
В свете повального увлечения объектно-ориентированными языками программирования, логическое программирование было забыто, между тем существует определенный ряд задач, который можно решить только с помощью логических языков программирования. Развитие аппаратной части ЭВМ подошло к труднопреодолеваемому барьеру и для получения значительно более мощной системы недостаточно выждать некоторый срок или купить более дорогое оборудование. Эффективнее увеличивать быстродействие за счет организации и расширения кластеров, многопроцессорных систем. Однако поддержка таких систем программными продуктами достаточно ограничена. Данная работа посвящена увеличению возможностей использования распределенных систем в логическом программировании.
В 70-е годы логическое программирование и базы данных развивались одновременно. Пролог — самый популярный язык программирования в логике — появился как результат упрощения более общих методов доказательства теорем для достижения возможности эффективного программирования. Аналогично реляционная модель данных возникла в результате упрощения сложных иерархической и сетевой моделей для обеспечения возможности непроцедурного манипулирования множественными данными. На протяжении 70-х и в начале 80-х годов пролог и реляционные базы данных получили широкое распространение не только в академической или научной среде, но и в деловом мире.
Одним из важнейших вопросов при построении вычислительных систем является увеличение их быстродействия. Но достигнуть большего быстродействия возможно лишь двумя методами: экстенсивным (улучшение архитектур, процессоров, увеличение тактовой частоты) или интенсивным (оптимизация, разгрузка кода, распараллеливание). Постоянно обновлять и покупать новое дорогое оборудование менее рентабельно, чем приобрести программное обеспечение, которое работает эффективнее и быстрее на любом имеющемся оборудовании. Распараллеливание в процессе трансляции даёт преимущество в работе программы, в быстродействии выполняемого кода. Развитие аппаратной части компьютеров достигло труднопреодолеваемого барьера. Как показывает практика - получение значительно более мощных систем, относительно существующих, в ближайшей перспективе маловероятно. Да и всегда существуют задачи, для которых недостаточно производительности одной системы.
Программа на языке пролог состоит из набора фактов, определенных отношений между объектами данных (фактами) и набором правил (образцами отношений между объектами базы данных). Для работы программы пользователь должен ввести запрос - набор термов, которые все должны быть истинны. Факты и правила из базы данных используются для определения того, какие подстановки для переменных в запросе (называемые унификацией) согласуются с информацией в базе данных.
Факты записываются в виде предикатов. Для описания предикатов введем некоторые понятия. Клауза — предложение, состоящие из заголовка и тела. Заголовок содержит имя и аргументы. Тело состоит из множества литер (возможно пустого). Предикат представляет множество клауз с одинаковым именем и набором аргументов.
Исходя из структуры программы на языке пролог, вытекает проблема интеграции различных парадигм программирования. Логической парадигмы с одной стороны, и, например, функциональной — с другой. Решение задачи такой интеграции, а значит и сам процесс распараллеливания пролог-программы, может быть построен по одному из трех следующих принципов, выделенных исходя из степени прозрачности этого процесса в отношении текста программы:
Использование любого из данных принципов требует модификации транслятора языка. В случае полной прозрачности необходима модификация внутренних структур данных и алгоритмов трансляции. Промежуточная прозрачность требует расширения диалекта языка и введения дополнительных предикатов, управляющих параллельными вычислениями. При отсутствии прозрачности требуется доработка интерфейса для интеграции транслятора с модулями на других языках программирования, которые будут явно реализовать параллелизм (например, вставки кода на языке Си с использованием MPI).
Наиболее оптимальной с точки зрения пользователя системы является реализация механизма полной прозрачности. Это позволяет пользователю писать код программы, не заботясь об изучении дополнительных расширений или сторонних языков. Особенно актуальна эта проблема в связи с появлением большого количества пользователей, не обладающих обширными профессиональными навыками в программировании.
В итоге при написании транслятора языка логического программирования по принципу полной прозрачности можно выделить несколько возможных типов параллелизма:
Среди существующих реализаций, параллелизм типа «И» реализован в таких трансляторах, как Parlog (разработчик Parallel Logic Programming Ltd.), параллелизм типа «ИЛИ» в трансляторах «Акторный пролог» (разработчик Морозов А.А.) и в YAP Prolog (разработчик LIACC/Universidade do Porto). Кроме того, существуют и другие реализации пролога, как с поддержкой распараллеливания, так и без нее.
Построение транслятора с возможностью распараллеливания по принципу полной прозрачности с использованием параллелизма типа «ИЛИ» возможно либо при помощи модификации кода существующего транслятора, либо его полной новой реализацией. Использование модификации существующих трансляторов связано с преодолением таких препятствий, как модификация внутреннего представления структур данных, а также связи существующей кодовой базы с самим механизмом распараллеливания. Для исследования выигрыша от процесса распараллеливание наиболее целесообразна разработка нового транслятора, с заведомо выбранным принципом внутреннего представления данных и связью кода трансляции с кодом распараллеливания.
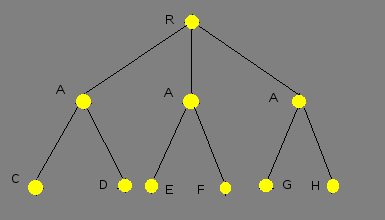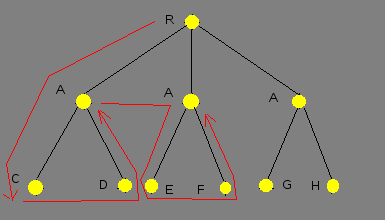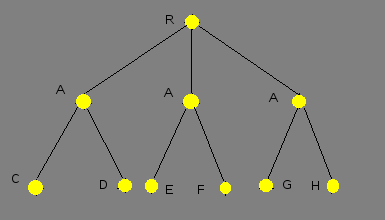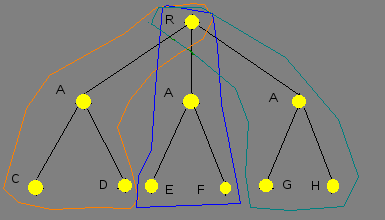
Данная работа посвящена исследованию параллелизма типа «ИЛИ». Этот тип параллелизма имеет место, когда одна подцель может быть унифицирована с заглавиями нескольких клауз, и тела этих клауз вычисляются различными вычислительными модулями. В отличие от классического варианта пролога, в котором производится последовательный обход дерева (рис. 1).

Лексический анализ представляет собой первую фазу транслятора. Его основная задача заключается в разбиении исходного кода программы на токены, заполнение таблиц имен, отсечение комментариев (если они допускаются) и выдача на выходе последовательности токенов для синтаксического анализатора. При построении таблиц имен, лексический анализатор подает на выход последовательность кодов объектов в этих таблицах. Задача построения лексического анализатора значительно упрощается при использовании инструмента Flex. Он позволяет построить лексический анализатор практически указанием грамматики языка в виде регулярных выражений и действий над теми или иными классами выделяемых объектов.
Введем следующие обозначения:
В случае последовательного варианта лексического анализатора общее время работы будет равно общему времени обработки:
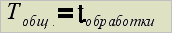
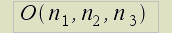
В параллельном варианте лексического анализатора общее время работы будет состоять из времени разбиения программы на части, сериализации полученных объектов для передачи по сети, пересылки данных по сети, сборки данных на узлах вычислений, собственно обработки на каждом узле, сериализации сформированных таблиц имен, пересылки их в центральный узел, сборки и склейки разрозненных таблиц имен в окончательную таблицу:
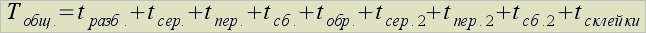
Наиболее затратным по времени будет операция склейки полученных таблиц имен в единую таблицу. Временную сложность данной операции можно оценить как:
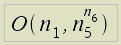
В связи с этим целесообразно реализовать последовательный вариант лексического анализатора при помощи инструмента Flex. Вторым этапом обработки программы является синтаксический анализ. На данном этапе проверяется синтаксическая правильность программы и формируются внутренние структуры данных, содержащие факты и правила исходной программы. Целесообразно на этапе синтаксического анализа сформировать две таблицы: таблицу фактов и таблицу правил. Такое разделение позволит на этапе унификации упростить формирование дерева поиска. Также на этапе синтаксического анализа должна быть сформирована матрица, содержащая информацию о связях зависимости между объектами программы. На этапе унификации это позволит быстро сформировать выборку из базы фактов и правил лишь нужной информации, которая будет разослана узлам вместе с информацией о запросе.
Существует множество различных подходов (как программных, так и аппаратных) к реализации параллелизма. Удачное использование этих подходов позволит решить крупную проблему с более высокой интенсивностью, затратив на решение приемлемый временной интервал, в течении которого сохраняется актуальность решения.
Основные проблемы, стоящие на пути к реализации пролог-системы с использованием параллелизма типа «ИЛИ» заключаются в эффективной реализации межпроцессного взаимодействия, обмена данными. Кроме того необходима оптимизация внутреннего представления данных для упрощения процедуры коммуникации. Должен быть реализован планировщик, решающий задачи первоначального разбиения программы на распараллеливаемые участки и координацию работы отдельных процессов.
В реализации системы целесообразно воспользоваться распределенными вычислениями на кластерной системе, поскольку это одна из наиболее масштабируемых схем распараллеливания вычислительных процессов.
На данный момент работа находится на стадии активной разработки. Окончание планируется к декабрю 2008 года. После этого окончательные результаты можно получить у автора или руководителя работы.