|
Чем отличается кластер и репликация? В репликации основной сервер обновляет бинарный лог по мере выполнения транзакций, вследствие чего и сам журнал, и все реплицируемые сервера несколько запаздывают. В случае, если произойдет отказ основного сервера, то несколько последних транзакций будут отсутствовать на Salve-серверах. Другими словами, репликация не гарантирует идентичность данных на Master
и Slave серверах. В случае использования кластера все задействованные элементы полностью синхронизированы. Если транзакция была завершена на одной из нод кластера, значит, она была завершена на всех нодах (двухфазный коммит). Говоря совсем просто, репликация асинхронна, в то время как кластер — синхронное решение.
Для того чтобы запустить кластер, рекомендуется использовать минимум три сервера (хотя, если схитрить, его можно запустить и на двух, но в таком случае об отказоустойчивости речь не идет). Для использования кластера под нагрузкой, рекомендуется задействовать минимум четыре сервера.
Давайте рассмотрим принципиальную схему кластера (показана на рисунке) и каждую из его составляющих.
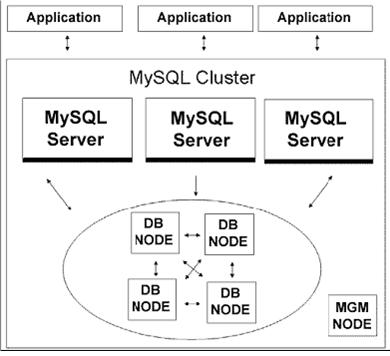
• MGM (Management) Node. Руководящая нода, которая задает общую конфигурацию и используется для управления кластером. Выполняет такие функции, как запуск и остановка кластера, создание резервных копий и восстановление после сбоя. В типовой
конфигурации кластера используется только одна нода данного типа, хотя допускается использование нескольких управляющих нод. Фактически после запуска кластера отказ или просто отключение управляющей ноды никак не влияет на остальные процессы внутри кластера. MGM-нода должна быть запущена раньше, чем все остальные ноды, для этого используйте команду ndb_mgmd.
• DB Node (Network Data Base Node, Storage Node). Основная нода, которая обеспечивает хранение данных и выполнение всех транзакций. Количество необходимых нод данного типа зависит от объема ваших данных (количества фрагментов, на которые их
необходимо разбить) и количества репликаций. Например, если вы хотите, чтобы данные обрабатывались двумя серверами, которые будут реплицироваться (дублироваться), вам необходимо использовать четыре ноды данного типа. Для запуска используйте
команду ndbd.
• MySQL Server (SQL Node). Стандартный MySQL-сервер, использующий NDB-ноды для хранения данных. Вы можете использовать любое количество нод данного типа. Выполняемые функции: предоставление стандартного SQL-интерфейса. Для запуска используйте команду mysqld -ndbcluster.
Кластерное хранилище данных
Давайте рассмотрим хранилище данных более детально. Основное отличие — все данные хранятся в оперативной памяти. Все действия с данными выполняются в оперативной памяти. Более того, используемый тип таблиц в кластере — NDBCLUSTER. Это означает, что при переносе данных в кластер с обычного mySQL-сервера вы должны заменить в описании структуры все строки вида 'TYPE=MyISAM' на 'TYPE=NDBCLUSTER'. Чем это обусловлено? На самом деле вы можете использовать таблицы MyISAM/InnoDB и в кластере, но в таком случае эта таблица будет размещена локально на создавшем ее MySQL-сервере и не будет использовать кластерное хранилище данных. Соответственно, она будет видна только для тех клиентов, которые соединяются с соответствующей SQL-нодой. В противовес этому NDBCLUSTER-таблицы используют кластерное хранилище данных и доступны для любой SQL-ноды. Сколько необходимо задействовать серверов для хранения данных? Вы можете воспользоваться следующей формулой для ответа на этот вопрос:

Например, если вы хотите, чтобы ваши данные были продублированы один раз, и при этом их прогнозируемый размер — 6 гигабайт, вам необходимо использовать четыре сервера с 4 Гб оперативной памяти на каждом из них (в таком случае ваша база данных будет распределена между двумя серверами). В случае, если вы получили сообщение об ошибке вида "ERROR 1114: The table 'my_cluster_table' is full", вам необходимо увеличить задействованный объем оперативной памяти. Количество задействованных серверов для хранения данных не должно превышать 48. Общее количество задействованных серверов в кластере не должно превышать 63.
Данные загружаются в оперативную память при старте кластера. Все дальнейшие операции также выполняются в оперативной памяти. Все проведенные транзакции пишутся на диск в виде лог-файла. При нормальном (не аварийном) завершении работы кластера все данные записываются на жесткий диск.
SQL-нода может использовать следующие обращения к кластерному хранилищу данных:
• Выборка по первичному ключу. Любая таблица, расположенная в кластерном хранилище данных, имеет первичный ключ, даже если вы не задали его явно при создании таблицы. Выборка по первичному ключу — наименее ресурсоемкий из возможных запросов, от NDB к SQL ноде передается только одна запись.
• Выборка по уникальному ключу. Очень похоже на первый вариант и также использует первичный ключ для выборки данных. От NDB к SQL ноде передается только одна запись.
• Полный просмотр таблицы. В случае, если серверное хранилище данных получает запрос на полный просмотр одной из таблиц, на каждом задействованном для хранения данной таблицы сервере запускается соответствующий процесс. В текущей конфигурации по умолчанию все записи будут переданы на SQL-ноду для дальнейшей обработки запроса. В кластере на базе mySQL 5.0 данный вид обращений существенно оптимизирован: в случае выборки по неиндексированному полю проверка условия выполняется на стороне хранилища, и на SQL-ноду передаются только те записи,
которые соответствуют заданному условию. Данная возможность находится в стадии тестирования и по умолчанию отключена.
Для ее активации, используйте опцию --engine-conditionpushdown.
В таком случае скорость выполнения таких запросов может возрасти в 5-10 раз.
• Выборка по индексу. В таком случае также выполняется полный просмотр таблицы, но на SQL-ноду передаются только те записи, которые имеют соответствующие значения индексного поля.
Производительность кластера
Высокие показания производительности кластера достигаются за счет распределения нагрузки между несколькими физическими серверами и использования оперативной памяти для хранения данных.
В пресс-релизе mySQL AB задекларирована следующая производительность кластера:
• 10 000 транзакций в секунду при использовании двух однопроцессорных серверов;
• 100 000 транзакций в секунду при использовании четырех двухпроцессорных серверов.
В блоге Jeremy Zawodny были опубликованы следующие показатели производительности при использовании 72-процессорного кластера (количество физических серверов не уточняется):
• 380 000 операций записи в секунду
• 1,5 миллиона операций чтения в секунду
Отказоустойчивость
Отказоустойчивость кластера обеспечивается следующими особенностями его архитектуры:
• MySQL-серверы соединены с каждой нодой кластерного хранилища данных. В случае отказа одной из NDB-нод выполнение транзакции продолжается на другой ноде.
• Все NDB-ноды, используемые для хранения данных, могут быть продублированы. В случае отказа одной из нод всегда есть еще одна нода с теми же данными.
• Управляющая нода также может быть продублирована. Отказ управляющей ноды (даже если она одна) никак не влияет на работу остальных нод кластера.
• Вы можете использовать несколько SQL-нод и равномерно распределять клиентов между ними. Все SQL-ноды оперируют одними и теми же данными (в случае использования кластерного хранилища данных).
• Любая из нод, составляющих кластер, может быть отключена физически, не нарушив при этом работу самого кластера (конечно же, в том случае, если она была продублирована).
Что происходит в случае сбоя одной из нод? В случае, если обнаружен отказ одной из нод (недоступность ее по сети, отказ жесткого диска), она автоматически помечается как недоступная, и все остальные ноды кластера оповещаются об этом. После того, как
восстановлена работоспособность "недоступной" ноды, она соединяется с кластером и инициализируется заново.
Логирование, резервное копирование и восстановление данных
Для обеспечения целостности данных используется:
• Непрерывное ведение лога всех выполненных транзакций.
• Локальные контрольные точки. По мере выполнения транзакций размер лог-файла достаточно быстро увеличивается в размерах.
Мо мере достижения определенного количества проведенных транзакций все консистентные данные (контрольная точка) сохраняются на диск, и лог-файл очищается.
• Контрольные точки. Поскольку все транзакции фиксируются в оперативной памяти, каждой выполняемой транзакции присваивается последовательный уникальный идентификатор (контрольная точка). Эти значения используются при восстановлении системы после глобального сбоя и для контроля записи транзакций
на диск. Например, если транзакция с идентификатором 15 была сохранена на диск, это означает, что все транзакции с идентификатором меньше 15-ти также были сохранены на диск.
Восстановление кластера после глобального сбоя выглядит следующим образом: вначале с диска загружаются последние сохраненные данные (локальная контрольная точка), после чего последовательно выполняются все транзакции, занесенные в лог (последняя контрольная точка).
Резервная копия кластера включает в себя три части: структура таблиц, данные таблиц, сохраненные на каждой их нод серверного хранилища данных, и логи транзакций. Команда на создание резервной копии задается на управляющей ноде. При получении такой команды каждая нода хранилища создает три соответствующие
файла:
* BACKUP-..ctl
* BACKUP--0..data
* BACKUP-..log
Источник
1. MySQL Cluster. – Интернет-адрес: http:// www.mysql.com /products / cluster
|

