые элементы. Модуль слова обнаруживает слова из распознанных элементов.
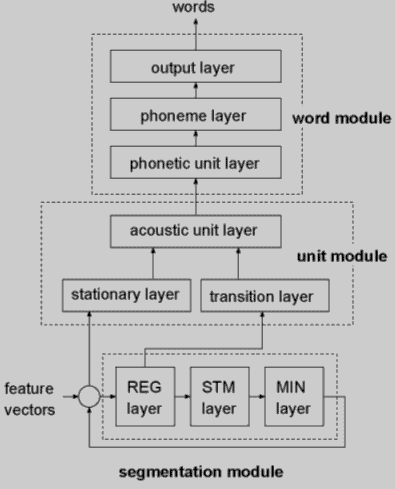
Рисунок 1. - Структура системы
2.1. Модуль сегментации и модуль распознания элементов.
Модуль сегментации сегментирует входную слитную речь в неравные по длине элементы. Рисунок 2 отображает структура модуля и пример работы модулей. Вход берется из временного окна в котором скользят семь окон. Первый слой модуля сегментации, слой REG, имеющий на выходе 14 нейронов. Выход m нейрона в момент времени t равен:
(1)
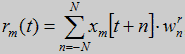 ,l<m<p
,l<m<p
Второй слой модуля сегментации - слой STM, выходы которого описываются выражением (2).
(2)
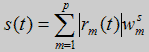
где wmw- вес между m нейроном и выходным нейроном. Выходное значение s(t) - взвешенная переходная спектральная мера [6], для уменьшения сегментной вариации элементов [2]. Большое значение выхода подразумевает, что спектр быстро изменяется в данной точке.
Третий слой - слой MIN, который обнаруживает точку, где выход STM слоя находиться в локульном минимуме. Выход M(t) в момент времени t выражается следующей формулой:
(3)
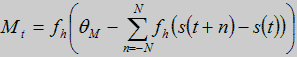
где функция fh(t)- пороговая функция, и 9M=2N+Q, с порогом 0<a<1. Выход активен когда s(t) - минимум s(t+n), при -N<n<N, N=3, то есть значение взвешенной переходной спектральной меры в момент времени t является локальным минимумом.
Входной векторный поток разрезается между двух точек, где активируется выход MIN слоя. То есть, вход сегментируется в точке, где спектр изменяется относительно медленно. Позиция может также быть расценена как точка стационарности , а область ограниченная данными точками может расценнена как переходная , быстрое изменение спектра между двумя этими точками. В примере, показанном на рисунке 2, сегмент включает три фонемы 'b', 'u', и 's', и модуль отмечает как 'bus'.
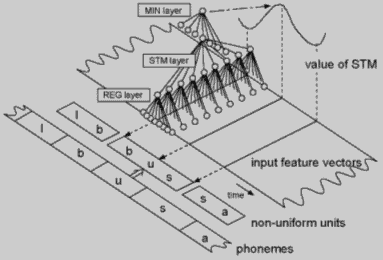
Рисунок 2. - Сегментационный модуль и определение сегментов.
Элементы сегментируются модулем сегментации и классифицируются модулем распознавания сегментов, показанным на рисунке 3. Из сегмента выбирается семь векторов. Два вектора выбираются в двух стационарных точках, которые являются концами сегмента. Один вектор выбирается в точке, где значение переходной спектральной меры находится в пике, а остальные между центром и границами.
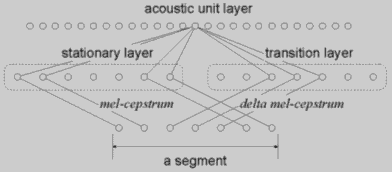
Рисунок 3. - Модуль распознавания сегментов.
Центральные векторы подаются на переходной слой, а крайние веткоры подаются на стационарный слой. На стационарный слой подаются мел-кепструм коэффициенты, а на переходной слой - дельта мел-кепструм коэффициенты, которые являются выходами слоя REG.
Активация Aj для j выходного нейрона акустического слоя выражается равентсвом (4).
(4)
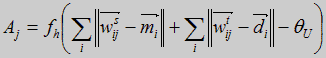
где 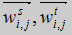 - вектор веса между j нейроном акустического слоя и i нейроном стационарного и переходного слоя, соответственно.
- вектор веса между j нейроном акустического слоя и i нейроном стационарного и переходного слоя, соответственно. 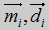 - i вектор мел-кепструма и дельта мел-кепструма на сегменте. Нейроны акустического слоя связаны с фонетическим слоем модуля слова.
- i вектор мел-кепструма и дельта мел-кепструма на сегменте. Нейроны акустического слоя связаны с фонетическим слоем модуля слова.
2.2. Модуль слова
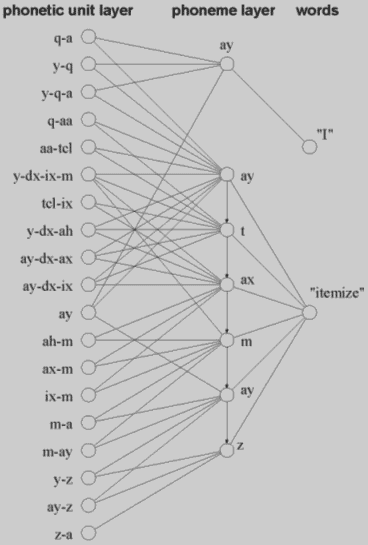
Рисунок 4. - Модуль слов.
Модуль слова детектирует слова на выходе модуля распознавания. На рисунке 4 показана схема распознавания слова. Сеть имеет четыре слоя: слой акустических элементов, слой фонетических элементов, фонемный слой и выходной слой, который показан на рисунке 1. Первый слой составлен из нейронов, которые соответствуют акустическим единицам. Слой также является выходом модуля распознавания элементов. Второй слой - слой фонетических элементов, карта связей между акустическим слоем и фонетическим слоем. Фонетический слой классифицирует фонемы, путем определения акустического расстояния между элементами. Картирование необходимо, потому что слово может быть описано фонетическими элементами и входной сигнал легко преобразуется в акустическиие единицы. А акустические единицы могут отображать несколько фонетических элементов и наоборот. И несколько нейронов двух слоев модуля подслова могут быть активированы от одного входного сегмента.
Нейроны в выходном слое соответствуют словам, которые являются конечной целью данной систем. Нейрон в выходном слое имеет свой набор нейронов в слое фонем. Нейроны в слое фонем соеденены только с одним нейронов в выходном слое, и группа нейронов представляющие фонемы составляют слово. На рисунке 4, выходной нейрон соответствующий слову "itemize" соединен с набором из шети нейронов в слое фонем, которые представляют фонемы "ay", "t", "ax", "m", "ay", "z", и эти шесть нейроно представляют только одно слово.
Нейрон в слое фонетических единиц активизируется всякий раз, когда один или больше нейронов активизируются в слое акустических единиц, которые связаны с данным нейроном. Значение i-ого нейрона в фонетическом слое для слова w согласно входу от слоя фонетических единиц в момент времени t выражется следующими выражениями.
(5)
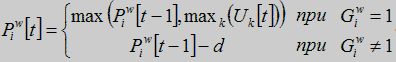
(6)
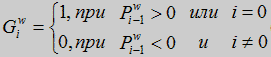
где Piw[t] - значение i-ого нейрона в фонетическом слое, который связан с w нейронов в слое слова в момент времени t, Uk[t] - k нейрона в слое фонетических единиц в момент времени t, где существует связь между Piw и Uk, 1<i<Lw, Lw - количество фонем в слое w, d - контстанта. Нейроны в фонетическом слое активизируются только, когда фонемы идут в соответствующем порядке. Иначе значение Piw уменьшается на константу d.
Наконец, выход Ow[t], который соответстует слову w в момент времени t равен(7)
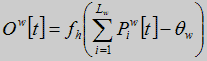
где θw - порог чувствительности для слова w, Lw - число фонем в слове w, то есть число нейронов в фонетическом слове, которые связаны с выходом Ow. Активация выходного нейрона означает обнаружение слова w.
3. ОБУЧЕНИЕ
Сеть обучается на фонетически маркированой слитной речи. Если слово не распознается, то связанные со словом сегменты используются для повторного обучения. Если сегмент выдает элемент, который не был замечен, то создается нейрон в каждом акустическом слое и слое фонетических элементов, а также добавляется связи между ними. Если для элемента уже существует нейрон, то связи модифицируются с помощь котролируемого обучения Хебба. Для нового слова на выходе добавляется нейрон, а также добавляется нейроны в слой фонем соответствующие фонемам в слове. Также добавляются связи между слоем фонем и слоем фонетических элементов, а также добавляются или модифицируются связи между слоем акустических элементов и слоем фонетических элементов. Порог чувствительности θw понижается, если распознавательная способность слова w ниче, чем у других слов.
4. ЭКСПЕРИМЕНТЫ
Система моделируется на рабочей станции SPARC-20. Для проверки использовался набор TIMIT. В данных, предложения SX произнесены семью дикторами. Мы выбрали 520 ключевых слов из 150 предложений SX. Шесть произношений для каждого предложения, в общем количестве 900 предложений использовалось для обучения, и 150 предложений использовались для испытания, которые включали 593 ключевых слова. К речевому сигналу применялось окно Хеминга длино 16мс каждые 8мс и извлекались LPC кепстральные коэфициенты 14 порядка. В результате, обучающий набор составлял 5068 примеров. 59,3% (2413) из общего количества (4077) примеров были правильно классифицированы для десяти дикторов. 10.1 % (411) нераспознаных элементов, и 13.5 % (80) из слов пропущены из-за нераспознаного элемента, когда способность обнаружения слова - 77.2 %. Это означает, что 59 % ошибок происходит из-за нераспознаных элементов. Система может быть переобучена с нераспознаными элементами для уточнения. Мы также оценили систему, когда входная речь сегментирована в точках, где значения спектральной переходной меры - пики, а не точки минимума, показывать тем что использование стационарных точек эффективно. 5339 элементов определено и 48.3 % из общего количества 5710 элементов классифицированы правильно.
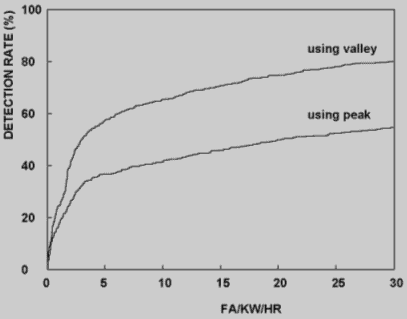
Рисунок 5. - Результат распознания слов (ROC кривая).
На рисунок 5 показана рабочая характеристика системы (ROC кривая), для этих двух случаев. Видно, что эффективность использования точки минимума спектральной преходной меры составляет приблизительно 150 % эффективности обнаружения слова при использовании пика спектральной переходной меры. В моделировании, элементы являются заданными, и используется только два вектора на концах, так как слишком много времени занимает, чтобы вычислить все значения активации слоя акустических елементов. Число нейронов, которые нуждаются в полном вычислении, сокращен приблизительно к 10 % от общего количества нейронов в слое акустических елементов, но на способность обнаружения слов не влияло.
5. ЗАКЛЮЧЕНИЯ
Мы предложили нейронную сеть для распознания слитной речи на неравных элементах. Система состоит из трех модулей, которые являются комбинацией простых нейронных сетей. Первый модуль сегментирует входную слитную речь на неравные сегменты, второй модуль - распазнает данные сегменты. Третий номер распознает слово в предложении. Использую нераваные сегменты, ошибки в сегментации не будут существенного влияния, потому что мы можем определить достаточно много элементов, чтобы охватить большое множество акустических элементов. Данная система эффективно распознавала 520 ключевых слов. Система на данный момент разрабатывается для обработки большого количества данных.
6. ЛИТЕРАТУРА
- Morgan, D.P., and Scofield, C.L., Neural Networks and Speech Processing, Kluwer Academic Publishers, Boston, 1991
- Yu, H.-J., and Oh, Y.-H., "A Neural Network using Non-Uniform Unit for Continuous Speech Recognition," EU-ROSPEECH'95, Madrid, Spain, Vol 3, pp. 1677-1680, September 1995
- Sagisaka, Y., "Speech synthesis by rule using an optimal selection of non-uniform synthesis units," Proceedings of International Conference on Acoustics, Speech, and Signal ICASSP '88, pp. 679-682
- Yu, H.-J., and Oh, Y.-H., Yamashita, Y., and Mizoguchi, R., "Expert system for continuous speech recognition with non-uniform recognition unit," IEICE Technical Report, SP93-56, pp.57-64, August 1993
- Matsumura, T. and Matsunaga, S., "Towards Nonuniform Unit HMMs for Speech Recognition," 2nd IEEE Workshop on Interactive Voice Technology for Telecommunications Applications (IVTA94) pp. 89-92, 1994
- Furui, S., "On the Role of Spectral Transition for Speech Perception," Journal of Acoustic Society of America 80(4), pp. 1016-1025, 1986
